Хеширование данных
Хэш таблица представляет собой эффективную структуру данных для реализации словарей. Хотя на поиск элемента в хэш таблице в наихудшем случае может потребоваться столько же времени что и в связанном списке О(n) на практике хеширование является намного эффективнее. Три вполне обоснованных допущениях математическое ожидания времени поиска элемента хэш таблицы составляют О(1).
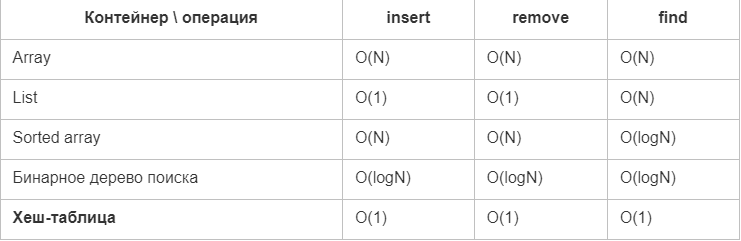
Термин hashing или scatter storage означает в переводе крошить, размалывать, рассеивать. Идея хеширования состоит в использовании некоторой частичной информации полученной из ключа в качестве основы поиска т.е. вычисляется хэш адрес h(key) который используется для поиска хэш таблицы. Хэш таблица представляется собой обобщение обычного массива.
Возможность прямой индексации элементов обычного массива обеспечивает доступ к произвольной позиции в массиве за время О(1).
Прямая индексация применима если мы в состоянии выделить массив размера в остаточного для того, чтобы для каждого возможного значения ключа имелось своя ячейка.
Если количество реально хранящихся в массиве ключей мало по сравнению с количеством возможных значений ключа эффективно альтернативой массива с прямой индексацией становится хэш таблица, которая обычно использует массив с размером пропорциональным количеству реально хранящихся в нем ключей. В место непосредственного использования ключа в качестве индекса массива, индекс вычисляется по значению ключа.
// Реализация хеш-таблицы через остаток от деления
// Добавление и поиск элементов осуществлятся через имя (name). В реальных условиях
// такая таблица будет иметь много коллизий, но, поскольку задание является тестовым,
// я избрал самый простой, быстрый и наглядный метод реализации.
#include <iostream>
#include <string>
#define PRIME_SIZE 29 // Использовано просто число
using namespace std;
class Person // Класс, который содержит немного информации о человеке.
{
public:
Person *next; // При возникновении коллизии элементы будут помещены в односвязный список.
string name;
string surname;
int age;
Person()
{
this->next = NULL;
}
Person (string name, string surname, int age = 0)
{
this->name = name;
this->surname = surname;
this->age = age;
this->next = NULL;
}
~Person()
{
//cout << "Delete " << this->name << endl;
if ( this->next != NULL )
{
delete this->next;
}
}
};
class HashTable // Хеш-таблица, представленная в виде массива элементов (которые в свою очередь представляют список).
{
Person *table[PRIME_SIZE];
// Самая простоя хеш-функция. Считает сумму ASCII кодов, делит на константу и
// получает остаток от деления.
static int hash ( string str )
{
int asciisum = 0;
for ( int i = 0; i < str.length(); i++ )
{
asciisum += str[i];
}
return asciisum % PRIME_SIZE;
}
public:
HashTable()
{
for ( int i = 0; i < PRIME_SIZE; i++ )
{
table[i] = NULL;
}
}
~HashTable()
{
//cout << "Delete table\n";
for ( int i = 0; i < PRIME_SIZE; i++ )
{
delete table[i];
}
}
// Вставляет элемент в таблицу
void push ( string name, string surname, int age )
{
int hashNumber = hash(name);
Person *pers = new Person(name, surname, age);
Person *place = table[hashNumber];
if ( place == NULL )
{
table[hashNumber] = pers;
return;
}
while ( place->next != NULL )
{
place = place->next;
}
place->next = pers;
}Таблицы с прямой адресацией
Прямая адресация представляет собой простейшую технологию, которая хорошо работает для небольших множеств ключей.
Предположим что требуется динамическое множество каждый элемент которого имеет ключ из множества от 0 до N-1. Где значение m не велико. Кроме того предполагается что никакие 2 элемента не имеют одинаковых ключей.
Для представления динамического множества мы используем массив или таблицу с прямой адресацией. Которую обозначим как T[0…m-1] . Каждая позиция или яцейка которого соответствуют ключу из пространства ключей множества О.

Хеш-таблицы
Недостаток прямой адресации очевиден: если пространство ключей U велико, хранение таблицы T размером |U| непрактично, а то и вовсе невозможно — в зависимости от количества доступной памяти и размера пространства ключей. Кроме того, множество K реально сохраненных ключей может быть мало по сравнению ´ с пространством ключей U, а в этом случае память, выделенная для таблицы T, в основном расходуется напрасно.
Когда множество K хранящихся в словаре ключей гораздо меньше пространства возможных ключей U, хеш-таблица требует существенно меньше места, чем таблица с прямой адресацией. Точнее говоря, требования к памяти могут быть снижены до Θ (|K|), при этом время поиска элемента в хеш-таблице остается равным O (1).
В случае прямой адресации элемент с ключом k хранится в ячейке k. При хешировании этот элемент хранится в ячейке h (k), т.е. мы исп ользуем хеш-функцию h для вычисления ячейки для данного ключа k. Функция h отображает пространство ключей U на ячейки хеш-таблицы T [0..m − 1]: h : U → {0, 1,...,m − 1} . Мы говорим, что элемент с ключом k хешируется в ячейку h (k); величина h (k) называется хеш-значением ключа k. На рис. 11.2 представлена основная идея хеширования. Цель хеш-функции состоит в том, чтобы уменьшить рабочий диапазон индексов массива, и вместо |U| значений мы можем обойтись всего лишь m значениями. Соответственно снижаются и требования к количеству памяти.
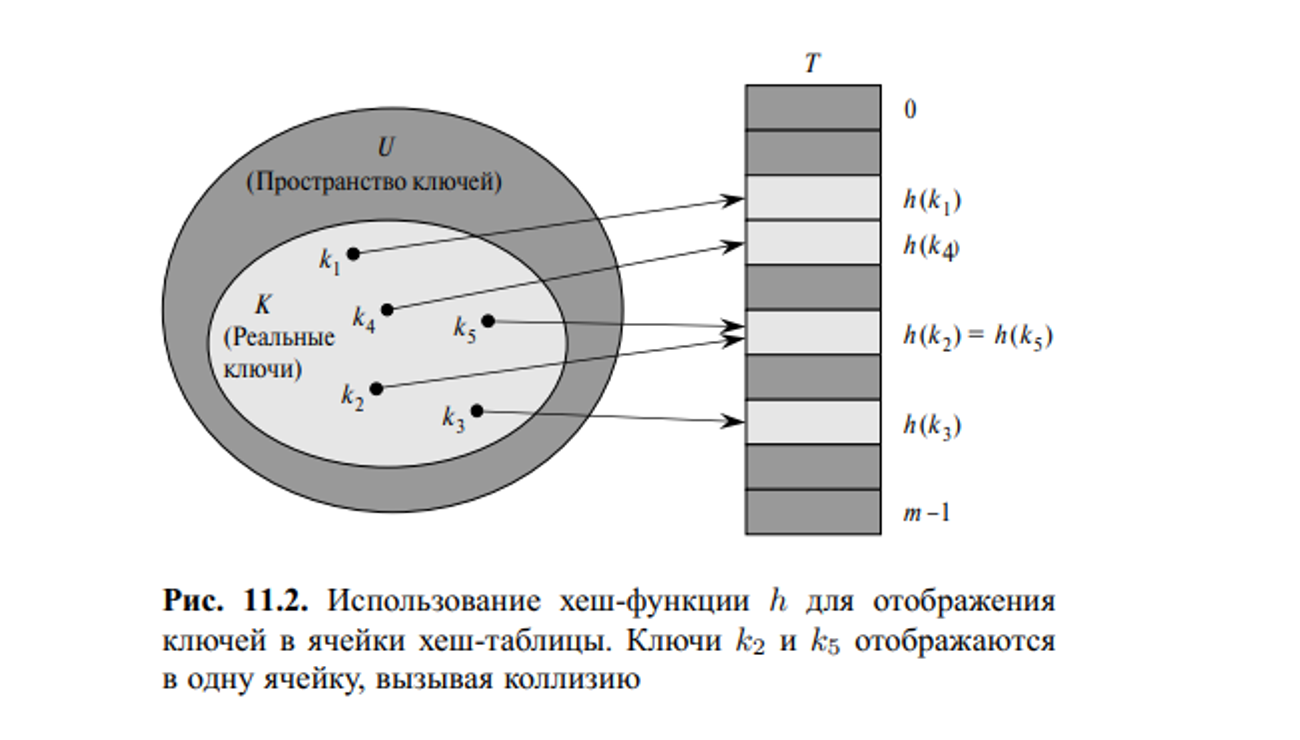
Однако здесь есть одна проблема: два ключа могут быть хешированы в одну и ту же ячейку. Такая ситуация называется коллизией, что может привезти к конфликтам.
Хеш-функции
Качественная хеш-функция удовлетворяет (приближенно) предположению простого равномерного хеширования: для каждого ключа равновероятно помещение в любую из m ячеек, независимо от хеширования остальных ключей.
Иногда распределение вероятностей оказывается известным. Например, если известно, что ключи представляют собой случайные действительные числа, равномерно распределенные в диапазоне 0 ≤ k≤1, то хеш-функция h(k) = |k| удовлетворяет условию простого равно- мерного хеширования.
На практике при построении качественных хеш-функций зачастую используются различные эвристические методики. В процессе построения большую помощь оказывает информация о распределении ключей. Рассмотрим, например, таблицу символов компилятора, в которой ключами служат символьные строки, представляющие идентификаторы в программе. Зачастую в одной программе встречаются похожие идентификаторы, например, pt и pts. Хорошая хеш–функция должна минимизировать шансы попадания этих идентификаторов в одну ячейку хеш- таблицы.
Построение хеш-функции методом деления
Построение хеш-функции методом деления ******состоит в отображении ключа k в одну из ячеек путем получения остатка от деления k на m, т.е. хеш-функция имеет вид h (k) = k mod m.
Например, если хеш-таблица имеет размер m = 12, а значение ключа k = 100, то h (k) = 4. Поскольку для вычисления хеш-функции требуется только одна операция деления, хеширование методом деления считается достаточно быстрым. При использовании данного метода мы обычно стараемся избегать некоторых значений m. Например, m не должно быть степенью 2, поскольку если m = 2р, то h (к) представляет собой просто р младших битов числа k. Если только заранее неизвестно, что все наборы младших р битов ключей равновероятны, лучше строить хеш-функцию таким образом, чтобы ее результат зависел от всех битов ключа.
Построение хеш-функции методом умножения
Построение хеш-функции методом умножения выполняется в два этапа. Сначала мы умножаем ключ k на константу 0 < А < 1 и полу- чаем дробную часть полученного произведения. Затем мы умножаем полученное значение на m применяем к нему функцию "floor" т.е.
где выражение "kА mod 1" означает получение дробной части произведения kА, т.е. величину k А - |kА|.
Достоинство метода умножения заключается в том, что значение m перестает быть критичным. Обычно величина m из соображений удобства реализации функции выбирается равной степени 2.
Универсальное хеширование
Если недоброжелатель будет умышленно выбирать ключи для хеширования при помощи конкретной хеш-функции, то он сможет подобрать n значений, которые будут хешироваться в одну и ту же ячейку таблицы, приводя к среднему времени выборки Θ(n). Таким образом, любая фиксированная хеш-функция становится уязвимой, и единственный эффективный выход из ситуации – случайный выбор хеш-функции, не зависящий от того, с какими именно ключами ей предстоит работать. Такой подход, который называется универсальным хешированием, гарантирует хорошую производительность в среднем, независимо от того, какие данные будут выбраны злоумышленником.
h[ab] (k) = ((ak + b) mod p) mod m
Этот класс хеш-функций обладает тем свойством, что размер m выходного диапазона произволен и не обязательно представляет со- бой простое число.. Поскольку число, а можно выбрать р - 1 способом, и р способами – число b, всего в данном семействе будет содержаться р (р - 1) хеш-функций.