Web Scraping в Python. Детальна інструкція
Збір даних на даний момент у 2020 році — це один з основних напрямків задач, які можна зустріти на Freelance біржах, до прикладу Upwork. Також це єдиний спосіб отримати бажані дані, якщо власники веб-сайтів не надають доступ через API для своїх користувачів. Багато веб-сайтів, таких Twitter, YouTube або Facebook, надають простий спосіб отримати доступ до своїх даних через публічний API. Отримана таким чином інформація належним чином структурована та нормалізована. Наприклад, це можуть бути формати JSON, CSV або XML.
4 способи отримати дані з будь-якого веб-сайту
№0 RSS
Стояла задача отримувати дані з Upwork, там майже неможливо займатись скрапінгом та збирати дані. Можна використовувати API, проте для цього потрібно відправляти свої документи на верифікацію.
При цьому всьому після дослідження robots.txt побачив, що є доступна можливість отримувати дані чере з RSS (Really Simple Syndication).
З допомогою цього можна дуже просто отримувати оновлення ресурсів, збирати новини чи нові повідомлення на форумах. В Python використовувати це, можна з допомогою бібліотеки feedparser.
№1 Офіційне API
В інших випадках, перш за все, ви завжди повинні перевірити, чи є офіційний API, який ви можете використовувати для отримання потрібних даних.
Іноді офіційний API не оновлюється у відповідності до змін на ресурсі, або деякі при його використанні відсутні, до прикладу, Amazon Seller API.
№2 "Прихований API"
Серверна частина може генерувати дані в форматі JSON або XML, далі ці дані відправляються браузеру для відображення користувачам. Для нас, розробників, це хороша можливість скористатись інспектором в браузері, де можна дослідити вкладку XMLHttpRequest (XHR) і, можливо, знайти потрібні нам запити до API цього ресурсу.
Цей спосіб надасть нам можливсіть отримати дані так само, як це б зробив офіційний API, правда без детальної документації доступних методів.
Як отримати ці дані? Давайте самостійно "вполюємо" кінцеву точку API!
Наприклад, візьмемо ресурс, де відображається статистичні дані по COVID19.
- Відкрийте Chrome DevTools натиснувши Ctrl+Shift+I або F12
- Як тільки відкриється консоль, перейдіть до вкладки "Network".
- Давайте використаємо фільтр XHR, щоб визначити кінцеву точку API як запит "XHR", якщо він доступний.
- Варто переконатись, що кнопка "recording" включена, аби відображались всі запити належним чином.
- Перезавантажте сторінку.
- Натисніть зупинити "recording", коли бачите, що вміст запитів, пов’язаний з даними, вже з’явився на веб-сторінці.
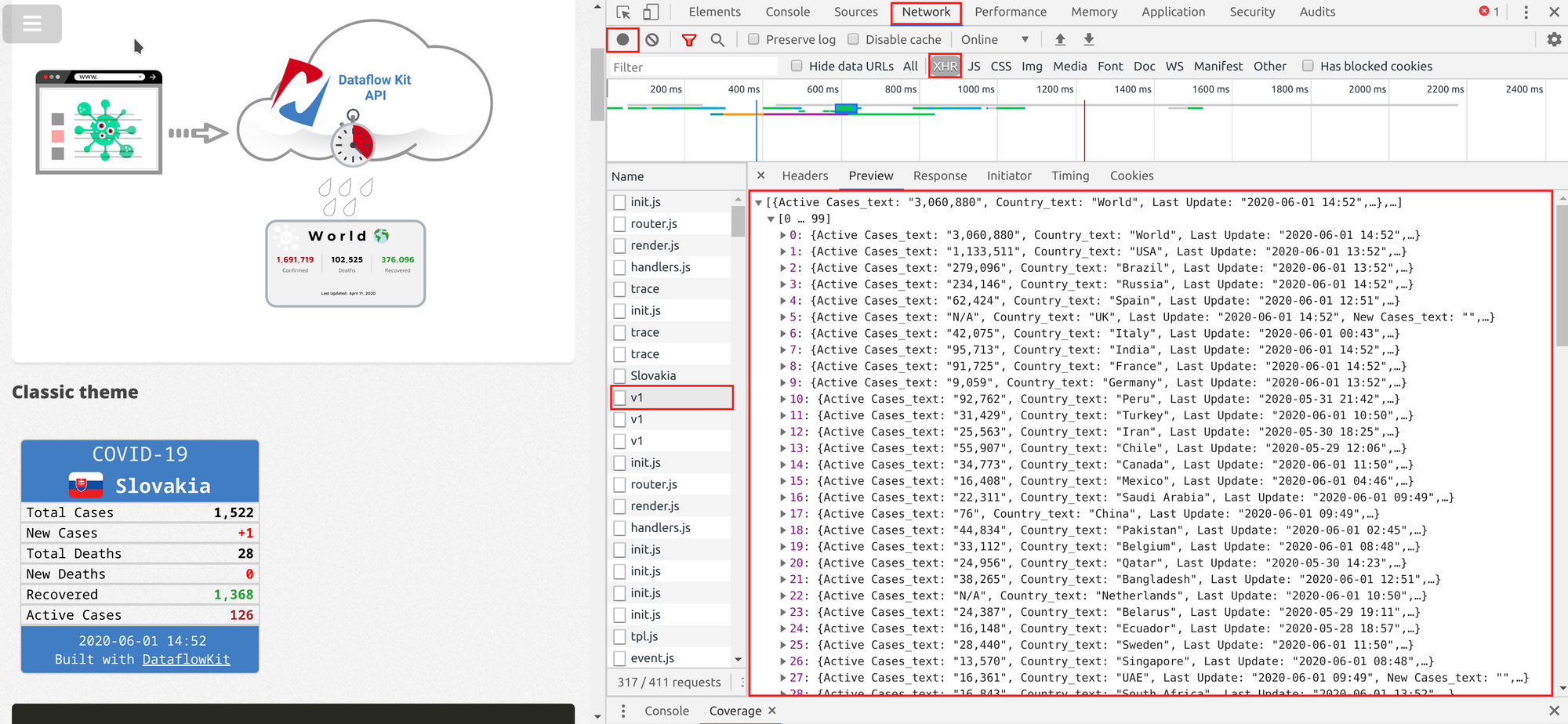
Зараз перед вами список із запитів зліва. Досліджуйте їх. Вкладка попереднього перегляду відображає масив значень для запиту під назвою " v1".
Натисніть на вкладку "Headers", аби переглянути деталі потрібного запиту. Найбільш важливою штукою для нас є метод запиту та URL. В даному випадку для позиції " v1" URL є https://covid-19.dataflowkit.com/v1.
Тепер, давайте просто відкриємо цей URL як іншу вкладку браузеру, щоб побачити що ж відбудеться.
Круто! Це те, що ми шукали.
Отже, отримання даних безпосередньо через API або використання вищеописаної техніки, це найпростіший шлях до завантаження потрібних наборів даних з веб-ресурсів. Звичайно, ці методи можуть бути не надто ефективними для деяких веб-сайтів, тому бібліотеки з web scraping функціоналом все ще необхідні.
Web scraping або вилучення даних з веб-сайтів - це єдиний шлях для отримання бажаних даних, якщо власники ресурсу не надають доступ до їх API. Scraping є технікою вилучення даних, що може автоматизувати повторний ввід даних або копіювання з послідуючою вставкою.
№3 Website scraping. Знай правила!
Що слід перевірити перед тим, як отримувати дані з веб-сайту?

☑️Robots.txt — це перше, що потрібно перевірити, перед тим як діставати будь-які дані з веб-сайту. Файл Robots.txt перераховує правила того, як ви або бот повинні взаємодіяти з цим ресурсом. Ви завжди повинні поважати та дотримуватися всіх правил, перелічених у robots.txt.
☑️Не забудьте також переглянути Terms of use сайту. Якщо умови використання не говорять про те, що це обмежує доступ до ботів чи павуків і не забороняє швидкі запити сервера, то можна без будь-яких сумнівів вилучати дані.
☑️ Варто також подумати про те, аби відповідати Загальному регламенту ЄС про захист даних або GDPR, потрібно спершу оцінити проект по збору даних. Якщо ж проект не збирає персональні дані, то в такому випадку GDPR не застосовується. В цьому випадку можна пропустити цей крок та переходити
☑️Будьте уважні стосовно того чи вилучені дані не порушують авторські права, таке іноді трапляється. Якщо умови використання не накладають обмеження стосовно цього моменту, то ваш збір даних може використовуватись так довго, наскільки вам вистачить ресурсів.
Детальніше про це можна прочитати в статті: Веб-сканування законно чи ні?
Sitemaps
На типових веб-сайтах є файли мапи сайту, що містять список посилань, що належать до цього веб-сайту. Вони допомагають пошуковим системам простіше сканувати веб-сайти та індексувати їх. Отримати URL-адреси з веб-сайтів для сканування завжди набагато швидше, ніж послідовно збирати їх з допомогою опрацювання сторінок.
Відображення ресурсів, керованих з допомогою JavaScript
Фреймворки JavaScript, такі як Angular, React, Vue.js широко використовуються для створення сучасних веб-додатків. Коротше кажучи, типовий інтерфейс веб-додатків складається з HTML + JS-коду + CSS-стилів. Зазвичай вихідний HTML спочатку не містить усього фактичного вмісту. Під час завантаження веб-сторінки елементи HTML DOM динамічно завантажуються разом з виконанням коду JavaScript. В результаті ми отримуємо статичний HTML.
☑️Ви можете використовувати Selenium для збору даних з веб-сайтів, але це не дуже гарна ідея, хоча багато навчальних посібників говорять про використання саме з цією ціллю. На домашній сторінці чітко зазначено, що Selenium "для автоматизації тестування веб-додатків".
☑️ PhantomJS раніше використовувався для подібних задач, це схоже на браузер без візуальної обгортки, що забирає багато ресурсів. Проте, з 2018 року розробка цього інструменту заморожена.
☑️ Як альтернатива, Scrapinghub's Splash раніше був варіантом для Python розробників перед Headless Chrome.
Ваш браузер — це скрапер веб-сайтів по своїй природі. Найкращим способом на сьогодні є використання Headless Chrome для відображення сторінок.
Будьте розумними. Не дозволяйте їм блокувати вас.

Деякі веб-сайти використовують техніки для протидії автоматизованим інструментам збору даних. Web scraping — це завжди гра в "кота й мишки". Тому проектуючи та розробляючи ваш скрапер, візьміть до уваги наступні поради по уникненню блокувань. Або ви ризикуєте не отримати очікуваного результату.
Порада №1: Робіть випадкові затримки між запитами
Коли людина відвідує веб-сайт, швидкість доступу до різних сторінок у рази менша порівняно зі швидкістю веб-сканера. Скрапер, навпаки, може витягнути кілька сторінок одночасно за короткий час. Величезний трафік, який надходить на сайт за короткий проміжок часу, виглядає підозрілим.
Ви повинні дізнатися ідеальну швидкість сканування, індивідуальну для кожного веб-сайту. Щоб імітувати поведінку користувачів людини, ви можете додавати випадкові затримки між запитами.
Не створюйте надмірне навантаження на сайт. Будьте ввічливі до веб-сайту, з якого витягуєте дані, щоб ви могли продовжувати використовувати цей ресурс, не турбуючись про те, що будете заблоковані.
Порада №2: Заміна User-Agent
Коли браузер підключається до веб-сайту, він передає рядок User-Agent (UA) у заголовку HTTP. Це поле визначає браузер, номер його версії та операційну систему, яку використовує користувач.
Типовий рядок User-Agent виглядає подібним чином:
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36
- Якщо кілька запитів на один і той же домен виконуються з використанням одного і того ж агента користувача, веб-сайт може дуже швидко вас заблокувати .
- Деякі веб-сайти блокують конкретні запити, якщо вони містять User-Agent рядок, що сильно відрізняється від загальнодоступних браузерів.
- Якщо значення "user-agent" пропущено, багато веб-сайтів не дозволять отримати доступ до їх вмісту.
Створіть список з доступних значень для User-Agent заголовків та використовуйте їх випадковим чином. Також допоможе Python бібліотека — fake-useragent.
Порада №3: Заміняйте IP-адреси. Використовуйте проксі-сервери
Якщо ви часто надсилаєте по кілька запитів з однієї і тієї ж IP-адреси в процесі збору інформації, веб-сайт може розпізнати підозрілу поведінку і заблокувати вас.
У найпростіших випадках достатньо використання дешевих Datacenter proxies. Але деякі веб-сайти мають складні алгоритми для розпізнавання ботів, тому в таких випадках приходиться використовувати дорожчі residential або mobile пороксі для збору даних.
Наприклад, хтось у Європі хоче отримати дані з веб-сайту з обмеженим доступом лише для американських користувачів. Очевидно, що запити проводяться через проксі-сервер, розташований у США, оскільки їхній трафік, як здається для ресурсу, надходить з американської IP-адреси.
Порада №4: Уникайте паттернів для web scraping. Імітуйте поведінку людини
Люди непередбачувані під час навігації по веб-сайту. Вони роблять різні випадкові дії, як натискання на різні області сторінки та рухи миші.
З іншого боку, скрапери використовують наперед визначені правила для збору інформації з ресурсу.
Навчіть свій скрепер наслідувати поведінку людини. Таким чином, алгоритми виявлення ботів на веб-сайті не мають жодних причин заважати вам виконувати автоматизовані завдання по збору даних.
Порада №5: Слідкуйте за засобами проти web scraping
Одним з найбільш часто використовуваних інструментів для виявлення спроб злому або веб-сканування є "honey pot" (горщик з медом). Такі речі не видимі для людського ока, але доступні для ботів та скраперів. Одразу після того, як скрапер натисне на невидиме посилання, сайт блокує його доволі просто.
Дізнайтеся, чи встановлено властивість CSS "display: none" або "visibility: hidden" та просто обходьте такі посилання. В іншому випадку, ресурс легко зрозуміє, що має справу не з людиною.
Порада № 6: Розв’яжіть CAPTCHA
Під час сканування веб-сайту у великих об'ємах є ймовірність бути заблокованими веб-сайтом. В такі моменти вам починає відображатись CAPTCHA замість веб-сторінок.
CAPTCHA - це тест, який використовується веб-сайтами для боротьби з ботами та сканерами, просячи відвідувачів веб-сайту довести, що вони люди, перш ніж продовжувати роботу з ресурсом.
Багато веб-сайтів використовують reCAPTCHA від Google. Остання версія v3 reCAPTCHA аналізує поведінку людини і вимагає від них поставити галочку "I'm not a robot".
Сервіси для вирішення CAPTCHA використовують два способи:
☑️ Human-based CAPTCHA Solving Services
Коли ви відправляєте свою CAPTCHA для вирішення до такого сервісу, її обробляють люди та повертають назад до вас.
☑️ OCR (Optical Character Recognition) Solutions
В цому випадку використовуються методи машинного навчання для розпізнавання символів на зображенні, такі сервіси виконують обробку автоматично.
Використання візуальних селекторів
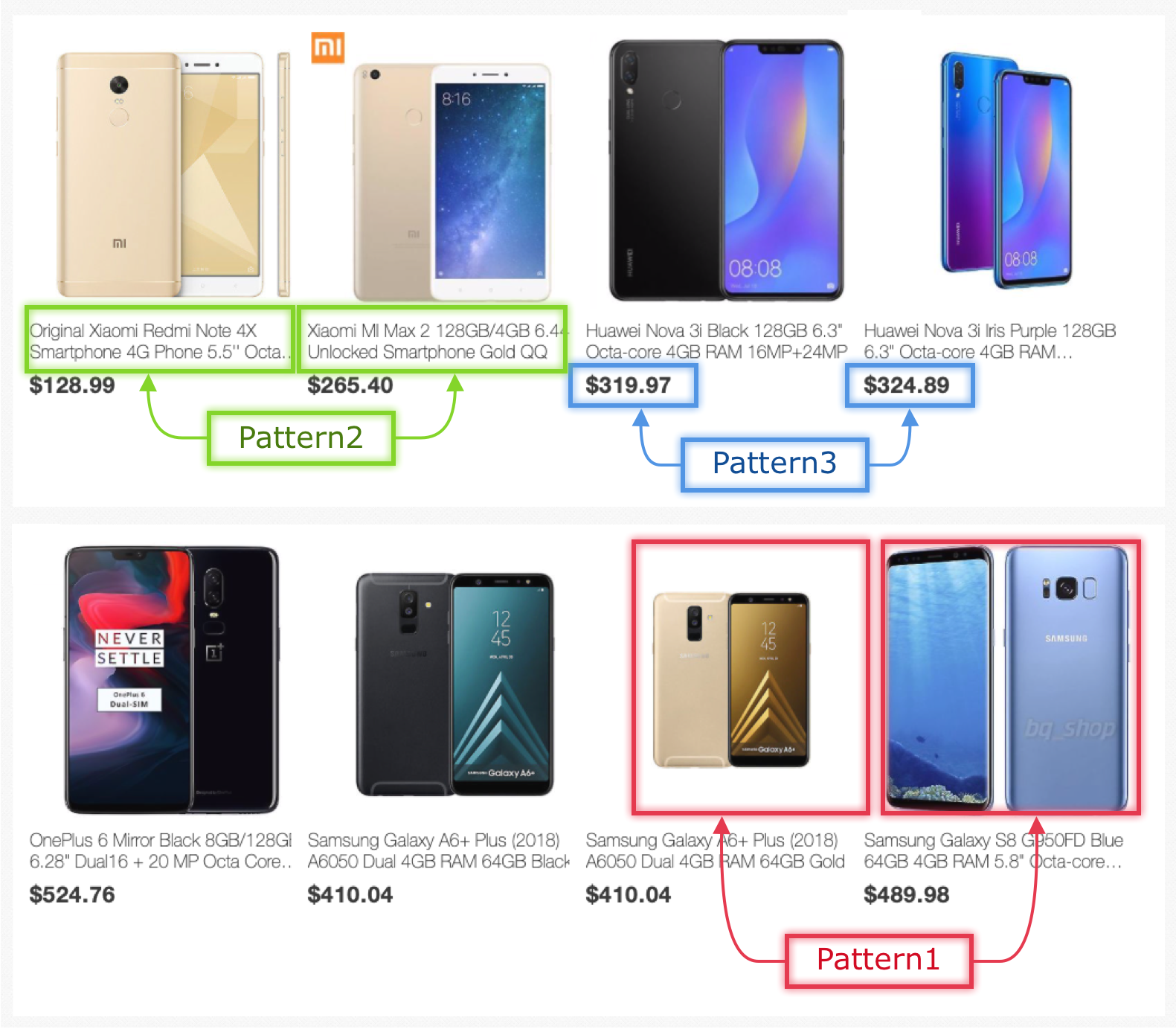
Before starting of data extraction, let's specify patterns of data. Look at the sample screenshot taken from web store selling smartphones. We want to scrape the Image, Title of an item, and its Price.Google chrome inspect tool does a great job of investigating the DOM structure of HTML web pages.
Перш ніж розпочати вилучення даних, давайте визначимо структуру даних чи шаблон того результату, який ми отримуємо. Подивіться на зразок, зроблений із веб-магазину, що продає смартфони. Ми хочемо отримати зображення, назву предмета та його ціну.
Google chrome inspect tool дозволяє зручно проводити вивчення структури DOM для веб-сторінок.

Клікніть на піктограму Inspect в лівому верхньому кутку інструменту DevTools.
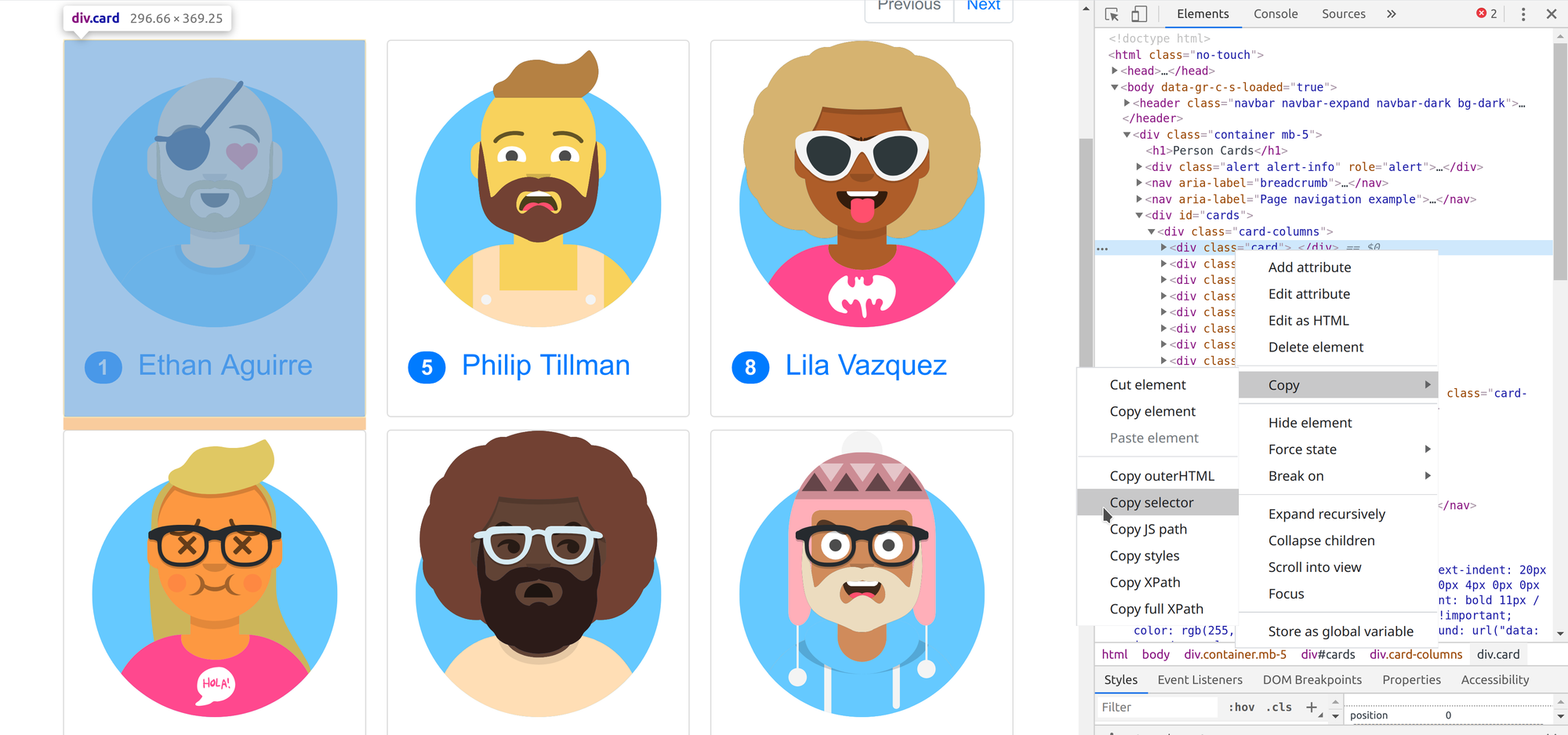
За допомогою інструмента Chrome Inspect ви можете легко знайти та скопіювати CSS Selector or XPath для обраного DOM на цій сторінці.
Usually, when scraping a web page, you have more than one similar block of data to extract. Often you crawl several pages during one scraping session.
Зазвичай під час збору даних з веб-сторінки ви маєте більше ніж один аналогічний блок даних. Сучасні онлайн-скрапери в більшості випадків пропонують зручніший спосіб задати шаблони (CSS Selectors або XPath) для збору даних, встановити правила розбиття сторінок і правила для обробки деталей тої чи іншої сторінки на своєму шляху.
Можете переглянути дане відео для того, щоб з'ясувати як це працює.
Оберіть стратегію для збереження даних
Найбільш відомі прості формати даних для зберігання структурованих даних на сьогоднішній день включають CSV, Excel, JSON (Lines). Зібрані дані можуть бути відформатовані відразу після розбору веб-сторінки. Ці формати підходять для зберігання даних як малогабаритних сховищ.
Сканувати кілька сторінок може бути простою задачею, але мільйони сторінок вимагають інших підходів.
Як просканувати кілька мільйонів сторінок і витягти десятки мільйонів записів?
Що робити, якщо розмір вихідних даних коливається від середніх до великих?
Визначіть правильний формат для вихідних даних

Формат №1. Формат значень, розділених комами (CSV)
CSV — це найпростіший формат обміну даними, що є дуже простим для розуміння людиною. Кожен рядок файлу це один запис. Кожен запис складається з даних по відповідних однакових полях, розділених комами. Поля зазвичай визначені у першому рядку.
Тут список сімей відображених у вигляді CSV:

CSV обмежений для зберігання двовимірних нетипізованих даних. В цьому форматі складно реалізовувати вкладені структури даних.
Формат №2. JSON
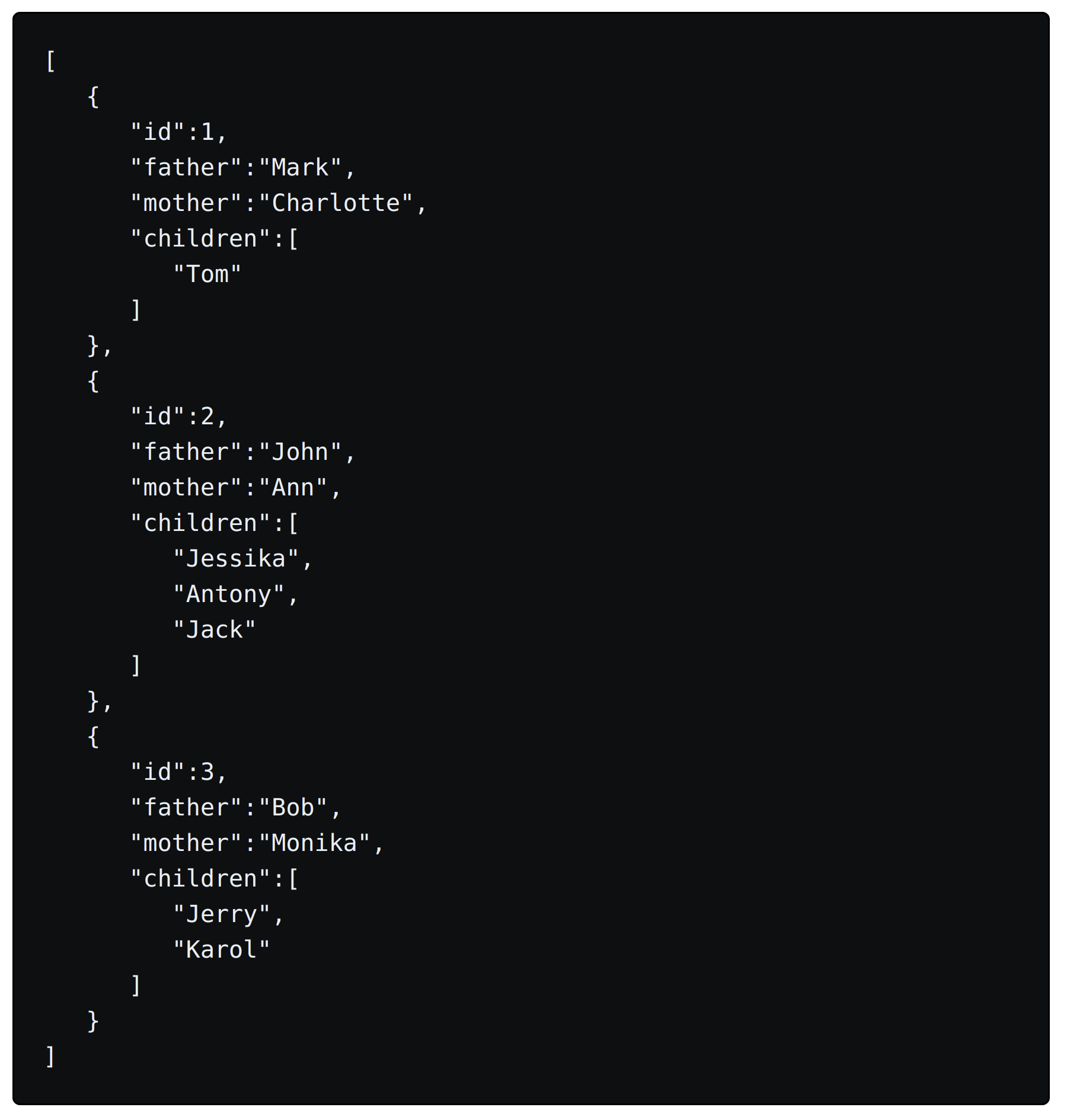
Створення складних вкладених структур у файлах JSON є доволі простою задачею.
В даний час JavaScript Object Notation (JSON) стала фактичним стандартом формату обміну даними, замінюючи XML у більшості випадків.
Один з наших проектів складається з 3 мільйонів розібраних сторінок. В результаті розмір кінцевого JSON становить понад 700 Мб.
Проблема виникає, коли вам доведеться мати справу з такими розмірами JSON. Щоб вставити або прочитати запис з масиву JSON, потрібно щоразу аналізувати весь файл, що далеко не ідеально.
Формат №3. JSON Lines
Давайте розглянемо, що таке формат JSON Lines та як він порівнюється з традиційним JSON. В індустрії доволі часто використовується саме цей формат, Logstash та Docker зберігають логи в форматі JSON Lines.
Той самий список сімей виражений у форматі JSON Lines виглядає так:
{"id":1,"father":"Mark","mother":"Charlotte","children":["Tom"]}
{"id":2,"father":"John","mother":"Ann","children":["Jessika","Antony","Jack"]}
{"id":3,"father":"Bob","mother":"Monika","children":["Jerry","Karol"]}JSON Lines складається з декількох рядків розділених символом нового рядка \n, у яких кожен рядок є типовим об'єктом JSON. Наприклад, це дозволяє розділити файл, що займає 10GB, на менші файли і використовувати їх по мірі необхідності.
Переклад статті: The A-Z of Web Scraping in 2020 [A How-To Guide]