Petabyte Scale Data Deduplication
Mixpanel ingests petabytes of event data over the network from the mobile, browser, and server-side clients. Due to unreliable networks, clients may retry events until they receive a 200 OK message from Mixpanel. Although this retry strategy avoids data loss, it can create duplicate events in the system. Analyzing data with duplicates is problematic because it gives an inaccurate picture of what happened and causes Mixpanel to diverge from other client data systems that we may sync with, such as data warehouses. This is why we care deeply about data integrity.
Today, we’re excited to share our solution to deduplicating event data at petabyte scale.
Requirements
To address this problem, we needed an approach that was:
- Scalable: Scales to an ingestion volume of 1M+ events/sec
- Cost-Efficient: Optimizes cost/performance overhead to ingestion, storage, and query
- Retroactive: Identifies duplicate events sent arbitrarily later
- Lossless: Preserves duplicates to rollback in case of misconfiguration
- Maintainable: Minimizes operational overhead
State of the art: Ingestion-Time Deduplication
The industry has a lot of creative approaches to solve the deduplication problem. The central theme involves architecting an infrastructure that performs deduplication at the ingestion layer. Customers send a unique identifier, $insert_id as a property on each event. The deduplication infrastructure stores the $insert_id for all the events within a limited retention window (e.g. 7 days) and checks it against every new event for duplicate identification. A key-value store like sharded RocksDB or Cassandra is often used for storage. The lookup costs in the storage can be improved using a bloom filter. This kind of architecture ensures that the duplicates are weeded out of the system at its entry point.
However, this approach fails to meet our requirements for the following reasons:
- ✅ Scalable: Sharded key-value stores can scale horizontally
- ❌ Cost-Efficient: Requires a separate data store and infrastructure for duplicates
- ❌ Retroactive: Can only capture duplicates in a limited retention window
- ❌ Lossless: Drops data at ingestion, so it’s impossible to rollback
- ❌ Maintainable: Dedupe becomes an additional service that must be up 24×7
Our Approach
We architected a solution that satisfies all of our requirements, by ingesting all events and deduplicating them at read-time. A simple approach to read-time deduplication would be to build a hashtable of all $insert_ids on each query; however, this would add non-trivial overhead to our system. But before describing our solution, let’s review a few key aspects of our architecture.
Mixpanel Architecture
(Project, User, Time)-Based Sharding
Mixpanel’s analytics database, Arb, shards its data files by project, user and event time. This allows us to ensure that all data for a given user is co-located, so that behavioral queries can run across many users simultaneously over relevant portions of time.
Lambda Architecture
In Arb, all the events are written to append-only files, which are periodically indexed (compaction) into columnar files in the background. Append-only files are indexed when they reach either a size or age threshold. This approach ensures that queries are both real-time and efficient, by scanning both small, real-time, append-only files and the large, historical, indexed files.
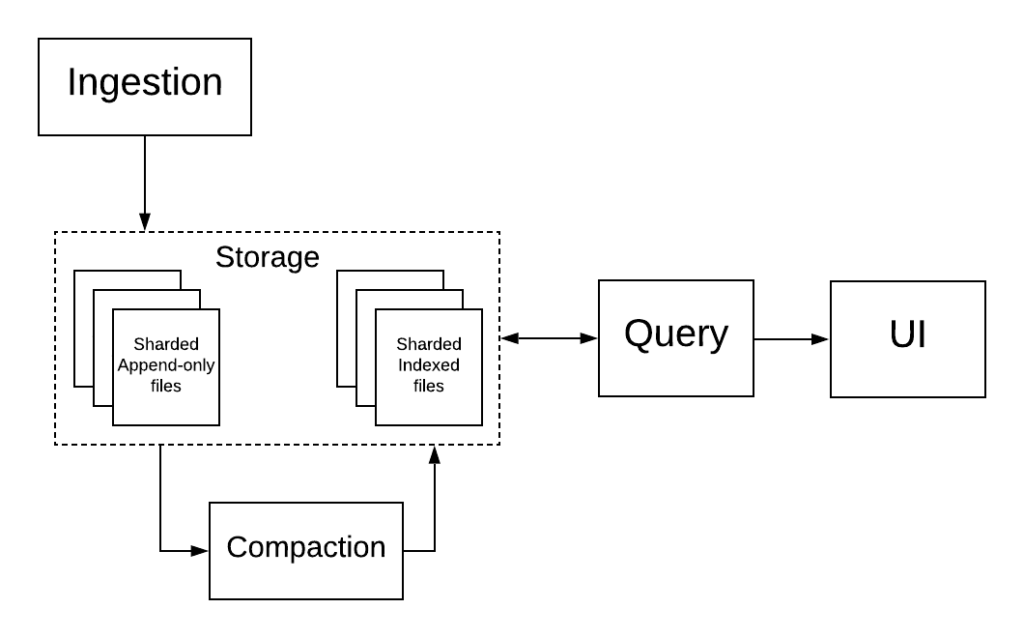
We leveraged these two aspects of our architecture to make read-time deduplication efficient. By first principles, event duplicates have the following properties:
- Event duplicates belong to the same project
- Event duplicates belong to the same user
- Event duplicates belong to the same event-time
We glean the following key insights from these fundamentals:
- We can scope down the search space for event duplicates to the project, user and day — ie, to a single Arb shard.
- We can minimize the overhead of deduplication by amortizing it alongside our lambda architecture to maintain both real-time and efficient queries.
These insights lead to a solution that satisfies all of our requirements.
Deduplication Architecture
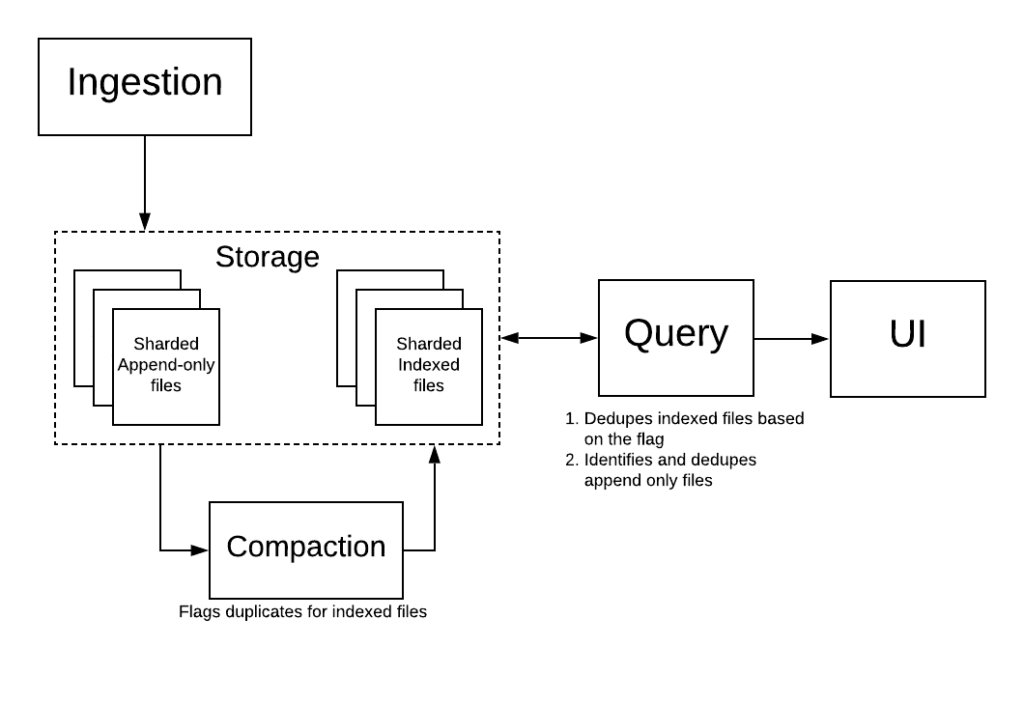
Deduping within Mixpanel infrastructure happens both at indexing time and query time.
Our indexer maintains an in-memory hashset by $insert_id for all the events from the files that are being indexed. If it sees a hit on an event, that event is marked as a duplicate by setting a bit on the event in the indexed format. This process has minimal overhead since indexing occurs at the fine-grained shard level.
At query-time, due to our lambda architecture, we scan both indexed files and append-only files. For indexed files, we can check if the duplicate bit is set, and if so, skip processing the event. For the small, append-only files, queries do hash-based deduping on $insert_id. This allows us to be both real-time and efficient, leveraging the power of the lambda architecture.
Performance

From our experiments, we found that indexing of files with 2% duplicates has a time overhead range of 4% to 10%. This does not have any direct impact on our user experience, as indexing is an offline process.
For query-time, we found that reading an extra bit for every event adds around 10ns to the reading of data. This is close to a 2% increase in the query time because of the additional column. Reading 10 million events adds a time overhead close to 0.1 seconds (100ms). For reference, Mixpanel’s largest columnar file as of today contains around 2 million events (thanks to the project, user, time sharding). We think the trade-off on time overhead is quite acceptable given the win we get on the unlimited retention window and minimum operational overhead.
Conclusion
In this blog, we discussed our architecture that distributes duplicate identification at the indexing layer and duplicate filtering at the query level. This solution has been live in Mixpanel for the last 6 months.