Google AI4Code или мой первый раз на Kaggle
Вчера наконец-то закончилось трехмесячное соревнование от гугла по машинному обучению, где нужно было написать программу, которая умеет понимать взаимосвязь между питоновским кодом и комментариями к нему. На вход вашей программе давался Python ноутбук, который состоит из клеток с кодом и клеток с текстом. Клетки с кодом даны в том же порядке, в котором они были в исходном ноутбуке. А клетки с текстом случайно перемешаны. Цель вашей программы — как можно точнее восстановить исходный порядок.
До этого соревнования у меня не было никакого реального опыта машинного обучения, и я подумал, что это отличный шанс попробовать что-то новое. В итоге это оказалось достаточно прикольно и интересно, но очень выматывающе (хочется же получить результат получше, но ничего не работает, приходится пробовать много всего).
Тестирование проходит в два этапа. Во время самого соревнования можно послать свой код и узнать, сколько он набирает баллов на закрытом датасете. Сам закрытый датасет набирался из публично доступный ноутбуков с Kaggle, так что теоретически можно было обучить свою модель на них и получить идеальный результат. Поэтому в следующие три месяца организаторы будут собирать новый датасет и перетестируют все решения на нем.
Так что официальных результатов ждать еще три месяца, но на предварительных у меня 25е место из 1000+ команд. С одной стороны для первого раза довольно неплохо. С другой конечно же можно было гораздо лучше и судя по таблице результатов, решение явно можно сильно улучшить.
О чем написать?
За прошедшие три месяца случилось довольно много интересных историй, и уместить их все в один пост явно не получится (ну либо его никто не дочитает до конца). Так что я постараюсь какую-то часть написать в этот пост, а потом, возможно, напишу еще отдельных историй (ставьте лайки и пишите о чем интересно почитать!).
Bad setup
Я потратил очень большое количество времени просто на то, чтобы сделать удобной разработку. Kaggle предоставляет возможность создавать jupyter ноутбуки и даже бесплатно запускать их. Они даже дают возможность пользоваться их gpu (30+ часов в неделю). Это прикольно, потому что можно сразу начать что-то делать, но на самом деле это ужасно не удобно.
- Во-первых, все тормозит. Запускаешь клетку ноутбука, ждешь секунду пока она исполнится. С одной стороны можно потерпеть, но с другой — это реально существенно замедляет процесс.
- Во-вторых, когда ноутбук становится длиннее клеток 20, им становится невозможно пользоваться. Начинаешь запускать клетки в неправильном порядке, какие-то инварианты глобальных переменных ломаются, потом очень долго дебажишь.
- В-третьих, нет нормальной возможности сохранить промежуточные данные куда-то на диск. Есть какое-то временное хранилище пока ноутбук работает, но если хочется переиспользовать данные, их нужно скачать/сохранить куда-то отдельно. По умолчанию, максимально ноутбук может работать 9 часов, а потом выключится.
- В-четвертых, нет нормальной возможности версионирования и хранения кода. Пусть у меня есть код, который генерирует какую-то модель, и код, который ее проверяет. На Kaggle это должно быть два отдельных ноутбука, чтобы второй мог использовать модель, который сгенерил первый. Но если я хочу переиспользовать часть кода (например, который считывает данные или считает статистику), его нужно будет скопировать.
- В-пятых, gpu, который Kaggle предоставляет бесплатно, P100, не то чтобы очень крутые.
В общем, если бы я мог путешествовать во времени, и дать себе один совет, это явно был бы "не использовать Kaggle для запуска кода".
Better setup?
Я вряд ли пришел к идеальному варианту, но в итоге получилось так:
- Весь код лежит в репозитории на github.
%load_ext autoreload %autoreload 2
- Редактировал и писал новый код я в основном локально (latency гораздо лучше чем на Kaggle!).
- Чтобы запускать код, я арендовал сервер на https://jarvislabs.ai/
- Сервер с gpu A6000 (у которого 48Gb памяти вместо 16Gb на Kaggle) стоит ~1$/час. В итоге я суммарно потратил где-то 200$, но я не особо пытался экономить.
- У них есть persistent storage, так что если сервер выключить, а потом включить — данные будут на месте.
- На сервер можно заходить по ssh. Оказывается у ssh есть замечательный ключ
-A, который форвардит локальные ключи на сервер, к которому подключаешься. Например, если хочешь выкачать приватный github репозиторий на сервер, но не хочешь добавлять в github профиль ключ с этого сервера, то-Aэто то, что нужно. - Когда все-таки хочется скачать с/на cервер что-то большое, можно пользоваться scp, но он тормозит (видимо потому что сервера стоят где-то в Индии), а хорошо работает Google Drive Cli. Правда безопасность этого решения несколько сомнительная.
- Я не придумал как нормально сабмитить свое решение на Kaggle. Сабмитить нужно один ноутбук, а в репозитории код лежит в нескольких файлах. Если их в тупую собрать в один файл, то могут появиться функции с одинаковыми именами. Или будут какие-то лишние инклуды. В итоге я фиксил это все руками, но скорее всего можно как-то лучше.
Графики!
По жизни я очень люблю визуализировать данные и считаю, что обычно это путь к успеху.
В этот раз я пользовался https://wandb.ai/ и он очень клевый! В нем очень просто логировать данные во время экспериментов, а потом визуализировать и строить дашборды.
Например как-то так выглядели графики с результатами разных моделей:
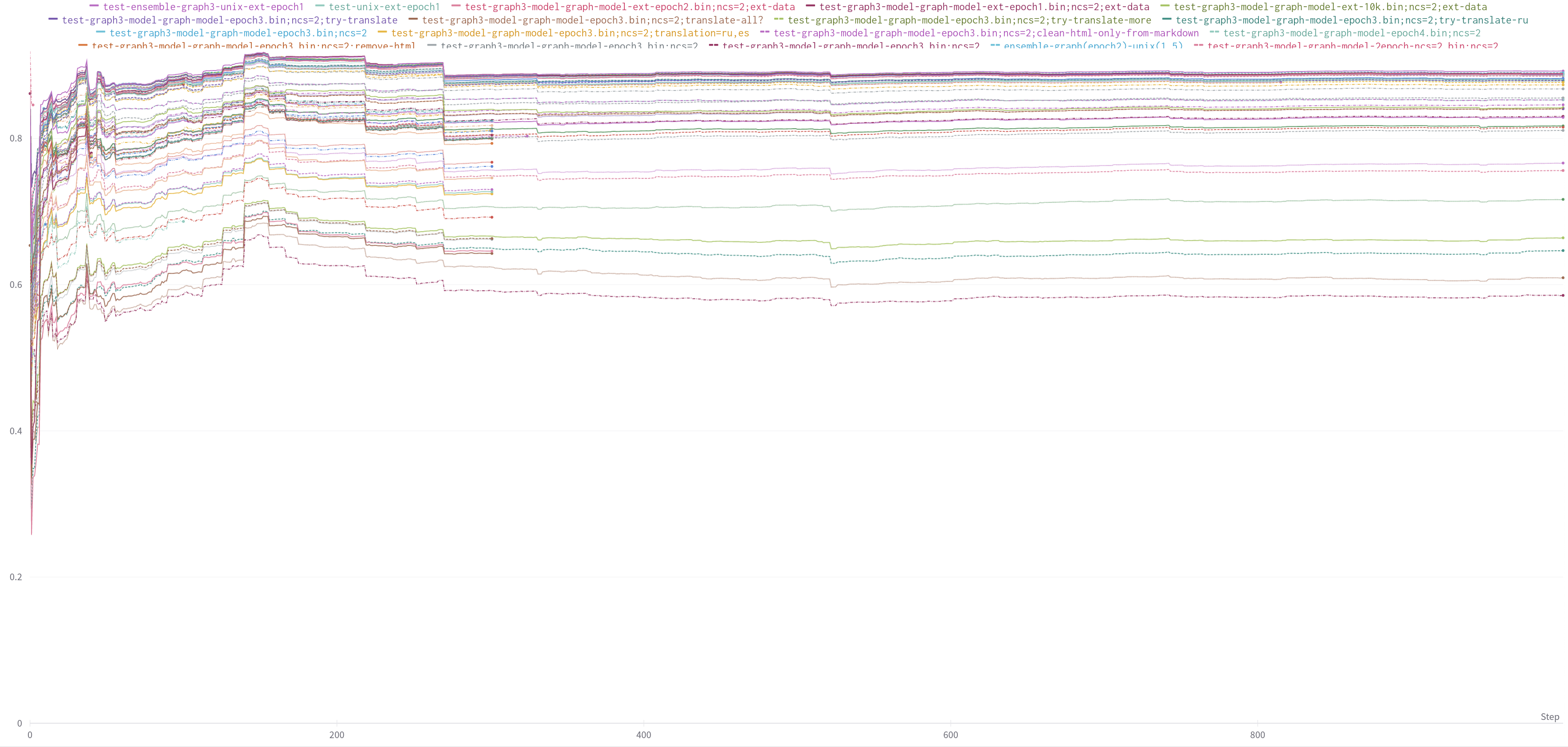
На самом деле он интерактивный и в нем можно что-то понять, честно-честно!

Тут на графике каждая линия — какая-то отдельная модель, которую тестируем. А значение — средний скор модели на Х ноутбуках. "Настоящий" скор модели мы бы получили, если бы посмотрели на значение при X=+infinity, но тестирование довольно долгое, поэтому хочется уметь быстрее понимать, получилась ли модель лучше чем другая.
Посмотрев на такой график можно понять, что тестирование, например, только на 100 ноутбуках, будет работать плохо и данные будут слишком шумные. А вот после 300 ноутбуков, если одна модель показывает результат лучше другой, то и настоящий результат скорее всего будет такой же.
Wandb позволяет строить графики интерактивно, т.е. прямо во время работы программы. Это спасает много времени, когда случайно запустил что-то неправильно, и сразу можешь заметить, что скор уж слишком маленький даже на первых ноутбуках.
А еще иногда можно заметить, что график одной модели в точности совпадает с графиком другой, и понять, что в эксперименте явно что-то пошло не так (например, мы почему-то тестируем другую модель).
В следующей серии?
- Какое в итоге было решение.
- Как я визуализировал данные и ничего полезного из этого не получил :(
- Сколько раз я долго искал какие-то баги, потому что привык к нормальным языкам программирования, а не к питону.
- Как я пробовал сделать что-то более сложное, но ничего не работало :(
Если вы дочитали до сюда, то подписывайтесь на мой канал https://t.me/bminaiev_blog