Алгоритмы и структура данных (АСД).
Преподаватель - Гатауллин Раил Маулетович
Студент - Латышов Данила Сергеевич
Алгоритмы
Информация - сведение, независимое от типов данных. Информация бывает аналоговой и цифровой.
Данные - сведение для вывода, решения
Алгоритмы – это конечный набор инструкций на определенном языке, который описывает последовательность выполнимых и определенных шагов для решения задачи. Они применимы к разным входным данным
Алгоритм всегда должен завершаться после выполнения конечного числа шагов. Это означает, что он не бесконечно продолжается, а имеет четкую точку завершения.
Каждый шаг алгоритма должен быть четко определен и иметь однозначное значение. Это означает, что действия, которые нужно выполнить, не могут иметь двусмысленных интерпретаций.
Алгоритм имеет некоторое число входных данных, которые задаются до начала его работы или динамически определяются во время выполнения. Простыми словами, алгоритму нужно знать, с чем он будет работать.
У алгоритма есть одно или несколько выходных данных, которые связаны с входными данными.
Эффективность алгоритма определяется тем, насколько простыми являются его операторы. Если мы можем точно выполнить эти операторы с помощью карандаша и бумаги в течение ограниченного времени, то алгоритм считается эффективным.
Псевдокод — это способ описания алгоритмов и структур данных с использованием естественного языка и элементов программирования. Он позволяет выразить основные идеи без деталей реализации. Проще говоря, это “черновик” для программы, который помогает программистам понять, как решить задачу, не вдаваясь в код.
Используйте арифметические операции, чтобы вычислить значения.
Определите функции или методы для выполнения конкретных задач.
3. Структура принятия решений:
Используйте условные операторы (if-else) для выбора разных путей в зависимости от условий.
Используйте циклы (например, for или while) для повторения действий.
Обращайтесь к элементам массива по индексу.
Вызывайте методы объектов для выполнения определенных действий.
7. Возвращаемое значение метода:
Убедитесь, что ваши методы возвращают нужные значения.
Давайте подробнее разберемся с алгоритмом нахождения наибольшего общего делителя (НОД) для двух натуральных чисел N и M.
Пусть P будет минимальным из чисел N и M. Это позволяет сократить диапазон поиска общих делителей.
Устанавливаем t равным 1. Начальное значение НОД.
Если P равно 1, переходим к шагу 5. В противном случае переходим к шагу 4.
Задаем i последовательностью всех целых чисел от 2 до P.
По возрастанию проверяем каждое i: Если M делится на i без остатка (M % i == 0) и N делится на i без остатка (N % i == 0), то обновляем t: t = i. Это означает, что i является общим делителем для N и M.
Результатом НОД будет значение t.
Пример: Пусть N = 12 и M = 18.
P = min(12, 18) = 12.
t = 1 (начальное значение).
Проверяем i от 2 до 12:i = 2: 12 % 2 == 0 и 18 % 2 == 0, обновляем t: t = 2.
i = 3: 12 % 3 == 0 и 18 % 3 == 0, обновляем t: t = 3.
i = 4: 12 % 4 == 0 и 18 % 4 != 0 (не делится на 4).
…
i = 12: 12 % 12 == 0 и 18 % 12 == 0, обновляем t: t = 12.
НОД(12, 18) = 6 (так как 6 - наибольший общий делитель).
Этот алгоритм помогает найти наибольший общий делитель двух чисел, используя поиск общих делителей и выбор наибольшего из них.
Типы данных. Простейшие стандартные типы данных.
Тип данных - это набор значений и операций, которые можно проводить над этими значениями.
1. Любой тип данных определяет множество значений, к которым может относится некоторая константа, принимающая переменную им выражении, которая может формироваться функцией им операции
2. Тип любой величины, обозначаемой константой, выражением может быть этого нет необходимости проводить какие-либо вычисления
3. Каждая операция или функция требует аргументом определенного типа и дает результат также фиксированного типа. Если операцию допускают аргументы нескольких типов, то тип результата регламентируется вполне определенным правилам языка.
Любой новый простейший тип определяется простым перечислением, входящих в него. Такой тип называемым перечисляемым.
YPE T = (C1, C2, …, CM)
T — индификатор нового типа C1, C2, …, CM индикаторы новых констант
card(T) = 1 — мощность
Стандартным простым типом данных называют типы данных, которые встроены на большинстве вычислительных машин (целые числа, вещественные числа, логические значения и множество символов).
Это числа без десятичных знаков. Диапазон этих чисел зависит от количества бит, выделенных под их хранение. Если используется n бит, то диапазон будет от −2^(n−1) до 2^(n−1)−1. Операции над данными этого типа точны и следуют арифметическим правилам. Если результат выходит за допустимые пределы, происходит переполнение и вычисления останавливаются.
Это числа с десятичной частью. Они используются для представления дробных значений, но при этом могут иметь ошибки округления.
Имеет только два значения - True (истина) и False (ложь). Используется для логических операций.
Представляет собой одиночные символы. Стандарт ASCII был принят для кодировки этих символов, но сейчас часто используются utf-8, utf-16, utf-64.
Это типы данных с определенным диапазоном значений. Например, TYPE T = [MIN, MAX].
Это структура данных, которая содержит элементы одного типа. Каждый элемент можно получить по его индексу. Например, TYPE T = ARRAY[N] OF REAL.
Это составные типы данных, которые могут содержать элементы различных типов.
Это тип данных, который может содержать уникальные элементы определенного типа. Например, TYPE T = SET OF T0.
Последовательности (sequence):
Это тип данных, который содержит упорядоченный набор элементов.
Это последовательности символов. Например, Type T = String(T0).
Тип Integer включает некоторые подмножества целых чисел, размер которого варьируется от машине к машине.
Если для представления целых чисел в машине используется n разрядов включая кокой-то код, то допустимые числа должны удовлетворять условию:
-2 ** (n-1) ≤ x ≤ 2 ** (n - 1)
Все операции над данными этого типа выполняются в точности и соответствуют обычным правилам арифметических операций. Если результат выходит за пределы памяти множества, то вычисления будут прерваны.
Тип Real обозначает подмножество вещественных чисел. При использовании этого типа данных допускается предел ошибок округлений, вызванных вычислениями с конечным числом цикла
Тип Boolean. У него есть 2 значения, которые обозначаются индикаторами True & False.
1. Логическая конъюкция
2. Дизъюнкция
. Отрицание

В стандартный тип Char входит множество печатных символов. В международной стандартной организации был принят стандарт кодировки ASCII. Но сейчас UTF-8.
Ограниченные типы данных: Это типы данных с определенным диапазоном значений. Например, TYPE T = [MIN, MAX].
Тип данных ARRAY Массив(структура). Массив состоит из компонентов, называемых базовым. кроме того массивы относят к структурам со случайным доступом для того, чтобы обозначить отдельную компоненту к имени всего массива добавляется индекс.
Индекс — значение специального типа определенного как тип индекса данного массива.
TYPE T = ARRAY[I] of TO
Мощность массового типа, т.е. число величин, принадлежащих типов есть произведение мощностей его компонентов
Тип записи RECORD. Для получения составных типов, объединения элемента произвольных типов используется RECORD. Эти элементы в свою очередь тоже могут быть составными.
TYPE T = SET of TO
Возможными значениями некоторой переменной типа Т будут множества элементов типа Т0. Множества всех подмножеств из элементов множество Т0 наз множеством степенью Т0.
Мощность множественного типа Т = 2 ** card(T0)
Тип Последовательности. SEQUENCE.
T = SEQUENCE of T0
Его элементы имеют порядок
TYPE T = STRING of T0
Тип STEC
Алгоритмы поиска
В программировании одной из наиболее часто встречающихся задач является поиск. При решении таких задач мы исходим из предположения, что группа данных, в которой необходимо найти заданный элемент, является фиксированной.
Пример: Пусть задан массив изnэлементовarray[0...n-1]. Обычноitemsописывает запись с некоторым полем, выполняющим роль ключа. Задача заключается в поиске элемента, ключ которого равен заданному аргументу поискаx(a[i], key = x). Полученный в результатеi, удовлетворяющий условиюa[i] = key = x, обеспечивает доступ к другим полям обнаруженного элемента. Так как нас интересует в первую очередь сам процесс поиска, а не обнаруженные данные, то мы будем считать, что типitemвключает только ключ (item = key).
Линейный поиск заключается в простом последовательном просмотре массива с увеличением шаг за шагом той его части, где желаемый элемент не обнаружен.Условием окончания поиска является: а)Элемент найден б)Весь массив просмотрен и совпадений не обнаружены. В логическом выражении порядок элементов имеет значения

#include <iostream>
using namespace std;
int lin_poisk(int arr[], int n, int x)
{
for (int i = 0; i < n; i++)
if (arr[i] == x)
return i;
return -1;
}
int main()
{
setlocale(LC_ALL, "Rus");
const int n = 20;
int arr[n] = { 1,2,3,4,5,6,7,8,9,10,20,30,40 };
int x;
cout << "Введите элемент: ";
cin >> x;
int res = lin_poisk(arr, n, x);
if (res != -1)
cout << "Элемент находится в массиве под индексом: " << res;
else
cout << "Элемент не найден в массиве";
return 0;
}При линейном поиске на каждом шаге требуется увеличивать индекс и вычислять логическое выражение. Чтобы ускорить поиск можно упростить само логическое выражение, то есть сформулировать простое условае эквивалентное сложному. Это можно сделать, если мы гарантируем, что совпадение всегда произойдет. Для этого в конец массива достаточно поместить дополнительный элемент x. Такой вспомогательный элемент называется барьером. Он охраняет нас от перехода за пределы массива.Алгоритм линейного поиска с барьером выглядит следующим образом:
Для рассмотрения алгоритма мы будем считать, что массив будет заранее упорядочен, то есть удовлетворяет условию1 <= k < N; a[k-1] <= a[k]. Основная идея алгоритма выбрать некоторый элемент, предположимa[m]и сравнить его с аргументом поискаx. Если он равенx, то поиск заканчивается. Если меньшеx, то мы заключаем, что все элементы с индексами<= mможно исключить из дальнейшего поиска. Это соображение приводит нас к алгоритму, который называется поиск делением пополам. Этот метод использует преимущество отсортированного массива, чтобы ускорить поиск. Он выбирает элемент в середине массива и сравнивает его с искомым. Если элемент в середине меньше искомого, то поиск продолжается в правой половине массива. Если элемент в середине больше искомого, то поиск продолжается в левой половине массива. Этот процесс повторяется, пока не будет найден искомый элемент или пока не останется непроверенных элементов.
Эффективность алгоритма можно несколько улучшить, если поменять местами заголовки условных операторов. Проверку на равенство можно выполнить во вторую очередь, так как она встречается лишь единожды и приводит к окончанию работы.

#include <iostream>
using namespace std;
int binar_poisk(int arr[], int lev_gran, int prav_gran, int x)
{
int centr = 0;
while (1)
{
centr = (lev_gran + prav_gran) / 2;
if (x < arr[centr])
prav_gran = centr - 1;
else if (x > arr[centr])
lev_gran = centr + 1;
else
return centr;
if (lev_gran > prav_gran)
return -1;
}
}
int main()
{
setlocale(LC_ALL, "rus");
const int n = 15;
int arr[n] = {};
for (int i = 0; i < n; i++)
{
arr[i] = i + 1;
cout << arr[i] << " ";
}
cout << endl;
int x;
cout << "Введите элемент: ";
cin >> x;
int res = binar_poisk(arr, 0, n, x);
if (res >= 0)
cout << "Элемент находится в массиве под индексом: " << res;
else
cout << "Элемент не найден в массиве";
return 0;
}
Поиск в массиве = поиск в таблице. Особенно если ключ сам является составным объектом, таким как массив чисел или массив символов. Часто встречается поиск символов, когда массив символов называют строками или словами. Строковый тип определяется так,string = char arr[0...n-1]. Для установки факта совпадения, мы должны убедиться, что все символы сравниваемых строк соответственно равны один к другому, поэтому сравнение составных операндов сводится к поиску их на неравенство. Если нет не равных частей, то это равенство. Чаще всего используется 2 представления о размерах строк. 1) Размер указывается неявно, благодаря добавлению кольцевого символа, который больше нигде не употребляется. Обычно используется непечатаемый символ со значением0C('/0') (минимальный символ из всех символов). 2) Размер явно хранится в качестве первого элемента массива, то есть строкаsимеет видs = s0, s1, ..., s(n-1). Эти символы являются фактическими в строке, аs0 = char(n)(определяет размер строки). Этот метод аналогичен поиску в массиве, но применяется к строкам. Здесь мы ищем подстроку в строке, сравнивая каждый символ подстроки с соответствующим символом строки.
Задача: упорядоченная таблицаT(в алфавитном порядке); Аргумент поиска =x(string);T = string arr[0...n-1].Nдостаточно велико.
#include <iostream>
using namespace std;
int poisk_tabl(string arr[], int lev_gran, int prav_gran, string x)
{
int centr = 0;
while (1)
{
centr = (lev_gran + prav_gran) / 2;
if (x < arr[centr])
prav_gran = centr - 1;
else if (x > arr[centr])
lev_gran = centr + 1;
else
return centr;
if (lev_gran > prav_gran)
return -1;
}
}
int main()
{
setlocale(LC_ALL, "rus");
int const n = 9;
string arr[n] = { "a","b","c","d","e" };
string x;
cout << "Введите элемент: ";
cin >> x;
int res = poisk_tabl(arr, 0, n, x);
if (res >= 0)
cout << "Элемент находится в массиве под индексом: " << res;
else
cout << "Элемент не найден в массиве";
return 0;
}Пусть задан массив s из n элементов. И задан массив p из m элементов. 0 < m <= n. s: array[0...n-1] of item, p: array[0...n-1] of item. Поиск строки обнаруживает первое вхождение p в s. Обычно item это символы, то есть их можно считать некоторым текстом, а p является образом или словом. Мы хотим найти первое вхождение в слово. Рассмотрим прямолинейный поиск алгоритма. Поиск можно представить, как повторяющие сравнения. Этот метод ищет первое вхождение подстроки в строке, сравнивая каждый символ подстроки с соответствующим символом строки.
#include <iostream>
using namespace std;
int main()
{
setlocale(LC_ALL, "rus");
string P = "yes";
string T = "net da yes no";
int M = P.size();
int N = T.size();
bool found = false;
for (int i = 0; i <= N - M && !found; i++)
{
int j = 0;
while (j < M && T[i + j] == P[j])
{
j++;
}
if (j == M)
{
found = true;
cout << "Строка найдена на позиции: " << i << endl;
}
}
if (!found)
{
cout << "Строка не найдена." << endl;
}
}6) Прямолинейный алгоритм поиска
Поиск можно представить как повторяющееся сравнение.

Алгоритм поиска Кнута Мориса Пратта (алгоритм КМП)
Алгоритм Кнутта-Морриса-Пратта (KMP) - это алгоритм поиска подстроки, который использует принцип сдвига образа для ускорения поиска. Он состоит из двух этапов:
Формирование таблицы D: Эта таблица создается на основе образа (подстроки, которую мы ищем) и используется для определения величины сдвига образа при поиске. Размер таблицы равен длине образа.
Поиск образа в строке: На этом этапе мы сравниваем символы образа и строки. Если символы не совпадают, образ сдвигается вправо.
Таблица d формируется на основе образа и содержит значения, которые в дальнейшем будут использованы при вычислении величины сдвига образа. Размер данной таблицы равен длине образа, то есть таблица d фактически является одномерным массивом. Первый элемент массива d всегда равен -1. Всё элементы массива, соответствующие символам одинаковым первому символу образа, также приравниваются к -1.
Для остальных символов образа значений элементов массива вычисляется следующим образом: значение d[j], соответствующие j-тому символу образа равно максимальному числу символов, непосредственно предшествующих данному символу, совпадающих с началом образа. При этом, если рассматриваемую символу предшествуют k символов, то во внимание принимаются только k-1 предшествующих символов.
Вывод: значение массива d определяется лишь образом и не зависит от строки текста. Для определения значения элементов массива d необходимо найти самую длинную последовательность символов образа, непосредственно предшествующих позиции j, которое совпадает полностью с началом образа, так как эти значения зависят только от образа.
Перед началом поиска необходимо вычислить элементы массива d.
Вторым этапом работы КМП алгоритма является сравнение символов образа и строки и вычисление сдвига образа в случае их несовпадения. Символы образа рассматриваются слева направо, то есть от начала к концу образа. При несовпадении символов образа и строки образ сдвигается вправо по строке. Величина сдвига вычисляется следующим образом: если при переборе символов образа используется индекс j, то сдвиг образа происходит на j-d[j] символов.


Алгоритм Бойера-Мура улучшает поиск символов в тексте, используя только ( M + N ) сравнений, где ( M ) - длина шаблона, а ( N ) - длина текста. Это более эффективно, чем ( M * N ) сравнений, необходимых для прямого поиска. Проще говоря, алгоритм Бойера-Мура быстрее находит, где шаблон появляется в тексте, минимизируя количество сравнений.
Давайте рассмотрим пример работы алгоритма Кнутта-Морриса-Пратта (KMP) на примере поиска образа “ABABCABAB” в тексте “ABABDABACDABABCABAB”.
Формирование таблицы D: На этом этапе мы создаем таблицу на основе образа. В нашем случае, образ - это “ABABCABAB”. Таблица D будет выглядеть так: [-1, 0, 0, 1, 2, 0, 1, 2, 3]. Эта таблица показывает, на сколько символов нужно сдвинуть образ в случае несовпадения символа.
Поиск образа в строке: Теперь мы начинаем поиск образа в строке. Мы сравниваем символы образа и строки слева направо. Если символы совпадают, мы переходим к следующему символу. Если символы не совпадают, мы сдвигаем образ на величину, указанную в таблице D для этого символа.
В результате, мы находим образ “ABABCABAB” в тексте “ABABDABACDABABCABAB” на позиции 10.
#include <iostream>
#include <vector>
#include <cstring>
using namespace std;
void computeDTable(char* pattern, int M, vector<int>& d)
{
int length = 0;
d[0] = -1;
for (int i = 1; i < M; i++) {
if (pattern[i] == pattern[length]) {
length++;
d[i] = length;
}
else {
if (length != 0) {
length = d[length - 1];
i--;
}
else {
d[i] = 0;
}
}
}
}
void KMPSearch(char* pattern, char* text) {
int M = strlen(pattern);
int N = strlen(text);
vector<int> d(M);
computeDTable(pattern, M, d);
int i = 0;
int j = 0;
while (i < N) {
if (pattern[j] == text[i]) {
j++;
i++;
}
if (j == M) {
cout << "Найден образ на индексе " << i - j << endl;
j = d[j - 1];
}
else if (i < N && pattern[j] != text[i]) {
if (j != 0)
j = d[j - 1];
else
i = i + 1;
}
}
}
int main()
{
setlocale(LC_ALL, "Ru");
char text[] = "OEAEOEAEQBGOEAEOEAE";
char pattern[] = "QBG";
KMPSearch(pattern, text);
return 0;
}
Алгоритм Бойера-Мура
Поиск образа в строке по методу КМП даёт выигрыш только в том случае, когда несовпадений символов образа и строки предшествовало некоторое число совпадений. Если при сравнении образа и анализируемой части строки сопоставляемые символы различны, то образ сдвигается только на 1 символ.
Скорость в алгоритме БМ достигается за счёт того, что удается пропускать те части текста, которые заведомо не участвуют в успешном сопоставлении. В алгоритме БМ сравнение символов начинается с конца образа, а не с начала.
Как и при работе КМП алгоритма перед началом поиска образа сопоставляется таблица d, используемая в дальнейшем при смещении образа в строке. При создании матрицы d используется таблица кодов символов ASCII. Любой печатный или служебный символ имеет свой код.
Первоначально всем элементам матрицы d присваивается значение равное длине образа. Следующим шагом является присвоение каждому элементу таблицы d, индекс которого равен коду ASCII текущего рассматриваемого символа образа значение равного удаленности текущего символа от конца образа. Далее происходит присваивание элементам массива d соответствующих значений, равных расстоянию от рассматриваемого символа до конца образа. При этом индекс элемента массива d, который получает новые значения, определяется кодом ASCII рассматриваемого символа.
Например код ASCII последнего образца слова hоoligan = 8. Поскольку данный символ является последним, то удаленность до конца образа равна 0. Код предпоследнего буквы а=97 ASCII . Удаленность данного символа до конца образа равна 1.

В том случае, когда образ содержит несколько одинаковых символов, элементу таблицы d соответствующего данному символу присваивается значение равное удаленности от конца образа с самого правого из одинаковых символов.

Вторым этапом работы алгоритма БМ поиска после построения таблицы d является сам поиск образа в строке. При сравнении образа со строкой, образ продвигается по строке слева направо, однако посимвольное сравнение образа и строки выполняются справа налево. Сравнение образа со строкой происходит до тех пор пока:
1) Не будет рассмотрен весь образ, который говорит о том, что соответствие между образом и некоторой части строки найдены
2) Не закончится строка, которая означает, что вхождений соответствующих строки образа нет
3) Не произойдет несовпадений символом образа и строки, что вызывает сдвиг образа на несколько символов вправо и продолжения процесса поиска.
В том случае, если произошло несовпадение символов, смещение образа по строке определяется значением элемента таблицы d, причем индексом данного элемента является код ASCII символа строки. Эффективность алгоритма БМВ о многих случаях, кроме специально построенных примеров, алгоритм требует значительно меньше N сравнений. В самых благоприятных обстоятельствах, когда последний символ образа всегда попадает на несовпадающий символ строки, число сравнений равно N/M.

Алгоритмы Бойера-Мура и Кнута-Морриса-Пратта (KMP) оба предназначены для поиска подстроки в строке, но они используют разные подходы:
Сканирование текста выполняется справа налево.
Использует две эвристики: “плохой символ” и “хороший суффикс”, которые помогают быстро сдвигать образ вправо, пропуская неподходящие части текста.
Эффективен, когда алфавит символов велик, так как вероятность совпадения символов меньше, что позволяет делать большие сдвиги.
Сканирование текста выполняется слева направо.
Использует таблицу префиксов для определения, на сколько символов можно сдвинуть образ в случае несовпадения, без необходимости повторного сравнения уже проверенных символов.
Эффективен, когда есть много повторяющихся символов в образе, так как позволяет избежать повторного сравнения этих символов.
В общем, алгоритм Бойера-Мура обычно быстрее на практике, особенно когда образ длинный и когда алфавит символов большой. Однако, KMP может быть более предпочтительным в случаях, когда образ содержит много повторяющихся символов или когда алфавит символов мал. Оба алгоритма имеют свои преимущества в зависимости от контекста задачи.
Алгоритмы сортировок
Сортировка - это процесс упорядочивания элементов в списке. Вот как это работает:
У нас есть список, и мы выбираем одно поле в каждом элементе списка, которое будет служить “ключом”. Этот ключ должен быть чем-то, что мы можем сравнить, например, числом или словом.
Наша цель - переставить элементы списка так, чтобы ключи были в порядке возрастания или убывания.
Есть два основных типа сортировки:
Внутренняя сортировка: Здесь мы предполагаем, что все данные находятся в оперативной памяти компьютера. Наша цель - сделать как можно меньше шагов, чтобы отсортировать список.
Внешняя сортировка: Здесь данные хранятся где-то вне оперативной памяти, например, на жестком диске. Наша цель - сделать как можно меньше обращений к этому хранилищу данных, потому что это обычно занимает много времени.
Существуют разные методы сортировки, которые подходят для разных ситуаций. Например, есть простые методы, такие как обмен, вставки и выбор. Есть и более сложные методы, такие как сортировка Шелла, пирамидальная сортировка и быстрая сортировка. Есть даже специальные методы, такие как подсчет, которые работают только в определенных ситуациях.

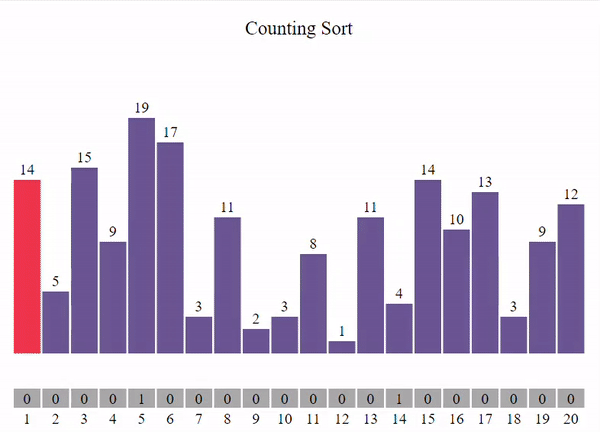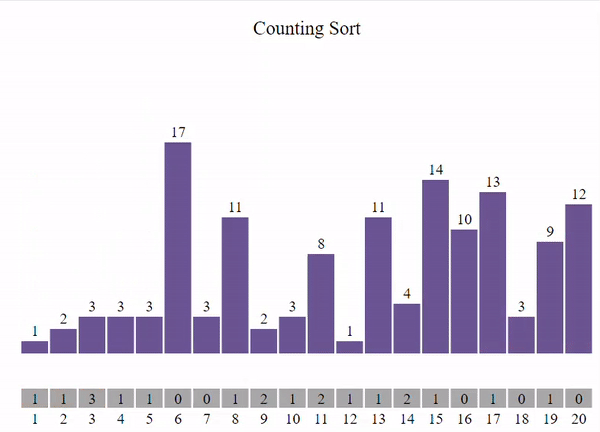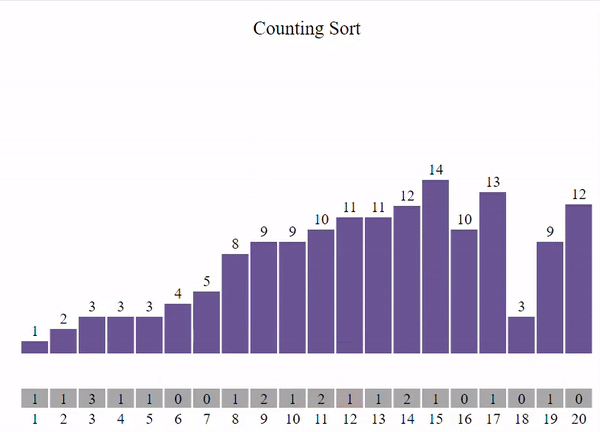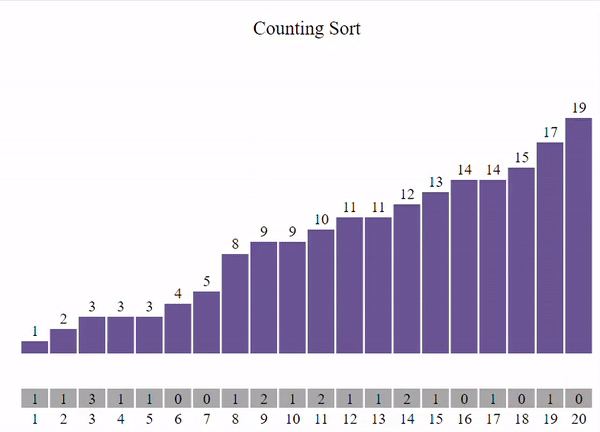
Этот метод подразумевает, что все данные, которые мы хотим отсортировать, являются целыми числами в диапазоне от 0 до k. Основная идея состоит в том, чтобы для каждого числа x определить, сколько чисел меньше x. Зная это, мы можем поместить число x на правильное место в отсортированном списке.
#include <iostream>
#include <fstream>
using namespace std;
void show_array(int* arr, const int& size, int pass_count) {
cout << "Array after " << pass_count << " passes: [";
for (int i = 0; i < size; i++) {
cout << arr[i];
if (i != size - 1) {
cout << ", ";
}
}
cout << "]" << endl;
}
void count_sort(int* arr, const int size) {
int min = *min_element(arr, arr + size);
int max = *max_element(arr, arr + size);
int* countArr = new int[max - min + 1] {0};
for (int i = 0; i < size; i++) {
countArr[arr[i] - min]++;
}
int outputIdx = 0;
for (int i = min; i <= max; i++) {
while (countArr[i - min] > 0) {
arr[outputIdx] = i;
outputIdx++;
countArr[i - min]--;
show_array(arr, size, outputIdx);
}
}
delete[] countArr;
}
int main() {
const int size = 10;
int arr_count[size] = { 0, 0, 1, 0, 1, 0, 0, 1, 1, 1 };
count_sort(arr_count, size);
}
При этом методе мы делим список на две части: отсортированную и неотсортированную. В начале отсортированной частью считается только первый элемент. Затем мы берем следующий элемент из неотсортированной части и вставляем его на правильное место в отсортированной части.
Максимальное количество сравнений ключей с i при i-ом проходе равно i - 1. Если предположить, что все перестановки из n элементов равновероятны, то среднее число сравнений равно i/2. Число перестановок M(i) = C(i) + 2. Этот алгоритм работает лучше всего, когда исходный список уже отсортирован, и хуже всего, когда элементы расположены в обратном порядке.
#include <iostream>
using namespace std;
void show_array(int* arr, const int& size, int pass_count) {
cout << "Array after " << pass_count << " passes: [";
for (int i = 0; i < size; i++) {
cout << arr[i] << ", ";
}
cout << "]" << endl;
}
void insertionSort(int* arr, int n) {
int pass_count = 0;
for (int i = 1; i < n; i++) {
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
pass_count++;
show_array(arr, n, pass_count);
}
}
int main()
{
setlocale(LC_ALL, "Ru");
int n;
cout << "Введите размерность массива: ";
cin >> n;
int* a = new int[n];
cout << "Введите элементы массива:" << endl;
for (int i = 0; i < n; i++)
cin >> a[i];
insertionSort(a, n);
return 0;
}
Этот метод сортировки работает так: мы делим массив на две части - отсортированную и неотсортированную. В начале считаем, что отсортированная часть пуста, а все элементы массива находятся в неотсортированной части. Затем мы ищем наименьший элемент в неотсортированной части и перемещаем его в конец отсортированной части. Этот процесс повторяется, пока весь массив не будет отсортирован.
#include <iostream>
using namespace std;
void show_array(int* arr, const int& size, int pass_count) {
cout << "Array after " << pass_count << " passes: [";
for (int i = 0; i < size; i++) {
cout << arr[i] << ", ";
}
cout << "]" << endl;
}
void selection_sort(int* arr, const int& size) {
int pass_count = 0;
for (int i = 0; i < size - 1; i++) {
int min_index = i;
for (int j = i + 1; j < size; j++) {
if (arr[j] < arr[min_index]) {
min_index = j;
}
}
swap(arr[i], arr[min_index]);
pass_count++;
show_array(arr, size, pass_count);
}
}
int main()
{
setlocale(LC_ALL, "Ru");
int n;
cout << "Введите размерность массива: ";
cin >> n;
int* a = new int[n];
cout << "Введите элементы массива:" << endl;
for (int i = 0; i < n; i++)
cin >> a[i];
selection_sort(a, n);
return 0;
}
Пузырьковая сортировка - это еще один простой метод сортировки. Он работает так: на каждом шаге мы сравниваем два соседних элемента и меняем их местами, если они расположены в неправильном порядке. Этот процесс повторяется, пока весь массив не будет отсортирован.
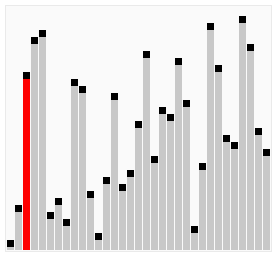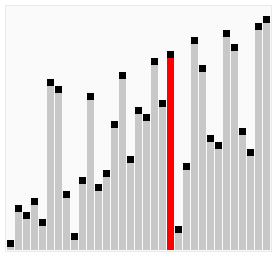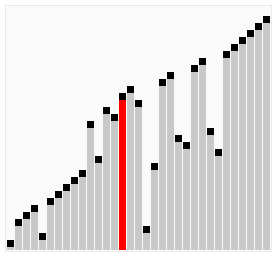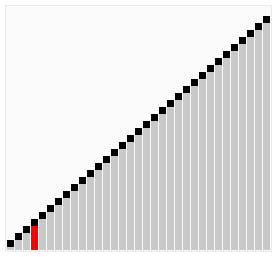
Оба этих метода имеют свои преимущества и недостатки. Метод прямого выбора обычно работает быстрее, если элементы в начале массива уже почти отсортированы. Пузырьковая сортировка, с другой стороны, может быть более эффективной для больших массивов, но она может быть медленной, если массив изначально почти отсортирован. Если на каком-то проходе не произошло ни одного обмена, это означает, что список уже отсортирован, и алгоритм может быть завершен раньше времени. Это свойство делает пузырьковую сортировку идеальной для списков, которые уже почти отсортированы.
#include <iostream>
using namespace std;
void show_array(int* arr, const int& size, int pass_count) {
cout << "Array after " << pass_count << " passes: [";
for (int i = 0; i < size; i++) {
cout << arr[i] << ", ";
}
cout << "]" << endl;
}
void bubbleSort(int* arr, int n)
{
int pass_count = 0;
for (int i = 0; i < n - 1; i++)
{
for (int j = 0; j < n - i - 1; j++)
{
if (arr[j] > arr[j + 1]) {
swap(arr[j], arr[j + 1]);
}
}
pass_count++;
show_array(arr, n, pass_count);
}
}
int main()
{
setlocale(LC_ALL, "Ru");
int n;
cout << "Введите размерность массива: ";
cin >> n;
int* a = new int[n];
cout << "Введите элементы массива:" << endl;
for (int i = 0; i < n; i++)
cin >> a[i];
bubbleSort(a, n);
return 0;
}
Шейкерная сортировка(сортировка перемещиванием) – Алгоритм сортировки, которая улучшает сортировку пузырьком, проходя по массиву в обоих направлениях. Это позволяет уменьшить количество проходов, необходимых для полной сортировки массива. На каждом проходе справа налево минимальный элемент всплывает на первую позицию, а на проходе слева направо максимальный элемент тонет на последнюю позицию. Процесс повторяется, пока границы рабочей части массива не сойдутся. Число сравнений пузырька = (n^2 – n) / 2 . Шейкерная сортировка лучше пузырьковой за счет того, что шейкерная сортировка проходит с двух сторон, а пузырьковая только с одной стороны
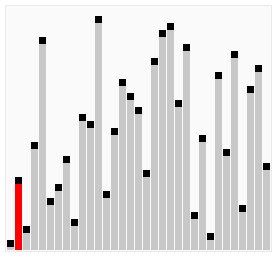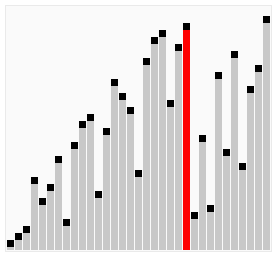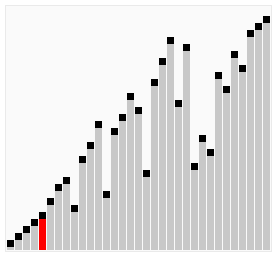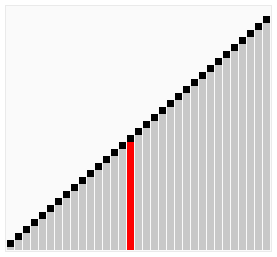
#include <iostream>
using namespace std;
void show_array(int* arr, const int& size, int pass_count) {
cout << "Array after " << pass_count << " passes: [";
for (int i = 0; i < size; i++) {
cout << arr[i] << ", ";
}
cout << "]" << endl;
}
void shaker_sort(int* arr, const int& size) {
int pass_count = 0;
bool swapped = true;
int left = 0;
int right = size - 1;
while (swapped) {
swapped = false;
for (int i = left; i < right; i++) {
if (arr[i] > arr[i + 1]) {
swap(arr[i], arr[i + 1]);
swapped = true;
}
}
right--;
if (!swapped) {
break;
}
swapped = false;
for (int i = right; i > left; i--) {
if (arr[i - 1] > arr[i]) {
swap(arr[i - 1], arr[i]);
swapped = true;
}
}
left++;
pass_count++;
show_array(arr, size, pass_count);
}
}
int main()
{
setlocale(LC_ALL, "Ru");
int n;
cout << "Введите размерность массива: ";
cin >> n;
int* a = new int[n];
cout << "Введите элементы массива:" << endl;
for (int i = 0; i < n; i++)
cin >> a[i];
shaker_sort(a, n);
return 0;
}
Сортировка Шелла — это алгоритм сортировки, который улучшает классическую сортировку вставками. Он работает на принципе предварительного “разбиения” массива на подмассивы и сортировки элементов в этих подмассивах.
Как работает Сортировка Шелла:
Суть алгоритма заключается в сравнении и обмене элементов, которые находятся на определённом расстоянии друг от друга, и постепенном уменьшении этого расстояния до тех пор, пока не будет достигнута полная отсортированность массива.
1. Выбор интервала: Начинаем с интервала, равного половине длины массива.
2. Сортировка подмассивов: Выполняем сортировку вставками для элементов, разделённых выбранным интервалом.
3. Уменьшение интервала: Интервал уменьшается, и процесс повторяется.
4. Финальная сортировка: Когда интервал становится равным 1, массив считается отсортированным.
Сложность Сортировки Шелла зависит от выбора интервалов и может варьироваться от O(nlogn) до O(n^2)в худшем случае.
Сортировка Шелла применяется для средних по размеру массивов и может использоваться как предварительная сортировка перед применением других алгоритмов.
Представим массив [13, 14, 94, 33, 82, 25]. После первого прохода с интервалом в 3 элемента, массив может выглядеть так: [13, 14, 25, 33, 82, 94]. После уменьшения интервала до 1, массив будет полностью отсортирован.
#include <iostream>
using namespace std;
void show_array(int* arr, const int& size, int pass_count) {
cout << "Array after " << pass_count << " passes: [";
for (int i = 0; i < size; i++) {
cout << arr[i] << ", ";
}
cout << "]" << endl;
}
void shellSort(int* arr, int size) {
int pass_count = 0;
for (int interval = size / 2; interval > 0; interval /= 2) {
for (int i = interval; i < size; i++) {
int j;
for (j = i; j >= interval && arr[j - interval] > arr[j]; j -= interval) {
swap(arr[j], arr[j - interval]);
}
}
pass_count++;
show_array(arr, size, pass_count);
}
}
int main()
{
setlocale(LC_ALL, "Ru");
int n;
cout << "Введите размерность массива: ";
cin >> n;
int* a = new int[n];
cout << "Введите элементы массива:" << endl;
for (int i = 0; i < n; i++)
cin >> a[i];
shellSort(a, n);
return 0;
}
Сравнение различных алгоритмов сортировки:

Время работы различных методов:

Простые алгоритмы сортировки не возможно применять для данных, которые из-за своего размера не помещаются в оперативной памяти машины и находятся например на внешних последовательных запоминающих устройствах памяти. В таком случае мы говорим, что данные представляют собой последовательный файл. Для него характерно, что каждый момент непосредственно доступна одна и только одна компонента. Для таких последовательностей применима сортировка с помощью слияния. Слияние означает объединение двух или более последовательностей или одну единственную упорядоченную последовательность с помощью повторяющегося выбора из доступных в данный момент элементов.
Алгоритм работает следующим образом:
Разделение: Массив рекурсивно делится пополам до тех пор, пока каждый подмассив не будет содержать только один элемент.
Слияние: Затем эти подмассивы сливаются вместе таким образом, чтобы элементы были упорядочены. Это достигается путем сравнения элементов каждого подмассива и размещения меньшего элемента в результирующий массив.
Конкатенация: Процесс слияния продолжается, пока все подмассивы не будут объединены в один отсортированный массив.
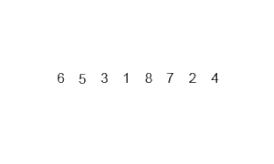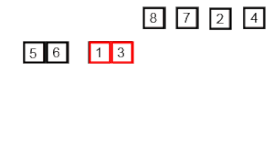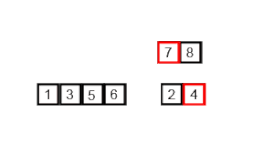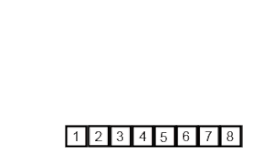
Этот алгоритм эффективен для больших наборов данных, поскольку его среднее и худшее время выполнения составляет O(n log n), где n - количество элементов в массиве.
#include <iostream>
#include <fstream>
#include <vector>
void merge(std::vector<int>& arr, int left, int middle, int right) {
int n1 = middle - left + 1;
int n2 = right - middle;
std::vector<int> L(n1), R(n2);
for (int i = 0; i < n1; i++) {
L[i] = arr[left + i];
}
for (int j = 0; j < n2; j++) {
R[j] = arr[middle + 1 + j];
}
int i = 0, j = 0, k = left;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
}
else {
arr[k] = R[j];
j++;
}
k++;
}
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
void mergeSort(std::vector<int>& arr, int left, int right) {
if (left >= right) {
return;
}
int middle = left + (right - left) / 2;
mergeSort(arr, left, middle);
mergeSort(arr, middle + 1, right);
merge(arr, left, middle, right);
for (int i = left; i <= right; i++) {
std::cout << arr[i] << " ";
}
std::cout << std::endl;
}
int main() {
std::ifstream input("input.txt");
if (!input) {
std::cerr << "Error opening file" << std::endl;
return 1;
}
std::vector<int> arr;
int num;
while (input >> num) {
arr.push_back(num);
}
input.close();
int n = arr.size();
std::cout << "Original array: ";
for (int i = 0; i < n; i++) {
std::cout << arr[i] << " ";
}
std::cout << std::endl;
mergeSort(arr, 0, n - 1);
std::cout << "Sorted array: ";
for (int i = 0; i < n; i++) {
std::cout << arr[i] << " ";
}
std::cout << std::endl;
return 0;
}
Алгоритм естественного слияния - это метод сортировки, который использует стратегию "разделяй и властвуй". Он работает следующим образом:
Разделение: Входной массив разделяется на серии(естественные отсортированные последовательностей) подряд идущих отсортированных элементов, которые называются "естественными сериями".
Слияние: Серии сливаются попарно, пока не останется одна отсортированная серия, которая и будет являться отсортированным массивом.
Простыми словами, алгоритм находит уже отсортированные части массива и последовательно сливает их вместе, пока весь массив не будет отсортирован.
При сортировки простым слиянием данные разбиваются и сливаются подпоследовательности длина которых равна степени двойки, однако данные исходной последовательности могут быть уже частично упорядочены. В этом случае целесообразно просто объединить уже упорядоченные подпоследовательности. Упорядоченные подпоследовательности называют сериями. Таким образом, сортировки естественным слиянием объединяются в серии, а не в подпоследовательности фиксированной длины. Если сливаются две последовательности, каждая из n серий, то результирующая также содержит ровно n серий. Следовательно, при каждом проходе общее число серий уменьшается вдвое и общее число пересылок в самом плохом случае будет равно nlog(n), а в других случаях меньше.
В основе сортировки последовательности многофазным слиянием лежит распределение начальных серий в соответствии с числами Фибо наччи. Поэтому, перед тем, как перейти непосредственно к алгоритму мно гофазной сортировки, рассмотрим числа Фибоначчи.
Иными словами, число пар кроликов создает ряд, каждый член кото рого равен сумме двух предыдущих. Этот ряд известен как ряд Фибоначчи, а сами числа - как числа Фибоначчи.
При многофазной сортировке слиянием распределений серий происходит с тремя последовательностями. Две из которых являются входными, одна выходной. На каждом проходе элементы из двух входных последовательностей сливаются в третью. Как только одна их входных последовательностей исчерпывается она становится выходной.
Слияние начинается с двух последовательностей f1 и f2,, организованных в виде серий длины 1, а серии их f1 и f2 обьединяются, образуя серии длины 2 и записываются в третью последовательность f3. Слияние происходит до послного опустошения последовательности f2, затем обьединяем оставшиеся серии длины 1 из f1 с таким же количеством серий длины 2 из f3. В результате получаются серии длины 3, которые помещаются в файл f2. Затем объединяется серии длины 2 из f3 с сериями длины 3 из f2.
Таким образом, в многофазной сортировке используется эффективное распределение и слияние серий по числам Фибоначчи для поэтапной сортировки и объединения данных последовательностей.
Многофазная сортировка может быть более эффективной по сравнению с сбалансированной, так как она использует слияние ( n - 1 ) путей вместо ( n / 2 ), если начать с ( n ) последовательностей. Приблизительное количество необходимых проходов для сортировки равно ( log(N)n), где ( N ) - это количество последовательностей, а ( n ) - количество серий.
Для сбалансированного многопутевого слияния, общее количество проходов, необходимых для сортировки, пропорционально количеству серий, так как на каждом проходе происходит копирование всех данных. Один из способов уменьшить количество проходов - это распределение серий более чем между двумя последовательностями. Слияние ( r ) серий, равномерно распределенных между ( n ) последовательностями, приведет к ( r / N ) сериям после первого прохода. После второго прохода количество серий уменьшится до ( (r / N)^2 ), и так далее до ( (r / N)^k ) после ( k )-го прохода. Таким образом, общее количество проходов для сортировки ( n ) элементов с помощью ( n )-путевого слияния равно ( k = log_{n}(N) ). Поскольку на каждом проходе выполняется ( n ) операций копирования, то в худшем случае потребуется ( M = n *log_{n}(N) ) операций.
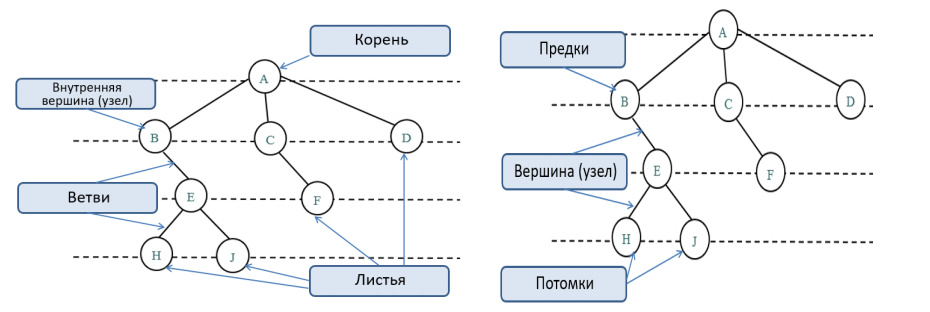
Деревья
Деревья - это структуры данных, которые состоят из узлов. В каждом дереве есть один особенный узел, называемый корнем. Все остальные узлы делятся на несколько поддеревьев, каждое из которых само является деревом.
Основные свойства деревьев данных в информатике:
Иерархическая структура. Каждый узел имеет родительский узел и ноль или более дочерних узлов.
Один корневой узел. Он является вершиной дерева и не имеет родительского узла.
Уникальные пути. Каждый узел имеет уникальный путь от корневого узла до него.
Отсутствие циклов. Невозможно пройти по узлам и вернуться в исходный узел.
Рекурсивная структура. Каждый поддерево также является деревом данных.
Обход дерева - это процесс посещения каждого узла в дереве. Существуют разные стратегии обхода:
Пошаговый перебор элементов дерева по связям между предками-узлами и потомками-узлами называется обходом дерева. Обход, при котором каждый узел-предок просматривается прежде его потомков называется предупорядоченным обходом или обходом в прямом порядке (pre-order walk), а когда просматриваются сначала потомки, а потом предки, то обход называется поступорядоченным обходом или обходом в обратном порядке. Существует также симметричный обход, при котором посещается сначала левое поддерево, затем узел(текущий корень), затем – правое поддерево, и обход в ширину, при котором узлы просматриваются уровень за уровнем. Каждый уровень обходится слева направо.
Прямой обход (предупорядоченный): Сначала посещается корень, затем левое поддерево, и наконец правое поддерево.
Обратный обход (подупорядоченный): Сначала посещаются все поддеревья, а затем корень.
Симметричный обход: Сначала посещается левое поддерево, затем корень, и наконец правое поддерево.
Обход в ширину: Узлы посещаются уровень за уровнем, каждый уровень обходится слева направо.
Бинарные деревья поиска - это структура данных, которая позволяет хранить элементы в отсортированном порядке для эффективного поиска, вставки и удаления. Основные операции выполняются за время, пропорциональное глубине дерева. Для полного дерева с n узлами эти операции выполняются за O(logn). Бинарные деревья поиска также поддерживают запросы на поиск минимального и максимального элементов, предшествующего и последующего элементов.
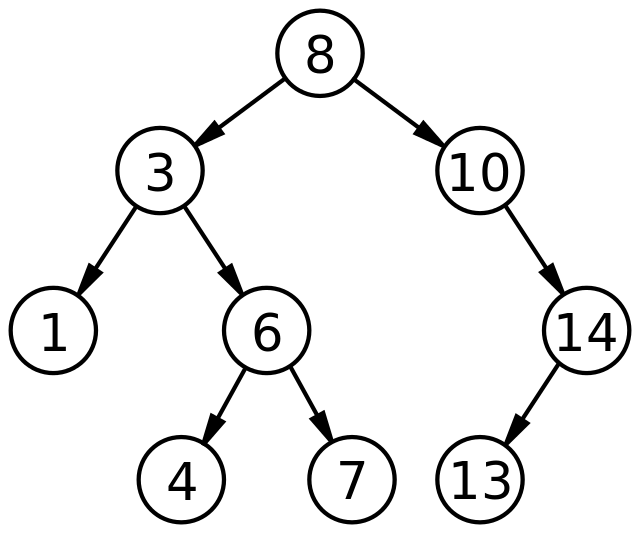
Структура бинарного дерева поиска
Каждый узел бинарного дерева поиска содержит ключ и связанные данные, а также указатели на левого и правого потомков и на родительский узел. Корень дерева хранит первый элемент, и для каждого последующего элемента создается новый узел. Если новый элемент меньше текущего узла, он помещается в левое поддерево, иначе в правое.
Операции на бинарных деревьях поиска
- Поиск ключа: Начиная с корня, производится сравнение ключа с каждым узлом. Если ключ найден или дождемся конца дерева, операция завершается. Время работы O(h), где h - высота дерева.
- Поиск минимального/максимального элемента: Простой проход по указателям left (для минимального) или right (для максимального) от корня до nil.
- Вставка и удаление: Вставка элемента в бинарное дерево поиска подразумевает поиск позиции для него, а удаление требует сохранения свойств дерева после удаления узла.
Эффективность бинарных деревьев поиска обеспечивается свойством упорядоченности элементов и быстрым доступом к данным. Они поддерживают множество операций и широко применяются в практике.
#include <iostream>
using namespace std;
class Node {
public:
int data;
Node* left;
Node* right;
Node(int value) : data(value), left(nullptr), right(nullptr) {}
// Деструктор для освобождения памяти узлов
~Node() {
delete left;
delete right;
}
};
class BinaryTree {
private:
Node* root;
Node* copyNodes(Node* node) {
if (node == nullptr) {
return nullptr;
}
Node* newNode = new Node(node->data);
newNode->left = copyNodes(node->left);
newNode->right = copyNodes(node->right);
return newNode;
}
public:
BinaryTree() : root(nullptr) {}
BinaryTree(const BinaryTree& other) {
root = copyNodes(other.root);
}
// Функция insert(value) позволяет вставить новое значение в бинарное дерево.
void insert(int value) {
root = insertRecursive(root, value);
}
// В начале вызывается функция insertRecursive для рекурсивного поиска места вставки.
// Если корень дерева пустой (nullptr), то создается новый узел с заданным значением.
// В противном случае происходит сравнение значения с корневым узлом:
// если значение меньше, рекурсивно вызывается insert для левого поддерева, иначе - для правого.
// В итоге, узел с новым значением вставляется на правильное место в дереве.
Node* insertRecursive(Node* root, int value) {
if (root == nullptr) {
return new Node(value);
}
if (value < root->data) {
root->left = insertRecursive(root->left, value);
}
else if (value > root->data) {
root->right = insertRecursive(root->right, value);
}
return root;
}
// Функция search(value) осуществляет поиск значения в бинарном дереве.
Node* search(int value) {
return searchRecursive(root, value);
}
// Сначала вызывается функция searchRecursive для рекурсивного поиска значения в дереве.
// Если корень пустой или корневое значение совпадает с заданным, возвращается текущий корень.
// Иначе, если заданное значение меньше значения корня, вызывается поиск для левого поддерева,
// а если больше - для правого поддерева.
// В конечном итоге либо возвращается узел с заданным значением, либо nullptr, если значением не существует в дереве.
Node* searchRecursive(Node* root, int value) {
if (root == nullptr || root->data == value) {
return root;
}
if (value < root->data) {
return searchRecursive(root->left, value);
}
return searchRecursive(root->right, value);
}
// Функция inorderTraversal осуществляет обход бинарного дерева в порядке inorder.
// При обходе в порядке inorder сначала посещается левое поддерево, затем текущий узел, а затем правое поддерево.
// Таким образом, функция рекурсивно вызывает себя для левого поддерева до тех пор, пока не достигнет самого левого узла.
// После этого выводит значение текущего узла и рекурсивно вызывает себя для правого поддерева.
// В итоге все значения узлов выводятся в отсортированном порядке, что является характерной особенностью обхода inorder.
void inorderTraversal(Node* node) {
if (node) {
inorderTraversal(node->left);
cout << node->data << " ";
inorderTraversal(node->right);
}
}
// Функция preorderTraversal(node) осуществляет обход бинарного дерева в порядке preorder.
// При обходе в порядке preorder сначала выводится значение текущего узла, затем рекурсивно вызывается функция для левого поддерева,
// и затем для правого поддерева. Таким образом, при посещении каждого узла сначала выполняется вывод его значения.
// Затем переход к левому поддереву, где происходит повторный обход в порядке preorder,
// после чего переход к правому поддереву аналогично.
// Такой порядок обхода называется preorder, где узлы посещаются в порядке: корень-левое поддерево-правое поддерево.
void preorderTraversal(Node* node) {
if (node) {
cout << node->data << " ";
preorderTraversal(node->left);
preorderTraversal(node->right);
}
}
// Функция postorderTraversal(node) осуществляет обход бинарного дерева в порядке postorder.
// При обходе в порядке postorder сначала вызывается функция для левого поддерева, затем для правого поддерева,
// и только после этого выводится значение текущего узла. Таким образом, узлы обрабатываются в следующем порядке:
// сначала левое поддерево, затем правое поддерево, и в конечном итоге значение текущего узла.
// Такой порядок обхода называется postorder, где узлы обрабатываются в порядке: левое поддерево-правое поддерево-корень.
void postorderTraversal(Node* node) {
if (node) {
postorderTraversal(node->left);
postorderTraversal(node->right);
cout << node->data << " ";
}
}
// Функция treeSize(node) определяет размер бинарного дерева, то есть количество узлов в нем.
// Рекурсивно суммирует количество узлов в левом поддереве, правом поддереве и узле текущего узла.
int treeSize(Node* node) {
if (node == nullptr) {
return 0;
}
return 1 + treeSize(node->left) + treeSize(node->right);
}
// Функция findMin(node) определяет узел с минимальным значением, начиная обход от корня и налево
Node* findMin(Node* node) {
if (node == nullptr) {
return nullptr;
}
while (node->left != nullptr) {
node = node->left;
}
return node;
}
// Функция findMax(node) определяет узел с максимальным значением, начиная обход от корня и направо
Node* findMax(Node* node) {
if (node == nullptr) {
return nullptr;
}
while (node->right != nullptr) {
node = node->right;
}
return node;
}
// Оператор присваивания
BinaryTree& operator=(const BinaryTree& other) {
if (this != &other) {
delete root;
root = copyNodes(other.root);
}
return *this;
}
int& operator[](int value) {
Node* node = search(value);
if (node == nullptr) {
insert(value);
node = search(value);
}
return node->data;
}
~BinaryTree() {
delete root;
root = nullptr;
}
};
int main() {
BinaryTree tree;
tree.insert(5);
tree.insert(3);
tree.insert(7);
tree.insert(1);
tree.insert(4);
int size = tree.treeSize(tree.search(5));
cout << "Size of the subtree with root 5: " << size << endl;
Node* minNode = tree.findMin(tree.search(5));
cout << "Minimum element in the subtree with root 5: " << minNode->data << endl;
Node* maxNode = tree.findMax(tree.search(5));
cout << "Maximum element in the subtree with root 5: " << maxNode->data <<
cout << endl;
tree.preorderTraversal(tree.search(3));
cout << endl;
tree.postorderTraversal(tree.search(3));
cout << endl;
cout << "Value at node 7: " << tree[7] << endl;
return 0;
}#include <iostream>
#include <string>
using namespace std;
class Node {
public:
int data;
Node* left;
Node* right;
Node* parent;
Node(int value) : data(value), left(nullptr), right(nullptr), parent(nullptr) {}
};
class BinaryTree {
private:
Node* root;
Node* copyNodes(Node* node, Node* parent) {
if (node == nullptr) {
return nullptr;
}
Node* newNode = new Node(node->data);
newNode->parent = parent;
newNode->left = copyNodes(node->left, newNode);
newNode->right = copyNodes(node->right, newNode);
return newNode;
}
void deleteTree(Node* node) {
if (node == nullptr) {
return;
}
deleteTree(node->left);
deleteTree(node->right);
delete node;
}
public:
BinaryTree() : root(nullptr) {}
BinaryTree(const BinaryTree& other) {
root = copyNodes(other.root, nullptr);
}
~BinaryTree() {
deleteTree(root);
root = nullptr;
}
void insert(int value) {
root = insertRecursive(root, value);
}
Node* insertRecursive(Node* root, int value) {
if (root == nullptr) {
return new Node(value);
}
if (value < root->data) {
root->left = insertRecursive(root->left, value);
root->left->parent = root;
}
else if (value > root->data) {
root->right = insertRecursive(root->right, value);
root->right->parent = root;
}
return root;
}
Node* search(int value) {
return searchRecursive(root, value);
}
Node* searchRecursive(Node* root, int value) {
if (root == nullptr || root->data == value) {
return root;
}
if (value < root->data) {
return searchRecursive(root->left, value);
}
return searchRecursive(root->right, value);
}
BinaryTree& operator=(const BinaryTree& other) {
if (this != &other) {
deleteTree(root);
root = copyNodes(other.root, nullptr);
}
return *this;
}
int& operator[](int value) {
Node* node = search(value);
if (node == nullptr) {
insert(value);
node = search(value);
}
return node->data;
}
Node* findMin(Node* node) {
while (node->left != nullptr) {
node = node->left;
}
return node;
}
Node* findMax(Node* node) {
while (node->right != nullptr) {
node = node->right;
}
return node;
}
Node* findNext(int value) {
Node* current = search(value);
if (current == nullptr) {
return nullptr;
}
if (current->right != nullptr) {
return findMin(current->right);
}
else {
Node* parent = current->parent;
while (parent != nullptr && parent->data <= value) {
parent = parent->parent;
}
return parent;
}
}
Node* findPrev(int value) {
Node* current = search(value);
if (current == nullptr) {
return nullptr;
}
if (current->left != nullptr) {
return findMax(current->left);
}
else {
Node* parent = current->parent;
while (parent != nullptr && parent->data >= value) {
parent = parent->parent;
}
return parent;
}
}
};
Node* findNode(BinaryTree& tree) {
int value;
cout << "Введите значение для поиска: ";
cin >> value;
Node* node = tree.search(value);
if (node != nullptr) {
cout << "Узел с данным значением найден!" << endl;
}
else {
cout << "Узел с данным значением не найден!" << endl;
}
return node;
}
int main()
{
setlocale(LC_ALL, "Rus");
BinaryTree tree;
tree.insert(8);
tree.insert(4);
tree.insert(12);
tree.insert(2);
tree.insert(6);
tree.insert(9);
tree.insert(14);
Node* currentNode = findNode(tree);
if (currentNode != nullptr) {
Node* nextNode = tree.findNext(currentNode->data);
Node* prevNode = tree.findPrev(currentNode->data);
if (nextNode != nullptr) {
cout << "Следующий элемент для " << currentNode->data << " : " << nextNode->data << endl;
}
else {
cout << "Следующий элемент для " << currentNode->data << " не найден" << endl;
}
if (prevNode != nullptr) {
cout << "Предыдущий элемент для " << currentNode->data << " : " << prevNode->data << endl;
}
else {
cout << "Предыдущий элемент для " << currentNode->data << " не найден" << endl;
}
}
return 0;
}
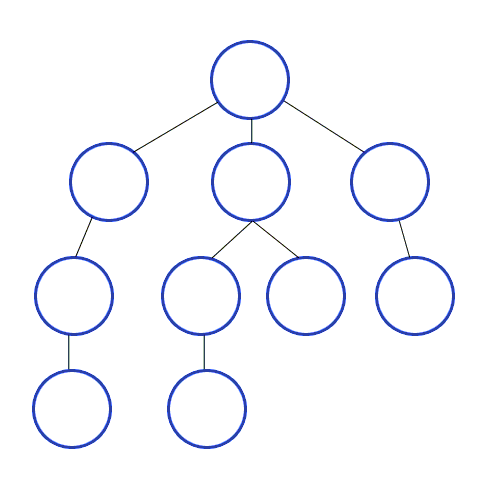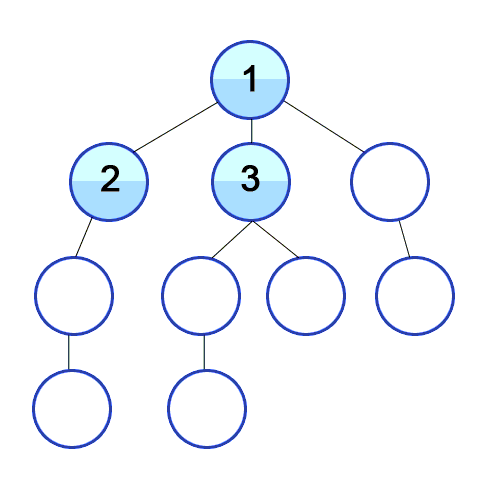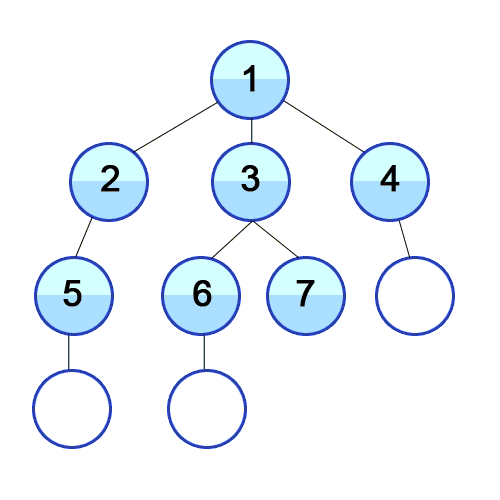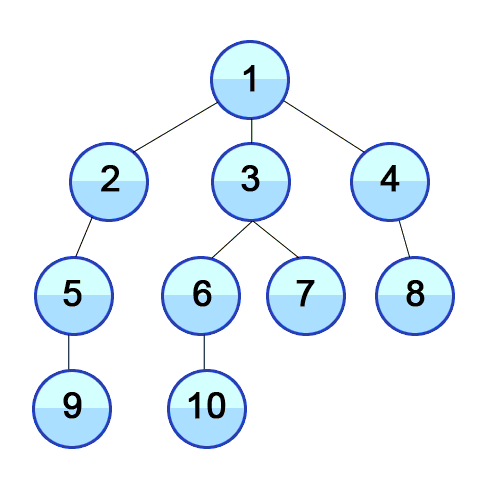
В программировании существует несколько способов обхода деревьев, каждый из которых имеет свои особенности и применяется в различных ситуациях. Рассмотрим основные типы обходов деревьев:
1. Обход в глубину (Depth-First Traversal):
1.1 Прямой обход (Preorder Traversal):
- Посещение узла происходит перед посещением его потомков.
- Порядок: Узел - Левое поддерево - Правое поддерево.
- Пример использования: копирование структуры дерева для сохранения.
1.2 Симметричный обход (Inorder Traversal):
- Посещение узла происходит между посещениями его левого и правого потомков.
- Порядок: Левое поддерево - Узел - Правое поддерево.
- Пример использования: вывод элементов дерева в отсортированном порядке.
1.3 Обратный обход (Postorder Traversal):
- Посещение узла происходит после посещения его потомков.
- Порядок: Левое поддерево - Правое поддерево - Узел.
- Пример использования: высвобождение памяти узлов дерева.
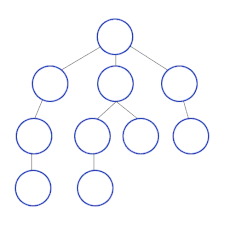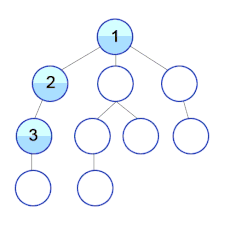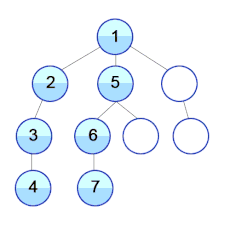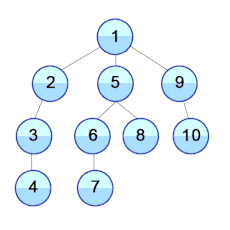
2. Обход в ширину (Breadth-First Traversal):
- Посещение узлов происходит слева направо, начиная с корня и продвигаясь на уровень ниже.
- Реализуется чаще с использованием очереди.
- Пример использования: поиск в ширину или поиск кратчайшего пути в дереве.
Общие применения:
- Прямой обход: Позволяет создавать копии структуры дерева, выполнять вычисления перед посещением потомков.
- Симметричный обход: Подходит для сортировки элементов дерева, поиска в отсортированных данных.
- Обратный обход: Пригоден для высвобождения выделенной памяти, выполнения действий после посещения всех потомков.
- Обход в ширину: Используется для поиска в ширину, построения уровней дерева.
Для поиска узла заданным ключом в бинарном дереве поиска используется следующая процедура, которая получает в качестве параметров указатель на корень бинарного дерева и ключ k и возвращает указатель на узел с этим ключом, если таковой существует. Procedure Tree_search (x,k)

Процедура поиска начинается с корня дерева и проходит вниз по дереву. Для каждого узла х на пути вниз его ключ key(x) сравнивается с переданным в качестве параметра ключом k. Если ключи одинаковы, поиск завершается. Время работы данной процедуры равно О(h), где h - высота.
Элемент с минимальным значением ключа легко найти следуя по указателям left от корневого узла до тех пор, пока не встретится значение NIL. Пример расчета ализации данного алгоритма

Если у узла х нет левого поддерева, то поскольку все ключи в правом поддереве х не меньше ключа х минимальный ключ поддерева с корнем в узле х находится в этом самом узле.
Предшествующие и последующие элементы
Нахождение предшествующих и последующих элементов в бинарном дереве поиска Иногда имея узел в бинарном дереве поиска требуется определить какой узел следует за ним в отсортированной последовательности определяемой порядком центрированного обхода бинарного дерева и какой узел предшествует данному. Если все ключи различны последующим по отношению к узлу х является узел с наименьшим ключом большим key(х).

Данная процедура возвращает узел следующий за узлом х или же возвращает значение NIL, если х обладает наибольшим ключом в бинарном дереве. Время работы данного алгоритма равна О(h). Алгоритмы поиска предшествующих и последующих элементов симметричны.
Операции вставки и удаления приводят внесению изменений в динамическое множество представленное в бинарном дереве поиска. Структура данных должна быть изменена таким образом, чтобы отражать эти изменения, но при этом сохранить свойства бинарных деревьев поиска. Вставка нового элемента выполняется относительно просто, а удаление значительно сложнее.
Procedure Free_Insert(T,z) y ← NIR x ← root (T) while x ≠ NIR do y ← x if key|z| < key|x| then x ← left|x| else x ← right|x| P|z| <- y if y = NIL then root|T| else if key|z| < key|y| then left|y| <- z else right|y| <- z left|z| = NIL right|z| = NIL P|z| O(h)
Процедура получает в качестве параметра узел z, у которого left |z| = NIL и right |z| = NIL. Таким образом она изменяет дерево Т и некоторые поля z, что z оказывается вставленным в соответствующую позицию в дереве. Процедура вставки начинает работу с корневого узла дерева и проходит по несходящиму пути. Указатель x отмечает проходимый путь, а указатель y указывает на родительский по отношению к x узел. После инициализации в строках 3 и 7 перемещает эти указатели вниз по дереву, перемещаясь влево и вправо в зависимости от результата сравнений ключей key |x| и key |z|, до тех пор пока х не станет равным NIL. Это значение находится именно в той позиции куда следует поместить элемент z. В стоках 8-13 выполняется установка значений указателей для вставки z. Процедура вставки выполняется за время O(h) в дереве высотой h.
Процедура удаления узла z из бинарного дерева поиска получает в качестве аргумента указатель на z.
Процедура рассматривает 3 возможные ситуации.
1. если у узла z нет защитных узлов, то мы просто изменяем его родительский узел |z| заменяя в нем указатель на z значением NIL.
2. если у узла z только один дочерний узел, то мы удаляем узел z создавая новую связь между родительским и дочерним узлом узла z.
3. если у узла z два дочерних узла, то мы находим следющий за ним узел Y, у которого нет левого дочернего узла и убраем его из позиции где он находился ранее путем создания новой связи между его родителем и потомком и заменяем им узел z.
Procedure Free_Delete(T,z) if left|z| = NIL или right|z| = NIL then y <- z else y <- Tree_Successor(z) if left|z| ≠ NIL then x <- left|y| else x <- right|y| if x ≠ NIL then p[x] <- p[y] if p[y] = NIL then root[T] <- x else if y = left[p[y]] then left[p[y]] <- x else right[p[y]] <- x if y ≠ z then key[z] <- key[y] // копирование сопутствующих данных в z return y
В строках 1-3 алгоритм определяет убираемый путем склейки родител и потомка узел y. Этот узел представляет собой либо узел z (если у узла z не более одного дочернего узла), либо узел следующий за узлом z (если у z имеется два дочерних узла). Затем в строках 4-6 к х присваивается указатель на дочерний узел узла у, либо значение NIL, если у у нет дочерних узлов, затем узел у убирается из дерева в строка 7-13 путем изменения указателей в p[y] и х. Это удаление усложняется необходимостью корректной отработки граничных условий (когда х равно NIL или когда у - корневой узел). И наконец, в строках 14-16, если удаленный узел у был следующим за z, мы перезаписываем ключ z и сопутствующие данные ключом и сопутствующими данными у. Удаленный узел у возвращается в строке 17, с тем чтобы вызывающая процедура могла при необходимости освободить или использовать занимаемую им память.
Опирации вставки и удаления в бинарном дереве поиска высоты h могут быть выполнены за время O(h).


Алгоритм вставки в бинарное дерево дает хорошие результаты при использовании случайных входных данных, но при этом существует возможность что будет построено вырожденное дерево. Для этого можно разработать алгоритм поддерживающий дерево в оптимальном состоянии. Под оптимальностью рассматривается сбалансированность дерева. Идеально сбалансированным называется дерево у которого для каждой вершины выполняются следующие требования: число вершин в левом и правом поддеревьях различается не более чем на единицу.
АВЛ дерево является структурой данных придуманных в 1962 году советскими учеными Адельсон-Вельский и Ландас. Эта модификация классического бинарного дерева поиска благодаря которой структура лучше сбалансирована и практически не может выразится.
Выражением называется ситуация, когда у каждого узла оказывается только по одному потомку и структура фактически становится линейной, которые являются неоптимальной. Благодаря сбалансированности и почти невозможности выражения дерева информация в нем хранится более эффективно поэтому доступ к данным оказывается быстрее и найти их становится легче.
для хранения данных. Эта структура позволяет хранить информацию в узлах дерева и перемещаться по ней с помощью путей, которые соединяют между собой узлы.
для поисковых алгоритмов. Их применяют при построении поисковых систем и интеллектуальных сервисов.
для сортировки. С помощью AVL деревьев можно хранить и сортировать информацию в базах данных, в особых участках памяти и других структурах.
для программных проверок. AVL дерево может использоваться для решения некоторый стандартных задач, например для быстрой проверки существования элемента в структуре.
для построения сложных структур. Дерево может быть составной частью более сложной структуры данных или какого либо алгоритма, например используемого для поиска, хранения или принятия решений.
AVL дерево отличается от обычного бинарного дерева поиска несколькими особенностями:
оно сбалансировано по высоте, поддеревья которые образованы левым и правым потомками каждого из узлов должны различаться длиной не более чем на один уровень.
общая длина дерева и соответственно скорость операции с ним зависят от числа узлов логарифмически.
вероятность получить сильно несбалансированные AVL дерева крайне мала, а риск что оно выродится практически отсутствует. Сбалансированность такого дерева гарантирована в отличии от рандомизированных деревьев, которые сбалансированные вероятностно.
Балансировка называют операцию, которая делает дерево более сбалансированным. В случае с АВЛ-деревьями ее применяют, когда нарушается главное правило структуры: Поддеревья потомки одного узла начинают различаться больше, чем на один уровень. Если разница в количестве уровней становится равна -2 и 2, то запускается балансировка. В связи между предками и потомками изменяются и перестраиваются так, чтобы сохранить структуру. Обычно для этого какую-либо из узлов поворачивается влево или вправо, то есть меняет свое расположение. Поворот может быть простым, когда расположение изменяет только один узел, или большим, при нем два узла разворачиваются в разные стороны.
Особенность АВЛ-деревьев при балансировке состоит в том, что после вставки надо проверить соотношение длин поддеревьев и если нужно, то провести балансировку. Высота АВЛ-дерева с n ключами лежит в диапазоне log2(n + 1) < h < 1.44log(n + 2) – 0.328.




#include <iostream>
#include <algorithm>
#include <queue>
using namespace std;
class Node
{
public:
int key;
int height; // Высота поддерева с корнем в этом узле
Node* left;
Node* right;
Node(int key) : key(key), height(1), left(nullptr), right(nullptr) {}
};
// Класс дерева АВЛ
class Avl_tree
{
private:
Node* root;
int height(Node* node)
{
return node ? node->height : 0;
}
int balanceFactor(Node* node)
{
return height(node->right) - height(node->left);
}
void updateHeight(Node* node)
{
node->height = 1 + max(height(node->left), height(node->right));
}
Node* rotateRight(Node* y)
{
Node* x = y->left;
Node* T2 = x->right;
x->right = y;
y->left = T2;
updateHeight(y);
updateHeight(x);
return x;
}
Node* rotateLeft(Node* x)
{
Node* y = x->right;
Node* T2 = y->left;
y->left = x;
x->right = T2;
updateHeight(x);
updateHeight(y);
return y;
}
Node* balance(Node* node)
{
updateHeight(node);
if (balanceFactor(node) == 2) // правое поддерево >
{
if (balanceFactor(node->right) < 0) // левый узел тяжелее
{
node->right = rotateRight(node->right); // из правый-левый в левый-левый
}
return rotateLeft(node);
}
if (balanceFactor(node) == -2) // левое поддерево >
{
if (balanceFactor(node->left) > 0) // правый узел тяжелее
{
node->left = rotateLeft(node->left); // из левый-правый в правый-правый
}
return rotateRight(node);
}
return node;
}
Node* insert(Node* node, int key)
{
if (!node)
{
return new Node(key);
}
if (key < node->key)
{
node->left = insert(node->left, key);
}
else
{
node->right = insert(node->right, key);
}
return balance(node); // Балансировка после вставки
}
Node* findMin(Node* node)
{
return node->left ? findMin(node->left) : node;
}
Node* remove(Node* node, int key)
{
if (!node)
{
return nullptr;
}
if (key < node->key)
{
node->left = remove(node->left, key);
}
else if (key > node->key)
{
node->right = remove(node->right, key);
}
else
{
Node* left = node->left;
Node* right = node->right;
delete node;
if (!right)
{
return left;
}
Node* minNode = findMin(right);
minNode->right = removeMin(right);
minNode->left = left;
return balance(minNode);
}
return balance(node);
}
Node* removeMin(Node* node)
{
if (!node->left)
{
return node->right;
}
node->left = removeMin(node->left);
return balance(node);
}
public:
Avl_tree() : root(nullptr) {}
void insert(int key)
{
root = insert(root, key);
}
void remove(int key)
{
root = remove(root, key);
}
void printTree() {
if (!root) {
cout << "Дерево пусто." << endl;
return;
}
queue<Node*> q;
q.push(root);
while (!q.empty()) {
int levelSize = q.size();
for (int i = 0; i < levelSize; i++) {
Node* node = q.front();
q.pop();
cout << node->key << " ";
if (node->left) {
q.push(node->left);
}
if (node->right) {
q.push(node->right);
}
}
cout << endl;
}
}
};
int main()
{
Avl_tree tree;
tree.insert(10);
tree.insert(20);
tree.insert(30);
tree.insert(55);
tree.insert(60);
tree.insert(70);
tree.insert(80);
tree.remove(20);
tree.remove(10);
tree.printTree();
return 0;
}
Хеширование данных
Хэш таблица представляет собой эффективную структуру данных для реализации словарей. Хотя на поиск элемента в хэш таблице в наихудшем случае может потребоваться столько же времени что и в связанном списке О(n) на практике хеширование является намного эффективнее. Три вполне обоснованных допущениях математическое ожидания времени поиска элемента хэш таблицы составляют О(1).

Термин hashing или scatter storage означает в переводе крошить, размалывать, рассеивать. Идея хеширования состоит в использовании некоторой частичной информации полученной из ключа в качестве основы поиска т.е. вычисляется хэш адрес h(key) который используется для поиска хэш таблицы. Хэш таблица представляется собой обобщение обычного массива.
Возможность прямой индексации элементов обычного массива обеспечивает доступ к произвольной позиции в массиве за время О(1).
Прямая индексация применима если мы в состоянии выделить массив размера в остаточного для того, чтобы для каждого возможного значения ключа имелось своя ячейка.
Если количество реально хранящихся в массиве ключей мало по сравнению с количеством возможных значений ключа эффективно альтернативой массива с прямой индексацией становится хэш таблица, которая обычно использует массив с размером пропорциональным количеству реально хранящихся в нем ключей. В место непосредственного использования ключа в качестве индекса массива, индекс вычисляется по значению ключа.
Прямая адресация представляет собой простейшую технологию, которая хорошо работает для небольших множеств ключей.
Предположим что требуется динамическое множество каждый элемент которого имеет ключ из множества от 0 до N-1. Где значение m не велико. Кроме того предполагается что никакие 2 элемента не имеют одинаковых ключей.
Для представления динамического множества мы используем массив или таблицу с прямой адресацией. Которую обозначим как T[0…m-1] . Каждая позиция или ячейка которого соответствуют ключу из пространства ключей множества О.

Недостаток прямой адресации очевиден: если пространство ключей U велико, хранение таблицы T размером |U| непрактично, а то и вовсе невозможно — в зависимости от количества доступной памяти и размера пространства ключей. Кроме того, множество K реально сохраненных ключей может быть мало по сравнению ´ с пространством ключей U, а в этом случае память, выделенная для таблицы T, в основном расходуется напрасно.
Когда множество K хранящихся в словаре ключей гораздо меньше пространства возможных ключей U, хеш-таблица требует существенно меньше места, чем таблица с прямой адресацией. Точнее говоря, требования к памяти могут быть снижены до Θ (|K|), при этом время поиска элемента в хеш-таблице остается равным O (1).
В случае прямой адресации элемент с ключом k хранится в ячейке k. При хешировании этот элемент хранится в ячейке h (k), т.е. мы используем хеш-функцию h для вычисления ячейки для данного ключа k. Функция h отображает пространство ключей U на ячейки хеш-таблицы T [0..m − 1]: h : U → {0, 1,...,m − 1}. Мы говорим, что элемент с ключом k хешируется в ячейку h (k); величина h (k) называется хеш-значением ключа k. На рис. 11.2 представлена основная идея хеширования. Цель хеш-функции состоит в том, чтобы уменьшить рабочий диапазон индексов массива, и вместо |U| значений мы можем обойтись всего лишь m значениями. Соответственно снижаются и требования к количеству памяти.
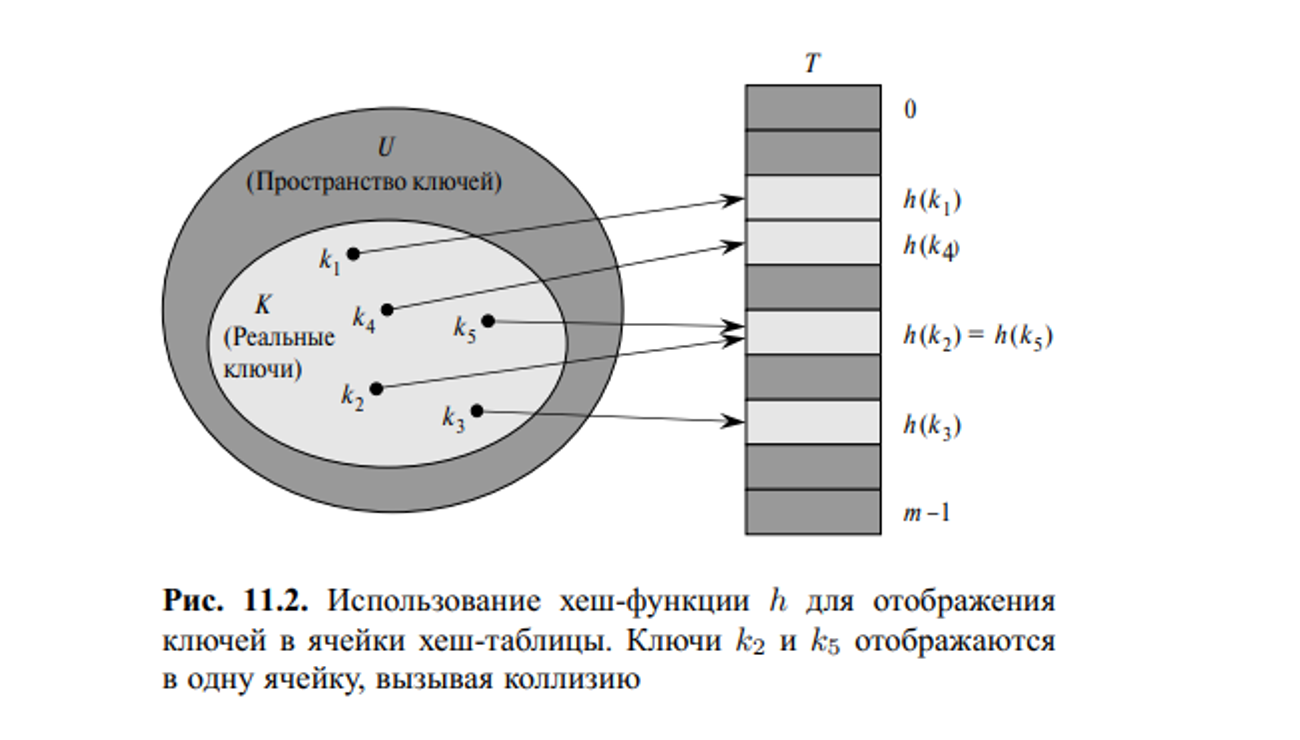
Однако здесь есть одна проблема: два ключа могут быть хешированы в одну и ту же ячейку. Такая ситуация называется коллизией, что может привезти к конфликтам.
Качественная хеш-функция удовлетворяет (приближенно) предположению простого равномерного хеширования: для каждого ключа равновероятно помещение в любую из m ячеек, независимо от хеширования остальных ключей.
Иногда распределение вероятностей оказывается известным. Например, если известно, что ключи представляют собой случайные действительные числа, равномерно распределенные в диапазоне 0 ≤ k≤1, то хеш-функция h(k) = |k| удовлетворяет условию простого равно- мерного хеширования.
На практике при построении качественных хеш-функций зачастую используются различные эвристические методики. В процессе построения большую помощь оказывает информация о распределении ключей. Рассмотрим, например, таблицу символов компилятора, в которой ключами служат символьные строки, представляющие идентификаторы в программе. Зачастую в одной программе встречаются похожие идентификаторы, например, pt и pts. Хорошая хеш–функция должна минимизировать шансы попадания этих идентификаторов в одну ячейку хеш- таблицы.
Построение хеш-функции методом деления
Построение хеш-функции методом деления ******состоит в отображении ключа k в одну из ячеек путем получения остатка от деления k на m, т.е. хеш-функция имеет вид h (k) = k mod m.
Например, если хеш-таблица имеет размер m = 12, а значение ключа k = 100, то h (k) = 4. Поскольку для вычисления хеш-функции требуется только одна операция деления, хеширование методом деления считается достаточно быстрым. При использовании данного метода мы обычно стараемся избегать некоторых значений m. Например, m не должно быть степенью 2, поскольку если m = 2р, то h (к) представляет собой просто р младших битов числа k. Если только заранее неизвестно, что все наборы младших р битов ключей равновероятны, лучше строить хеш-функцию таким образом, чтобы ее результат зависел от всех битов ключа.
Построение хеш-функции методом умножения
Построение хеш-функции методом умножения выполняется в два этапа. Сначала мы умножаем ключ k на константу 0 < А < 1 и полу- чаем дробную часть полученного произведения. Затем мы умножаем полученное значение на m применяем к нему функцию "floor" т.е.
h(k)= |m(kA mod 1)|,
где выражение "kА mod 1" означает получение дробной части произведения kА, т.е. величину k А - |kА|.
Достоинство метода умножения заключается в том, что значение m перестает быть критичным. Обычно величина m из соображений удобства реализации функции выбирается равной степени 2.
Если недоброжелатель будет умышленно выбирать ключи для хеширования при помощи конкретной хеш-функции, то он сможет подобрать n значений, которые будут хешироваться в одну и ту же ячейку таблицы, приводя к среднему времени выборки Θ(n). Таким образом, любая фиксированная хеш-функция становится уязвимой, и единственный эффективный выход из ситуации – случайный выбор хеш-функции, не зависящий от того, с какими именно ключами ей предстоит работать. Такой подход, который называется универсальным хешированием, гарантирует хорошую производительность в среднем, независимо от того, какие данные будут выбраны злоумышленником.
h[ab] (k) = ((ak + b) mod p) mod m
Этот класс хеш-функций обладает тем свойством, что размер m выходного диапазона произволен и не обязательно представляет со- бой простое число.. Поскольку число, а можно выбрать р - 1 способом, и р способами – число b, всего в данном семействе будет содержаться р (р - 1) хеш-функций.
Разрешение коллизий при помощи цепочек При использовании данного метода мы объединяем все элементы, хешированные в одну и ту же ячейку, в связанный список
Открытая адресации При использовании метода открытой адресации все элементы хранятся непосредственно в хеш-таблице, т.е. каждая запись таблицы содержит либо элемент динамического множества, либо значение NIL. При поиске элемента мы систематически проверяем ячейки таблицы до тех пор, пока не найдем искомый элемент или пока не убедимся в его отсутствии в таблице.
Линейное исследование
Квадратичное исследование
Двойное хеширование
Граф
Граф - это математическая абстракция реальной системы любой природы, объекты которой обладают парными связями. Граф, как математический объект, есть совокупность двух множеств. Множества вершин и множества ребер (парных связей/дуги).
Простой граф G(V, E) есть совокупность двух множеств. Негустого множества V и множества E неупорядоченных пар различных элементов множества V. Множество V называют множеством вершин, множество E называют множеством ребер. V - не пустое множество.
Ориентированный граф состоит из множества вершин и множества V, E, здесь E - ориентированные ребра. Ребро или дуга представляется в виде упорядоченных пар вершин (v, w), где v - начальная вершина, w - конец дуги, v->w: говорят, что дуга ведёт от вершины v к вершине w, а вершина w смежная с вершиной v.
Пример ориентированного графа:
Вершину ориентированного графа можно использовать для представления объектов, а дуги для отношений между объектами. Путем в ориентированном грфе называется последовательность вершин V1, V2, ..., Vn, для которой существуют в дуги V1->V2, ... , Vn-1->Vn. Этот путь начинается в вершине V1 и проходя через вершины V2, Vn-1 заканчивается в вершине Vn. Длина пути - это количество дуг, составляющих путь. В данном случае длина души равна n-1. Путь называется простым, если все вершины на нем, за исключением может быть первой и последней, различны. Цикл - это простой путь длины не менее единицы, которая начинается и заканчивается в одной и той же вершине.
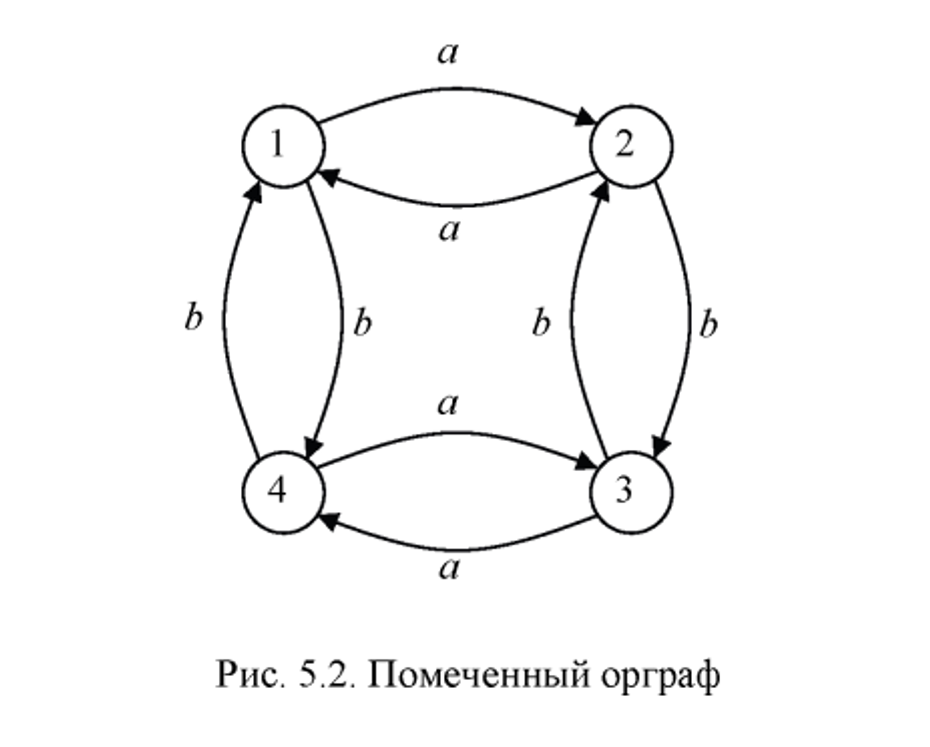
Помеченным ориентированным графом называется граф, у которого каждая дуга или каждая вершина имеет соответствующие метки. Меткой может быть имя, вес или стоимость дуги или значение данных какого-либо заданного типа. В помеченным ориентированном графе вершина может иметь как имя, так и метку.
Представления ориентированных графов.
Для представления ориентированных графов можно использовать различные структуры графов. Выбор структур данных зависит от операторов, которые будут применяться к вершинам и дугам ориентированных графов. Одним из наиболее общих представлений ориентированных графов является матрица смежности. Предположим, что множество вершин равна V={1,2,3,n}. Матрица смежности для данного ориентированного графа это матрица А={N,M}, со значением рулевого типа, где А[i,j]=true тогда и только тогда, когда существует дуга из вершины i до вершины j. Часто в матрицах смежности значение true обозначается 1, а false значением 0. Время доступа к элементам матрицы смежности зависит от размеров множества вершин и множества дуг. Основной недостаток использования матрицы смежности заключается в том, что она требует О(n^2) памяти, даже если дуг значительно меньше, чем n^2.

Вместо матрицы смежности часто используется представление посредством списком смежности. Списком смежности для вершины i называется список всех вершин смежных с вершиной i, причем определенным образом упорядоченный. Таким образом, ориентированный граф G можно представить посредством массива HEAD(заголовок), чей элемент HEAD[i] является указателем на список смежности вершины i. Представление ориентированного графа с помощью списков смежности требует для хранения объем памяти пропорциональный сумме количества вершин и количества дуг. Если количество дуг имеет порядок О(n), то и общий объем необходимой памяти имеет такой же порядок.
Для вставки и удаления элементов в списке смежности необходимо иметь массив HEAD, содержащий указатель на ячейки заголовков списков смежности, но не сами смежные вершины.
#include <iostream>
#include <limits>
#include <vector>
#include <queue>
#include <map>
using namespace std;
const int MAX_VERTICES = 6;
const int MAX_EDGES = 10;
const int INF = numeric_limits<int>::max();
struct Edge {
int to;
int weight;
};
struct Vertex {
Edge edges[MAX_EDGES];
int edgeCount;
};
class DirectedGraph {
private:
Vertex vertices[MAX_VERTICES];
int vertexCount;
bool visited[MAX_VERTICES];
map<int, char> indexToChar;
int dist[MAX_VERTICES];
void DFSUtil(int v) {
visited[v] = true;
cout << indexToChar[v] << " ";
for (int i = 0; i < vertices[v].edgeCount; ++i) {
int to = vertices[v].edges[i].to;
if (!visited[to]) {
DFSUtil(to);
}
}
}
public:
DirectedGraph(int numVertices) : vertexCount(numVertices) {
for (int i = 0; i < vertexCount; ++i) {
vertices[i].edgeCount = 0;
indexToChar[i] = 'A' + i;
dist[i] = INF;
}
}
void addEdge(char from, char to, int weight) {
int fromIndex = from - 'A';
int toIndex = to - 'A';
if (fromIndex >= 0 && fromIndex < vertexCount && vertices[fromIndex].edgeCount < MAX_EDGES) {
vertices[fromIndex].edges[vertices[fromIndex].edgeCount++] = Edge{ toIndex, weight };
}
}
void DFS(char startVertex) {
fill(visited, visited + MAX_VERTICES, false);
DFSUtil(startVertex - 'A');
}
void BFS(char startVertex) {
fill(visited, visited + MAX_VERTICES, false);
queue<int> queue;
int startIndex = startVertex - 'A';
visited[startIndex] = true;
queue.push(startIndex);
while (!queue.empty()) {
int v = queue.front();
cout << indexToChar[v] << " ";
queue.pop();
for (int i = 0; i < vertices[v].edgeCount; ++i) {
int to = vertices[v].edges[i].to;
if (!visited[to]) {
visited[to] = true;
queue.push(to);
}
}
}
}
void printGraph() {
for (int i = 0; i < vertexCount; ++i) {
cout << "Вершина " << indexToChar[i] << " соединена: ";
for (int j = 0; j < vertices[i].edgeCount; ++j) {
cout << "(" << indexToChar[vertices[i].edges[j].to] << ", " << vertices[i].edges[j].weight << ") ";
}
cout << endl;
}
}
void dijkstra(char startVertex) {
int startIndex = startVertex - 'A';
dist[startIndex] = 0;
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> pq;
pq.push({ 0, startIndex });
while (!pq.empty()) {
int u = pq.top().second;
pq.pop();
for (int i = 0; i < vertices[u].edgeCount; ++i) {
int v = vertices[u].edges[i].to;
int weight = vertices[u].edges[i].weight;
if (dist[u] != INF && dist[u] + weight < dist[v]) {
dist[v] = dist[u] + weight;
pq.push({ dist[v], v });
}
}
}
cout << "Кратчайшие расстояния от вершины " << startVertex << ":" << endl;
for (int i = 0; i < vertexCount; ++i) {
cout << startVertex << " -> " << indexToChar[i] << " = ";
if (dist[i] == INF)
cout << "INF" << endl;
else
cout << dist[i] << endl;
}
}
};
int main() {
setlocale(LC_ALL, "Rus");
DirectedGraph graph(MAX_VERTICES);
/*
graph.addEdge('A', 'B', 4);
graph.addEdge('A', 'C', 2);
graph.addEdge('B', 'E', 3);
graph.addEdge('C', 'D', 4);
graph.addEdge('B', 'F', 3);
*/
graph.addEdge('A', 'B', 7);
graph.addEdge('A', 'C', 2);
graph.addEdge('B', 'D', 2);
graph.addEdge('C', 'D', 5);
graph.addEdge('C', 'E', 4);
graph.addEdge('D', 'E', 2);
graph.printGraph();
cout << "Глубина обхода с A: ";
graph.DFS('A');
cout << endl;
cout << "Ширина обхода с A: ";
graph.BFS('A');
cout << endl;
cout << "Поиск кратчайших путей с помощью алгоритма Дейкстры:" << endl;
graph.dijkstra('A');
return 0;
}Задача нахождения кратчайшего пути
В конце 1950-х годов Эдгар Дейкстра и Прим, работая и публикуя свои результаты независимо друг от друга, предложили следующий алгоритм построения МОД. Воспользуемся для поиска МОД так называемым «жадным» алгоритмом. Жадные алгоритмы действуют, используя в каждый момент лишь часть исходных данных и принимая лучшее решение на основе этой части. В нашем случае мы будем на каждом шаге рассматривать множество ребер, допускающих присоединение к уже построенной части остовного дерева, и выбирать из них ребро с наименьшим весом. Повторяя эту процедуру, мы получим остовное дерево с наименьшим весом.
Разобьем вершины графа на 3 класса:
1) Вершины, вошедшие в уже построенную часть дерева
2) Вершины, окаймляющие построенную часть
3) Еще не рассмотренные вершины
Инициализация: Выбирается произвольная вершина графа, которая включается в остовное дерево. Все вершины, соединённые с выбранной, добавляются в список кандидатов (кайму).
Поиск ребра: На каждом шаге алгоритма из каймы выбирается ребро с наименьшим весом, которое соединяет вершину в остовном дереве с вершиной вне дерева.
Добавление вершины: Выбранное ребро и соответствующая вершина добавляются в остовное дерево. Кайма обновляется новыми рёбрами, соединяющими новую вершину с остальными вершинами графа, которые ещё не включены в дерево.
Повторение: Шаги 2 и 3 повторяются до тех пор, пока все вершины графа не будут включены в остовное дерево.
Завершение: Когда все вершины включены в остовное дерево, алгоритм завершается.
Важно отметить, что алгоритм Прима эффективен для плотных графов, где количество рёбер значительно превышает количество вершин. Он гарантирует нахождение минимального остовного дерева, если все веса рёбер различны, или одного из минимальных остовных деревьев, если некоторые веса совпадают.




Дейкстры-Прима начинает построение МОД с конкретной вершины графа и постепенно расширяет построенную часть дерева; в отличие от него алгоритм Крускала делает упор на ребрах графа. В этом алгоритме мы начинаем с пустого дерева и добавляем к нему ребра в порядке возрастания их весов пока не получим набор ребер, объединяющий все вершины графа. Если ребра закончатся до того, как все вершины будут соединены между собой, то это означает, что исходный граф был несвязным, и полученный нами результат представляет собой объединение МОД всех его компонент связности.


При рассмотрении ребер весом = 6, 2 из 4 ребер весом 6 стоит отбросить, поскольку их добавление приведет к появлению цикла в уже построенной части mod. Присоединение ребра CF создало бы цикл содержащий вершину А. Присоединение ребра BD создало бы цикл содержащий вершины А и F.
Алгоритм поиска кратчайшего пути
Результатом алгоритма поиска кратчайшего пути является последовательность ребер соединяющая заданные две вершины и имеющие наименьшую длину среди всех таких последовательностей.

Задача найти кратчайший путь от А до G.




На данном примере мы имеем дело с полным деревом кратчайших путей, поскольку конечная вершина G была добавлена к дереву последней. Если бы мы добрались до нее раньше, алгоритм бы тотчас завершил свою работу.
Могут возникнуть ситуации в которых нас интересуют кратчайшие пути из данной вершины во все остальные, если например мы имеем дело с небольшой компьютерной сетью, скорость и передача данных между узлами которой приблизительно постоянно, то для каждого из компьютеров данной сети мы можем выбрать кратчайший путь для каждого из остальных компьютеров, поэтому при необходимости переслать сообщение, единственное что нам потребуется это воспользоваться заранее рассчитанным наиболее эффективным путем.
Алгоритмы современные
Современные алгоритмы обработки данных
В настоящее время эффективные алгоритмы разрабатываются в рамках научного направления, которое можно назвать (природные вычисления), объединяющего такие разделы, как генетические алгоритмы, эволюционное программирование, нейросетевые вычисления, клеточные автоматы и ДНК вычисления, муравьиные алгоритмы. Исследователи обращаются к природным механизмам, которые миллионы лет обеспечивают адаптацию биоценозов к окружающей среде. Одним из таких механизмов, имеющих фундаментальный характер, является механизм наследственности. Его использование для решения задач оптимизации привело к появлению генетических алгоритмов.
Алгоритм решения задач оптимизации, основанный на идеях наследственности в биологических популяциях, был впервые предложен Джоном Холландом (1975). Он получил название репродуктивного плана Холланда, и широко использовался как базовый алгоритм в эволюционных вычислениях.
Цель генетического алгоритма при решении задачи оптимизации состоит в том, чтобы найти лучшее возможное, но не гарантированно оптимальное решение. Для реализации генетического алгоритма необходимо выбрать подходящую структуру данных для представления решений. В постановке задачи поиска оптимума, экземпляр этой структуры должен содержать информацию о некоторой точке в пространстве решений.
Структура данных генетического алгоритма состоит из набора хромосом. Хромосома, как правило, представляет собой битовую строку, так что термин строка часто заменяет понятие «хромосома». Хромосомы генетических алгоритмов не ограничены только бинарным представлением. Известны другие реализации, построенные на векторах вещественных чисел.
Для иллюстрации идеи мы ограничимся только структурами, которые являются битовыми строками. Каждая хромосома (строка) представляет собой последовательное объединение ряда подкомпонентов, которые называются генами. Гены расположены в различных позициях или локусах хромосомы, и принимают значения, называемые аллелями - это биологическая терминология. В представлении хромосомы бинарной строкой, ген является битом этой строки, локус - есть позиция бита в строке, а аллель - это значение гена, равное 0 или 1.
Чтобы решить задачу оптимизации нужно задать некоторую меру качества для каждой структуры в пространстве поиска. Для этой цели используется функция приспособленности. При максимизации целевая функция часто сама выступает в качестве функции приспособленности, для задач минимизации целевая функция инвертируется и смещается в область положительных значений.
Рассмотрим фазы работы простого генетического алгоритма. В начале случайным образом генерируется начальная популяция (набор хромосом). Работа алгоритма представляет собой итерационный процесс, который продолжается до тех пор, пока не будет смоделировано заданное число поколений или выполнен некоторый критерий останова. В каждом поколении реализуется пропорциональный отбор приспособленности, одноточечная рекомбинация и вероятностная мутация. Пропорциональный отбор реализуется путем назначения каждой особи (хромосоме) i вероятности Р(і), равной отношению ее приспособленности к суммарной приспособленности популяции (по целевой функции):

Основные шаги генетического алгоритма
1. Создать начальную популяцию
2. Цикл по поколениям пока не выполнено условие останова // цикл жизни одного поколения
3. Оценить приспособленность каждой особи
4. Выполнить отбор по приспособленности
5. Случайным образом разбить популяцию на две группы пар
6 . Выполнить фазу вероятностной рекомбинации для пар популяции и заменить родителей
7. Выполнить фазу вероятностной мутации
8 . Оценить приспособленность новой популяции и вычислить условие останова
9. Объявить потомков новым поколением
10. Конец цикла по поколениям
Модификации генетического алгоритма
метод турнирного отбора
двухточечная рекомбинация
равномерная рекомбинация
Применение генетических алгоритмов
Генетический алгоритм может стать эффективной процедурой поиска оптимального решения, если: • пространство поиска достаточно велико, и предполагается, что целевая функция не является гладкой и унимодальной в области поиска, т.е. не содержит один гладкий экстремум • задача не требует нахождения глобального оптимума, необходимо достаточно быстро найти приемлемое «хорошее» решение, что довольно часто встречается в реальных задачах.
Сегодня генетические алгоритмы успешно применяются для решения классических AP-полных задач, задач оптимизации в пространствах с большим количеством измерений, ряда экономических задач оптимального характера, например, задач распределения инвестиций.
Муравьиные алгоритмы представляют собой новый перспективный метод решения задач оптимизации, в основе которого лежит моделирование поведения колонии муравьев. Колония представляет собой систему с очень простыми правилами автономного поведения особей. Однако, несмотря на примитивность поведения каждого отдельного муравья, поведение всей колонии оказывается достаточно разумным. Исследования в этой области начались в середине 90-х годов XX века, автором идеи является Марко Дориго из Университета Брюсселя, Бельгия.
Биологические принципы поведения муравьиной колонии
Коллектив муравьев называется колонией. Число муравьев в колонии может достигать нескольких миллионов. Одним из подтверждений оптимальности поведения колоний является тот факт, что сеть гнезд суперколоний близка к минимальному остовному дереву графа их муравейников. Колония не имеет централизованного управления, и ее особенностями является обмен локальной информацией только между отдельными особями и наличие непрямого обмена, который и используется в муравьиных алгоритмах.
Непрямой обмен - стигмержи (stigmergy), представляет собой разнесенное во времени взаимодействие, при котором одна особь изменяет некоторую область окружающей среды, а другие используют эту информацию позже, в момент, когда они в нее попадают. Концентрация феромона на тропе определяет предпочтительность движения по ней.
Идея муравьиного алгоритма — моделирование поведения муравьев, связанное с их способностью быстро находить кратчайший путь от муравейника к источнику пищи и адаптироваться к изменяющимся условиям, находя новый кратчайший путь. При своем движении муравей метит свой путь феромоном, и эта информация используется другими муравьями для выбора пути. Это элементарное правило поведения и определяет способность муравьев находить новый путь, если старый оказывается недоступным. Дойдя до преграды, муравьи с равной вероятностью будут обходить ее справа и слева. То же самое будет происходить и на обратной стороне преграды. Однако, те муравьи, которые случайно выберут кратчайший путь, будут быстрее его проходить, и за несколько передвижений он будет более обогащен феромоном. Поскольку движение муравьев определяется концентрацией феромона, то следующие будут предпочитать именно этот путь, продолжая обогащать его феромоном. Очевидная положительная обратная связь быстро приведет к тому, что кратчайший путь станет единственным маршрутом движения большинства муравьев. Моделирование испарения феромона — отрицательной обратной связи, гарантирует нам, что найденное локально оптимальное решение не будет единственным - муравьи будут искать и другие пути. Если мы моделируем процесс такого поведения на некотором графе, ребра которого представляют собой возможные пути перемещения муравьев, в течение определенного времени, то наиболее обогащенный феромоном путь по ребрам этого графа и будет являться решением задачи, полученным с помощью муравьиного алгоритма.
Параллельные алгоритмы
Компьютерные системы можно разделить на четыре основных категории. Для этого нужно несколько сменить наше представление о том, как работает программа. С точки зрения центрального процессора программа представляет собой поток инструкций, которые следует расшифровать и выполнить. Данные тоже можно считать поступающими в виде потока. Четыре категории, о которых мы говорим, определяются тем, поступают ли программы и данные одним потоком или несколькими.
Один поток инструкций / Один поток данных
Модель Один поток инструкций / Один поток данных (SISD) представляет собой классическую модель с одним процессором. К ней относятся как компьютеры предыдущих поколений, так и многие современные компьютеры. Процессор такого компьютера способен выполнять в любой момент времени лишь одну инструкцию и работать лишь с одним набором данных. В таких последовательных системах никакого параллелизма нет в отличие от прочих категорий.
Один поток инструкций / Несколько потоков данных
В компьютерах с одним потоком инструкций и несколькими по- токами данных (SIMD) имеется несколько процессоров, выполняющих одну и ту же операцию, но над различными данными. SIMD- машины иногда называются также векторными процессорами, поскольку они хорошо приспособлены для операций над векторами, в которых каждому процессору передается одна координата вектора и после выполнения операции весь вектор оказывается обработанным. Например, сложение векторов покоординатная операция. Первая координата суммы векторов — сумма первых координат суммируемых векторов, вторая — сумма вторых координат, и т.д. В нашей SIMD- машине каждый процессор получит инструкцию сложить пару координат входных векторов. После выполнения этой единственной инструкции результат будет подсчитан полностью. Заметим, что на векторе из N элементов SISD-машине потребуется выполнить N итераций цикла, а SIMD-машине с не менее, чем N процессорами, хватит одной операции.
Несколько потоков инструкций / Один поток данных
Возможность одновременно выполнять различные операции над одними и теми же данными может поначалу показаться странной: не так уж часто встречаются программы, в которых нужно какое-то значение возвести в квадрат, умножить на 2, вычесть из него 10 и т.д. Однако, если посмотреть на эту ситуацию с другой точки зрения, то мы увидим, что на машинах такого типа можно усовершенствовать проверку числа на простоту . Если число процессоров равно N, то мы можем проверить простоту любого числа между 1 и Л^ на MISD-машине за одну операцию: если число X составное, то у него должен быть делитель, не превосходящий \fX. Для проверки простоты числа X < 7V поручим первому процессору делить на 2, второму — делить на 3, третьему - на 4, и так до процессора с номером К — 1, который будет делить на К, где К = [Л/А]. Если на одном из этих процессоров деление нацело проходит успешно, то число X составное. Поэтому мы достигаем результата за одну операцию.
Несколько потоков инструкций / Несколько потоков данных
Это наиболее гибкая из категорий. В случае MIMD-систем мы имеем дело с несколькими процессорами, каждый из которых способен выполнять свою инструкцию. Кроме того имеется несколько потоков данных, и каждый процессор может работать со своим набором данных. На практике это означает, что MIMD-система может выполнять на каждом процессоре свою программу или отдельные части одной и той же программы, или векторные операции так же, как и SIMD- конфигурация. Большинство современных подходов к параллелизму - включая кластеры компьютеров и мультипроцессорные системы — лежат в категории MIMD.
В архитектуре параллельных компьютерных систем основную роль играют два аспекта: как связаны между собой процессоры и их память и как процессоры взаимодействуют. Об этих аспектах мы и будем говорить при обсуждении параллельных алгоритмов, поскольку те или иные решения могут иметь разную эффективность для различных задач.
Слабо и сильно связанные машины
В машинах со слабой связью у каждого процессора есть своя собственная память, а связь между процессорами осуществляется по «сетевым» кабелям. Это архитектура компьютерных кластеров: каждый компьютер кластера представляет собой отдельную компьютерную систему и может работать самостоятельно. Параллелизм осуществляется за счет распределения заданий по компьютерам кластера центральным управляющим компьютером. В машинах с тесными связями все процессоры пользуются общей центральной памятью. Взаимодействие процессоров осуществляется за счет того, что один из них записывает информацию в общую память, а остальные считывают ее оттуда.
Принципы анализа параллельных алгоритмов
При работе с параллельными алгоритмами нас будут интересовать два новых понятия: коэффициент ускорения и стоимость.
Коэффициент ускорения параллельного алгоритма показывает, насколько он работает быстрее оптимального последовательного алгоритма. Так, мы видели, что оптимальный алгоритм сортировки требует O(Nlog N) операций. У параллельного алгоритма сортировки со сложностью O(N) коэффициент ускорения составил бы О (log N). Второе интересующее нас понятие — стоимость параллельного ал- горитма, которую мы определяем как произведение сложности алгоритма на число используемых процессоров. Если в нашей ситуации алгоритм параллельной сортировки за O(N) операций требует столько же процессоров, каково число входных записей, то его стоимость равна O(N ). Это означает, что алгоритм параллельной сортировки обходится дороже, поскольку стоимость алгоритма последовательной сортировки на одном процессоре совпадает с его сложностью и равна поэтому O(Nlog N). Близким понятием является расщепляемость задачи. Если единственная возможность для нашего алгоритма параллельной сортировки состоит в том, что число процессоров должно равняться числу входных записей, то такой алгоритм становится бесполезным как только число входных записей оказывается достаточно большим. Никаких похожих ограничений в алгоритме последовательной сортировки нет. По большей части нас будут интересовать такие алгоритмы параллельной сортировки, в которых число процессоров значительно меньше потенциального объема входных данных и это число не требует увеличения при росте длины входа.
Одна из проблем параллельных систем состоит в чтении данных из памяти и записи в память. Что произойдет, например, если два процессора попытаются записать данные в одно и то же место общей памяти? В рассмотренных нами в главах 2-6 алгоритмах предполагалось, что машина, на которой они реализуются, обладает прямым доступом к любой наперед заданной ячейке памяти (RAM). Алгоритмы этой главы будут основаны на параллельном варианте такой машины, называемом PRAM. Процессоры нашей PRAM-машины тесно связаны между собой и пользуются общим блоком памяти. В каждом процессоре есть несколько регистров, в которых может храниться небольшой объем данных, однако основная часть данных содержится в общей памяти. Помимо требования тесной связи между процессорами мы также будем предполагать, что все они осуществляют один и тот же цикл обработки, состоящий в чтении данных из памяти, выполнении операции над ними и записи результата в память. Это означает, что все процессоры одновременно читают память, одновременно обрабатывают про- читанные данные и одновременно производят запись. Спор за ячейки памяти может возникнуть как при чтении, так и при записи. Требование трехшагового цикла означает, что мы можем не беспокоиться, что произойдет, если процессор Y меняет содержимое ячейки памяти в то время, как процессор X обрабатывает только что прочитанные оттуда данные. Не может также возникнуть и ситуация, в которой один процессор читает содержимое ячейки памяти в тот момент, когда другой пытается что-либо записать в нее.