Вопросы с собесов. Деревья и ансамбли
Собрал подборку популярных вопросов с технических собеседований по теме деревьев решений и ансамблей — с подробными ответами и пояснениями. Подходит как для повторения перед интервью, так и для закрепления теории.
А ещё по этим вопросам провели мок-собес с моей ученицей — полезно, если хочется посмотреть, как это выглядит в формате собеседования.
Как выглядит алгоритм построения решающего дерева?
- Начинаем с корня — берём весь обучающий датасет
- Выбираем лучший признак и значение для сплита (критерия ветвления)
- Разбиваем данные на две части по этому сплиту
- Повторяем шаги для каждой части — рекурсивно строим поддеревья
- Останавливаемся, если выполнен критерий остановки; тогда вершина становится листом
- достигнута максимальная глубина
- в узле мало или много объектов
- прирост информации от нового сплита слишком мал

Какие есть критерии сплиттинга? Джини, энтропия, мсе
Интуиция: вероятность, что случайно выбранный элемент будет неправильно классифицирован, если мы выберем класс случайно по распределению в узле.
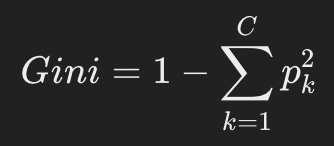
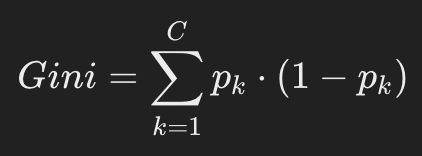
где p_i - доля i-го класса в листе.
Интуиция: мера "неопределённости" или "хаоса" — насколько непредсказуемо распределение классов.
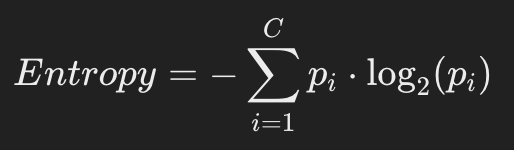
где p_i - доля i-го класса в листе.
На практике разница в выборе критерия редко сильно влияет на итоговую модель — важнее настройка других параметров (например, глубины, минимального количества в узле и т.д.).
В чём разница между классификацией и регрессией в деревьях?
- предсказываем метки классов
- Используем gini или энтропию
- самый популярный класс по объектам в листе (мода)
- предсказываем числовое значение
- Оптимизируем mse/mae во время сплита
- Используем среднее / медиану в листе как предсказание
Какие есть плюсы и минусы решающего дерева?
- Хорошо работают с нелинейными зависимостями
- Интерпретируемость: легко объяснить, почему модель приняла решение
- Работает с категориальными и числовыми признаками
- Не требует нормализации данных
- Легко переобучается, особенно при большой глубине
- Плохо работает с трендами
- Очень чувствительны к гиперпараметрам
Почему деревья плохо улавливают тренды и не умеют экстраполировать?
Как глубина влияет на дерево?
Маленькая глубина → недообучение (underfitting): модель слишком простая, плохо захватывает зависимости.
Слишком большая глубина → переобучение (overfitting): модель подстраивается под шум в данных, плохо обобщает. Крайний случай, например, когда дерево поместила каждый объект обучающей выборки в отдельный лист, в таком случае у нас идеальные метрики на трейне и очень плохие на тесте.
Обычно глубина дерева — один из основных гиперпараметров для настройки


Как можно регуляризировать решающее дерево?
- Ограничить максимальную глубину дерева (max_depth)
- Задать минимальное количество объектов в узле (min_samples_split, min_samples_leaf)
- Ограничить максимальное число признаков для выбора сплита (max_features)
- Использовать pruning (обрезку лишних веток после обучения)
- max_leaf_nodes — ограничивает общее число листьев в дереве
- min_impurity_decrease - минимальный прирост критерия сплита
Почему деревья не чувствительны к масштабированию признаков?
Потому что они не используют расстояния. Сплиты происходят по порогам типа: "если x > 3, то идти влево", и не важно, в каком масштабе заданы значения — хоть в сантиметрах, хоть в метрах.
Как оценить важность признаков по дереву?
Обычно важность признака измеряется как суммарное снижение impurity (Gini или энтропии), которое произошло благодаря разбиениям по этому признаку, по всем уровням дерева.
В ансамблях деревьев (например, в Random Forest) эти значения усредняются по всем деревьям.
Что такое бэггинг?
Бэггинг (Bagging) — это метод ансамблирования, в котором используется несколько одинаковых моделей, обученных на разных случайных подмножествах обучающих данных. Модели обучаются параллельно, а затем их прогнозы усредняются (для регрессии) или берётся мода (для классификации), чтобы получить итоговое решение.
Что такое бустинг?
Бустинг — это метод ансамблирования, в котором модели обучаются последовательно. Каждая последующая модель пытается исправить ошибки предыдущих. Например, слабые модели (например, слабые деревья) обучаются на ошибках предыдущих моделей, усиливая их предсказания на тяжёлых объектах.
Что такое стекинг?
Стекинг (Stacking) — это метод ансамблирования, при котором несколько моделей обучаются на исходных данных, а затем их предсказания используются как входные данные для мета-модели (вторичного уровня). Мета-модель учится на прогнозах базовых моделей и даёт итоговое предсказание.
Что такое bias-variance decomposition? Какой тип ансамблирования, что оптимизирует?
Bias-Variance Decomposition — это концепция, которая помогает понять, как ошибки модели можно разделить на две основные составляющие:
- Bias (смещение) — ошибка, возникающая, когда модель слишком простая и не может захватить все закономерности в данных. Это приводит к систематической ошибке в предсказаниях.
- Variance (вариативность) — ошибка, возникающая, когда модель слишком сложная и слишком чувствительна к случайным колебаниям данных, что приводит к нестабильным и переобученным предсказаниям.
- Noise (шум) — это неизбежная ошибка, которая не может быть уменьшена ни с помощью улучшения модели, ни с помощью большого объёма данных.
Полная ошибка модели может быть разложена на три части:
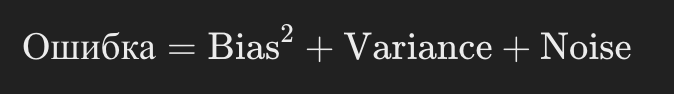
Бэггинг - уменьшает вариенс и уже обладает низким смещением.

Бустинг имеет низкий вариенс и уменьшает смещение.
Стекинг явно ничего из этого не призван минимизировать.
Что такое бутстреп?
Бутстрэп (Bootstrap) — это метод случайного выбора подмножества данных с возвращением (т.е. с повторениями). В контексте бэггинга, для каждой базовой модели создаётся случайное подмножество обучающих данных путём повторного выбора объектов из исходного набора.
Что такое случайные лес? Где там случайность?
Случайный лес (Random Forest) — это ансамбль решающих деревьев, построенных на случайных подмножествах данных и признаков. Случайность здесь проявляется как в процессе бутстрэппинга (создание случайных подмножеств данных), так и в случайном выборе подмножества признаков на каждом сплите дерева.
Почему в Random Forest при выборе признаков на каждом сплите используют случайное подмножество признаков?
Это делается для того, чтобы снизить корреляцию между деревьями в лесу и улучшить общую производительность модели. Если все деревья будут использовать одни и те же признаки, они будут более похожи друг на друга, что приведёт к менее разнообразным решениям.
С точки зрения bias-variance decomposition мы хотим строить максимально разнообразные деревья и как можно больше их. То есть мы строим экспертов в своей области (по подмножеству данных и признаков), а потом их усредняем.
Да и просто с точки зрения логики - зачем нам строить одинаковые деревья?)
Почему градиентный бустинг называется градиентным? Где там градиент?
Когда мы говорим, что обучаемся на ошибках предыдущих моделей, мы:
- выбираем функцию потерь
она зависит от таргета и нашего предсказания - после очередного шага считаем антиградиент в точке a_k(x_i) предсказания текущей части композиции на объекте x_i
- обучаем следующий алгоритм на значение антиградиента
Таким образом мы обучаемся на ошибках, но не совсем на остатках (разницы между предсказанием и таргетом), а на значение антиградиента, что, например, для функции потерь mse одно и то же.
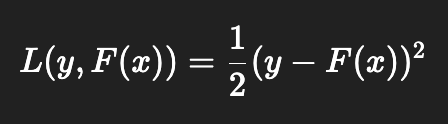
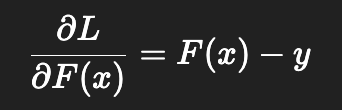
Почему нельзя в качестве базовых алгоритмов использовать линейные модели, например?
Потому что будет линейная комбинация линейных моделей - это бессмысленно, будет просто та же самая линейная комбинация.
Где деревья глубже бустинг/бэггинг?
В бэггинге обычно деревья глубже, а бустинге с ограничением, чтобы не переобучаться.
Если в бустинге в какой-то момент будет переобучение - вырулить из этого никак не получится.
А в бэггинге даже если будет несколько переобученных деревьев, эффект от них может быть некритичным, так как мы берем несколько алгоритмов и усредняем их предсказаниях.
Что если сделать первое дерево очень глубоким в бэггинге/бустинге?
Если первое дерево очень глубокое, оно будет склонно к переобучению на обучающих данных, так как оно будет слишком подстраиваться под шум и выбросы в данных. Однако, поскольку в бэггинге используются ансамбли деревьев, остальные деревья будут обучаться на других подмножествах данных, и, возможно, это частично уменьшит влияние переобучения первого дерева. Но в целом такое дерево может ухудшить стабильность ансамбля.
Если первое дерево слишком глубокое, это может усилить переобучение с самого начала. В бустинге каждая модель обучается на ошибках предыдущей, и если первое дерево слишком сильно подгоняет данные, оно будет давать плохие результаты для последующих моделей. Если у нас первое дерево уже переобучилось - что тогда делать другим деревьям, трейн данные мы уже идеально запомнили. Это может повлиять на стабильность и общую точность всей модели. Поэтому в бустинге часто ограничивают глубину деревьев для предотвращения этого.
Что если убрать первое дерево в бэггинге/устинге?
Если удалить первое дерево, в ансамбле всё равно останется множество других деревьев, и они будут давать разнообразие прогнозов. Так как в бэггинге важно среднее усреднение множества деревьев, удаление одного не сильно повлияет на итоговый результат, особенно если количество деревьев велико. Однако, если деревьев мало, удаление может снизить точность ансамбля.
Если удалить первое дерево в бустинге, это сломает всю последовательность обучения, так как каждое следующее дерево пытается исправить ошибки предыдущего. Без первого дерева у модели не будет фундамента для исправления ошибок, и это может значительно снизить эффективность ансамбля. Это нарушает основной принцип бустинга, и результат будет хуже.
Можно ли переобучить бустинг? а бэггинг?
Да, бустинг легко переобучается, особенно при слишком большом количестве итераций, сложных базовых моделях.
Бэггинг в целом более устойчив к переобучению, поскольку каждое дерево обучается на случайных подмножествах данных. И при увеличении числа базовых алгоримтов переобучить ансамбль не получится.
Как можно регуляризировать ансамбли?
- Ограничить глубину деревьев и настраивать другие гиперпараметры.
- Использовать бутстрэппинг и случайный выбор признаков (для Random Forest).
- Использовать методы ранней остановки (early stopping) в бустинге.
- Применять методы усечения моделей (например, ограничение на максимальное количество итераций).
Отличия LightGBM, XGBoost, CatBoost?
- На каждом шаге выбираем вершину для ветвления с наилучшим скором
- Дерево получается несимметричным
- В этом алгоритме быстро подстраиваемся под трейн данные, поэтому можно быстрее переобучиться
- Основной критерий остановки - максимальная глубина

- Строим дерево последовательно по уровням до достижения максимальной глубины
- Дерево получается симметричным, а иногда и бинарным
- Такому алгоритму тяжелее переобучиться, чем LightGBM

- Все вершини одного уровня имеют одинаковых предикат (см картинку ниже). предикат = условие ветвления
- Такое жесткое ограничение является сильным регуляризатором
- Также из-за отсутствия вложенных if-else ускоряется инференс дерева

Как делать трейн/тест сплит для стекинга?
Для стекинга важен out-of-fold split. Каждый базовый классификатор обучается на части данных (например, с использованием кросс-валидации), а затем делает предсказания на оставшихся данных, которые не использовались в обучении. Эти предсказания (out-of-fold) используются для тренировки мета-модели.
Часто делают кросс-валидацию, чтобы в итоге обучаться на всех данных.

