Спроба накрутити перегляди на YouTube з допомогою Python 1/4
Цілі
- Реалізувати скрипт, який буде змінювати IP адреси (proxy).
- Оглянути доступні інструменти для цієї задачі.
- Організувати безперебійний перехід на сторінку з відео.
- Дослідити як зараховується перегляд для відео на YouTube.
- Зробити мінімум 350-400 переглядів на обраному відео.
Proxy та їх використання у запитах
Проксі-сервер — сервер, який виступає посередником при виконанні запитів до певного ресурсу, з англійської proxy перекладається як "представник" чи "уповноважений". Не будемо глибоко вникати в суть цієї технології, головне, що варто знати, ми хочемо приховувати справжню IP-адресу для отримання потрібної інформації.
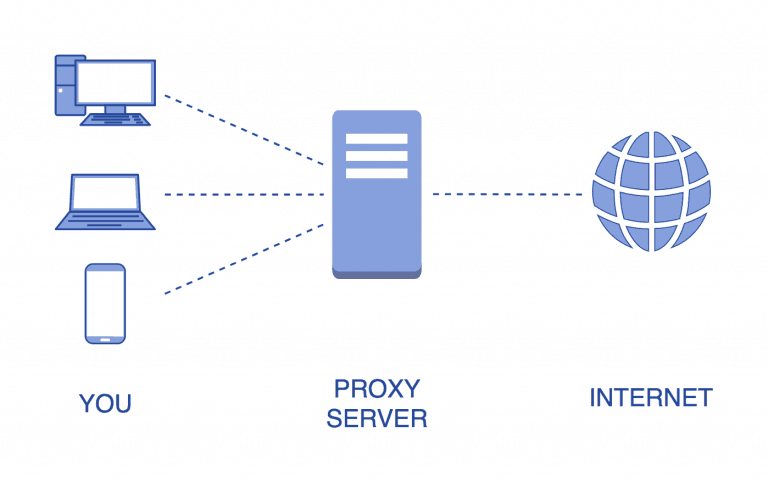
Є багато ресурсів, де можна отримати список безкоштовних проксі-серверів, аби посилати свої запити через них.
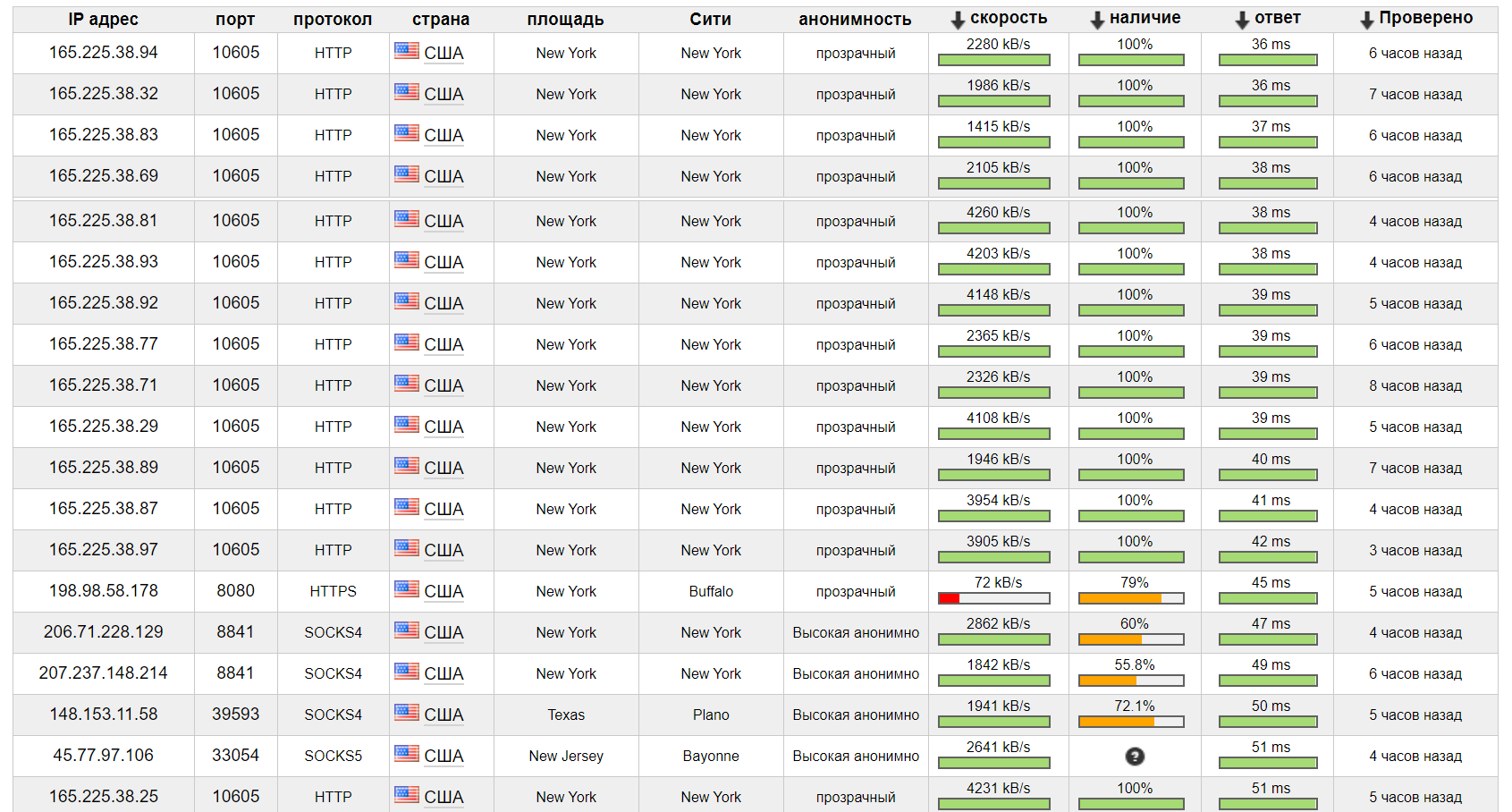
Для роботи нам потрібно IP-адрес та порт, проте інші параметри можуть знадобитись для того, щоб фільтрувати отриманий список.
Країна та місто — часто потрібно використовувати лише фільтрацію по країні, аби отримати доступ до локального ресурсу.
Ступінь анонімності — в залежності від цього параметру гарантується чи високий рівень анонімності, чи абсолютно низький, при якому кінцевий ресурс все одно бачить нашу справжню адресу.
Швидкість відгуку (timeout) — те, наскільки швидко обробляються запити цим проксі-сервером, від цього залежить кількість виконаних запитів.
Як попрактикуватись?
- Скопіювати/завантажити файл зі списком проксі з GitHub.
- Спробувати відправити 20 запитів з різними проксі до ресурсу
https://api.myip.com/з використаннямrequests-futuresабоaiohttpякщо хочеться гострих вражень. - Вивести результати в якості логу з використанням модуля
logging.
Зробивши це, одразу стане зрозуміло, що таке підводні камені безкоштовних проксі-серверів і як з цим справлятись. Або не стане зрозуміло взагалі нічого :)
Приклад коду з requests-futures:
from concurrent.futures import ThreadPoolExecutor from requests_futures.sessions import FuturesSession # створення сесії з використанням мультипроцесингу session = FuturesSession(executor=ThreadPoolExecutor(max_workers=10))
Приклад коду з aiohttp:
# створення асинхронної сесії
async with aiohttp.ClientSession() as session:
async with session.get("http://python.org",
proxy="http://proxy.com") as resp:
print(resp.status)Доволі непогано це все описано в статті: Python та HTTP-клієнти
Загальна інформація про скрапинг тут: Web Scraping в Python. Детальна інструкція