Деревья
Бинарные деревья поиска - это структура данных, которая позволяет хранить элементы в отсортированном порядке для эффективного поиска, вставки и удаления. Основные операции выполняются за время, пропорциональное глубине дерева. Для полного дерева с n узлами эти операции выполняются за O(logn). Бинарные деревья поиска также поддерживают запросы на поиск минимального и максимального элементов, предшествующего и последующего элементов.
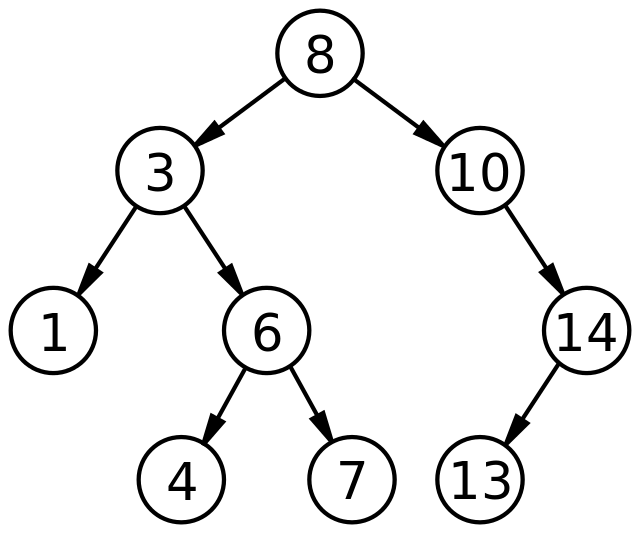
Структура бинарного дерева поиска
Каждый узел бинарного дерева поиска содержит ключ и связанные данные, а также указатели на левого и правого потомков и на родительский узел. Корень дерева хранит первый элемент, и для каждого последующего элемента создается новый узел. Если новый элемент меньше текущего узла, он помещается в левое поддерево, иначе в правое.
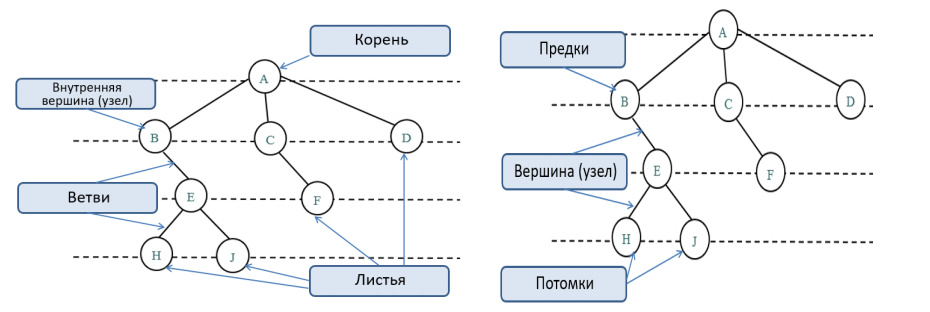
Операции на бинарных деревьях поиска
- Поиск ключа: Начиная с корня, производится сравнение ключа с каждым узлом. Если ключ найден или дождемся конца дерева, операция завершается. Время работы O(h), где h - высота дерева.
- Поиск минимального/максимального элемента: Простой проход по указателям left (для минимального) или right (для максимального) от корня до nil.
- Вставка и удаление: Вставка элемента в бинарное дерево поиска подразумевает поиск позиции для него, а удаление требует сохранения свойств дерева после удаления узла.
Эффективность бинарных деревьев поиска обеспечивается свойством упорядоченности элементов и быстрым доступом к данным. Они поддерживают множество операций и широко применяются в практике.
В программировании существует несколько способов обхода деревьев, каждый из которых имеет свои особенности и применяется в различных ситуациях. Рассмотрим основные типы обходов деревьев:
1. Обход в глубину (Depth-First Traversal):
1.1 Прямой обход (Preorder Traversal):
- Посещение узла происходит перед посещением его потомков.
- Порядок: Узел - Левое поддерево - Правое поддерево.
- Пример использования: копирование структуры дерева для сохранения.
1.2 Симметричный обход (Inorder Traversal):
- Посещение узла происходит между посещениями его левого и правого потомков.
- Порядок: Левое поддерево - Узел - Правое поддерево.
- Пример использования: вывод элементов дерева в отсортированном порядке.
1.3 Обратный обход (Postorder Traversal):
- Посещение узла происходит после посещения его потомков.
- Порядок: Левое поддерево - Правое поддерево - Узел.
- Пример использования: высвобождение памяти узлов дерева.
2. Обход в ширину (Breadth-First Traversal):
- Посещение узлов происходит слева направо, начиная с корня и продвигаясь на уровень ниже.
- Реализуется чаще с использованием очереди.
- Пример использования: поиск в ширину или поиск кратчайшего пути в дереве.
- Прямой обход: Позволяет создавать копии структуры дерева, выполнять вычисления перед посещением потомков.
- Симметричный обход: Подходит для сортировки элементов дерева, поиска в отсортированных данных.
- Обратный обход: Пригоден для высвобождения выделенной памяти, выполнения действий после посещения всех потомков.
- Обход в ширину: Используется для поиска в ширину, построения уровней дерева.
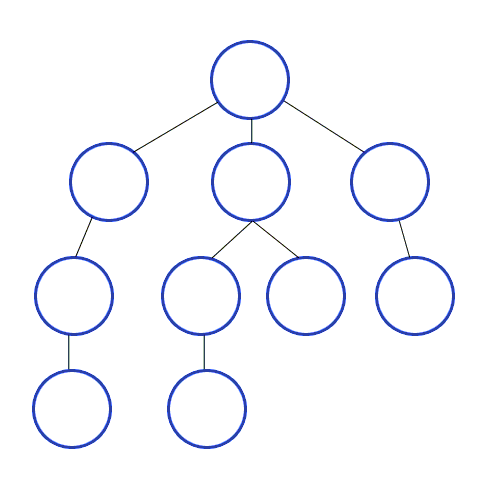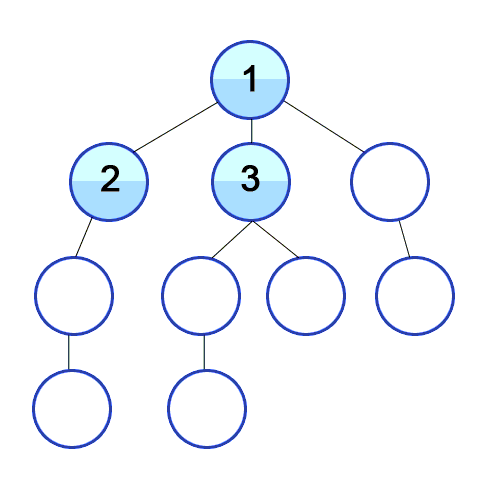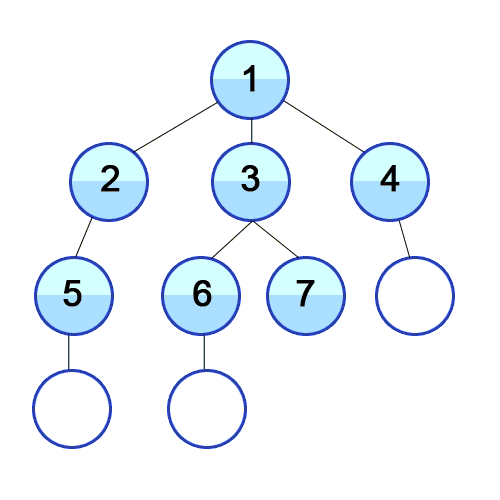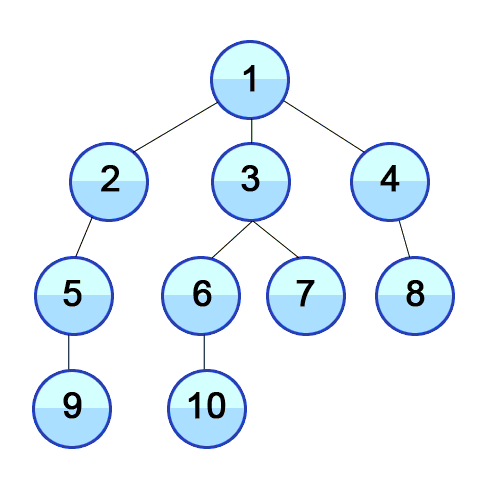
Каждый тип обхода дерева имеет свои характеристики и возможности, поэтому важно выбирать подходящий метод в зависимости от конкретной задачи и структуры дерева.
Node* insertRec(Node* root, int key) {
root->left = insertRec(root->left, key);
root->right = insertRec(root->right, key);
void inorderTraversal(Node* root) {
inorderTraversal(root->right);
cout << "Inorder traversal of the binary search tree: ";
tree.inorderTraversal(tree.root);
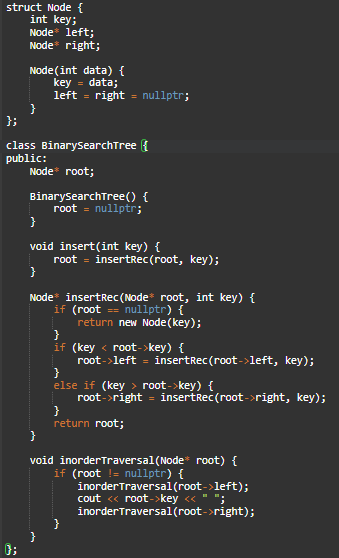
Данный код реализует простое бинарное дерево поиска на C++. Давайте подробно разберем, как это работает:
1. `struct Node`: Эта структура представляет узел бинарного дерева. У каждого узла есть ключ (`key`), указатели на левого (`left`) и правого (`right`) потомков.
2. `class BinarySearchTree`: Этот класс представляет бинарное дерево поиска. У него есть открытое поле `root`, которое указывает на корень дерева.
- Конструктор `BinarySearchTree()` инициализирует корень нулевым указателем.
3. `void insert(int key)`: Метод для вставки элемента в дерево.
- `insertRec(Node* root, int key)`: Рекурсивная функция вставки элемента. Если дерево пустое, создается новый узел с ключом `key`.
- Если `key` меньше текущего узла (`root->key`), он рекурсивно добавляется в левое поддерево, иначе в правое.
- На выходе возвращается измененный корень поддерева.
4. `void inorderTraversal(Node* root)`: Метод для симметричного обхода дерева (ин-порядок).
- Рекурсивно вызывается для левого поддерева, затем выводится ключ текущего узла, после чего происходит обход правого поддерева.
- Это позволяет выводить элементы дерева в отсортированном порядке.