O(N^2)
Каждый раз, когда вижу в олимпиадных задачах ограничение N≤10^5, хочется проверить, стали ли компьютеры достаточно быстрыми, чтобы O(N^2) успел по времени.
Я не видел особо туториалов по тому, как использовать SIMD в олимпиадах, так что решил куда-то записать свой опыт.
Когда я прочитал задачу F с Edu131, Time Limit = 6.5с показался слишком привлекательными...
Задача
Если отбросить детали, то её можно переформулировать следующим образом. Есть два массива alive (добавлена ли сейчас точка в множество) и cnt (количество живых точек правее на расстоянии не более d), каждый размером 2·10^5. Нужно уметь добавлять/удалять точки из множества. Т.е:
После каждой операции нужно считать сумму по всем живым точкам cnt[i] * (cnt[i] - 1) / 2.
Baseline
Сразу скажу, что делать нормальные воспроизводимые бенчмарки мне лень, так что погрешность измерений может быть довольно большой. Иногда измерения будут с ноута, а иногда с запуска на CodeForces (где все работает в ~2 раза медленнее и другое окружение). А еще все примеры кода будут на Rust, но должно быть все понятно.
Тестировать будем на тесте, когда для всех i от 1 до N, точку i добавляют в множество, и нужно обновить все значения cnt левее i. Вроде бы это максимальный тест, который может быть в исходной задаче.
Самый простой вариант обработки одного запроса query выглядит примерно так:
alive[query] = !alive[query];
let delta = if alive[query] { 1 } else { -1 };
for c in cnt[seg_start[query]..query].iter_mut() {
*c += delta;
}
let res = cnt
.iter()
.zip(alive.iter())
.map(|(&cnt, &alive)| if alive { cnt * (cnt - 1) / 2 } else { 0 })
.sum();Локально он работает ~11.1с, на CodeForces это будет секунд 20, так что точно не вариант.
Простые оптимизации
Некоторые считают, что if в самом горячем месте кода это всегда плохо, и если его заменить, например, на умножение, все станет гораздо быстрее. На самом деле это не так, и в нашем случае все будет работать только медленнее. По крайней мере на этом тесте alive у нас всегда true, так что бранч предиктор будет очень хорошо предсказывать этот переход, и он почти не будет влиять на скорость.
А вот деление это очень плохо, так что если не делить на два внутри map, а сделать это только один раз в конце, то тест отработает за ~8.5с.
Perf
Умение пользоваться perf-ом может сильно помочь в поиске проблемных кусков кода. Но довольно часто perf выдает какую-то чушь, и нужно уметь это чинить. Базовые правила использования perf-а для Rust:
[profile.release] debug = 1
Иначе он не будет показывать строки исходного кода, которые соответствуют asm-у.
[build] rustflags = "-C force-frame-pointers=yes"
Возможно так perf будет лучше понимать откуда какая функция вызвалась и лучше строить стектрейсы. На скорость вроде бы влиять особо не должно.
perf recordнужно запускать с флагом-g, чтобы записывались стектрейсы.- Еще в
perf recordможно добавлять--call-graph dwarf, но лично у меня почему-то после этогоperf reportдолго запускается.
Итак, в perf-е текущей версии есть два горячих места:
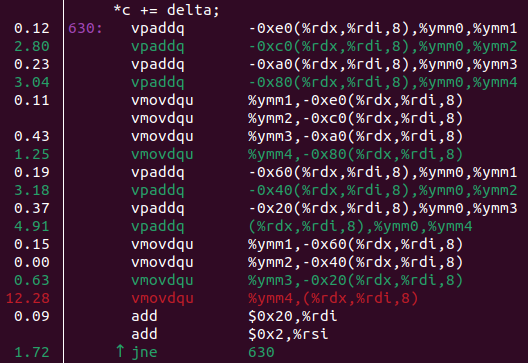

Какие можно сразу сделать выводы?
- Судя по использованию ymm регистров и буквe p (packed) в названии некоторых инструкций — тут уже есть SIMD! Компилятор умный (?)
- Пересчет результата занимает явно больше времени чем обновление
cnt(в столбце слева процент времени, который программа провела в этой строке).
Упрощаем (жизнь процессору, не код)
Как улучшить подсчет результата?
Во-первых, можно пересчитывать его только для части массива, на котором он поменялся (оптимизация в два раза на нашем тесте!).
Во-вторых, можно только считать разницу между старым результатом и новым, тогда не нужно будет делать умножения в самом вложенном месте.
Получился явно не самый простой для понимания код:
alive[query] = !alive[query];
let delta0 = if alive[query] { 0 } else { -1 };
let delta = if alive[query] { 1 } else { -1 };
res += cnt[seg_start[query]..query]
.iter()
.zip(alive[seg_start[query]..query].iter())
.map(|(&cnt, &alive)| if alive { cnt + delta0 } else { 0 })
.sum::<i64>()
* 2
* delta;
res += delta * cnt[query] * (cnt[query] - 1);
for c in cnt[seg_start[query]..query].iter_mut() {
*c += delta;
}Но основные идеи довольно просты:
- Заводим глобальную переменную
resна все запросы. - Отдельно обрабатываем вклад текущей точки.
- (с точностью до +-1) добавляем к ответу сумму
cntу живых точек слева, потому что это то, на сколько поменялисьcnt[i] * (cnt[i] - 1)при измененииcnt[i]на 1.
Такое решение работает локально ~4.7c, что очень обнадеживает. Но на CodeForces не укладывается даже в 15с, очень жаль.
Что не так с CodeForces?
Когда пытаешься что-то оптимизировать, полезно выделить важный кусок кода в отдельную функцию, которая ни от чего не зависит и у который понятный интерфейс. В нашем случае выделим две функции:
pub fn add_const(arr: &mut [i64], delta: i64) {
for val in arr.iter_mut() {
*val += delta;
}
}
pub fn calc_res(alive: &[bool], cnt: &[i64], delta0: i64) -> i64 {
cnt.iter()
.zip(alive.iter())
.map(|(&cnt, &alive)| if alive { cnt + delta0 } else { 0 })
.sum()
}После этого на них можно смотреть в Compiler Explorer. Например, можно заметить, что функция add_const использует xmm регистры (обычно это хороший знак), а calc_res — нет. Т.е. calc_res совсем не использует никакой SIMD магии. Но почему?
По умолчанию компилятор раста очень консервативен относительно того, какие инструкции он использует. Это нужно, чтобы программа, которую скомпилировали на одном компьютере, могла запускаться на другом. Даже если ваш процессор супер-пупер новый и поддерживает кучу клевых быстрых инструкций, по умолчанию раст вместо них будет использовать старые и проверенные.
Если вы уверены, что программа будет запускаться на том же железе, на котором компилируется, то можно передать -C target-cpu=native в строку компиляции. Это можно сделать и в compiler explorer и увидеть, что теперь calc_res использует xmm/ymm регистры.
Но есть проблема, что мы не можем поменять флаги, с которыми компилируется наша программа на CodeForces. Зато в Rust есть возможность внутри кода сказать компилятору, чтобы он использовал модные инструкции. Но если во время исполнения окажется, что их нет, программа как-то упадет, так что такой код автоматически становится unsafe. Примерно так:
#[target_feature(enable = "avx2")]
pub unsafe fn add_const(arr: &mut [i64], delta: i64) {
for val in arr.iter_mut() {
*val += delta;
}
}
#[target_feature(enable = "avx2")]
pub unsafe fn calc_res(alive: &[bool], cnt: &[i64], delta0: i64) -> i64 {
cnt.iter()
.zip(alive.iter())
.map(|(&cnt, &alive)| if alive { cnt + delta0 } else { 0 })
.sum()
}Аналогичная проблема есть и на других тестирующих системах, но нужно быть осторожным и использовать только те расширения, которые там действительно есть. Например, на Yandex Contest прогресс остановился на
#[target_feature(enable = "sse2")]
Версия кода, которая использует avx2, в запуске на CF работает уже 7.7с, а не больше 15 как раньше! Напомню, что TL в задаче 6.5c, так что осталось совсем чуть-чуть.
64/32
Можно заметить, что cnt всегда помещается в 32 бита, так что можно использовать [i32]. К сожалению, сумма элементов уже не влазит в i32, так что нужно не забыть добавить много кастов по всему коду к i64.
Такой код работает уже порядка 6.5с в запуске на CF. Возможно идея в том, что больше 32-битных чисел помещается в один xmm/ymm регистр. А возможно на CF все еще используют 32-битные что-то и это как-то влияет? Но факт остается фактом, оптимайз действительно помогает.
К сожалению эти 6.5с из запуска не учитывают считывание, вывод, и случайные изменения времени работы от теста к тесту, так что нужно еще немного соптимизировать.
Последняя оптимизация
Мне все еще хотелось сделать alive типом [i32] и заменить if на умножение, но это по прежнему только замедляло программу.
Но на самом деле вместо умножения можно использовать битовые операции. Например, сказать, что в alive мы храним либо 0, либо -1, а при подсчете делаем & с ним. Финальная версия выглядит как-то так:
#[target_feature(enable = "avx2")]
pub unsafe fn calc_res(alive: &[i32], cnt: &[i32], delta0: i32) -> i64 {
cnt.iter()
.zip(alive.iter())
.map(|(&cnt, &alive)| (alive & (cnt + delta0)) as i64)
.sum()
}Она работает ~6.2c и должна стабильно получать AC.
Вывод
Скорее всего у этого текста целевая аудитория 1 человек и это я сам, но хорошо хоть записал :)