Prefer Helper Classes Over Bookkeeping with Dictionaries and Tuples
Python’s built-in dictionary type is wonderful for maintaining dynamic internal state over
the lifetime of an object. By dynamic, I mean situations in which you need to do
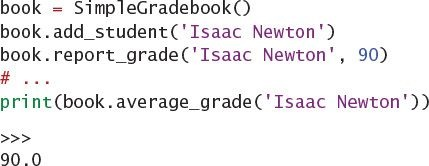
bookkeeping for an unexpected set of identifiers. For example, say you want to record the
grades of a set of students whose names aren’t known in advance. You can define a class
to store the names in a dictionary instead of using a predefined attribute for each student.

Dictionaries are so easy to use that there’s a danger of overextending them to write brittle
code. For example, say you want to extend the SimpleGradebook class to keep a list
of grades by subject, not just overall. You can do this by changing the _grades
dictionary to map student names (the keys) to yet another dictionary (the values). The innermost dictionary will map subjects (the keys) to grades (the values).

This seems straightforward enough. The report_grade and average_grade
methods will gain quite a bit of complexity to deal with the multilevel dictionary, but it’s
manageable.


Now, imagine your requirements change again. You also want to track the weight of each
score toward the overall grade in the class so midterms and finals are more important than
pop quizzes. One way to implement this feature is to change the innermost dictionary;
instead of mapping subjects (the keys) to grades (the values), I can use the tuple(score, weight) as values.

Although the changes to report_grade seem simple—just make the value a tuple—theaverage_grade method now has a loop within a loop and is difficult to read.

Using the class has also gotten more difficult. It’s unclear what all of the numbers in the
positional arguments mean.

When you see complexity like this happen, it’s time to make the leap from dictionaries
and tuples to a hierarchy of classes.
At first, you didn’t know you’d need to support weighted grades, so the complexity of
additional helper classes seemed unwarranted. Python’s built-in dictionary and tuple types
made it easy to keep going, adding layer after layer to the internal bookkeeping. But you
should avoid doing this for more than one level of nesting (i.e., avoid dictionaries that
contain dictionaries). It makes your code hard to read by other programmers and sets you
up for a maintenance nightmare.
As soon as you realize the bookkeeping is getting complicated, break it all out into classes.
This lets you provide well-defined interfaces that better encapsulate your data. This also
enables you to create a layer of abstraction between your interfaces and your concrete
implementations.
Refactoring to Classes
You can start moving to classes at the bottom of the dependency tree: a single grade. A
class seems too heavyweight for such simple information. A tuple, though, seems
appropriate because grades are immutable. Here, I use the tuple (score, weight) to
track grades in a list:

The problem is that plain tuples are positional. When you want to associate more
information with a grade, like a set of notes from the teacher, you’ll need to rewrite every
usage of the two-tuple to be aware that there are now three items present instead of two.
Here, I use _ (the underscore variable name, a Python convention for unused variables) to
capture the third entry in the tuple and just ignore it:

This pattern of extending tuples longer and longer is similar to deepening layers of
dictionaries. As soon as you find yourself going longer than a two-tuple, it’s time to
consider another approach.
The namedtuple type in the collections module does exactly what you need. It
lets you easily define tiny, immutable data classes.
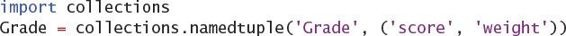
These classes can be constructed with positional or keyword arguments. The fields are
accessible with named attributes. Having named attributes makes it easy to move from anamedtuple to your own class later if your requirements change again and you need to
add behaviors to the simple data containers.
Limitations of namedtuple
Although useful in many circumstances, it’s important to understand whennamedtuple can cause more harm than good.
- You can’t specify default argument values for namedtuple classes. This makes
them unwieldy when your data may have many optional properties. If you find
yourself using more than a handful of attributes, defining your own class may be a
better choice. - The attribute values of
namedtupleinstances are still accessible using numerical
indexes and iteration. Especially in externalized APIs, this can lead to unintentional
usage that makes it harder to move to a real class later. If you’re not in control of all
of the usage of yournamedtupleinstances, it’s better to define your own class.
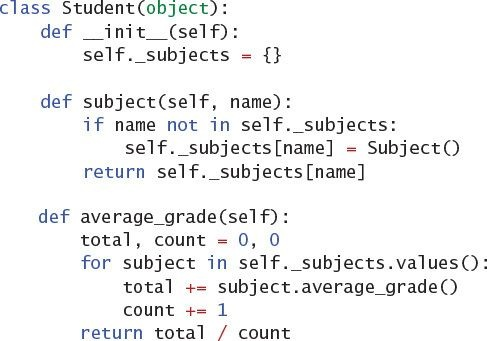
Next, you can write a class to represent a single subject that contains a set of grades.

Then you would write a class to represent a set of subjects that are being studied by a
single student.
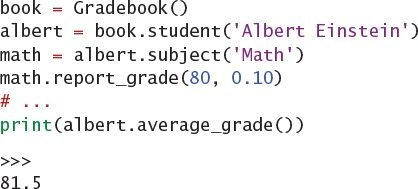
Finally, you’d write a container for all of the students keyed dynamically by their names.

The line count of these classes is almost double the previous implementation’s size. But
this code is much easier to read. The example driving the classes is also more clear and
extensible.
If necessary, you can write backwards-compatible methods to help migrate usage of the
old API style to the new hierarchy of objects.
Things to remember
- Avoid making dictionaries with values that are other dictionaries or long tuples.
- Use
namedtuplefor lightweight, immutable data containers before you need the
flexibility of a full class. - Move your bookkeeping code to use multiple helper classes when your internal state
dictionaries get complicated.
Source: Effective Python: 59 Ways to Write Better Python (Effective Software Development Series) 1st Edition by Brett Slatkin (March 8, 2015)