Comparing Footprint and Dune data models

- Data ownership and transfer has fast become one of the key problems to be solved when it comes to product building. The rise of social media platforms misusing data has led to the need to build solutions to solve data misuse. Given this, blockchains provide a functionality to immutably store, transfer data and create marketplaces allowing users to monetise their data.
- Blockchain, first of all, is a technology and its implementation can vary greatly depending on what global problem a certain ecosystem is trying to solve. Some blockchains are trying to focus on performance to potentially replace traditional infrastructure (for example, VISA can process 12,000 transactions per second), while others put privacy as a main component of financial infrastructure. Yes, globally, at the heart of any blockchain are blocks that have certain storage capacities and, when filled, are closed and linked to the previously filled block, forming a chain of data known as the blockchain, but the storage organization itself can be radically different between blockchains. All business logic in Ethereum is mainly implemented through smart contracts, when, for example, in Polkadot, the implementation is done through pallets. Yes, even dwelling on the same smart contracts and comparing, for example, Ethereum and Solana, firstly, they are written in different programming languages ( Solidity in the case of Ethereum, RUST | C | C++ in the case of Solana), and secondly, they implement completely different approaches to storage.
- Demand generates supply, and thus data web3 began to gain great popularity, which try to lower the entry threshold as low as possible and try to please both developers and analysts. There are many goals that a data startup follows, but perhaps the most important thing is the data model, because the user experience of use, the speed of query execution, and other key metrics depend on it.
This article will look at the implementation differences between Footprint data model and the one provided by the most popular analytics platform, Dune Analytics.
Platforms that work with blockchain data have a similar ETL process. The steps for this process are:
In the following part, we will look at each step in more detail and point out the differences in implementation within each of the platforms.
— — **NOTE** — For simplicity all following examples are based on EVM chains — The v2 version is taken as an object of comparison by Dune. More details — [Dune V2 — Dune Docs](https://dune.com/docs/reference/dune-v2/.) —
Node providers transmit data to indexer
A node provider is a “client” software that connects them to a blockchain’s network, enables them to send information back and forth between other nodes, and in some cases, validates transactions and stores data. In order to receive this “new block created” message, someone must run a blockchain node. To ensure a high enough degree of processing speed for new transactions, it is crucial to pick a solid RPC. Both platforms are closed source, so it’s hard to tell which node provider is being used or whether it’s being used at all, but a hybrid option is often followed: both node providers and deployed local nodes are used.
Handling raw data
As next step a hashed bytecode is received containing blockchain transaction data from node providers. The bytecode is decoded and kept in raw form. The raw data that a certain blockchain is holding should be known to you if you have ever used a [[block explorer]]. These details differ amongst chains, however as an illustration, the majority of chains powered by the Ethereum Virtual Machine (EVM) include:
- Blocks — groups of transactions appended to the chain
- Transactions — cryptographically signed blockchain state instructions
- Logs — events created by smart contracts
- Traces — step-by-step record of what happened during the execution of a transaction
In actuality, the aforementioned entities make up the entirety of the blockchain. This indicates that by use them alone, any decentralized ecosystem may already be fully analyzed. Although the data in these tables may be read by humans (unlike bytecode), doing so needs a deep understanding of the blockchain. The platform stores the aforementioned entities into the following tables as part of the ETL procedure:
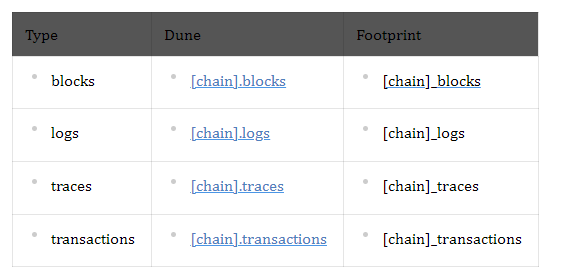
Table data, which is present on both platforms, have almost the same columns, so different queries can be reused between platforms:
https://www.footprint.network/chart/Latest-ethereum-transaction-fp-33365
https://dune.com/queries/1637400
Decoded data
The majority of smart contracts on any EVM blockchain are created using high level programming languages like Solidity. They must be compiled into EVM executable bytecode before they can be used in an EVM execution environment. Once deployed, the bytecode is permanently stored in the chain’s state storage and assigned to a specific address.
Client applications need a guide to call the functions defined in the high-level languages in order to be able to interact with this smart contract, which is currently merely bytecode. An Application Binary Interface (ABI) is used to translate names and arguments into byte form. The ABI properly documents names, types, and arguments, allowing client applications to communicate with the smart contract in a manner that is relatively readable by humans. The source code for the high-level programming language can be utilized to compile the ABI. TLDR: To invoke a smart contract or decipher the data it produces, use the ABI.
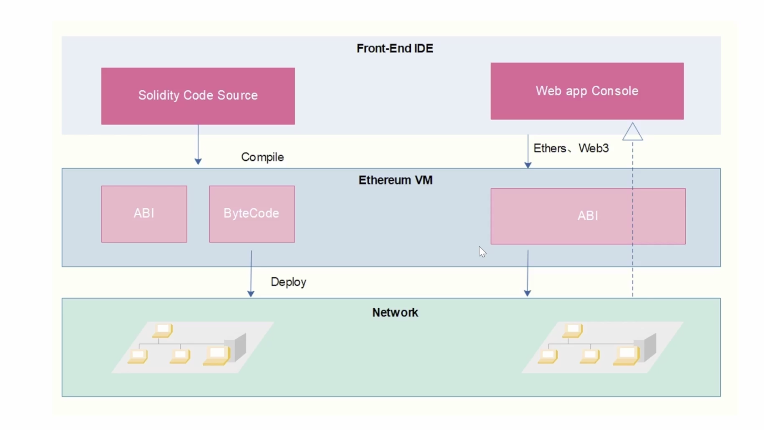
To allow for backward-looking analysis of what is happening, the blockchain is designed to analyze and store events. Smart contracts communicate with one another via transactions and message calls emitting the events within the process. Therefore, looking at events is typically the simplest and most convenient way to analyze various things happening on the blockchain.
However, occasionally important information is omitted from the events that are emitted or there are simply no events at all. Analysts might have to resort to transaction and message calls in these circumstances (found in raw tables). Cases where no event gets emitted get rarer over time as developers now mostly understand that events are important enough to be emitted, but they still exist. In some cases, it might make sense to combine the decoded data with raw data in order to get metadata about the transaction or dive even deeper.
Dune
For contracts to be decoded and added to Dune datasets, the following form could be used: Smart contract upload form Once the contract is parsed, the calls and events associated with the particular smart contract are being saved to the corresponding tables.
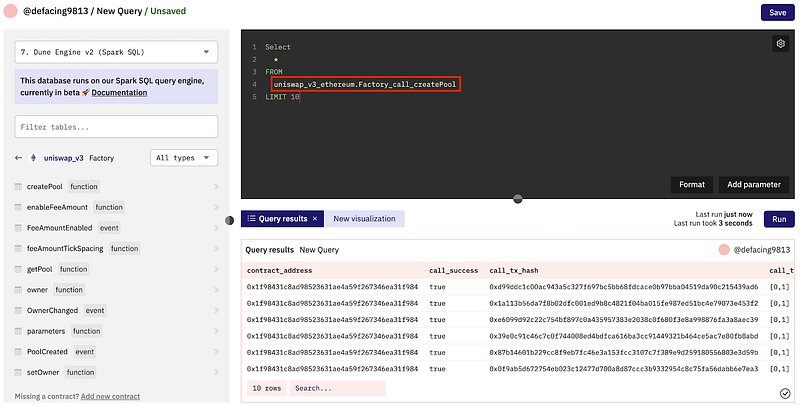
Calls
Typically, a smart contract will have functions that may be called by another smart contract or an externally owned account (EOA). From a straightforward state read and return to modifying several states and triggering message calls to other smart contracts, functions can be anything. Every message call and transaction made to smart contracts could be parsed on Dune into their own tables. The tables are then given the following names:
Events
Event logs are generated by smart contracts when specific predefined actions are finished. The smart contract developer has already predefined the structure of these logs, and the content is dynamically created throughout the transaction. Logs are helpful for tracking activity inside a smart contract and for monitoring, alerting, and other purposes.
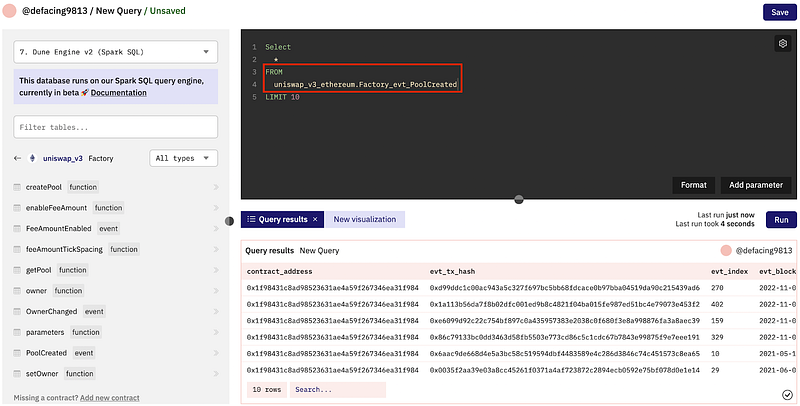
Footprint
Footprint currently supports Ethereum tables for storing calls and events. The underlying raw data for other EVM public chains, together with the submission of ABI and contract analysis requirements, are planned to be released before the end of 2022.
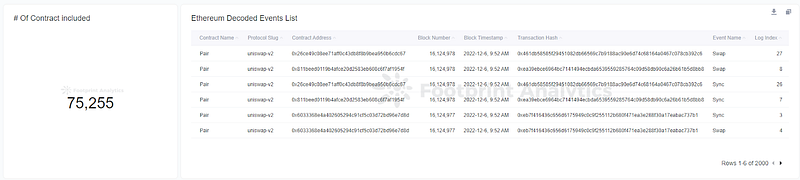

Abstractions over raw data
Transformation of raw data into insightful information is never a trivial task. Although tough, working with it is feasible. Building and fine-tuning ETL models is only a small piece of the effort that many data entrepreneurs conduct on a daily basis. The following specifications are included in the design of the system which is trying to transform the raw data:
- Tables that can analyze new data flows continuously from historical and streaming sources in real time, greatly streamlining the workflow for producing data science.
- Schema enforcement, which makes that tables are kept neat and orderly, free of column contamination, and prepared for machine learning.
- Schema evolution, which enables the addition of new columns to existing data tables without causing them to break while the tables are in use in production.
- Time travel, a.k.a. data versioning, which enables auditing, replication, and even rollback of changes to any Delta Lake table if necessary in the event of inadvertent changes brought about by human error.
Data ingestion (“Bronze”), transformation/feature engineering (“Silver”), and business aggregates (“Gold”) are the three stages of a typical ETL that employ tables that correlate to the various quality levels in the data engineering pipeline. These tables are together referred to as a “medallion” architecture.
It enables data engineers to create a pipeline that starts with unprocessed data and serves as the “single source of truth” through which everything else flows. Even if downstream users clean up the data and add context-specific structure, further transformations and aggregations can be computed and checked to make sure that business-level aggregate tables still reflect the underlying data. Both Dune and Footprint has the following approach implemented within the workflow, but in quite a different forms.
Dune
Silver and Gold tables are in Dune are constructed using a spellbook. Spellbook is a community-built layer. Spells are instructions for creating sophisticated tables that handle widely used use cases, such as NFT trades. Abstractions can be materialized into views and tables, but there are many possible refinements, including incrementally-loaded tables, date-partitioned tables, and more. See all supported materialisation types in Page Not Found | dbt Developer Hub. Data integrity tests can be easily added to a YAML file with just one line. Relational integrity, non-null values, distinct primary keys, and accepted values can all be quickly checked on models. Dbt understands all model dependencies natively.
Footprint
The footprint fully follows the approaches described in medallion architecture. Grouping by levels is done as follows:
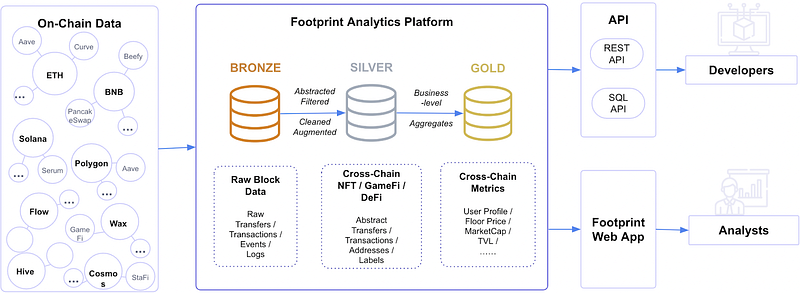
Bronze Unaltered, unprocessed, raw data. supplying thorough records of all blockchain activity. Transactions, logs, traces, and other data, such as in the case of EVM networks, will be stored here in the same manner as data on the blockchain. While it is feasible to conduct queries using this data, doing so effectively requires a solid grasp of the internal workings of smart contracts. The data in tables with this type is the most when compared with others. Thus, the processing of queries implies that the aggregation of this data will take quite a long time.
Silver The unprocessed Bronze data is turned into data sets with added values. This could entail changing codes to relevant values, adding sanity checks, eliminating unnecessary data, etc. Those tables are intended to harmonize data standards for EVM and non-EVM, abstract data structures for various domains, and establish a de facto business logic standard. NFT Transactions, Ethereum Token Transfer, Protocol Transactions, Contract Information, and others are a few of such tables. The main advantages of those tables are that switching between EVM and non-EVM chains, as well as between different marketplaces and protocols, is simple. This is because the data is correctly organized semantically, making it possible for someone without any prior knowledge of raw blockchain data structures to use those tables right away.
Gold Gold tables are business-level data aggregations that directly address questions in a certain domain. Without the need for any aggregations (joins and merges, decoding, etc.) within the query itself, Gold Tables provide a number of statistical indicators that are ready for study. Metrics can be used as-is, saving the development team time during development, run-time computation, as well as data validation and testing, as all of the necessary calculations for statistics like PnL and holding balance of a wallet address have already been performed by Footprint.
Query engine
Dune
DuneV2 changes the whole database architecture. Dune is now transitioning away from a PostgreSQL database to an Instance of [[Apache Spark]] hosted on [[Databricks]] .
Footprint
Footprint Analytics works on [[Apache Iceberg]] and [[Trino]] data architecture. [[Apache Iceberg]] is an open table format for huge analytic datasets. [[Trino]] is a distributed SQL query engine designed to query large data sets distributed over one or more heterogeneous data sources.
Queries execution
Dune
All Dune queries are executed using SQL language.
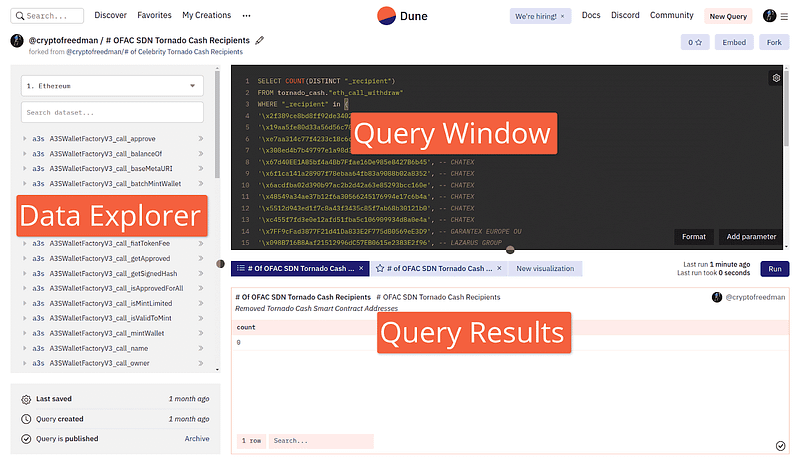
Footprint
Footprint is built on top of [[Metabase]]. The openness of the technology code allows various users to contribute to the code base, thus developing and improving it, which can later be used by other users. The technology itself implements a convenient drag and drop query builder. This significantly lowers the barrier to entry, allowing any user without any technical knowledge to use the product and extract business value.
It is important to note that architecturally Metabase is an abstraction over SQL code, that is, any request made by drag and drop can be represented as SQL. Thus, users who want to build more complex queries, or who prefer to work with data using code, have the opportunity to use SQL straight away.
Visualisations
Reference https://twitter.com/escapist5563