Алгоритм поиска (2 часть)
Алгоритм Кнутта-Морриса-Пратта (KMP) - это алгоритм поиска подстроки, который использует принцип сдвига образа для ускорения поиска. Он состоит из двух этапов:
- Формирование таблицы D: Эта таблица создается на основе образа (подстроки, которую мы ищем) и используется для определения величины сдвига образа при поиске. Размер таблицы равен длине образа.
- Поиск образа в строке: На этом этапе мы сравниваем символы образа и строки. Если символы не совпадают, образ сдвигается вправо.
#include <iostream>
#include <vector>
#include <cstring>
using namespace std;
void computeDTable(char* pattern, int M, vector<int>& d) {
int length = 0;
d[0] = -1;
for (int i = 1; i < M; i++) {
if (pattern[i] == pattern[length]) {
length++;
d[i] = length;
} else {
if (length != 0) {
length = d[length - 1];
i--;
} else {
d[i] = 0;
}
}
}
}
void KMPSearch(char* pattern, char* text) {
int M = strlen(pattern);
int N = strlen(text);
vector<int> d(M);
computeDTable(pattern, M, d);
int i = 0;
int j = 0;
while (i < N) {
if (pattern[j] == text[i]) {
j++;
i++;
}
if (j == M) {
cout << "Найден образ на индексе " << i - j << endl;
j = d[j - 1];
} else if (i < N && pattern[j] != text[i]) {
if (j != 0)
j = d[j - 1];
else
i = i + 1;
}
}
}
int main() {
setlocale(LC_ALL, "Ru");
char text[] = "ABABDABACDABABCABAB";
char pattern[] = "ABABCABAB";
KMPSearch(pattern, text);
return 0;
}Давайте рассмотрим пример работы алгоритма Кнутта-Морриса-Пратта (KMP) на примере поиска образа “ABABCABAB” в тексте “ABABDABACDABABCABAB”.
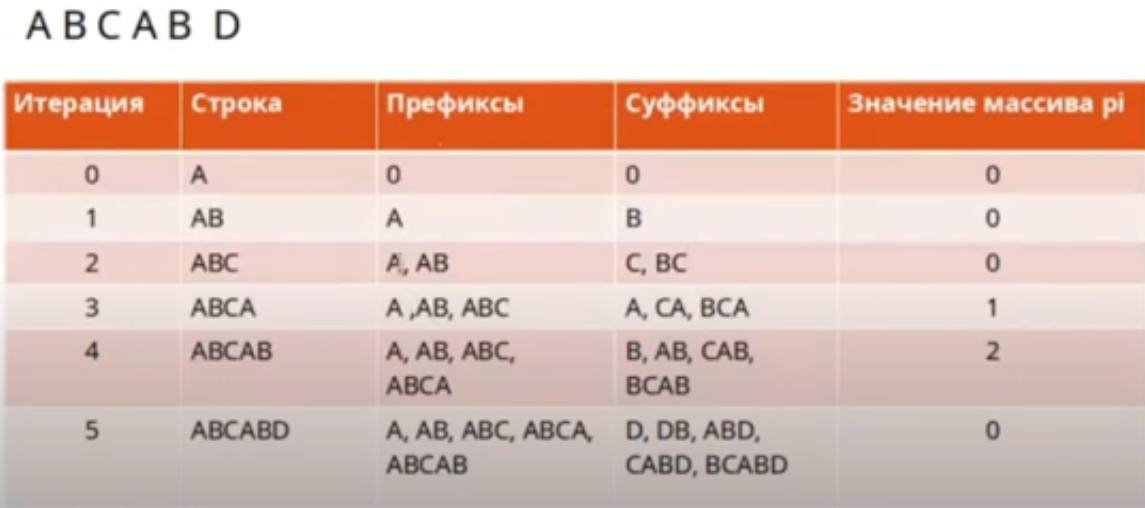
- Формирование таблицы D: На этом этапе мы создаем таблицу на основе образа. В нашем случае, образ - это “ABABCABAB”. Таблица D будет выглядеть так: [-1, 0, 0, 1, 2, 0, 1, 2, 3]. Эта таблица показывает, на сколько символов нужно сдвинуть образ в случае несовпадения символа.
- Поиск образа в строке: Теперь мы начинаем поиск образа в строке. Мы сравниваем символы образа и строки слева направо. Если символы совпадают, мы переходим к следующему символу. Если символы не совпадают, мы сдвигаем образ на величину, указанную в таблице D для этого символа.
В результате, мы находим образ “ABABCABAB” в тексте “ABABDABACDABABCABAB” на позиции 10.
Алгоритм Бойера-Мура улучшает поиск символов в тексте, используя только ( M + N ) сравнений, где ( M ) - длина шаблона, а ( N ) - длина текста. Это более эффективно, чем ( M * N ) сравнений, необходимых для прямого поиска. Проще говоря, алгоритм Бойера-Мура быстрее находит, где шаблон появляется в тексте, минимизируя количество сравнений.

Алгоритм Бойера-Мура - это способ быстро найти все вхождения некоторого короткого текста (называемого “образом”) внутри большого текста (называемого “строкой”). Вот как он работает:
- Подготовка: Прежде чем начать поиск, алгоритм создает специальную таблицу (называемую “таблицей D”), которая помогает определить, на сколько символов можно сдвинуть образ вправо, если текущий символ не совпадает. Это делается для ускорения поиска, чтобы не проверять каждый символ строки.
- Поиск: Когда начинается поиск, алгоритм сравнивает образ с частью строки, начиная с конца образа и двигаясь к началу. Если символы не совпадают, алгоритм использует таблицу D, чтобы сдвинуть образ вправо и пропустить некоторые символы строки, которые точно не подходят.
- Сдвиг: Если символы не совпадают, алгоритм смотрит на таблицу D и определяет, на сколько символов можно сдвинуть образ вправо. Это значение зависит от символа строки, который не совпал с образом.
- Продолжение поиска: Алгоритм продолжает сравнивать и сдвигать образ до тех пор, пока не найдет все совпадения или не дойдет до конца строки.
Этот метод эффективен, потому что он позволяет пропустить большую часть строки, не тратя время на сравнение каждого символа. В лучшем случае, когда символы образа всегда не совпадают с символами строки, количество сравнений может быть таким же маленьким, как количество символов в строке, деленное на количество символов в образе. Это делает алгоритм Бойера-Мура очень быстрым для поиска слов или фраз в больших текстах.
#include <iostream>
#include <cstring>
using namespace std;
// Функция для создания таблицы сдвигов
void createShiftTable(int* shiftTable, const char* pattern, int patternLength) {
// Инициализация таблицы сдвигов
for (int i = 0; i < 256; ++i) {
shiftTable[i] = patternLength;
}
// Обновление таблицы сдвигов на основе образца
for (int i = 0; i < patternLength - 1; ++i) {
shiftTable[(unsigned char)pattern[i]] = patternLength - i - 1;
}
}
// Функция поиска образца в строке
void boyerMooreSearch(const char* text, const char* pattern) {
int patternLength = strlen(pattern);
int textLength = strlen(text);
// Создание таблицы сдвигов
int* shiftTable = new int[256];
createShiftTable(shiftTable, pattern, patternLength);
int i = 0; // Индекс в тексте
while (i <= textLength - patternLength) {
int j = patternLength - 1; // Индекс в образце
// Сравниваем текст с образцом справа налево
while (j >= 0 && pattern[j] == text[i + j]) {
--j;
}
if (j < 0) {
// Образец найден, выводим индекс начала образца в тексте
cout << "Образец найден на позиции: " << i << endl;
// Сдвигаем образец на длину образца вправо
i += patternLength;
} else {
// Сдвигаем образец на значение из таблицы сдвигов
i += shiftTable[(unsigned char)text[i + j]];
}
}
// Освобождаем память
delete[] shiftTable;
}
int main() {
const char* text = "Здесь мы ищем образец 'образец' в тексте";
const char* pattern = "образец";
boyerMooreSearch(text, pattern);
return 0;
}
Алгоритмы Бойера-Мура и Кнута-Морриса-Пратта (KMP) оба предназначены для поиска подстроки в строке, но они используют разные подходы:
- Алгоритм Бойера-Мура:
- Сканирование текста выполняется справа налево.
- Использует две эвристики: “плохой символ” и “хороший суффикс”, которые помогают быстро сдвигать образ вправо, пропуская неподходящие части текста.
- Эффективен, когда алфавит символов велик, так как вероятность совпадения символов меньше, что позволяет делать большие сдвиги.
- Алгоритм KMP:
- Сканирование текста выполняется слева направо.
- Использует таблицу префиксов для определения, на сколько символов можно сдвинуть образ в случае несовпадения, без необходимости повторного сравнения уже проверенных символов.
- Эффективен, когда есть много повторяющихся символов в образе, так как позволяет избежать повторного сравнения этих символов.
В общем, алгоритм Бойера-Мура обычно быстрее на практике, особенно когда образ длинный и когда алфавит символов большой. Однако, KMP может быть более предпочтительным в случаях, когда образ содержит много повторяющихся символов или когда алфавит символов мал. Оба алгоритма имеют свои преимущества в зависимости от контекста задачи.