The Unified Star Schema
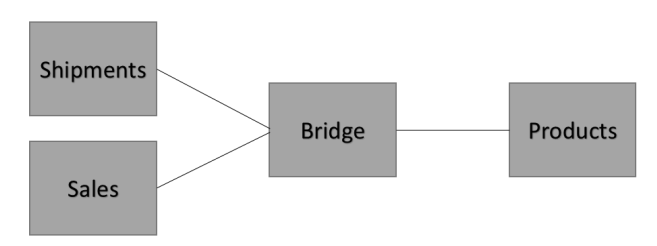
Универсальная Звезда (Unified Star Schema, USS) — это по сути схема Звезда, в центре которой находится не таблица фактов, а Мост — таблица связей (Bridge или Link Table).
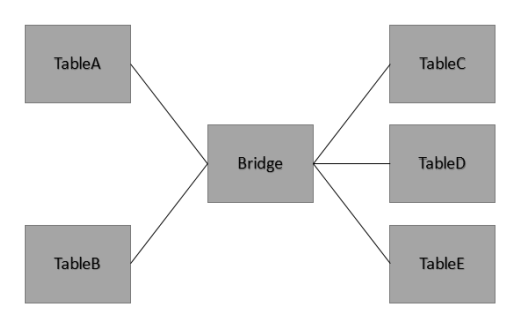
Мост соединяет между собой различные таблицы фактов, например: Продажи, Остатки, Планы, Платежи и т.д. Обычно в схеме Звезда для этого требуется джойнить эти таблицы, чтобы получить одну таблицу фактов. Это чревато появлением дубликатов. Таблица связей позволяет избежать такой проблемы.
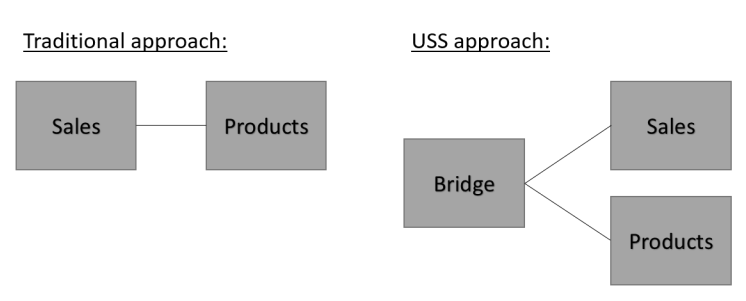
Все связи — только через Мост
Основной принцип USS — две таблицы никогда не соединяются между собой напрямую — только через Таблицу Связей.
Каждая таблица должна иметь свой первичный ключ
Первичный ключ должен уникально идентифицировать запись таблицы. Если его нет — то следует создать суррогатный первичный ключ. Например, хешировать значения из составного первичного ключа (из нескольких полей).
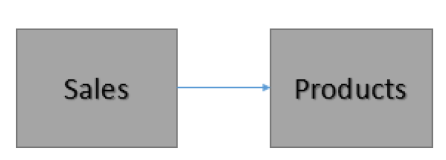
Связи всегда имеют направление
Одна таблица является основной, а вторая — подчиненной.
Проблема циклических ссылок
Такой тип связи создает неопределенность и приводит к ошибкам в BI-системах.
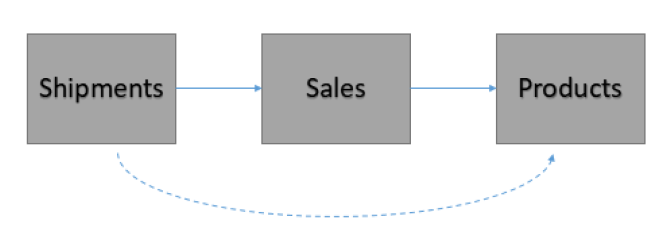
Можно, конечно, пожертвовать одним внешним ключом. Например, удалить Код продукта из таблицы Отгрузок. Но в этом случае мы можем потерять часть информации. Теоретически, что мы продали, то и должны отгрузить, но реальная жизнь бывает интереснее :)
Таблица связей решает проблему циклических ссылок, и не нужно жертвовать каким-то внешним ключом.
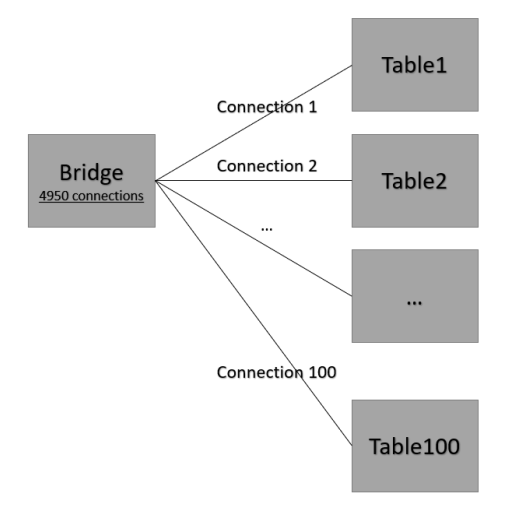
Такой подход может масштабироваться, независимо от количества таблиц в модели данных и количества их связей. Вся эта сложность может быть успешно представлена внутри Таблицы связей. Так например, если в модели данных 100 таблиц, то Мост может хранить до 100 * 99 / 2 = 4 950 связей.
Проблема JOIN-ов — потеря информации
Если мы делаем LEFT, RIGHT или INNER JOIN, мы вынуждены пожертвовать частью информации.
Для примера возьмем две таблицы: Продажи и Продукты.
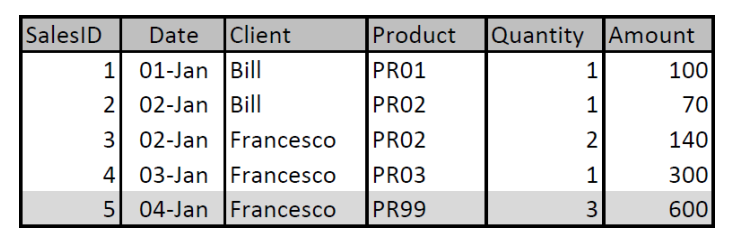

Тут явно нарушена целостность. Продажи содержат ссылку на продукт PR99, которого нет в справочнике Продуктов. Кроме этого можно заметить, что не все продукты продавались. Так продукта PR04 нет в таблице Продажи.
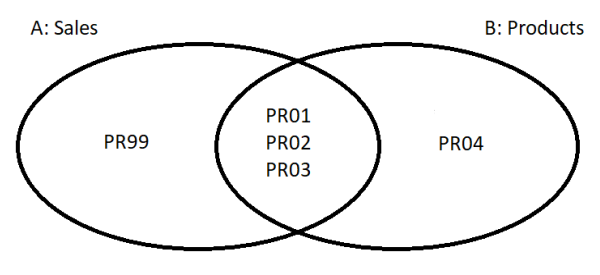
INNER JOIN этих двух таблиц приведет к тому, что мы потеряем информацию о продажах продукта PR99 сумма по полю Amount (количество) не будет отражать действительность. Результат будет отражать только общие записи двух таблиц.

LEFT JOIN приведет к тому, что мы сохраним все строки таблицы Продажи, но потеряем продукт PR04.
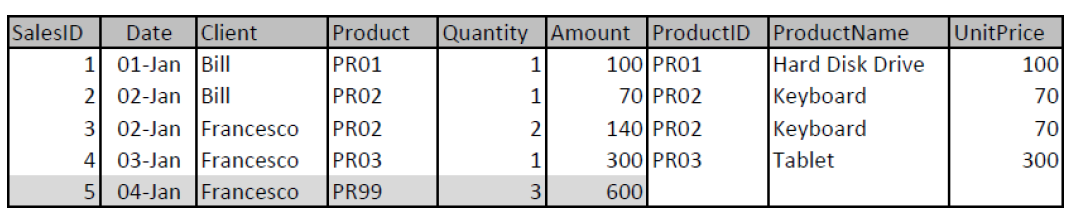
RIGHT JOIN, наоборот, сохранит все строки из таблицы Продукты, но приведет к потере записи о продажах PR99.
FULL OUTER JOIN — только он не приведет к потере данных. Но результирующая таблица выглядит весьма странно.
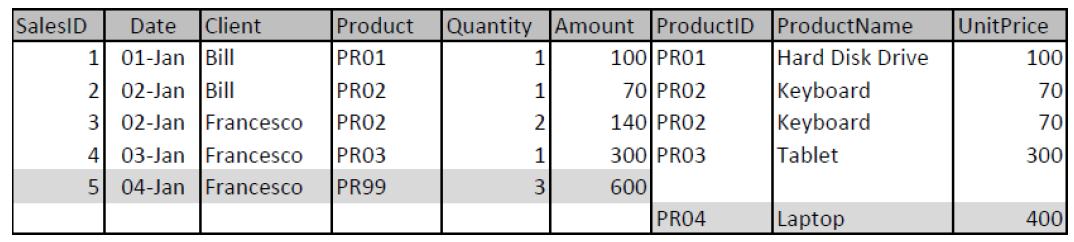
Вывод — какой тип JOIN-а применить, а значит, какими записями пожертвовать, зависит от конкретных бизнес-требований к результату вычислений. То есть,
на этапе проектирования модели данных уже должны быть известны конкретные бизнес-требования.

Это накладывает свои ограничения. Мы не можем сделать универсальную модель, используя JOIN-ы. Мы можем проектировать модель данных только под конкретную задачу.
Подход USS позволяет преодолеть это ограничение, поскольку то как мы связываем таблицы не зависит от бизнес-требований.