Машинное зрение на Python. Обучаем нейросеть распознавать цифры
Источник: t.me/Bureau121

Содержание статьи
- Как работает нейронная сеть
- Простейшая нейронная сеть
- Распознавание цифр — сеть MLP
- Распознавание цифр — сверточная сеть (CNN)
Для каждого примера я приведу код на Python 3.7. Ты можешь запустить его и посмотреть, как все это работает. Для запуска примеров потребуется библиотека Tensorflow. Установить ее можно командой pip install tensorflow-gpu, если видеокарта поддерживает CUDA, в противном случае используй команду pip install tensorflow. Вычисления с CUDA в несколько раз быстрее, так что, если твоя видеокарта их поддерживает, это сэкономит немало времени. И не забудь установить наборы данных для обучения сети командой pip install tensorflow-datasets.
Как работает нейронная сеть
Как работает один нейрон? Сигналы со входов (1) суммируются (2), причем каждый вход имеет свой «коэффициент передачи» — w. Затем к получившемуся результату применяется «функция активации» (3).
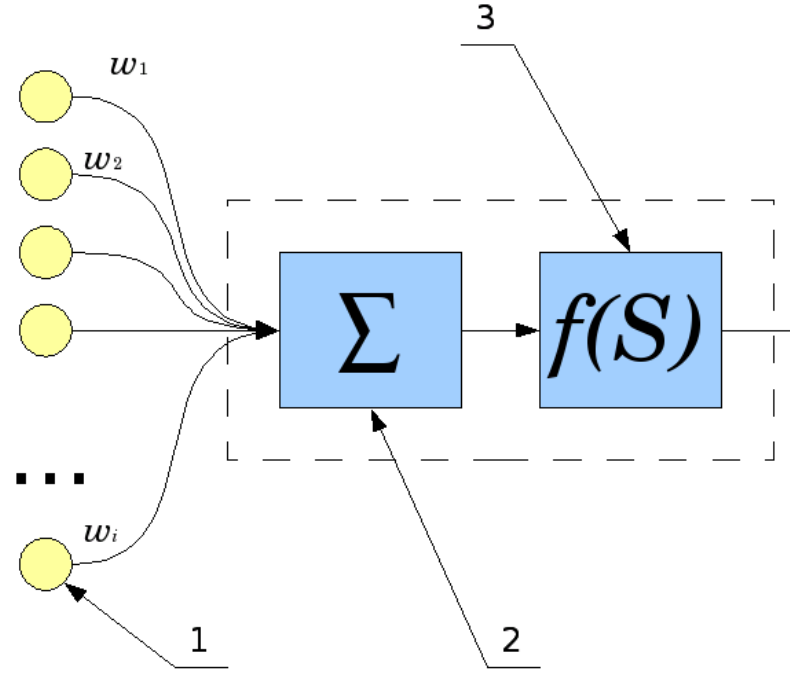
Типы этой функции различны, она может быть:
- прямоугольной (на выходе 0 или 1);
- линейной;
- в виде сигмоиды.
Еще в 1943 году Мак-Каллок и Питтс доказали, что сеть из нейронов может выполнять различные операции. Но сначала эту сеть нужно обучить — настроить коэффициенты w каждого нейрона так, чтобы сигнал передавался нужным нам способом. Запрограммировать нейронную сеть и обучить ее с нуля сложно, но, к счастью для нас, все необходимые библиотеки уже написаны. Благодаря компактности языка Python все действия можно запрограммировать в несколько строк кода.
Рассмотрим простейшую нейросеть и научим ее выполнять функцию XOR. Разумеется, вычисление XOR с помощью нейронной сети не имеет практического смысла. Но именно оно поможет нам понять базовые принципы обучения и использования нейросети и позволит по шагам проследить ее работу. С сетями большей размерности это было бы слишком сложно и громоздко.
Простейшая нейронная сеть
Сначала нужно подключить необходимые библиотеки, в нашем случае это tensorflow. Я также отключаю вывод отладочных сообщений и работу с GPU, они нам не пригодятся. Для работы с массивами нам понадобится библиотека numpy.
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' os.environ["CUDA_VISIBLE_DEVICES"] = "-1" from tensorflow import keras from tensorflow.keras import layers from tensorflow.keras import Sequential from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, Activation, BatchNormalization, AveragePooling2D from tensorflow.keras.optimizers import SGD, RMSprop, Adam import tensorflow_datasets as tfds # pip install tensorflow-datasets import tensorflow as tf import logging import numpy as np tf.logging.set_verbosity(tf.logging.ERROR) tf.get_logger().setLevel(logging.ERROR)
Теперь мы готовы создать нейросеть. Благодаря Tensorflow на это понадобится всего лишь четыре строчки кода.
model = Sequential() model.add(Dense(2, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1))
Мы создали модель нейронной сети — класс Sequential — и добавили в нее два слоя: входной и выходной. Такая сеть называется «многослойный перцептрон» (multilayer perceptron), в общем виде она выглядит так.
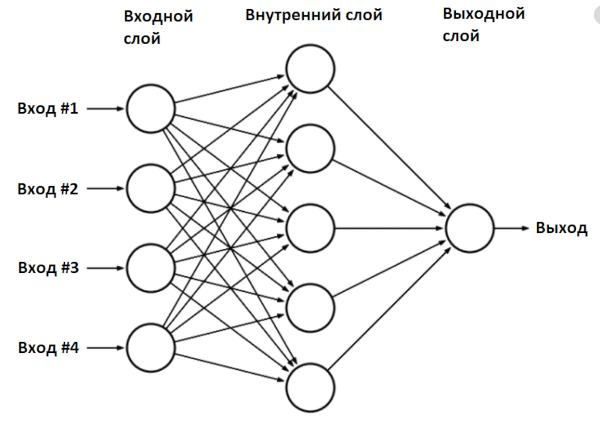
В нашем случае сеть имеет два входа (внешний слой), два нейрона во внутреннем слое и один выход.
Можно посмотреть, что у нас получилось:
print(model.summary())
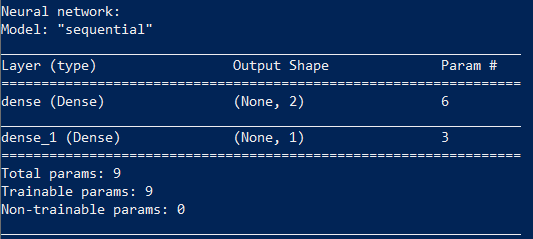
Обучение нейросети состоит в нахождении значений параметров этой сети.
Наша сеть имеет девять параметров. Чтобы обучить ее, нам понадобится исходный набор данных, в нашем случае это результаты работы функции XOR.
X = np.array([[0,0], [0,1], [1,0], [1,1]]) y = np.array([[0], [1], [1], [0]]) model.fit(X, y, batch_size=1, epochs=1000, verbose=0)
Функция fit запускает алгоритм обучения, которое у нас будет выполняться тысячу раз, на каждой итерации параметры сети будут корректироваться. Наша сеть небольшая, так что обучение пройдет быстро. После обучения сетью уже можно пользоваться:
print("Network test:")
print("XOR(0,0):", model.predict_proba(np.array([[0, 0]])))
print("XOR(0,1):", model.predict_proba(np.array([[0, 1]])))
print("XOR(1,0):", model.predict_proba(np.array([[1, 0]])))
print("XOR(1,1):", model.predict_proba(np.array([[1, 1]])))
Результат соответствует тому, чему сеть обучалась.
Network test:
XOR(0,0): [[0.00741202]]
XOR(0,1): [[0.99845064]]
XOR(1,0): [[0.9984376]]
XOR(1,1): [[0.00741202]]
Мы можем вывести все значения найденных коэффициентов на экран.
## Parameters layer 1
W1 = model.get_weights()[0]
b1 = model.get_weights()[1]
## Parameters layer 2
W2 = model.get_weights()[2]
b2 = model.get_weights()[3]
print("W1:", W1)
print("b1:", b1)
print("W2:", W2)
print("b2:", b2)
print()
Результат:
W1: [[ 2.8668058 -2.904025 ] [-2.871452 2.9036295]]
b1: [-0.00128211 -0.00191825]
W2: [[3.9633768] [3.9168582]]
b2: [-4.897212]
Внутренняя реализация функции model.predict_proba выглядит примерно так:
x_in = [0, 1] ## Input X1 = np.array([x_in], "float32") ## First layer calculation L1 = np.dot(X1, W1) + b1 ## Relu activation function: y = max(0, x) X2 = np.maximum(L1, 0) ## Second layer calculation L2 = np.dot(X2, W2) + b2 ## Sigmoid output = 1 / (1 + np.exp(-L2))
Рассмотрим ситуацию, когда на вход сети подали значения [0,1]:
L1 = X1W1 + b1 = [02.8668058 + 1-2.871452 + -0.0012821, 0-2.904025 + 1*2.9036295 + -0.00191825] = [-2.8727343 2.9017112]
Функция активации ReLu (rectified linear unit) — это просто замена отрицательных элементов нулем.
X2 = np.maximum(L1, 0) = [0. 2.9017112]
Теперь найденные значения попадают на второй слой.
L2 = X2W2 + b2 = 03.9633768 +2.9017112*3.9633768 + -4.897212 = 6.468379
Наконец, в качестве выхода используется функция Sigmoid, которая приводит значения к диапазону 0...1:
output = 1 / (1 + np.exp(-L2)) = 0.99845064
Мы совершили обычные операции умножения и сложения матриц и получили ответ: XOR(0,1) = 1.
С этим примером на Python советую поэкспериментировать самостоятельно. Например, ты можешь менять число нейронов во внутреннем слое. Два нейрона, как в нашем случае, — это самый минимум, чтобы сеть работала.
Но алгоритм обучения, который используется в Keras, не идеален: нейросети не всегда удается обучиться за 1000 итераций, и результаты не всегда верны. Так, Keras инициализирует начальные значения случайными величинами, и при каждом запуске результат может отличаться. Моя сеть с двумя нейронами успешно обучалась лишь в 20% случаев. Неправильная работа сети выглядит примерно так:
XOR(0,0): [[0.66549516]]
XOR(0,1): [[0.66549516]]
XOR(1,0): [[0.66549516]]
XOR(1,1): [[0.00174837]]
Но это не страшно. Если видишь, что нейронная сеть во время обучения не выдает правильных результатов, алгоритм обучения можно запустить еще раз. Правильно обученную сеть потом можно использовать без ограничений.
Можно сделать сеть поумнее: использовать четыре нейрона вместо двух, для этого достаточно заменить строчку кода model.add(Dense(2, input_dim=2, activation='relu')) на model.add(Dense(4, input_dim=2, activation='relu')). Такая сеть обучается уже в 60% случаев, �� сеть из шести нейронов обучается с первого раза с вероятностью 90%.
Все параметры нейронной сети полностью определяются коэффициентами. Обучив сеть, можно записать параметры сети на диск, а потом использовать уже готовую обученную сеть. Этим мы будем активно пользоваться.
Распознавание цифр — сеть MLP
Рассмотрим практическую задачу, вполне классическую для нейронных сетей, — распознавание цифр. Для этого мы возьмем уже известную нам сеть multilayer perceptron, ту же самую, что мы использовали для функции XOR. В качестве входных данных будут выступать изображения 28 × 28 пикселей. Такой размер выбран потому, что существует уже готовая база рукописных цифр MNIST, которая хранится именно в таком формате.
Для удобства разобьем код на несколько функций. Первая часть — это создание модели.
def mnist_make_model(image_w: int, image_h: int): # Neural network model model = Sequential() model.add(Dense(784, activation='relu', input_shape=(image_w*image_h,))) model.add(Dense(10, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) return model
На вход сети будет подаваться image_w*image_h значений — в нашем случае это 28 × 28 = 784. Количество нейронов внутреннего слоя такое же и равно 784.
С распознаванием цифр есть одна особенность. Как мы видели в предыдущем примере, выход нейросети может лежать в диапазоне 0…1, а нам нужно распознавать цифры от 0 до 9. Как быть? Чтобы распознавать цифры, мы создаем сеть с десятью выходами, и единица будет на выходе, соответствующем нужной цифре.

Структура отдельного нейрона настолько проста, что для его использования даже не обязателен компьютер. Недавно ученые смогли реализовать нейронную сеть, аналогичную нашей, в виде куска стекла — такая сеть не требует питания и вообще не содержит внутри ни одного электронного компонента.
Когда нейронная сеть создана, ее надо обучить. Для начала необходимо загрузить датасет MNIST и преобразовать данные в нужный формат.
У нас есть два блока данных: train и test — один служит для обучения, второй для верификации результатов. Это общепринятая практика, обучать и тестировать нейронную сеть желательно на разных наборах данных.
def mnist_mlp_train(model):
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# x_train: 60000x28x28 array, x_test: 10000x28x28 array
image_size = x_train.shape[1]
train_data = x_train.reshape(x_train.shape[0], image_size*image_size)
test_data = x_test.reshape(x_test.shape[0], image_size*image_size)
train_data = train_data.astype('float32')
test_data = test_data.astype('float32')
train_data /= 255.0
test_data /= 255.0
# encode the labels - we have 10 output classes
# 3 -> [0 0 0 1 0 0 0 0 0 0], 5 -> [0 0 0 0 0 1 0 0 0 0]
num_classes = 10
train_labels_cat = keras.utils.to_categorical(y_train, num_classes)
test_labels_cat = keras.utils.to_categorical(y_test, num_classes)
print("Training the network...")
t_start = time.time()
# Start training the network
model.fit(train_data, train_labels_cat, epochs=8, batch_size=64,
verbose=1, validation_data=(test_data, test_labels_cat))
Готовый код обучения сети:
model = mnist_make_model(image_w=28, image_h=28)
mnist_mlp_train(model)
model.save('mlp_digits_28x28.h5')
Создаем модель, обучаем ее и записываем результат в файл.
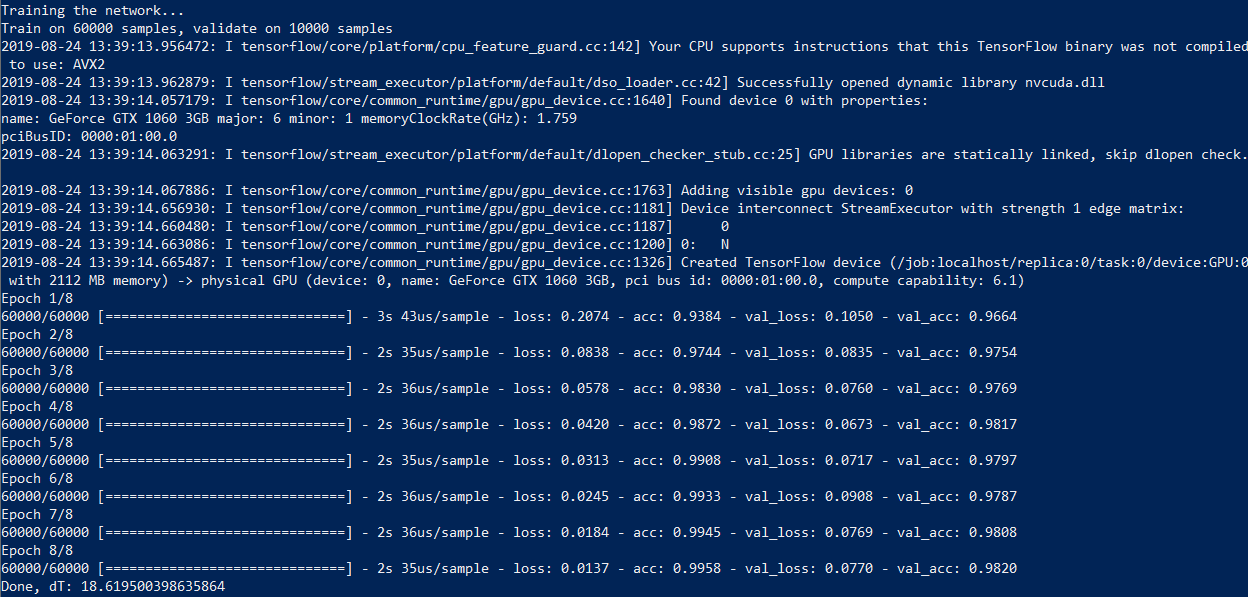
На моем компьютере c Core i7 и видеокартой GeForce 1060 процесс занимает 18 секунд и 50 секунд с расчетами без GPU — почти втрое дольше. Так что, если ты захочешь экспериментировать с нейронными сетями, хорошая видеокарта весьма желательна.
Теперь напишем функцию распознавания картинки из файла — то, для чего эта сеть и создавалась. Для распознавания мы должны привести картинку к такому же формату — черно-белое изображение 28 на 28 пикселей.
def mlp_digits_predict(model, image_file): image_size = 28 img = keras.preprocessing.image.load_img(image_file, target_size=(image_size, image_size), color_mode='grayscale') img_arr = np.expand_dims(img, axis=0) img_arr = 1 - img_arr/255.0 img_arr = img_arr.reshape((1, image_size*image_size)) result = model.predict_classes([img_arr]) return result[0]
Теперь использовать нейронную сеть довольно просто. Я создал в Paint пять изображений с разными цифрами и запустил код.
model = tf.keras.models.load_model('mlp_digits_28x28.h5')
print(mlp_digits_predict(model, 'digit_0.png'))
print(mlp_digits_predict(model, 'digit_1.png'))
print(mlp_digits_predict(model, 'digit_3.png'))
print(mlp_digits_predict(model, 'digit_8.png'))
print(mlp_digits_predict(model, 'digit_9.png'))

Результат, увы, неидеален: 0, 1, 3, 6 и 6. Нейросеть успешно распознала 0, 1 и 3, но спутала 8 и 9 с цифрой 6. Разумеется, можно изменить число нейронов, число итераций обучения. К тому же эти цифры не были рукописными, так что стопроцентный результат нам никто не обещал.
Вот такая нейронная сеть с дополнительным слоем и большим числом нейронов корректно распознает цифру восемь, но все равно путает 8 и 9.
def mnist_make_model2(image_w: int, image_h: int):
# Neural network model
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=(image_w*image_h,)))
model.add(Dropout(0.2)) # rate 0.2 - set 20% of inputs to zero
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(),
metrics=['accuracy'])
return model
При желании можно обучать нейронную сеть и на своем наборе данных, но для этого данных нужно довольно много (MNIST содержит 60 тысяч образцов цифр). Желающие могут поэкспериментировать самостоятельно, а мы пойдем дальше и рассмотрим сверточные сети (CNN, Convolutional Neural Network), более эффективные для распознавания изображений.
Распознавание цифр — сверточная сеть (CNN)
В предыдущем примере мы использовали изображение 28 × 28 как простой одномерный массив из 784 цифр. Такой подход, в принципе, работает, но начинает давать сбои, если изображение, например, сдвинуто. Достаточно в предыдущем примере сдвинуть цифру в угол картинки, и программа уже не распознает ее.
Сверточные сети в этом плане гораздо эффективнее — они используют принцип свертки, по которому так называемое ядро (kernel) перемещается вдоль изображения и выделяет ключевые эффекты на картинке, если они есть. Затем полученный результат сообщается «обычной» нейронной сети, которая и выдает готовый результат.
def mnist_cnn_model():
image_size = 28
num_channels = 1 # 1 for grayscale images
num_classes = 10 # Number of outputs
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3,3), activation='relu',
padding='same',
input_shape=(image_size, image_size, num_channels)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu',
padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu',
padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
# Densely connected layers
model.add(Dense(128, activation='relu'))
# Output layer
model.add(Dense(num_classes, activation='softmax'))
model.compile(optimizer=Adam(), loss='categorical_crossentropy',
metrics=['accuracy'])
return model
Слой Conv2D отвечает за свертку входного изображения с ядром 3 × 3, а слой MaxPooling2D выполняет downsampling — уменьшение размера изображения. На выходе сети мы видим уже знакомый нам слой Dense, который мы использовали ранее.
Как и в предыдущем случае, сеть вначале надо обучить, и принцип здесь тот же самый, за тем исключением, что мы работаем с двумерными изображениями.
def mnist_cnn_train(model):
(train_digits, train_labels), (test_digits, test_labels) = keras.datasets.mnist.load_data()
# Get image size
image_size = 28
num_channels = 1 # 1 for grayscale images
# re-shape and re-scale the images data
train_data = np.reshape(train_digits, (train_digits.shape[0], image_size, image_size, num_channels))
train_data = train_data.astype('float32') / 255.0
# encode the labels - we have 10 output classes
# 3 -> [0 0 0 1 0 0 0 0 0 0], 5 -> [0 0 0 0 0 1 0 0 0 0]
num_classes = 10
train_labels_cat = keras.utils.to_categorical(train_labels, num_classes)
# re-shape and re-scale the images validation data
val_data = np.reshape(test_digits, (test_digits.shape[0], image_size, image_size, num_channels))
val_data = val_data.astype('float32') / 255.0
# encode the labels - we have 10 output classes
val_labels_cat = keras.utils.to_categorical(test_labels, num_classes)
print("Training the network...")
t_start = time.time()
# Start training the network
model.fit(train_data, train_labels_cat, epochs=8, batch_size=64,
validation_data=(val_data, val_labels_cat))
print("Done, dT:", time.time() - t_start)
return model
Все готово. Мы создаем модель, обучаем ее и записываем модель в файл:
model = mnist_cnn_model()
mnist_cnn_train(model)
model.save('cnn_digits_28x28.h5')
Обучение нейронной сети с той же базой MNIST из 60 тысяч изображений занимает 46 секунд с использованием Nvidia CUDA и около пяти минут без нее.
Теперь мы можем использовать нейросеть для распознавания изображений:
def cnn_digits_predict(model, image_file):
image_size = 28
img = keras.preprocessing.image.load_img(image_file,
target_size=(image_size, image_size), color_mode='grayscale')
img_arr = np.expand_dims(img, axis=0)
img_arr = 1 - img_arr/255.0
img_arr = img_arr.reshape((1, 28, 28, 1))
result = model.predict_classes([img_arr])
return result[0]
model = tf.keras.models.load_model('cnn_digits_28x28.h5')
print(cnn_digits_predict(model, 'digit_0.png'))
print(cnn_digits_predict(model, 'digit_1.png'))
print(cnn_digits_predict(model, 'digit_3.png'))
print(cnn_digits_predict(model, 'digit_8.png'))
print(cnn_digits_predict(model, 'digit_9.png'))
Результат гораздо точнее, что и следовало ожидать: [0, 1, 3, 8, 9].
Все готово! Теперь у тебя есть программа, умеющая распознавать цифры. Благодаря Python работать код будет где угодно — на операционных системах Windows и Linux. При желании можешь запустить его даже на Raspberry Pi.
Ты наверняка хочешь знать, можно ли распознавать буквы аналогичным способом? Да, придется только увеличить число выходов сети и найти подходящий набор картинок для обучения.
Надеюсь, у тебя достаточно информации для экспериментов. К тому же с реальным примером перед глазами разбираться значительно проще!