Cloudflare goes InterPlanetary

Today we’re excited to introduce Cloudflare’s IPFS Gateway, an easy way to access content from the InterPlanetary File System (IPFS) that doesn’t require installing and running any special software on your computer. We hope that our gateway, hosted at cloudflare-ipfs.com, will serve as the platform for many new highly-reliable and security-enhanced web applications. The IPFS Gateway is the first product to be released as part of our Distributed Web Gateway project, which will eventually encompass all of our efforts to support new distributed web technologies.
This post will provide a brief introduction to IPFS. We’ve also written an accompanying blog post describing what we’ve built on top of our gateway, as well as documentation on how to serve your own content through our gateway with your own custom hostname.
Quick Primer on IPFS

Usually, when you access a website from your browser, your browser tracks down the origin server (or servers) that are the ultimate, centralized repository for the website’s content. It then sends a request from your computer to that origin server, wherever it is in the world, and that server sends the content back to your computer. This system has served the Internet well for decades, but there’s a pretty big downside: centralization makes it impossible to keep content online any longer than the origin servers that host it. If that origin server is hacked or taken out by a natural disaster, the content is unavailable. If the site owner decides to take it down, the content is gone. In short, mirroring is not a first-class concept in most platforms (Cloudflare’s Always Online is a notable exception).
The InterPlanetary File System aims to change that. IPFS is a peer-to-peer file system composed of thousands of computers around the world, each of which stores files on behalf of the network. These files can be anything: cat pictures, 3D models, or even entire websites. Over 5,000,000,000 files had been uploaded to IPFS already.
IPFS vs. Traditional Web
There are two key differences between IPFS and the web as we think of it today.
The first is that with IPFS anyone can cache and serve any content—for free. Right now, with the traditional web, most typically rely on big hosting providers in remote locations to store content and serve it to the rest of the web. If you want to set up a website, you have to pay one of these major services to do this for you. With IPFS, anyone can sign up their computer to be a node in the system and start serving data. It doesn’t matter if you’re working on a Raspberry Pi or running the world’s biggest server. You can still be a productive node in the system.
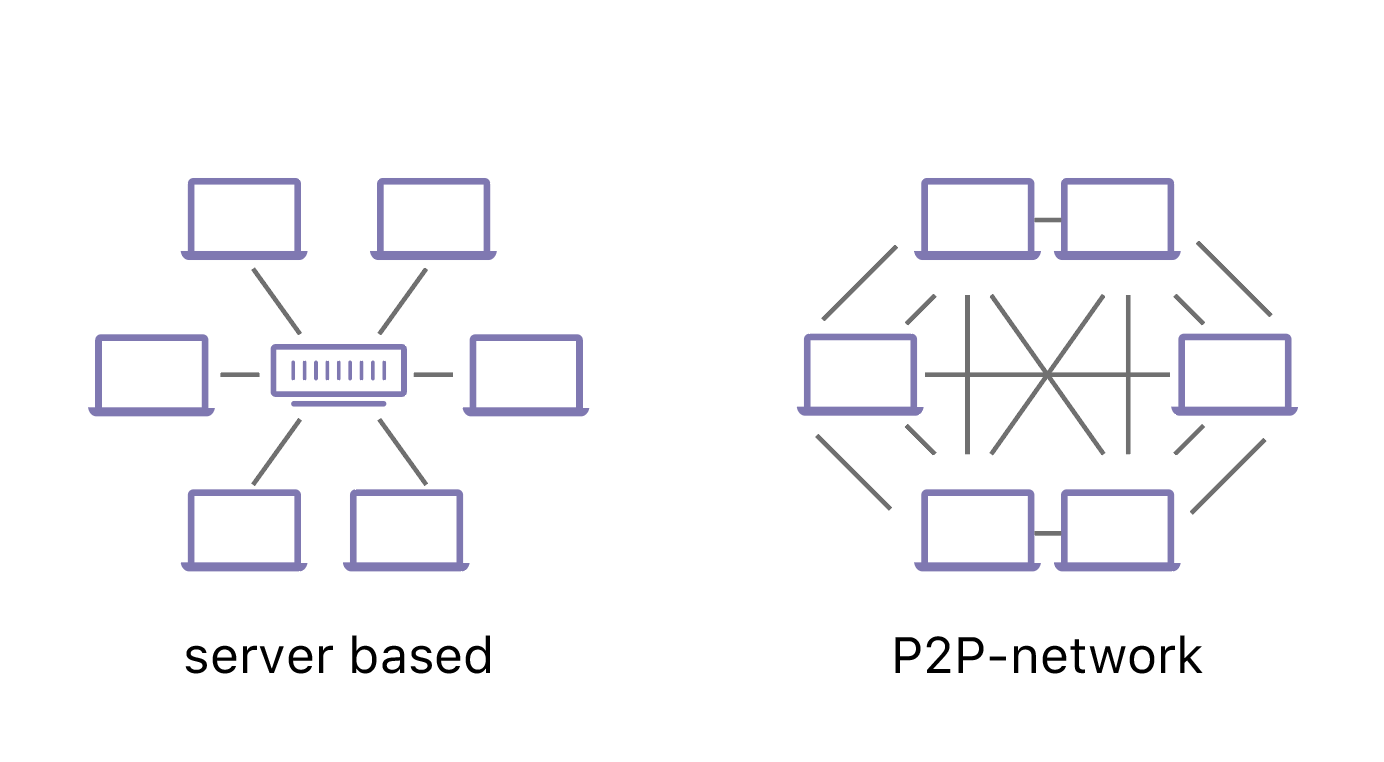
The second key difference is that data is content-addressed, rather than location-addressed. That’s a bit of a subtle difference, but the ramifications are substantial, so it’s worth breaking down.
Currently, when you open your browser and navigate to example.com, you’re telling the browser “fetch me the data stored at example.com’s IP address” (this happens to be 93.184.216.34). That IP address marks where the content you want is stored in the network. You then send a request to the server at that IP address for the “example.com” content and the server sends back the relevant information. So at the most basic level, you tell the network where to look and the network sends back what it found.
IPFS turns that on its head.
With IPFS, every single block of data stored in the system is addressed by a cryptographic hash of its contents, i.e., a long string of letters and numbers that is unique to that block. When you want a piece of data in IPFS, you request it by its hash. So rather than asking the network “get me the content stored at 93.184.216.34,” you ask “get me the content that has a hash value of QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy.” (QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy happens to be the hash of a .txt file containing the string “I’m trying out IPFS”).
How is this so different?
Remember that with IPFS, you tell the network what to look for, and the network figures out where to look.
Why does this matter?
First off, it makes the network more resilient. The content with a hash of QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy could be stored on dozens of nodes, so if one node that was caching that content goes down, the network will just look for the content on another node.
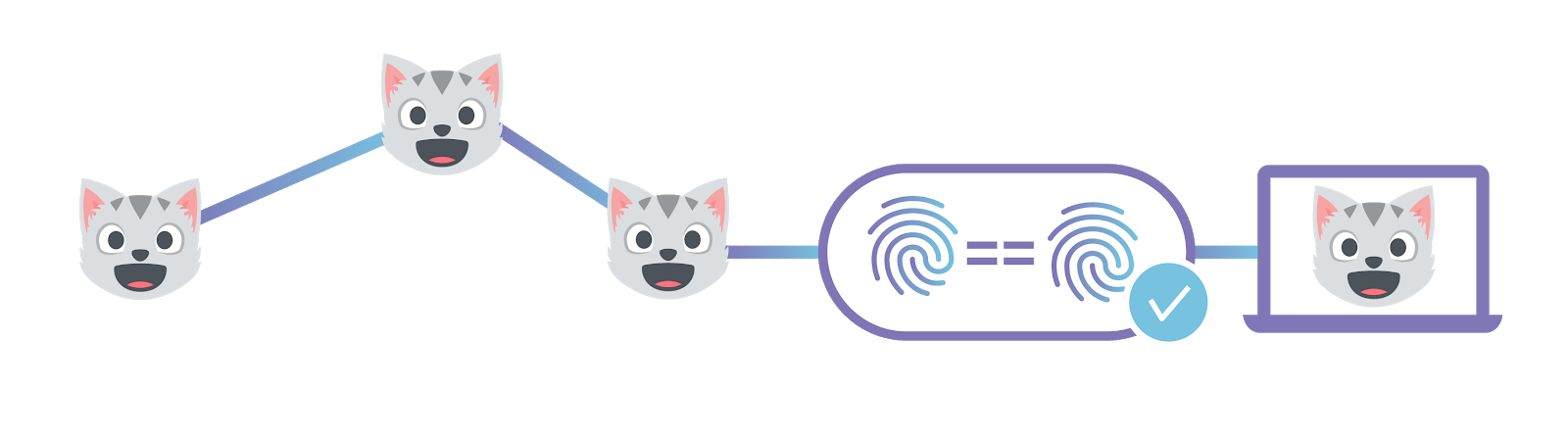
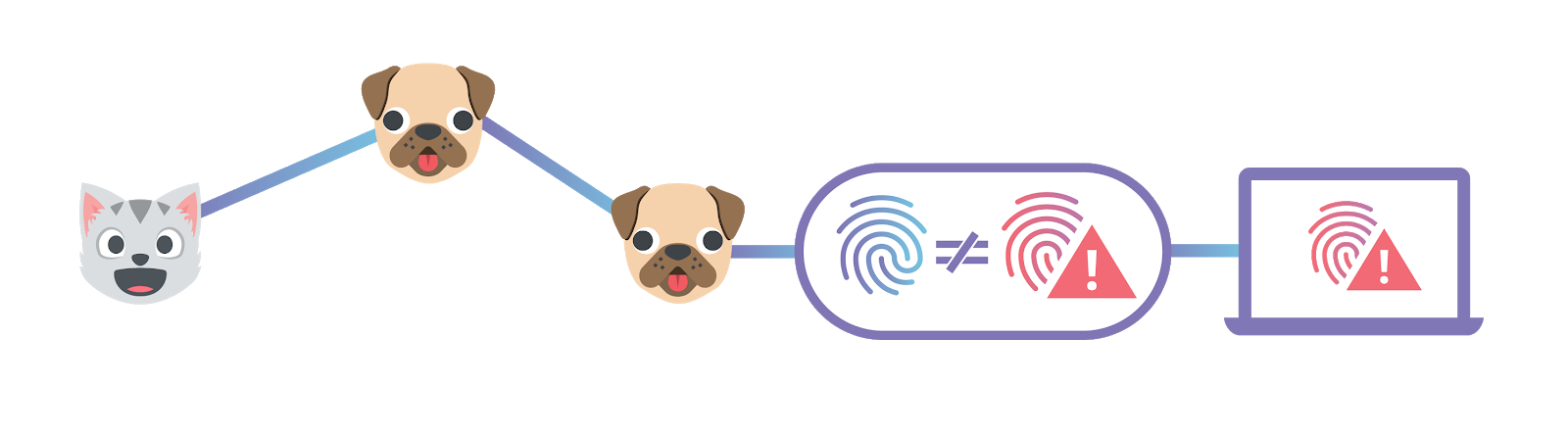
Second, it introduces an automatic level of security. Let’s say you know the hash value of a file you want. So you ask the network, “get me the file with hash QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy” (the example.txt file from above). The network responds and sends the data. When you receive all the data, you can rehash it. If the data was changed at all in transit, the hash value you get will be different than the hash you asked for. You can think of the hash as like a unique fingerprint for the file. If you’re sent back a different file than you were expecting to receive, it’s going to have a different fingerprint. This means that the system has a built-in way of knowing whether or not content has been tampered with.
A Note on IPFS Addresses and Cryptographic Hashes
Since we’ve spent some time going over why this content-addressed system is so special, it’s worth talking a little bit about how the IPFS addresses are built. Every address in IPFS is a multihash, which means that the address combines information about both the hashing algorithm used and the hash output into one string. IPFS multihashes have three distinct parts: the first byte of the mulithash indicates which hashing algorithm has been used to produce the hash; the second byte indicates the length of the hash; and the remaining bytes are the value output by the hash function. By default, IPFS uses the SHA-256 algorithm, which produces a 32-byte hash. This is represented by the string “Qm” in Base58 (the default encoding for IPFS addresses), which is why all the example IPFS addresses in this post are of the form “Qm…”.
While SHA-256 is the standard algorithm used today, this multihash format allows the IPFS protocol to support addresses produced by other hashing algorithms. This allows the IPFS network to move to a different algorithm, should the world discover flaws with SHA-256 sometime in the future. If someone hashed a file with another algorithm, the address of that file would start some characters other than “Qm”.
The good news is that, at least for now, SHA-256 is believed to have a number of qualities that make it a strong cryptographic hashing algorithm. The most important of these is that SHA-256 is collision resistant. A collision occurs when there are two different files that produce the same hash when run through the SHA-256 algorithm. To understand why it’s important to prevent collisions, consider this short scenario. Imagine some IPFS user, Alice, uploads a file with some hash, and another user, Bob, uploads a different file that happens to produce the exact same hash. If this happened, there would be two different files in the network with the exact same address. So if some third person, Carol, sent out an IPFS request for the content at that address, she wouldn't necessarily know whether she was going to receive Bob’s file or Alice’s file.
SHA-256 makes collisions extremely unlikely. Because SHA-256 computes a 256-bit hash, there are 2^256 possible IPFS addresses that the algorithm could produce. Hence, the chance that there are two files in IPFS that produce a collision is low. Very low. If you’re interested in more details, the birthday attack Wikipedia page has a cool table showing exactly how unlikely collisions are, given a sufficiently strong hashing algorithm.
How exactly do you access content on IPFS?
Now that we’ve walked through all the details of what IPFS is, you’re probably wondering how to use it. There are a number of ways to access content that’s been stored in the IPFS network, but we’re going to address two popular ones here. The first way is to download IPFS onto your computer. This turns your machine into a node of the IPFS network, and it’s the best way to interact with the network if you want to get down in the weeds. If you’re interested in playing around with IPFS, the Go implementation can be downloaded here.
But what if you want access to content that’s stored on IPFS without the hassle of operating a node locally on your machine? That’s where IPFS gateways come into play. IPFS gateways are third-party nodes that fetch content from the IPFS network and serve it to you over HTTPS. To use a gateway, you don’t need to download any software or type any code. You simply open up a browser and type in the gateway’s name and the hash of the content you’re looking for, and the gateway will serve the content in your browser.
Say you know you want to access the example.txt file from before, which has the hash QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy, and there’s a public gateway that is accessible at https://example-gateway.com
To access that content, all you need to do is open a browser and type
https://example-gateway.com/ipfs/QmXnnyufdzAWL5CqZ2RnSNgPbvCc1ALT73s6epPrRnZ1Xy
and you’ll get back the data stored at that hash. The combination of the /ipfs/ prefix and the hash is referred to as the file path. You always need to provide a full file path to access content stored in IPFS.
What can you do with Cloudflare’s Gateway?
At the most basic level, you can access any of the billions of files stored on IPFS from your browser. But that’s not the only cool thing you can do. Using Cloudflare’s gateway, you can also build a website that’s hosted entirely on IPFS, but still available to your users at a custom domain name. Plus, we’ll issue any website connected to our gateway a free SSL certificate, ensuring that each website connected to Cloudflare's gateway is secure from snooping and manipulation. For more on that, check out the Distributed Web Gateway developer docs.
A fun example we’ve put together using the Kiwix archives of all the different StackExchange websites and build a distributed search engine on top of that using only IPFS. Check it out here.
Dealing with abuse
IPFS is a peer-to-peer network, so there is the possibility of users sharing abusive content. This is not something we support or condone. However, just like how Cloudflare works with more traditional customers, Cloudflare’s IPFS gateway is simply a cache in front of IPFS. Cloudflare does not have the ability to modify or remove content from the IPFS network. If any abusive content is found that is served by the Cloudflare IPFS gateway, you can use the standard abuse reporting mechanism described here.
Embracing a distributed future
IPFS is only one of a family of technologies that are embracing a new, decentralized vision of the web. Cloudflare is excited about the possibilities introduced by these new technologies and we see our gateway as a tool to help bridge the gap between the traditional web and the new generation of distributed web technologies headlined by IPFS. By enabling everyday people to explore IPFS content in their browser, we make the ecosystem stronger and support its growth. Just like when Cloudflare launched back in 2010 and changed the game for web properties by providing the security, performance, and availability that was previously only available to the Internet giants, we think the IPFS gateway will provide the same boost to content on the distributed web.
Dieter Shirley, CTO of Dapper Labs and Co-founder of CryptoKitties said the following:
We’ve wanted to store CryptoKitty art on IPFS since we launched, but the tech just wasn’t ready yet. Cloudflare’s announcement turns IPFS from a promising experiment into a robust tool for commercial deployment. Great stuff!