Улучшение наблюдаемости сервисов GoLang
Эта статья в блоге предназначена для разработчиков GoLang, которые хотят улучшить наблюдаемость своих сервисов. Он пропускает основы и сразу переходит к продвинутым темам, таким как асинхронное структурированное логирование, метрики с exemplars, трассировка с TraceQL, агрегирование pprof и непрерывное профилирование, микробенчмарки и базовая статистика с benchstat, тесты производительности черного ящика и базовые ПИД-регуляторы для определения максимальной нагрузки системы. Мы также кратко коснемся текущих исследований в области наблюдаемости, включая активное случайное профилирование и пассивное обнаружение критических секций.
Три столпа наблюдаемости: Журналы, метрики, трассы
.png)
Если вы читаете эту статью, то, скорее всего, вам не нужно заново изучать основы наблюдаемости. Давайте погрузимся в неочевидные вещи и сосредоточимся на том, чтобы максимально упростить перемещение между тремя основными поверхностями наблюдаемости. Мы также обсудим, как добавить трассировку, чтобы данные pprof можно было связать с трассировкой и обратно.
Если вы ищете краткое и понятное введение в основы мониторинга и способы быстрого внедрения базовой наблюдаемости в ваш сервис, "Наблюдаемость распределенных систем" Cindy Sridharan - отличное место для начала.
Структурированное ведение журнала
Ведение журнала может стать узким местом, если вы не используете библиотеку ведения журнала с нулевым распределением. Если вы еще не сделали этого, рассмотрите возможность использования zap или zerolog - оба варианта отлично подходят.

В Golang также есть предложение по внедрению структурированного протоколирования: slog. Обязательно ознакомьтесь с ним и предоставьте отзывы о предложении!

Структурированный журнал необходим для извлечения данных из журналов. Принятие формата json или logfmt упрощает устранение неполадок ad-hoc и позволяет быстро и грязно строить графики/сообщения, пока вы работаете над правильными метриками. Большинство библиотек журналов также имеют готовые к использованию крючки для gRPC/HTTP клиентов и серверов, а также распространенных клиентов баз данных, что значительно упрощает их внедрение в существующие кодовые базы.
Если вы считаете текстовые форматы неэффективными, вы можете в значительной степени оптимизировать протоколирование. Например, zerolog поддерживает двоичный формат CBOR, а Envoy имеет protobufs для структурированных журналов доступа.
В некоторых случаях сами журналы могут стать узким местом в производительности. Вы же не хотите, чтобы ваш сервис застрял из-за того, что Docker не может достаточно быстро извлекать события из stderr-трубы, когда вы включаете журналы DEBUG.
Одним из решений является выборка журналов:
sampled := log.Sample(zerolog.LevelSampler{
DebugSampler: &zerolog.BurstSampler{
Burst: 5,
Period: 1*time.Second,
NextSampler: &zerolog.BasicSampler{N: 100},
},
})В качестве альтернативы можно сделать их выброс полностью асинхронным, чтобы они никогда не блокировались:
wr := diode.NewWriter(os.Stdout, 1000, 10*time.Millisecond, func(missed int) {
fmt.Printf("Logger Dropped %d messages", missed)
})
log := zerolog.New(wr)
Еще одно замечание для тех, кто использует Grafana и Loki: скорее всего, вы захотите настроить производные поля. Таким образом, вы сможете извлекать поля из журналов и помещать их в произвольные URL-адреса.
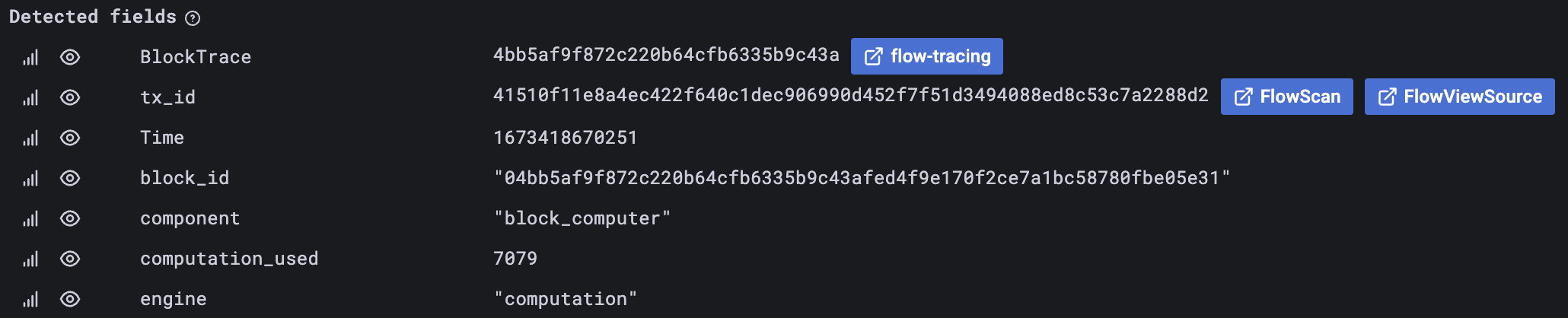
Рассмотрите возможность включения идентификатора трассировки в каждое сообщение журнала, если контекст указывает на то, что трассировка должна быть включена. Позже вы поблагодарите себя за это.
Метрики
Предположим, что вы уже используете метрики в стиле Prometheus в своем сервисе. Но что делать, когда вы видите всплеск на графике и вам нужно выяснить причину замедления (спойлер: скорее всего, это база данных)? Разве не здорово было бы перейти от метрики непосредственно к трассировке медленного запроса? Если да, то ExemplarAdder и ExemplarObserver для вас:
ctx := r.Context()
traceID := trace.SpanContextFromContext(ctx).TraceID.String()
requestDurations.(prometheus.ExemplarObserver).ObserveWithExemplar(
time.Since(now).Seconds(), prometheus.Labels{"traceID": traceID}
})Обратите внимание, что в метки можно поместить не только trace_id, но и произвольные ключевые данные, что особенно полезно для многопользовательских сред, где можно включить user_id или team_id. Это может быть экономически эффективным решением проблемы метрик с высокой кардинальностью.
Трек
Трассировка необходима для анализа производительности в современном мире, поэтому в большинстве сервисов она включена. Путь отрасли к трассировке был ухабистым: от OpenTracing до OpenCensus и теперь OpenTelemetry. Мы используем общую установку с библиотеками OTEL для эмиссии трассировки и Grafana Tempo в качестве бэкенда.
Выдача трассировки блокчейна Flow отличается от типичного веб-бэкенда: мы не полагаемся на контекст трассировки, передаваемый между границами доверия, поэтому вместо распространения идентификаторов трассировки мы детерминистически строим их на основе обрабатываемого объекта - хэша блока или хэша транзакции.
Проблема с трассировкой заключается не в выбросе данных, а скорее в способности найти "интересные" данные. Возможности поиска в Grafana по умолчанию весьма ограничены, и иногда на поиск нужной трассировки могут уйти минуты.
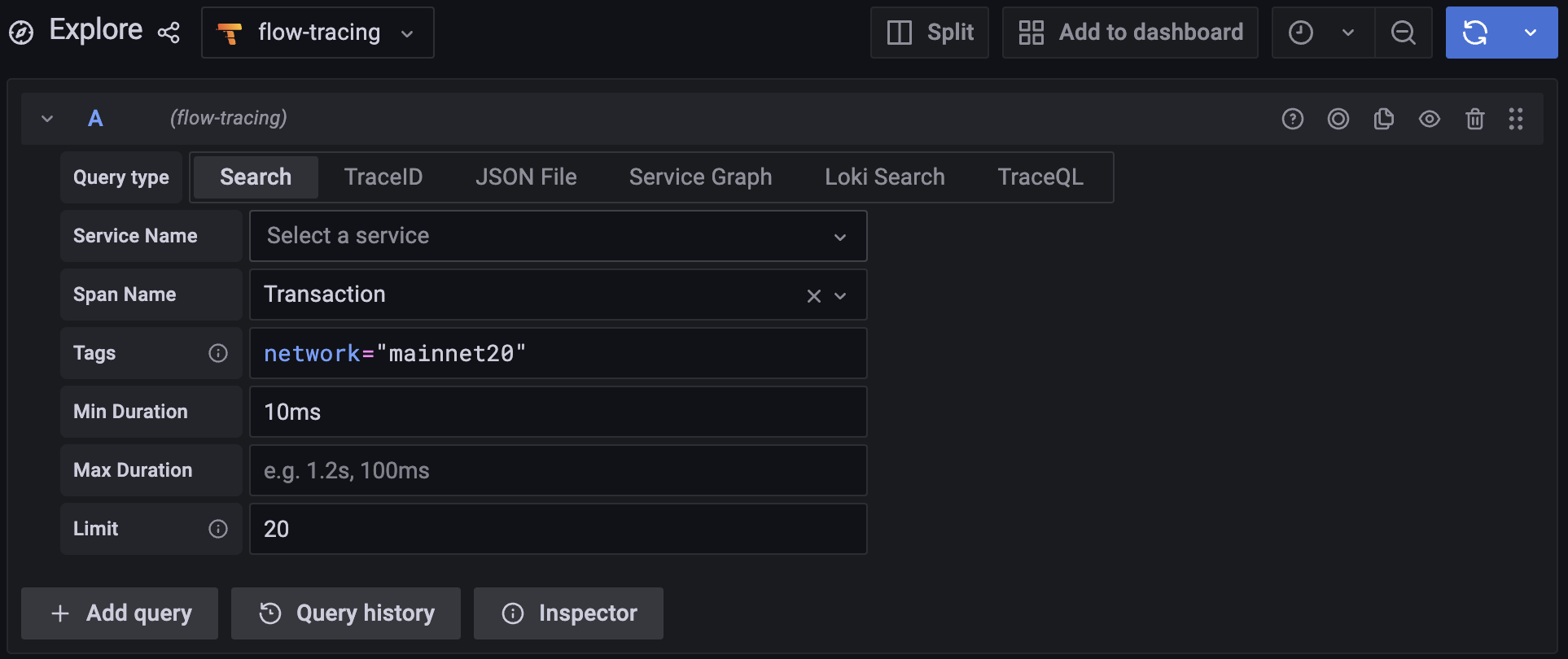
TraceQL решает эту проблему, представляя удобный способ поиска трасс. Найти конкретную трассу теперь проще простого. Вот несколько примеров из справочной документации:
# A trace has INSERTs that on average are longer than 1s:
{ span.db.statement =~ "INSERT.*"} | avg(duration) > 1s
# A trace has over 5 spans with http.status = 200 in any given namespace:
{ span.http.status = 200 } | by(resource.namespace) | count() > 5
# A trace passed through two regions (in any order):
{ resource.region = "eu-west-0" } && { resource.region = "eu-west-1" }Если вы предпочитаете видеоформат, вот введение Joe Elliott в TraceQL с конференции GrafanaCon 2022.
Теперь, с TraceQL, мы можем быть настолько конкретными, насколько пожелаем:
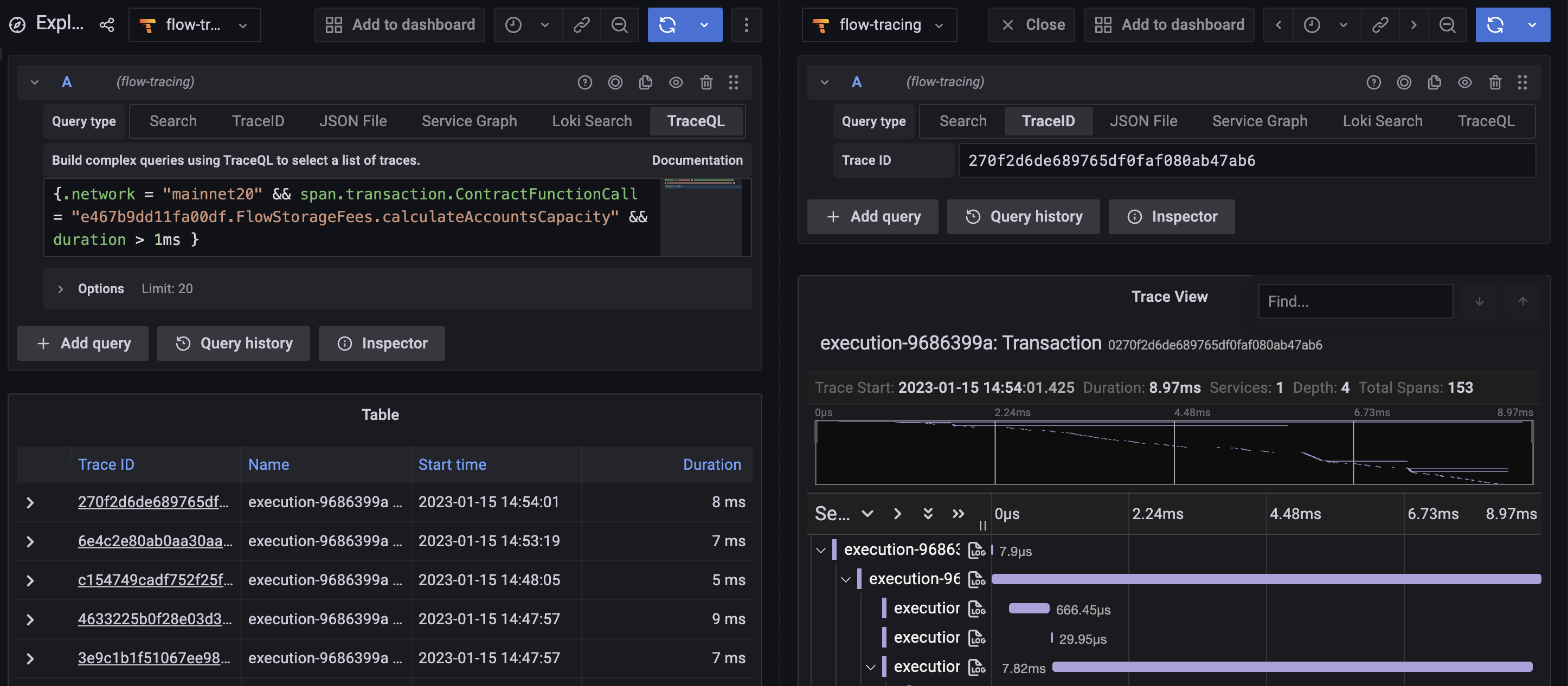
Если вы используете Grafana, не забудьте связать источник данных журнала с вашими трассами. Это облегчит навигацию между трассировками и журналами:
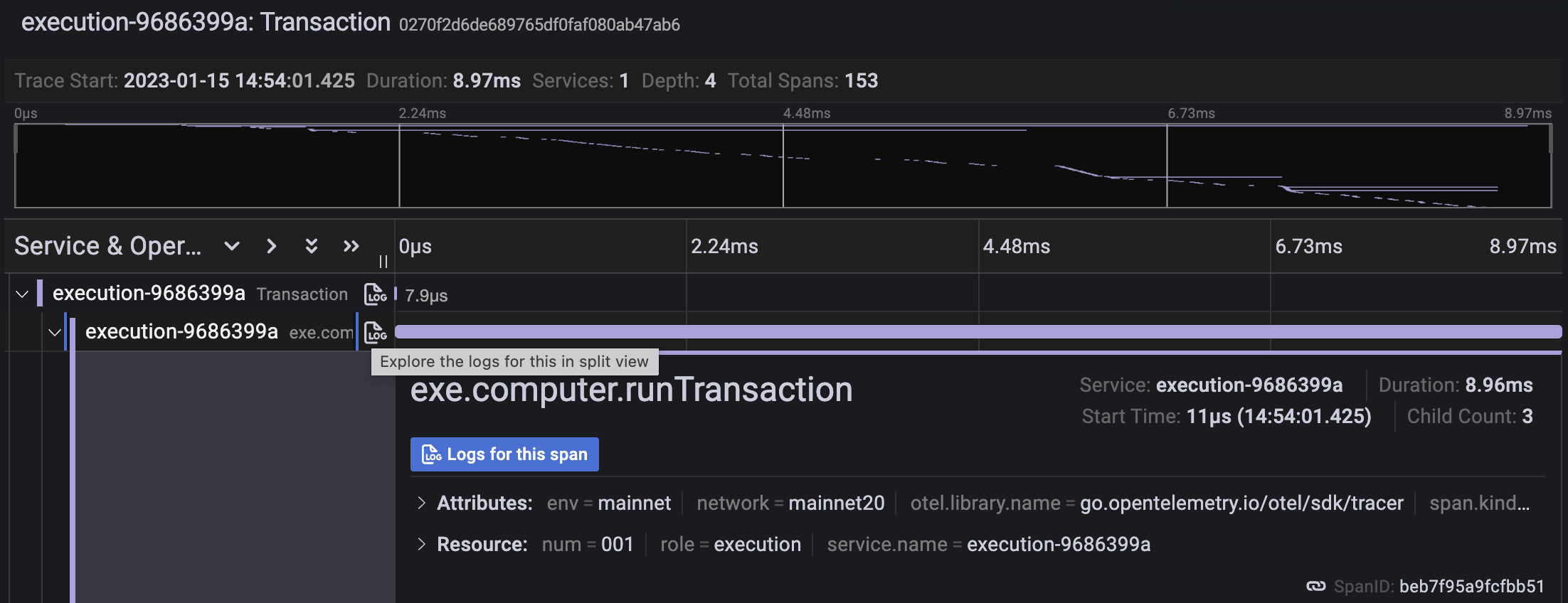
Оптимизация запросов TraceQL может быть достигнута за счет наличия общих атрибутов для каждого процесса в ваших "ресурсах". Это намного быстрее, чем поиск, и может иметь огромное значение. Например, на скриншоте выше мы обнаружили ошибку, когда env и network должны были быть переданы как ресурсы, а не как атрибуты.
Профилирование
Среда выполнения Go предлагает отличные возможности профилирования. Если вы хотите инструментировать свой код, не ограничиваясь net/http/pprof, мы настоятельно рекомендуем прочитать статью DataDog "The Busy Developer's Guide to Go Profiling, Tracing and Observability". В ней подробно рассматриваются все типы профилировщиков (CPU, Memory, Block,и т.д.) и описываются детали низкоуровневой реализации, такие как внутреннее устройство трассировки стека и формат pprof.
Многие из функций профилирования требуют новой среды выполнения Go для быстрой и точной работы. Если вы планируете использовать данные профилирования в производстве, особенно если вы планируете использовать непрерывное профилирование, пожалуйста, обновите Go до версии 1.19.
Получив необработанный файл pprof, вы захотите его проанализировать. Однако инструмент pprof -http 5000 имеет свои ограничения. Идеальным решением было бы хранить профили в базе данных, которая поддерживает базовые запросы и фильтрацию. Мы используем Cloud Profiler от Google, но вместо того, чтобы полагаться на их несколько ограниченные клиентские библиотеки, мы используем их "автономный API", который позволяет нам отправлять существующие файлы .pprof в Google:
profileBytes, _ := os.ReadFile(filename)
client.CreateOfflineProfile(ctx, &pb.CreateOfflineProfileRequest{
Parent: projectId,
Profile: &pb.Profile{
ProfileType: profileType,
Deployment: deployment,
ProfileBytes: profileBytes,
},
})Основным преимуществом отправки профилей в удаленное хранилище по сравнению с простым локальным хранением является возможность объединения нескольких профилей в единое представление.
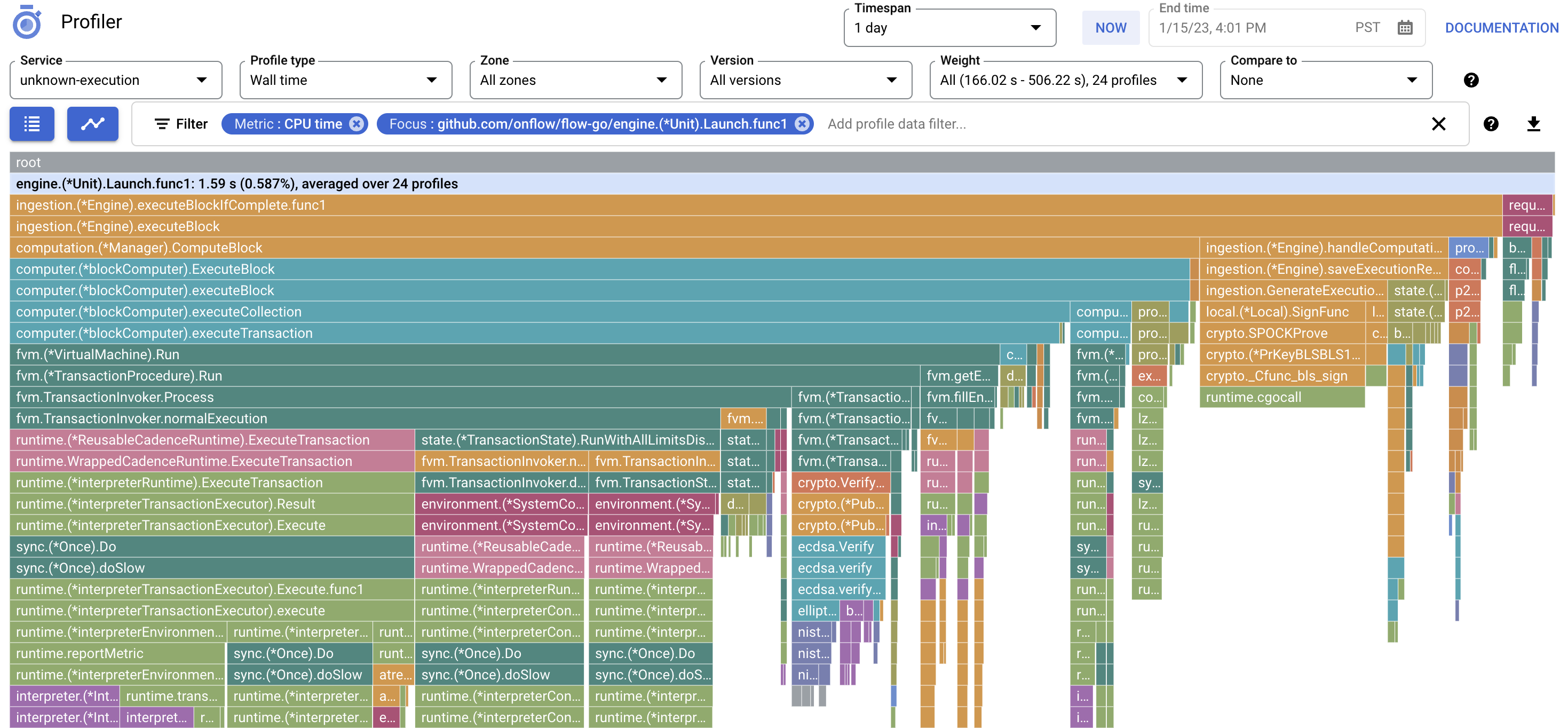
Кроме того, это дает нам возможность проследить тенденции изменения профиля во времени.
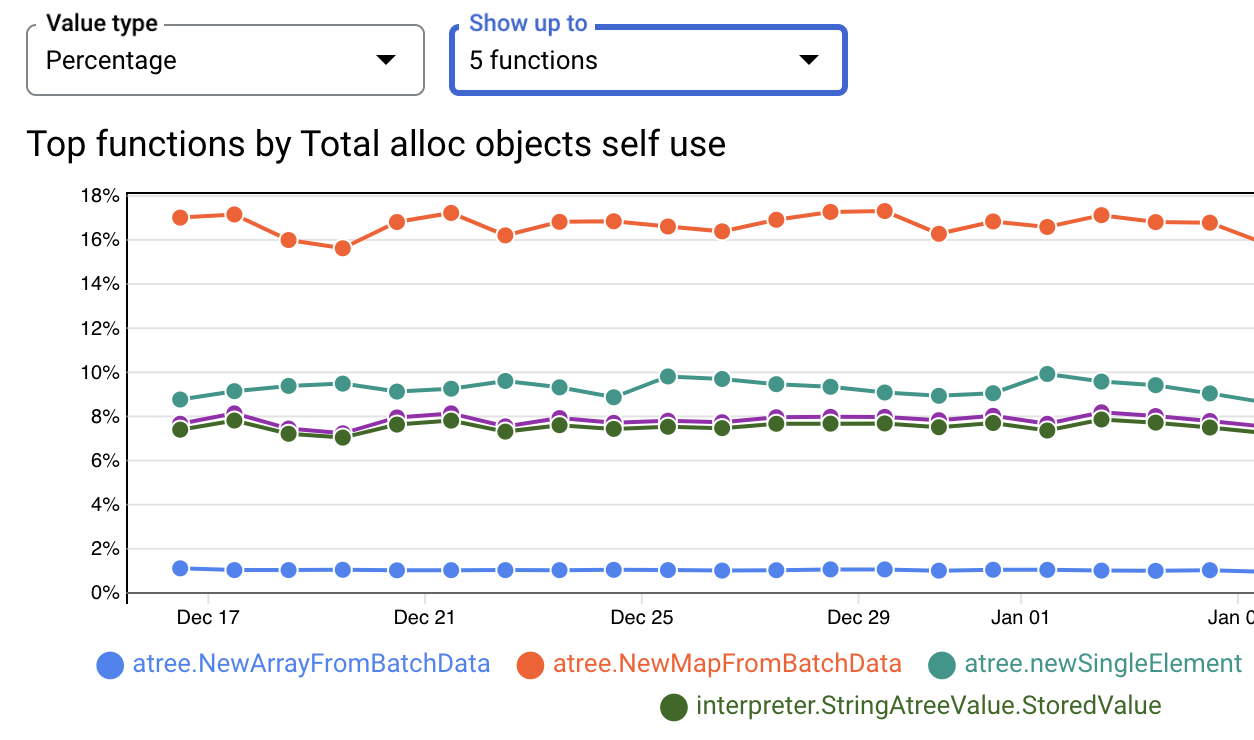
К сожалению, API Google "Offline" сильно ограничен по скорости и размеру и, похоже, вообще не поддерживается, поэтому мы активно изучаем альтернативы. Поскольку мы уже используем стек Grafana, мы следим за развитием Phlare; он выглядит как очень способная замена:
.gif)
Соединение профилирования с трассировкой
Мы вложили много усилий в пользовательский опыт анализа производительности, обеспечивая плавные переходы между журналами, трассировками и метриками. Однако профилирование данных в настоящее время представляет собой уникальную проблему. Чтобы решить эту проблему, мы изучаем pprof.Do (или, как вариант, pprof.SetGoroutineLabels на более низком уровне). Это позволит нам создать связь между профилированием и трассировкой, которая в настоящее время отсутствует.
pprof.Do(
ctx,
pprof.Labels(
"span", fmt.Sprintf("%s", span)
),
func(ctx context.Context) {
doWork(ctx)
},
)У меток есть несколько недостатков: они поддерживаются не для всех типов профилей и могут увеличить размер профиля, поэтому не забывайте о кардинальности меток.
Здесь можно добавлять произвольные метки, что особенно полезно в многопользовательских средах. Например, вы можете аннотировать pprofs идентификатором пользователя и идентификатором команды арендатора. Даже в однопользовательских установках аннотирование профилей с помощью EndpointPath может дать дополнительное представление об использовании CPU.
fgprof
Недостатком стандартного профилировщика Go является то, что он может просматривать только время работы на процессоре или вне процессора. Профилировщик Felix Geisendörfer, fgprof, решает эту проблему, предоставляя единое представление, которое захватывает оба вида.
Непрерывное профилирование
Профилирование стало достаточно дешевым, поэтому многие компании предоставляют библиотеки для непрерывного профилирования в производстве, что стало тенденцией. В качестве примера можно привести Pyroscope, DataDog и Google.
Вместо того чтобы встраивать профилировщик в кодовую базу, Grafana Phlare использует модель агента, который периодически обследует конечные точки Go pprof HTTP, расположенные по адресу /debug/pprof/:
scrape_configs:
- job_name: 'default'
scrape_interval: 10s
profiling_config:
path_prefix: "/debug/pprof"
pprof_config:
memory:
enabled: true
path: "/allocs"
delta: true
# ...Профилирование на основе eBPF
Все вышеперечисленные функции профилирования требуют наличия в бинарном файле какого-либо инструментария, будь то конечная точка HTTP или библиотека непрерывного профилирования. В последнее время в наблюдаемости наметилась тенденция к профилированию без инструментария, которое позволяет eBPF.
Например, Parca позволяет вам наблюдать за неинструментированными C, C++, Rust, Go и многими другими!
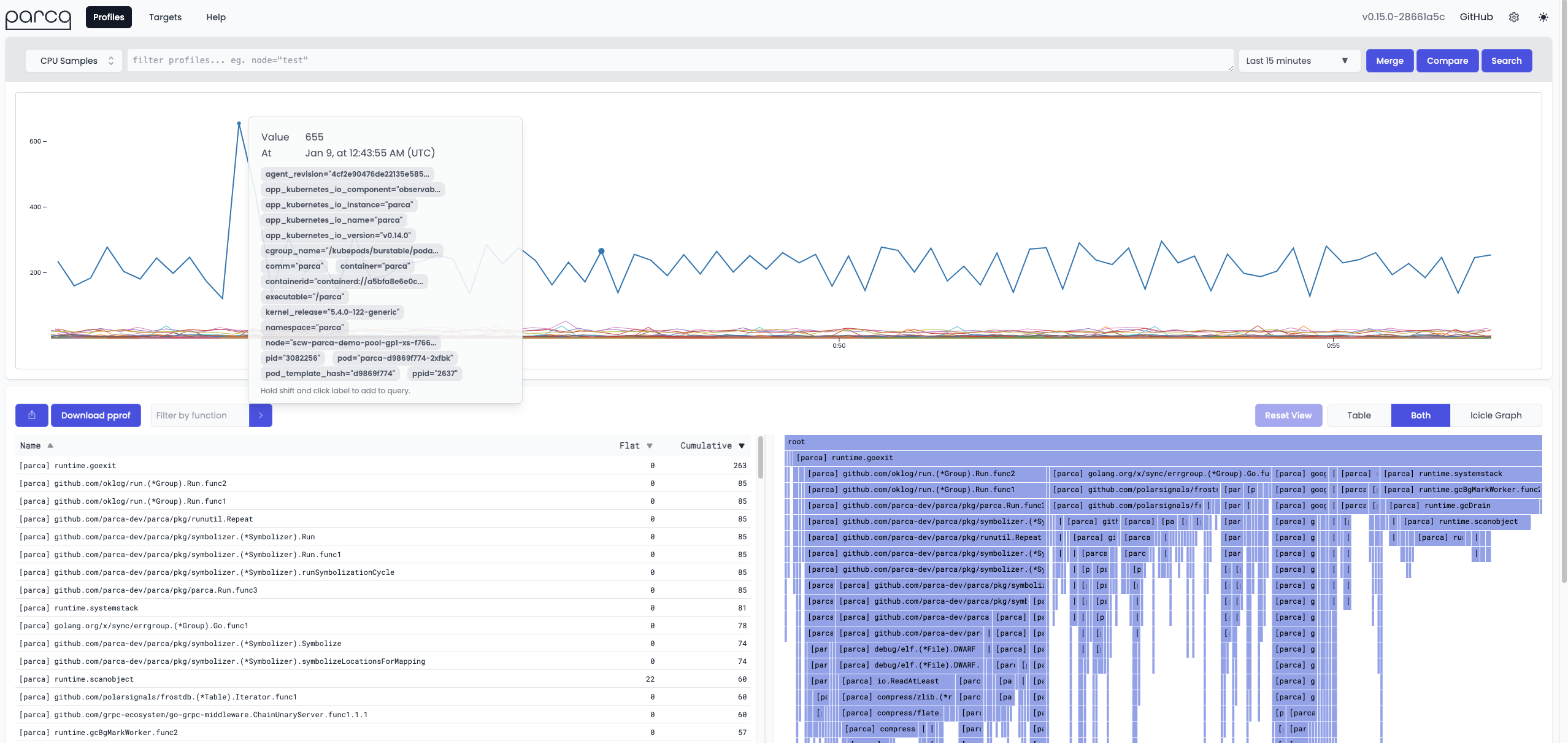
Если вы хотите использовать тот же подход к профилированию eBPF для Go, который вы использовали для кода на C/C++ с помощью uprobe / uretprobe, имейте в виду, что вы можете столкнуться с SIGBUS из-за роста и копирования стека в Go. Кроме того, goroutines динамически сопоставляются с потоками, что делает невозможным использование tid для идентификации потока кода (то же самое, вероятно, произошло бы с C++ при использовании coroutines). К счастью, есть обходные пути, доступные в соответствующих выпусках bcc и bpftrace.
Microbenchmarks
Microbenchmarking в Go - хорошо известная практика, поэтому говорить о ней много не нужно. Однако есть пара моментов, о которых стоит упомянуть. Во-первых, при выполнении Microbenchmarking рекомендуется использовать test.benchmem и выполнять '^#39;.
Во-вторых, результаты benchmark следует считать достоверными только в том случае, если параметр -count больше или равен 10:
$ go test -count 10 -bench 'Benchmark.*TokenTransfer' -benchmem -run '^#39; ./ goos: darwin goarch: arm64 pkg: github.com/onflow/cadence/runtime BenchmarkFungibleTokenTransfer-8 6638 179964 ns/op 104511 B/op 1966 allocs/op BenchmarkFungibleTokenTransfer-8 6458 179890 ns/op 103890 B/op 1966 allocs/op BenchmarkFungibleTokenTransfer-8 6853 180334 ns/op 104513 B/op 1966 allocs/op ...
Наконец, инструмент benchstat (или аналогичный) всегда должен использоваться при анализе результатов одного benchmark, чтобы улучшить читаемость и гарантировать отсутствие шума в среде:
$ benchstat go1.20rc1 name time/op FungibleTokenTransfer-8 180µs ± 0% name alloc/op FungibleTokenTransfer-8 105kB ± 1% name allocs/op FungibleTokenTransfer-8 1.97k ± 0%
Шум может быть серьезной проблемой в средах benchmarking. В проекте LLVM есть отличная документация о том, как настроить Linux-системы для получения менее 0,1% вариаций в benchmarking.
Кроме того, при проведении сравнений, особенно при заявлении об улучшении производительности, важно показать статистику:
$ benchstat go1.19 go1.20rc1 name old time/op new time/op delta FungibleTokenTransfer-8 182µs ± 2% 180µs ± 0% -1.33% (p=0.021 n=10+8) name old alloc/op new alloc/op delta FungibleTokenTransfer-8 105kB ± 1% 105kB ± 1% ~ (p=0.363 n=10+10) name old allocs/op new allocs/op delta FungibleTokenTransfer-8 1.97k ± 0% 1.97k ± 0% -0.10% (p=0.000 n=10+10)
Не стесняйтесь добавлять пользовательские метрики в свои тесты, чтобы получить более глубокое понимание отчетов о производительности критических секций. Используйте b.ReportMetric и b.ResetTimer для их оптимизации.
Было бы неплохо иметь инструмент с открытым исходным кодом или SaaS, который мог бы собирать и отслеживать результаты микробенчмарков с течением времени для хранилища Go; однако мы не нашли такого инструмента.
Тесты производительности черного ящика
Хотя существует множество инструментов для сквозного тестирования производительности веб-приложений (например, мы используем grafana/k6 для тестирования наших приложений), сложные системы, такие как компиляторы или базы данных, требуют специальных тестов черного ящика, также известных как макробенчмарки. Вот несколько хороших примеров автоматизированных макробенчмарков в крупных проектах с открытым исходным кодом (сами бенчмарк-фреймворки также являются открытыми).
Vitess, распределенная база данных, имеет очень полный (хотя и немного шумный) ночной тест производительности, который отслеживает результаты микро- и макро-benchmark. Тестовый фреймворк с открытым исходным кодом находится по адресу https://github.com/vitessio/arewefastyet.
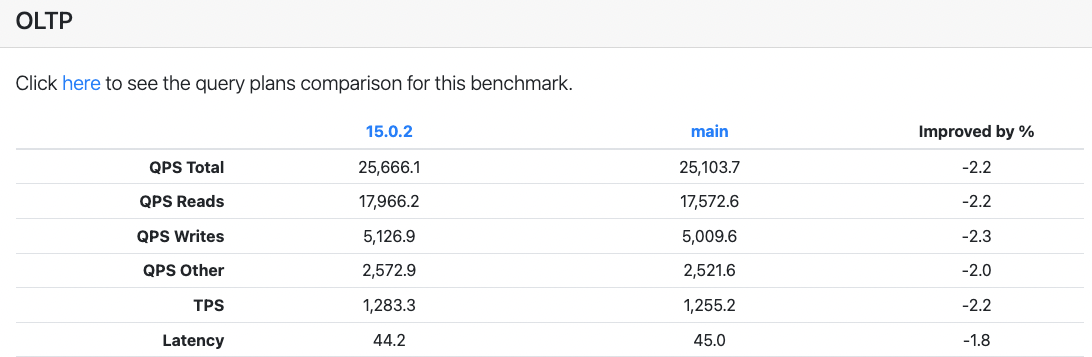
Rust - еще один хороший пример отличного эталонного фреймворка для всех видов специфических тестов компилятора, выполняемых на основе каждого коммита. Он также имеет открытый исходный код по адресу: https://github.com/rust-lang/rustc-perf.
Наша сквозная установка относительно тривиальна по сравнению с этими двумя, но все же имеет пару интересных деталей. Одна из них - обнаружение точки перегрузки системы. Поскольку блокчейн является асинхронным и может ставить транзакции в очередь на нескольких уровнях в нашем сквозном макробенчмарке, нам нужно найти максимальное значение транзакций в секунду, которое блокчейн может обрабатывать без чрезмерных задержек. Раньше мы использовали для этого алгоритм TCP с аддитивным увеличением/множественным уменьшением (AIMD), но он сходился довольно медленно. Недавно мы перешли на PID-регулятор (точнее, PD-регулятор), который обладает приятным свойством быстро сходиться к желаемому размеру очереди и при этом не слишком сильно проскакивать:
Если вы заинтересованы во внедрении PID-регуляторов в свои системы, книга Филиппа К. Янерта "Управление с обратной связью для компьютерных систем: Introducing Control Theory to Enterprise Programmers" - отличное место для начала. Если вы больше склонны к визуальному обучению, то первые несколько лекций из плейлиста YouTube "Понимание PID-регулирования" также являются отличным введением. Только имейте в виду, что это канал MATLAB, поэтому он быстро углубляется. Вас предупредили =)
Будущая работа
Здесь мы рассмотрим вещи, которые мы планируем добавить в наш инструментарий наблюдаемости производительности в этом году.
Обнаружение узких мест путем замедления работы
Ускорить работу может быть сложно, а вот замедлить - относительно просто. Поэтому один из способов выявления узких мест - попробовать замедлить работу компонентов системы на 1 мс, 5 мс, 50 мс, 250 мс и т.д. и измерить результаты эталонных показателей. Затем экстраполируйте функцию обратно на -1 мс, -5 мс, -50 мс и т.д. Этот метод является приблизительным, но он хорошо работает для небольших значений.
Случайный профилировщик
Казуальный профилировщик - это еще один активный метод и более точное обобщение предыдущего. Вместо того чтобы замедлять интересующий компонент, он замедляет все остальное вокруг него, таким образом эмулируя ускорение тестируемого компонента.
Если вас интересует казуальное профилирование, есть хорошее видео введение в "Coz: поиск кода, который имеет значение, с помощью казуального профилирования" (SOSP'15).
Автоматический анализ критического пути
Анализ критического пути крупномасштабной распределенной системы может оказаться сложной задачей. В своем докладе на OSDI'14 "Загадочная машина: End-to-End Performance Analysis of Large-Scale Internet Services" Мичиганский университет и Facebook предложили способ пассивного определения критического пути путем наблюдения за журналами (которые в настоящее время, вероятно, больше похожи на трассировку). Преимущество этого подхода в том, что он хорошо сочетается с инфраструктурой трассировки и профилирования.
Приложение A. AI-driven записей в блогах, управляемый искусственным интеллектом.
Не связано с наблюдаемостью Golang, но в целом применимо к тем, кто пишет сообщения в блогах: Английский может не быть вашим родным языком, поэтому первые черновики постов в блоге могут быть довольно болезненными для редактора. Это часто требует много часов (и, возможно, даже бутылку виски), чтобы вернуть на место забытые статьи, перефразировать предложения, побороть желание послать мне видео с развязкой, исправить пунктуацию и идиомы. Современные языковые модели могут избавить вас от многих проблем. Например, первый проход редактирования этой заметки был выполнен text-davinci-003 (поговорим о переборчивости!) со следующим заданием:
Вы - редактор технического блога, просматривающий пост "Улучшение наблюдаемости сервисов Golang". Пожалуйста, перепишите следующий абзац, исправляя орфографию, идиоматические выражения, пунктуацию и выбор слов по мере необходимости. При необходимости объедините, разделите предложения или перепишите для большей ясности. Не делайте его слишком сухим, юмор не помешает.