Як хоча б спробувати в Python за місяць
Вступ
Зі всіх усюд майорять статті про те, як почати займатись Data Science, ви вже втомились обирати з цього різноманіття?
Освоїти Python за короткий термін і, можливо, змінити свою кар'єру на щось інше?
В цій статті один з шляхів, яким можна піти, аби познайомитись з наукою про дані та спробувати себе в Python за місяць, все залежить від кількості сил вкладених в це. Тут будуть доступні щотижневі розклади та теми, які слід розглянути, щоб на базовому рівні опанувати Python.
Перш ніж перейти безпосередньо до Python, давайте зрозуміємо про використання Python в науці про дані чи Data Science.
Data Science Pipeline
Наука про дані — це багатопрофільна суміш гіпотез і висновків на основі даних, розробки алгоритмів та технологій для вирішення аналітично складних проблем. Цей напрямок пропонує рішення проблем у реальному світі за допомогою наявних даних. Проте аналіз даних — це покроковий процес. Це група з декількох методик, які використовуються для досягнення відповідного рішення проблеми. Крім того, досліднику, можливо, знадобиться пройти певну кількість етапів, щоб дійти до бачення проблеми, яке може відрізнятись від початкового через збільшення кількості доступної інформації.
Давайте розглянемо як це виглядає на різних етапах.
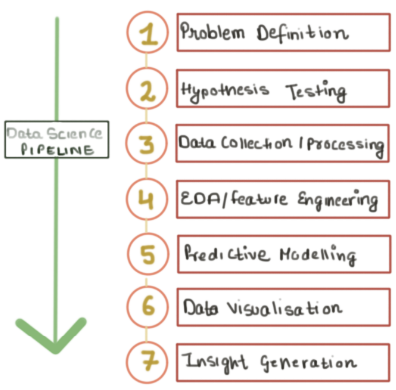
1. Problem Definition | Визначення проблеми
Всупереч поширеній думці, найважча частина наукових даних — це не побудова точної моделі чи отримання хороших, чистих даних. Набагато складніше визначити можливі проблеми та придумати правильні способи для оцінки їх вирішення. Визначення проблеми спрямоване на глибоке розуміння предметної області. Кілька мозкових штурмів дуже допоможуть в тому, щоб правильно визначити проблему через вашу кінцеву мету, залежно від того, яку проблему ви намагаєтесь вирішити. Отже, якщо ви помилитесь під час саме цієї фази, ви отримаєте рішення проблеми, яка спочатку навіть не існувала.
2. Hypothesis Testing | Перевірка гіпотез
Цей етап покладається повністю на статистику, під час якого аналітик перевіряє припущення щодо параметру генеральної сукупності. Простими словами, ми формуємо деякі припущення на етапі визначення проблеми, а потім затверджуємо ці припущення статистично, використовуючи дані. Цей етап дає можливість знайти параметри, що дають можливість побудувати на подальших кроках вірну модель для нашої вибірки.
3. Data collection and processing | Збір та обробка даних
Збір даних — це процес збору та оцінки інформації про цікаві параметри у встановленому систематизованому порялдку, який дає змогу відповідати на визначені дослідницькі запитання, перевіряти гіпотези та оцінювати результати. Більше того, цей етап у дослідженнях є загальним для всіх галузей, включаючи фізичні та соціальні науки, гуманітарні науки, бізнес тощо. Хоча методи відрізняються від дисципліни до дисципліни, акцент на забезпеченні точного та чесного збору даних залишається однаковим. Крім того, обробка даних — це більше про низку дій чи етапів, що виконуються над даними для перевірки, організації, перетворення, інтеграції та вилучення даних у відповідній вихідній формі для подальшого використання. Методи обробки повинні бути суворо задокументовані, щоб забезпечити корисність та цілісність даних.
4. EDA and feature Engineering | Дослідницький аналіз даних та побудова ознак
Після отримання чистих та трансформованих даних наступним кроком для проектів машинного навчання є ознайомлення з даними, використовуючи дослідницький аналіз даних (EDA). EDA стосується числових підсумків, графіків, агрегацій, розподілів, щільності, огляду всіх рівнів факторних змінних та застосування загальних статистичних методів. Чітке розуміння даних дає основу для вибору моделі, тобто вибору правильного алгоритму машинного навчання для вирішення вашої проблеми. Також побудова ознак - це процес визначення тих змінних прогнози яких сприятимуть найбільшою мірою передбачувальній здатності алгоритму машинного навчання. Здебільшого це мистецтво, аніж наука. Дуже добре в процесі цього етапу мати спеціаліста у предметній області, проте підключити свою уяву теж не завадить.
5. Modelling and Prediction | Моделювання та передбачення
Машинне навчання можна використовувати для прогнозування майбутнього. Ви забезпечуєте для моделі колекцію навчальних даних, навчаєте модель на них, а потім застосовуєте модель до нових даних, аби створювати прогнози. Моделювання прогнозів корисно для стартапів, оскільки ви можете виготовляти продукти, які адаптуються на основі очікуваної поведінки користувача. Наприклад, якщо глядач послідовно дивиться одне і те саме джерело контенту на потоковому сервісі, візьмемо канал на YouTube, то програма може завантажувати цей канал при запуску і давати вам його в рекомендаціях.
6. Data Visualisation | Візуалізація даних
Цей етап має в основі процес відображення даних/інформації у графіках чи фігурах. ВІн використовується для надання візуальної звітності користувачам щодо продуктивності, операцій або загальної статистики даних та успішності прогнозування моделі.
7. Insight generation and implementation | Генерація та впровадження інсайтів
Інтерпретація даних більше схожа на донесення ваших висновків зацікавленим сторонам. Якщо ви не можете пояснити свої висновки комусь, повірте мені, все, що ви зробили, не приносить користі. Отже, цей крок стає дуже важливим. Крім того, метою цього кроку є визначення інсайтів для бізнесу, після чого їх потрібно співвіднести з отриманими даними. Також, вам може знадобитись залучення експертів у предметній області, які допоможуть вам сформувати цілісне бачення того, що буде корисно для бізнесу. Ще з іншого боку, це допоможе у доведенні фактів до аудиторії, що не має відношення до технологій.
Використання Python на різних етапах
Ознайомившись з різними етапами в алгоритмі рішень Data Science задач, ми можемо перейти до визначення методів, які пропонує Python на кожному з цих етапів. На цьому кроці ми маємо можливість краще зрозуміти про зв'язок цієї мови програмування та науки про дані.
Для початку, перший та останній етапи не потребують використання жодної мови програмування як такої. Обидва етапи більше базуються на дослідженнях та прийнятті рішень, а не на реалізації з допомогою коду.
1. Python при зборі даних
У процесі розробки багатьох проектів, які мають відношення до науки про дані, потрібно зібрати (scraping) інформацію з веб-ресурсів для отримання даних з якими ви будете працювати. Мова програмування Python знайшла широке застосування у цій області, а тому має велику екосистему модулів та інструментів, які можна використовувати в рамках цього процесу.
2. Python при перевірці гіпотез
Перевірка гіпотез вимагає багато статистичних знань та вмінь їх використовувати. У Python є бібліотеки, які можуть допомогти користувачам легко виконувати статистичні тести та обчислення. Використання таких бібліотек, як SciPy, може полегшити процес автоматизації завдань для перевірки гіпотез.
3. Python при EDA
Для виконання базового аналізу доступно кілька бібліотек. Для EDA можна використовувати pandas та matplotlib, для обробки даних та побудови графіків відповідно. Jupyter Lab для написання коду та інших корисних штук. Jupyter Lab — це свого роду щоденник для аналізу даних та науковців, веб-платформа, де ви можете змішати Python, HTML та Markdown, щоб пояснити свої кроки при дослідженні даних.
4. Python при візуалізації
Однією з ключових навичок науковця є вміння розповідати переконливу історію своїх досліджень. Він повинен візуалізувати дані та знахідки у доступний та стимулюючий спосіб. Також вивчення бібліотеки для візуалізації даних дасть змогу отримувати додаткову інформацію, розуміти дані та приймати ефективні рішення. Крім того, існують такі бібліотеки, як matplotlib, seaborn, що дозволяють створювати досить непогані візуалізації, при цьому вивчення методів роботи з цими інструментами не займає багато часу.
5. Python при моделюванні та передбаченні
Python може похвалитись бібліотеками на зразок scikit-learn, бібліотекою з відкритим вихідним кодом в якій реалізовано алгоритми машинного навчання, попередньої обробки, перехресної перевірки та візуалізації за допомогою уніфікованого інтерфейсу. Такі бібліотеки абстрагуються від математичної реалізації моделі. Отже, розробники можуть зосередетись на побудові надійних моделей, а не на розумінні складної математичної реалізації. Якщо ви новачок у машинному навчанні, тоді ви можете перейти за цим посиланням аби дізнатись більше.
Хронологія вивчення
У цьому розділі ми розглянемо тижневий розподіл тем для знайомства з Python. Це допоможе вам організувати ваш графік роботи та дозволить мати спеціальну дорожню карту на місяць.
Одразу варто зазначити, що ви не станете хорошим спеціалістом чи тим більше експертом в цій області, за цей час. Але ви можете дати поштовх в розвитку в цьому напрямку.

Тиждень 1
- Основи Python Варто почати з вивчення того, що таке змінні, які є конструкції управління потоком виконання. Опанувати базові операції та функції. Дізнатись з якими базовими типами даних поставляється стандартна бібліотека Python.
- Поглиблений Python Одразу після того, як будуть освоєні базові концепції, ви можете сконцентруватись на таких речах як: багатопотоковість, класи, об'єкти, регулярні вирази, робота з мережею тощо. Багато з цього може не знадобитись кожного дня, проте з цим варто бути знайомим.
Курси та матеріали, що допоможуть з вивченням, вони покривають обидва кроки з цього тижню, обирати лише вам, які з них використовувати:
Stepik: Програмування на Python та Stepik: Python. основи та застосування
TutorialsPoint: Python Tutorial
Тиждень 2
- Web scraping в Python Мається на увазі збір даних з веб-сайтів за допомогою коду, це є найбільш логічним та легкодоступним джерелом даних для подальшої обробки. Автоматизація цього процесу за допомогою Python дозволяє уникнути ручного збору даних, економить час, а також дозволяє мати всі дані в потрібній структурі. Ви можете почати знайомство з таких бібліотек, як BeatifulSoup та Scrapy.
- Pandas, numPy та SciPy в Python В Python є прекрасний набір бібліотек, який покриває більшість задач по управлінню даними. Pandas дозволяє отримати доступ до даних у вигляді Data Frame, своєрідна таблична форма, яка дозволяє дуже просто проводити будь-які потрібні маніпуляції. Це у великій мірі спрощує роботу зі складними структурами та виконанням чисельних операцій над ними, будь то очищення даних, узагальнення даних тощо. NumPy в свою чергу забезпечує повним спектром чисельних методів та складних математичних структур. Багато методів з цієї бібліотеки є де-факто стандартом інтерфейсу по взаємодії з числовими даними в різних бібліотеках. Відповідно для виконання складних наукових та важких математичних обчислень існує бібліотека SciPy. Ці бібліотеки знайдуть застосування не лише при роботі в області науки про дані.
Тиждень 3
Третій тиждень — це про розуміння можливостей машинного навчання при використанні Python.
- Бібліотека Scikit-learn Ця бібліотека найбільш поширений вибір для вирішення задач класичного машинного навчання, її інтерфейс послугував для багатьох інших бібліотек. Обов'язково вкладіть свій час у вивчення методів цієї бібліотеки, вона забезпечує єдиний спосіб використання різних моделей.
- Бібліотека Keras
Ця бібліотека призначена для спрощення процесу створення моделей глибокого навчання (deep learning). Вона підтримує широкий спектр шарів нейронних мереж, таких як згорткові шари, рекурентні або щільні. Вам потрібно думати лише над використанням тої чи іншої архітектури, замість складної математичної реалізації. Також можна подивитись в сторону PyTorch, що на даний час є доволі популярним.
Тиждень 4
Четвертий тиждень — це більше про можливості візуалізації та узагальнення всіх попередніх знань у формі проекту.
- Matplotlib в Python Ця бібліотека для побудови 2D графіків, що легко можна поширювати від однієї платформи до іншої, її можна використовувати як в скриптах, в Python та IPython консолях, ноутбуках Jupyter, серверних додатках та в різноманітних графічних інтерфейсах, як приклад tkinter. Matplotlib дає можливість трішки спростити багато речей, які приходилось би писати вручну.
- Проект Освоївши всі вищезгадані інструменти, настав час застосувати ці всі знання разом у вигляді проекту. Проект допоможе вам отримати бачення того, яким чином застосовуються ті чи інші бібліотеки, знайти нові запитання, на які прийдеться шукати відповіді, а також отримати загальну картину побудови Data Science Pipeline.
Зразок проекту, яким слід закріпити знання
Ви можете обрати будь-який проект, який вам подобається. Якщо ж ви заплутались і не знаєте, що за проект реалізувати, ви можете взяти проблему "Titanic", що є своєрідним Hello, World! у сфері Data Science.
Я не розкажу вам, як це вирішити, але я можу дати вам кілька порад для початку проекту:
- Не будьте в погоні за рахунком вашої моделі на Kaggle. Мета полягає в тому, аби завершити проект, а не намагатись розробити хорошу модель;
- Робіть більше обробки даних та EDA замість того, щоб проектувати складну модель;
- Зосередьтеся на обробці даних з допомогою вивчених бібліотек (Pandas, NumPy, Matplotlib).
Висновок
Python - надзвичайно універсальна мова програмування. Окрім Data Science, ви можете використовувати її для створення веб-додатків, різноманітних інструментів автоматизації і навіть автономних безпілотників. Величезний відсоток програмістів у світі використовує Python, і це не дарма. Крім того, я думаю, що кожен може досягти високого рівня володіння ним, якщо знайде правильну мотивацію. Натхнення у навчанні!
Переклад статті Divya Singh: How to Learn Python in 30 days