Дістаємо та аналізуємо тексти відео з YouTube-каналів. Частина 1
Стало цікаво, яким же чином можна проаналізувати вміст відео на YouTube. Раніше доводилось працювати з сервісами Google, все захищено і важко добитись хороших результатів без прямого використання їх API. Проте з будь-якої ситуації можна знайти вихід, якщо сильно захотіти.
Що ж саме зробити?
Зацікавили мене рекомендаційні системи та їх реалізація, не дуже круто використовувати вже готові дані по фільмах і подібних речах. Хочеться чогось живого і трендового, слова з інтерв'ю підійдуть для цієї благої місії.
В мене є кілька основних каналів, які я періодично переглядаю, перше, що я б хотів зробити, це дістати ключові слова з текстів, провести мінімальне тематичне моделювання, спробувати прокластеризувати відео в рамках одного каналу. В подальшому перейти на рівень кількох каналів зі всім вмістом.
Дістаємо всі відео з каналу
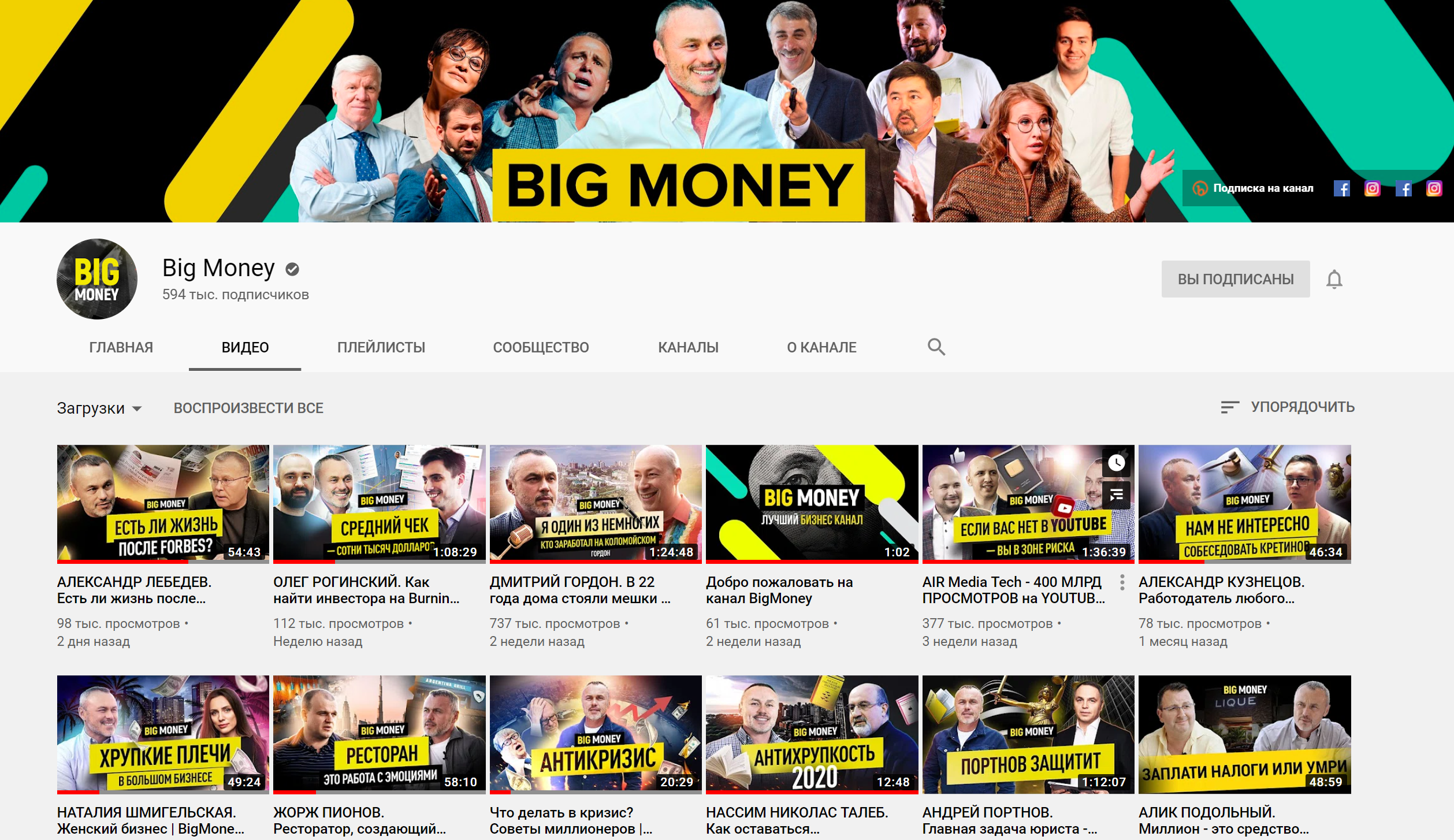
Почну з каналу BigMoney, де Євген Черняк розпитує всіх про їхні бізнеси та підходи, з обов'язковим запитанням про їхню маржу :)
Перше, що приходить на думку, це використання Selenium для збору даних з каналів, прості запити тут не допоможуть, а розбиратись з YouTube API взагалі не хочеться, якщо в результаті буду використовувати лише кілька запитів. Отримувати ключі, ковиряти документацію, займатись довгою обробкою даних, які приходять, напевно ви зрозуміли. Мені ж тільки ID відео з каналу потрібні.
Нещодавно відкрив для себе пакетний менеджер під Windows, це як apt-get install в Linux, дуже прикольна штука під назвою Chocolatey, однозначний плюс шоколадному. Тепер можна не переживати про пошук частини пакетів, вносити їх у змінну PATH, щоб можна було з командного рядка користуватись командами. Виглядає дуже прикольно, я використав це для встановлення драйверів браузерів, що використовуються у Selenium, відповідний пакет можна знайти за посиланням.
Після встановлення абсолютно всіх драйверів до браузерів, можна перейти до використання Selenium. Ще трішки пошукавши рішень, я наткнувся на бібліотеку під назвою yt-videos-list, це було приємно, як я думав, там під капотом Selenium, можна вибрати необхідний драйвер і отримати всі відео з каналу.pip install yt-videos-list і я вже на крок ближче до отримання всіх необхідних даних.
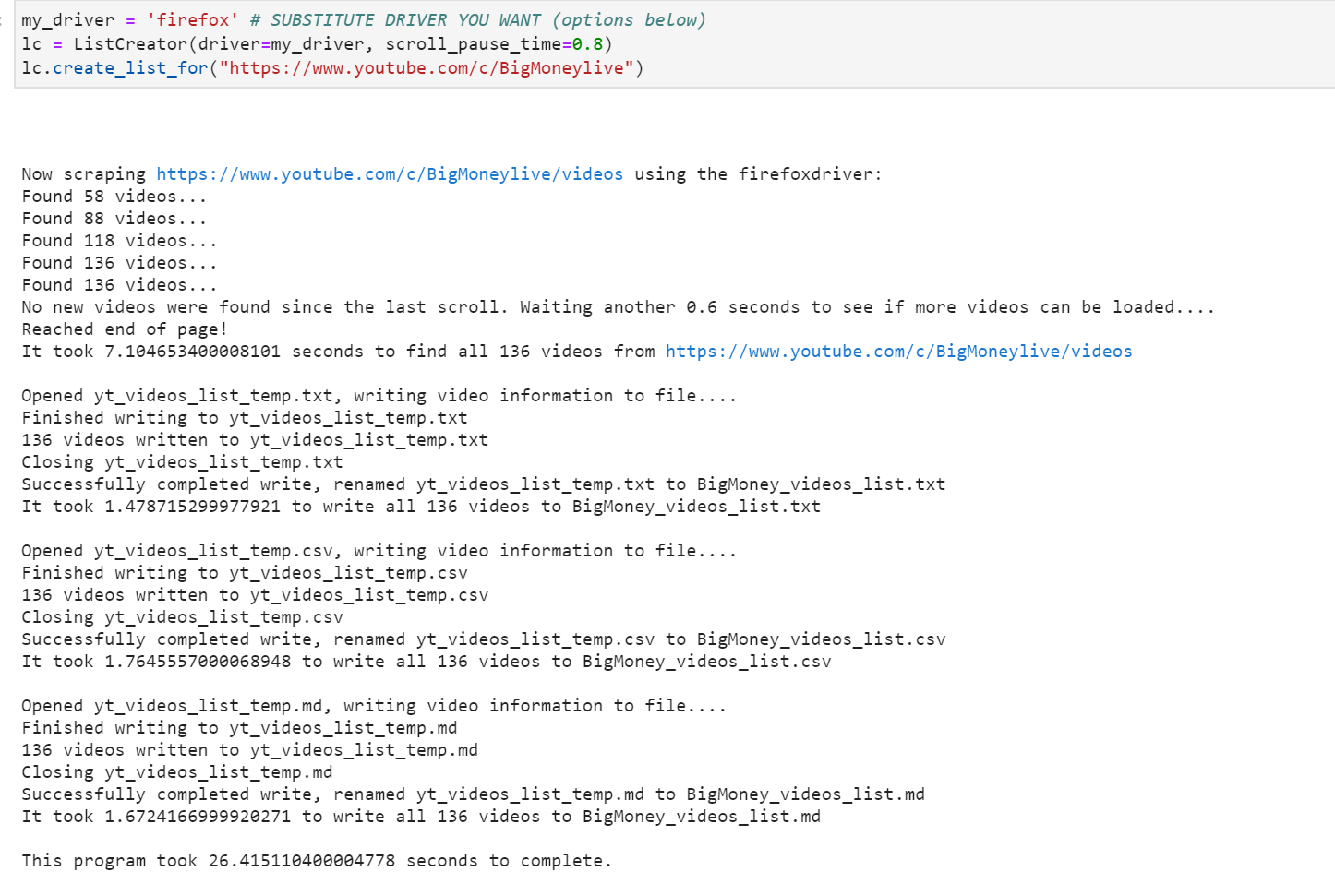
Результатом виконання є кілька файлів зі списком назв та посилань на відео в форматі CSV. З цим чудово справляється Pandas, тому його ми і використаємо для роботи з цими даними. Варто зазначити, що додатково в об'єкті ListCreator використовуються параметри:
txt,md,csv— булеві, можна зберігати у файлах всіх цих форматів;headless— якщо не потрібно, щоб відображався браузер в процесі отримання даних, то варто передати цей параметр зі значеннямTrue.

Бачимо що тут є зайві поля, нам необхідно залишити лише два. Видаляємо непотрібні поля, де немає цікавих нам значень з використанням pandas.DataFrame , тут параметр inplace=True означає, що ми виконуємо кожну операцію і одразу застосовуємо результат до нашого фрейму. Немає необхідності записувати результат кожної з операцій до змінної:
df.drop(columns=["Watched?", "Watch again later?", "Notes", "Video Number"], inplace=True)
df.rename(columns={
"Video Title": "title",
"Video URL": "video_url",
}, inplace=True)Створимо додаткове поле, що відповідає за ідентифікатор відео:
df["video_id"] = df.video_url.map(lambda url: urlsplit(url).query.strip("v="))Цих маніпуляцій нам достатньо аби перейти до слідуючого етапу, де ми будемо витягувати тексти з отриманих відео. Там є декілька нюансів, які розглянемо в слідуючій частині.