Experiments/Unpublished/
§ Это не опубликованные по разным причинам эксперементы/модели которые я нашел когда чистил память.
FLAN SD
Идея очень простая, давайте возьмем UNET, возьмем жирный энкодер, UNET и Encder заморозим, а учить будем прокладку между ними(идея частично спизжена у Влада Лиалина)

Адаптер состоял из Attention pooling + FF + LN, а в первой версии - FF + LN
Вот и мне так показалось, оно сошлось и начало генерить аниме(а учил я на аниме)

ДАВНООО Я так не ошибался, уйдя заниматься другими делами я отставил все считаться(около 3х дней на одной карте), а вернувшись увидел это:

Перезапустил, поставил LR ниже иии
Чо? Хуй через плечо, ответила модель и сошлась в какой то очень странный домен, начав генерить вместо аниме богинь вот это:

DENOISE GPT
РУКИ НА СТОЛ И ЧТОБЫ Я ИХ ВИДЕЛ, ЭТО НЕ СОБЕСЕДОВАНИЕ НА ШИТПОСТЕРА, МЫ ТУТ БЛЯТЬ СЕРЬЕЗНЫМИ ВЕЩАМИ ЗАНИМАЕМСЯ
Короче, денойзеры это схема которую придумал google(а может и нет), но по крайней мере я первый раз увидел это в папире UL2
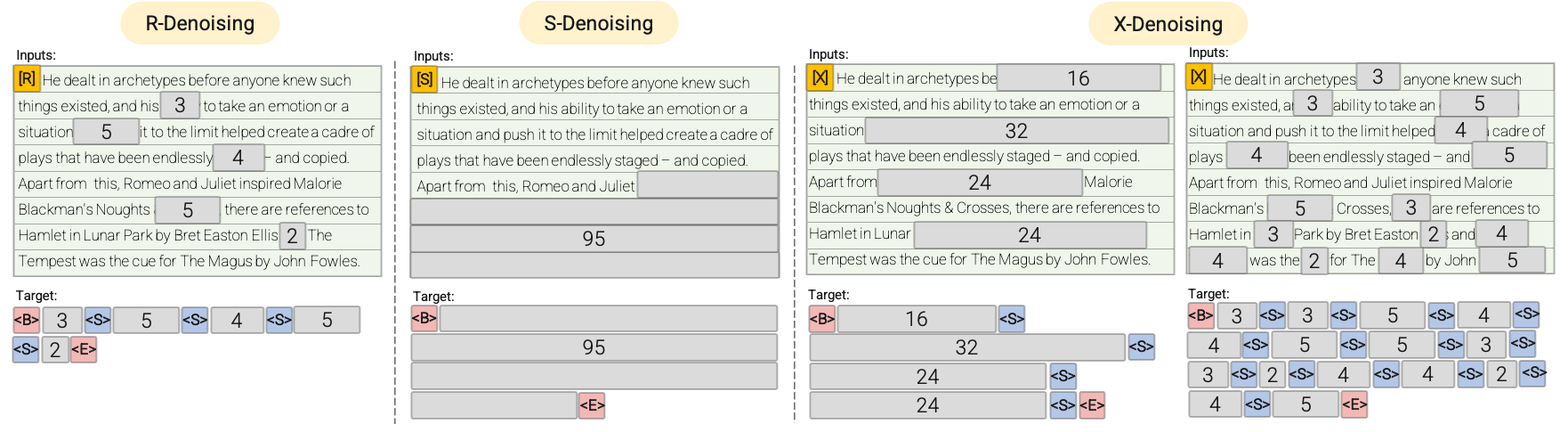
- R-Denoiser - это метод декодирования, который заменяет случайно выбранные 2-5 слов на маскированные слова. Это помогает модели научиться генерировать более связный текст, в attn mask это выглядит как Multi MLM или как нынче модно говорить: TEXT DIFFUSION, BERT ONE STEP DIFFUSION
- S-Denoiser - это метод очистки текста, который используется для задачи предсказания последующих слов в предложении. Короче GPT
- X-Denoiser - как R denoiser, только кусков больше и они еще и длинные, суммарно до 50% предложения
ну я посмотрел на это, подумал что чо бы не да, и сделал это для GPT
Поставил "дотрейн" на корпусе wiki-news-habr, ну а по итогу...

Так работал S denoiser, вроде и хорошо, но поигравшись и потюнив на другие задачи модель КРАЙНЕ незначительно выросла по метрикам, в итоге ее выкинули
CLONED TRANSFORMER
Ну трансформеры, знаете да? Хуйня из под каждого коня, каждого утюга...
А знает в чем прикол? MSE между выходом из двух последовательных блоков ОЧЕНЬ МАЛЕНЬКИЙ, те Hidden states по сути почти не меняются(кроме последнего)
Ну и я решил, а чо бы и не взять и не склонить слои последовательно?
Типа: Block1->Block1->Block2->Block2....
На скорую руку написал код и поставил учиться, выглядело все неплохо:

Ну те модели явно сходились, чо то работало на вид...

А вот генерации не радовали, они не улучшались от чекпоинта к чекпоинту, а на SuperGlue модель показывала себя где то между оригинальной моделью и моделью которую изначально учили в том же размере
Предвидя вопрос: Увеличивал число слоев в rugpt3medium(350m), сравнивал с rugpt3large, учил примерно на 2B токенов, с Batch 16(4*4 grad acum)
Wortega LM
Ну шиншилу знаете? Вот она говорит что 125m можно натренить дома, где то за 2-3 дня, надо пролить 2B~ токенов за 5-10 эпох и будет радость в доме!
Ну я взял свои карты, взял сет RULM и поставил учиться
Собственно поставил я GPT NEO 125m, ничего особо примечательного

Суммарный батч 64, все в целом очень хорошо, вроде даже генерит что то

Неплохо? Вот и мне нравилось. Нравилось до тех пор пока я не поставил тюниться на DownStream в виде QA

И ТУТ ДО МЕНЯ ДОШЛО!! Все просто, хотите хорошую LM? Лейте x4 от шиншило оптимального размера!!
А вот на задачах где не надо особо точно отвечать, модель показывает себя не плохо, сопастовимо с rugpt3small, но метрики я не считал отложив модель на полку и отдам студентам игрушечную модель.
Играться можно тут https://huggingface.co/AlexWortega/wortegaLM
