Графы (часть 1)
Графы
Граф - это математическая абстракция реальной системы любой природы, объекты которой обладают парными связями. Граф, как математический объект, есть совокупность двух множеств. Множества вершин и множества ребер (парных связей/дуги).
Простой граф G(V, E) есть совокупность двух множеств. Негустого множества V и множества E неупорядоченных пар различных элементов множества V. Множество V называют множеством вершин, множество E называют множеством ребер. V - не пустое множество.
Ориентированные графы
Ориентированный граф состоит из множества вершин и множества V, E, здесь E - ориентированные ребра. Ребро или дуга представляется в виде упорядоченных пар вершин (v, w), где v - начальная вершина, w - конец дуги, v->w: говорят, что дуга ведёт от вершины v к вершине w, а вершина w смежная с вершиной v.
Пример ориентированного графа:
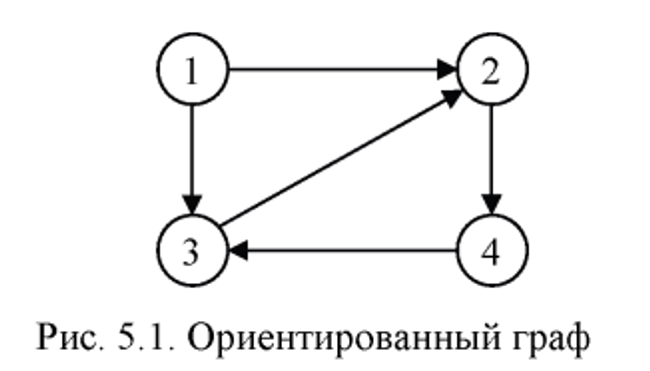
Вершину ориентированного графа можно использовать для представления объектов, а дуги для отношений между объектами. Путем в ориентированном грфе называется последовательность вершин V1, V2, ..., Vn, для которой существуют в дуги V1->V2, ... , Vn-1->Vn. Этот путь начинается в вершине V1 и проходя через вершины V2, Vn-1 закончивается в вершине Vn. Длина пути - это количество дуг, составляющих путь. В данном случае длина души равна n-1. Путь назвается простым, если все вершины на нем, за исключением может быть первой и последней, различны. Цикл - это простой путь длины не менее еденицы, которая начинается и заканчивается в одной и той же вершине.
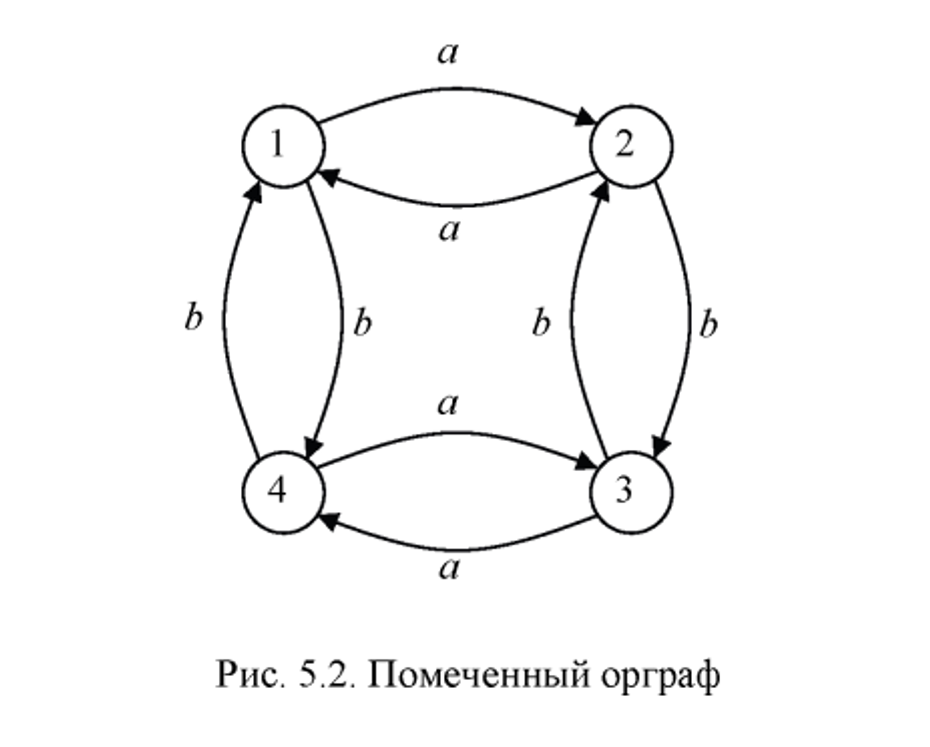
Помеченным ориентированным графом называется граф, у которого каждая дуга или каждая вершина имеет соответствующие метки. Меткой может быть имя, вес или стоимость дуги или значение данных какого-либо заданного типа. В помеченным ориентированном графе вершина может иметь как имя, так и метку.
Представления ориентированных графов.
Для представления ориентированных графов можно использовать различные структуры графов. Выбор структур данных зависит от операторов, которые будут применяться к вершинам и дугам ориентированных графов. Одним из наиболее общих представлений ориентированных графов является матрица смежности. Предположим, что множество вершин равна V={1,2,3,n}. Матрица смежности для данного ориентированного графа это матрица А={N,M}, со значением рулевого типа, где А[i,j]=true тогда и только тогда, когда существует дуга из вершины i до вершины j. Часто в матрицах смежности значение true обозначается 1, а false значением 0. Время доступа к элементам матрицы смежности зависит от размеров множества вершин и множества дуг. Основной недостаток использования матрицы смежности заключается в том, что она требует О(n^2) памяти, даже если дуг значительно меньше, чем n^2.

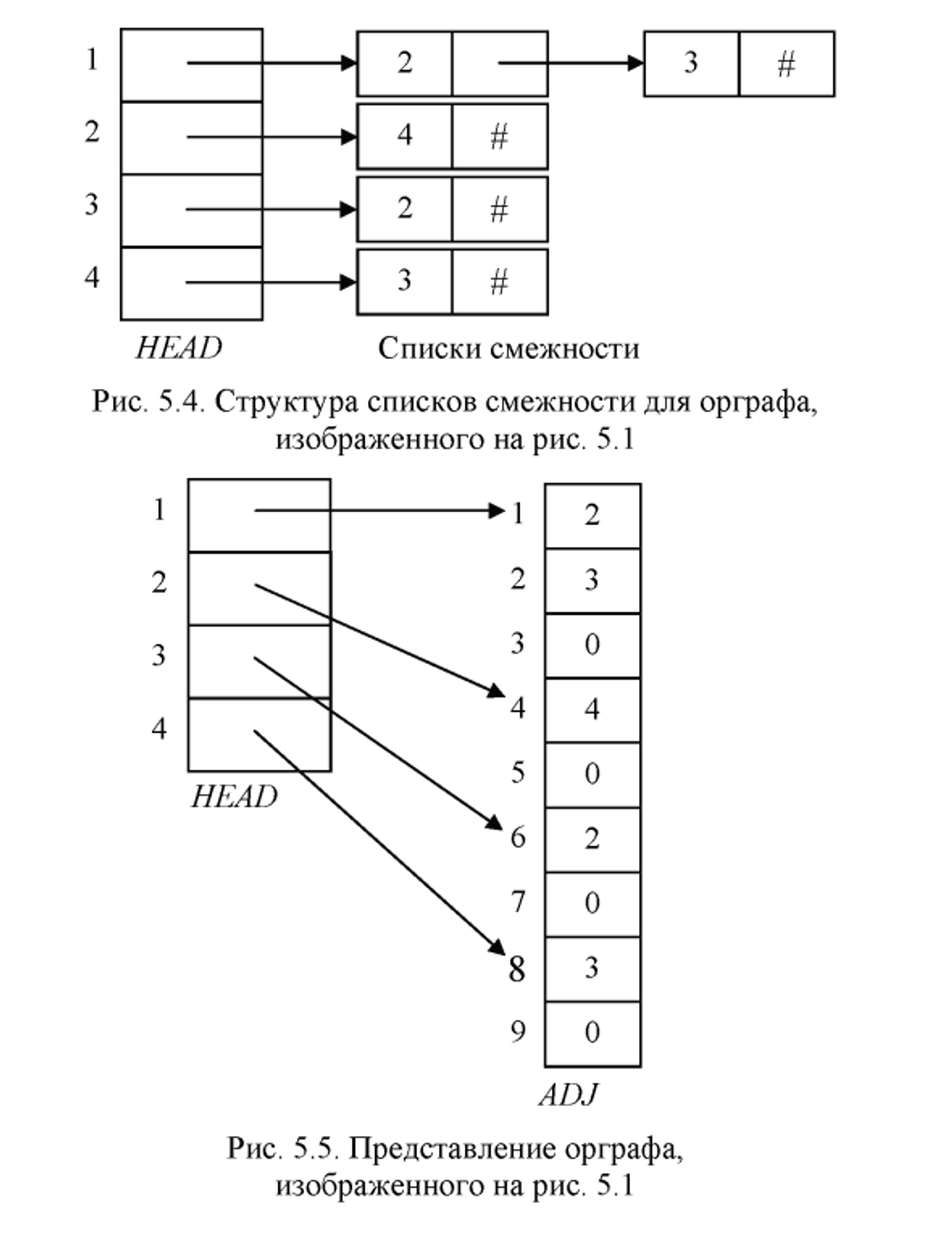
Вместо матрицы смежности часто используется представление посредством списком смежности. Списком смежности для вершины i называется список всех вершин смежных с вершиной i, причем определенным образом упорядоченный. Таким образом, ориентированный граф G можно представить посредством массива HEAD(заголовок), чей элемент HEAD[i] является указателем на список смежности вершины i. Представление ориентированного графа с помощью списков смежности требует для хранения объем памяти пропорциональный сумме количества вершин и количества дуг. Если количество дуг имеет порядок О(n), то и общий объем необходимой памяти имеет такой же порядок.
Для вставки и удаления элементов в списке смежности необходимо иметь массив HEAD, содержащий указатель на ячейки заголовков списков смежности, но не сами смежные вершины.
Задача нахождения кратчайшего пути
Пусть имеется ориентированный граф G(V, E), у которого все дуги имеют неотрицательные метки, а одна вершина определена как источник. Задача состоит в нахождении стоимости кратчайших путей от источника ко всем другим вершинам данного графа, здесь длина пути определяется как сумма стоимости дуг, составляющих путь. Для решения поставленной задачи будем использовать "жатный" алгоритм (алгоритм Дейкстра). Алгоритм строит множества S вершин, для которых кратчайшие пути от источника уже известны.
Обход графа
Что такое обход графа?
Простыми словами, обход графа — это переход от одной его вершины к другой в поисках свойств связей этих вершин. Связи (линии, соединяющие вершины) называются направлениями, путями, гранями или ребрами графа. Вершины графа также именуются узлами.
Двумя основными алгоритмами обхода графа являются поиск в глубину (Depth-First Search, DFS) и поиск в ширину (Breadth-First Search, BFS).
Несмотря на то, что оба алгоритма используются для обхода графа, они имеют некоторые отличия. Начнем с DFS.
Поиск в глубину
DFS следует концепции «погружайся глубже, головой вперед» («go deep, head first»). Идея заключается в том, что мы двигаемся от начальной вершины (точки, места) в определенном направлении (по определенному пути) до тех пор, пока не достигнем конца пути или пункта назначения (искомой вершины). Если мы достигли конца пути, но он не является пунктом назначения, то мы возвращаемся назад (к точке разветвления или расхождения путей) и идем по другому маршруту.
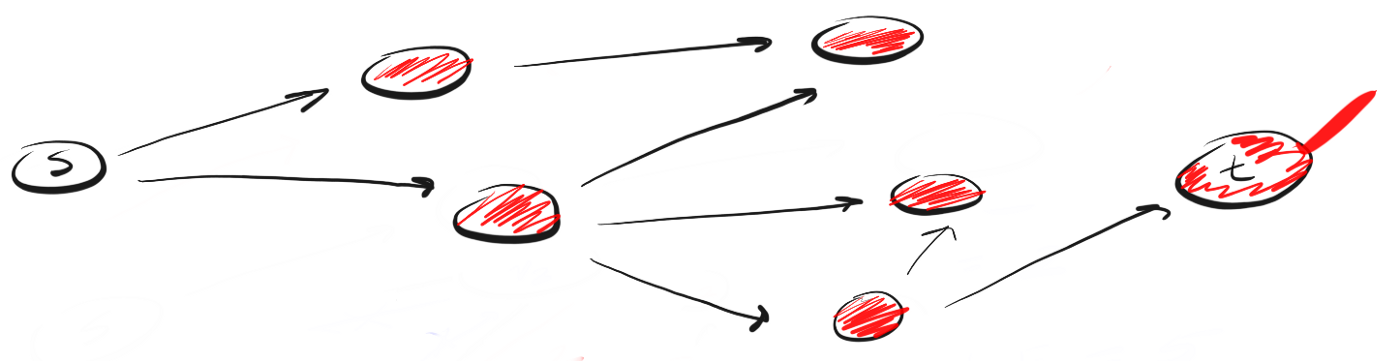
Давайте рассмотрим пример. Предположим, что у нас есть ориентированный граф, который выглядит так:
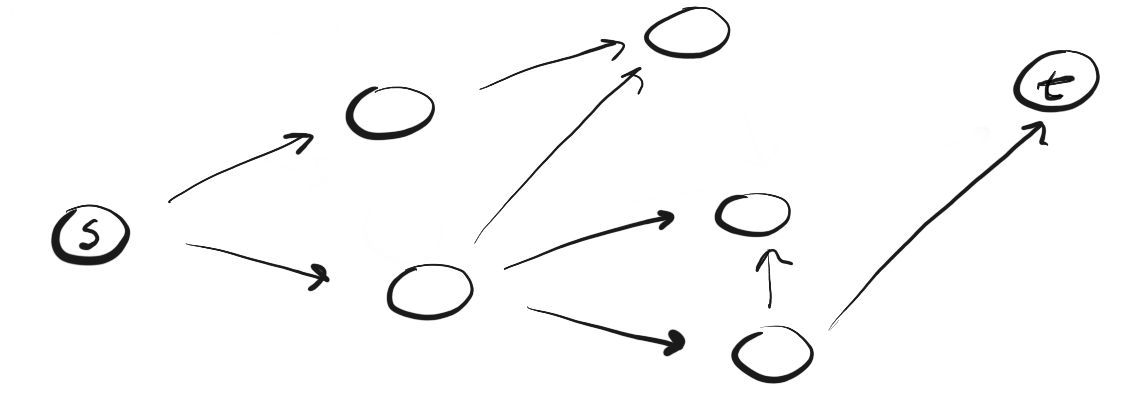
Мы находимся в точке «s» и нам нужно найти вершину «t». Применяя DFS, мы исследуем один из возможных путей, двигаемся по нему до конца и, если не обнаружили t, возвращаемся и исследуем другой путь. Вот как выглядит процесс:
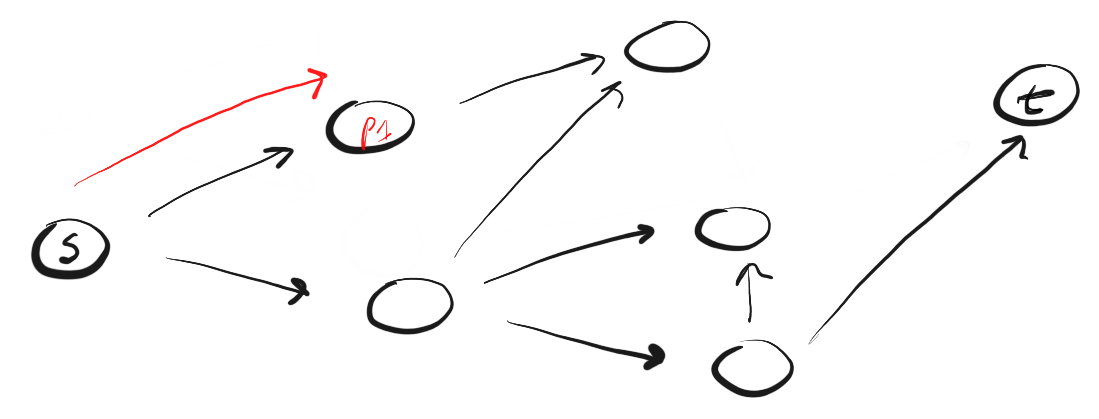
Здесь мы двигаемся по пути (p1) к ближайшей вершине и видим, что это не конец пути. Поэтому мы переходим к следующей вершине.
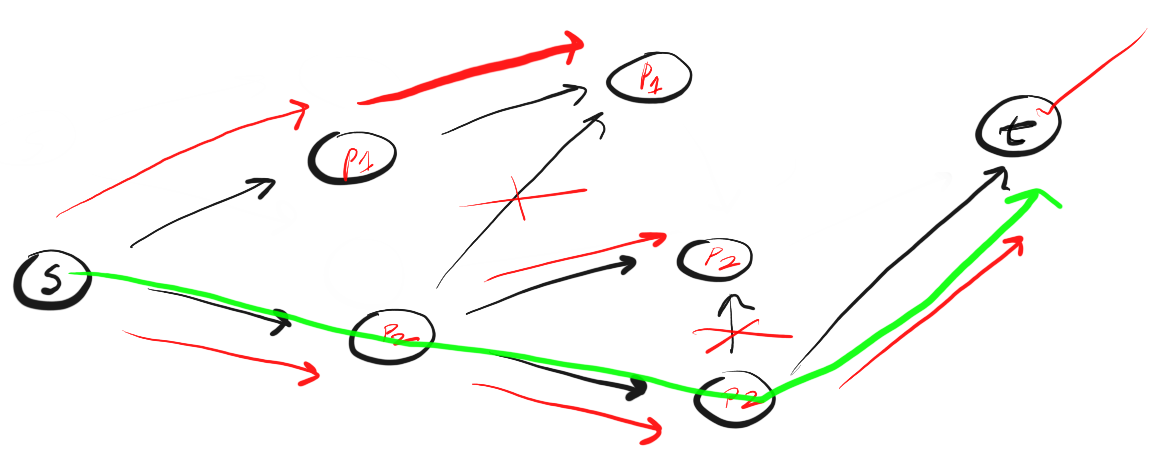
Так работает DFS. Двигаемся по определенному пути до конца. Если конец пути — это искомая вершина, мы закончили. Если нет, возвращаемся назад и двигаемся по другому пути до тех пор, пока не исследуем все варианты.
Мы следуем этому алгоритму применительно к каждой посещенной вершине.
Необходимость многократного повторения процедуры указывает на необходимость использования рекурсии для реализации алгоритма.
Поиск в ширину
BFS следует концепции «расширяйся, поднимаясь на высоту птичьего полета» («go wide, bird’s eye-view»). Вместо того, чтобы двигаться по определенному пути до конца, BFS предполагает движение вперед по одному соседу за раз. Это означает следующее:
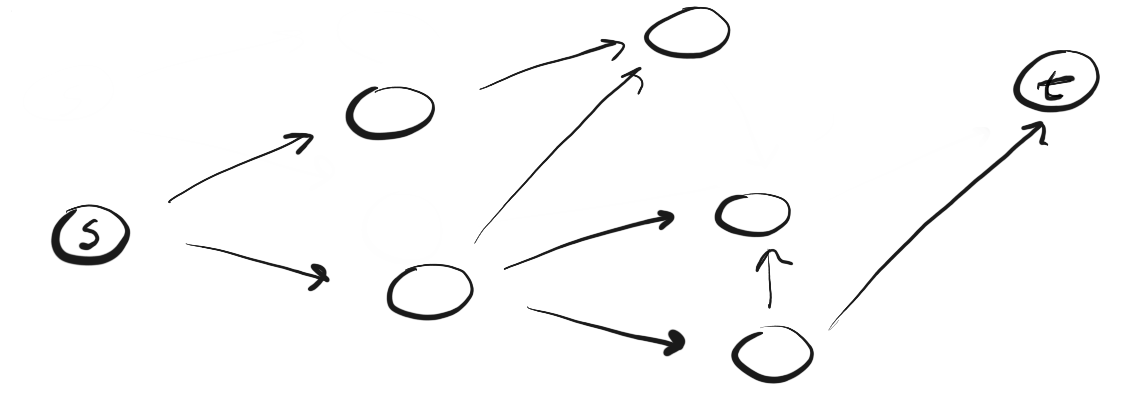
Вместо следования по пути, BFS подразумевает посещение ближайших к s соседей за одно действие (шаг), затем посещение соседей соседей и так до тех пор, пока не будет обнаружено t.

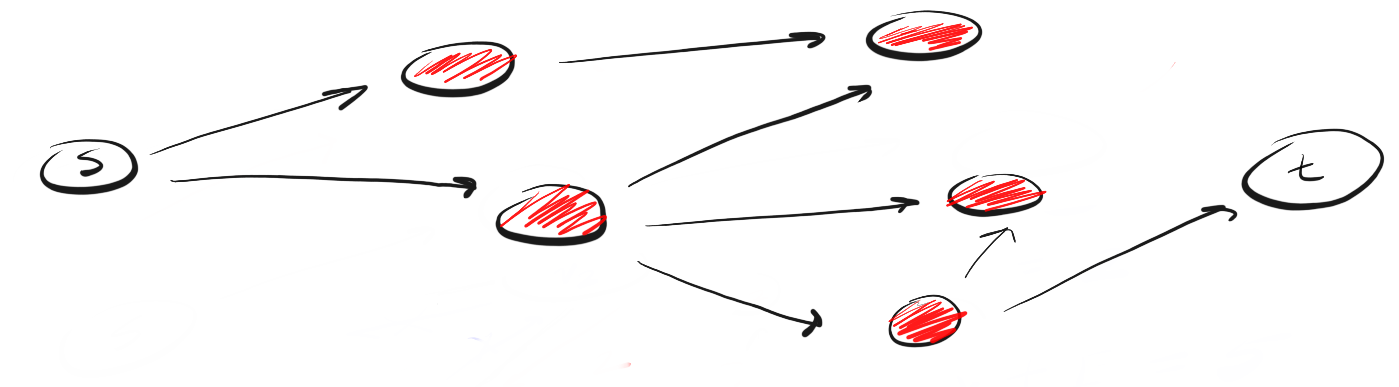
Чем DFS отличается от BFS? Мне нравится думать, что DFS идет напролом, а BFS не торопится, а изучает все в пределах одного шага.
Далее возникает вопрос: как узнать, каких соседей следует посетить первыми?
Для этого мы можем воспользоваться концепцией «первым вошел, первым вышел» (first-in-first-out, FIFO) из очереди (queue). Мы помещаем в очередь сначала ближайшую к нам вершину, затем ее непосещенных соседей, и продолжаем этот процесс, пока очередь не опустеет или пока мы не найдем искомую вершину.
Анализ BFS
Может показаться, что BFS работает медленнее. Однако если внимательно присмотреться к визуализациям, можно увидеть, что они имеют одинаковое время выполнения.
Очередь предполагает обработку каждой вершины перед достижением пункта назначения. Это означает, что, в худшем случае, BFS исследует все вершины и грани.
Несмотря на то, что BFS может казаться медленнее, на самом деле он быстрее, поскольку при работе с большими графами обнаруживается, что DFS тратит много времени на следование по путям, которые в конечном счете оказываются ложными. BFS часто используется для нахождения кратчайшего пути между двумя вершинами.
Таким образом, время выполнения BFS также составляет O(V + E), а поскольку мы используем очередь, вмещающую все вершины, его пространственная сложность составляет O(V).
Выводы
- Поиск в глубину и поиск в ширину используются для обхода графа.
- DFS двигается по граням туда и обратно, а BFS распространяется по соседям в поисках цели.
- DFS использует стек, а BFS — очередь.
- Время выполнения обоих составляет O(V + E), а пространственная сложность — O(V).
- Данные алгоритмы имеют разную философию, но одинаково важны для работы с графами.