Collection of confidential information through Google Dork's

We will teach you to see more.
Google Dorks or Google Hacking is a technique used by the media, investigative agencies, hackers, and anyone else to create queries on the Google search engine to discover hidden information and vulnerabilities that can be found on public servers. This is a method in which ordinary website search requests are used to their fullest extent to determine the information hidden on the surface.
How does Google Dorking work?
This example of collecting and analyzing information, acting as an OSINT tool, is not a Google vulnerability or a device for hacking website hosting. On the contrary, it acts as a regular data mining process with enhanced capabilities. And this is not new, as there are a huge number of websites that are over a decade old and serve as repositories for learning and using Google Hacking.
Search engines index, store headers and page content, and link them together for optimal search queries. Web spiders of any search engines are configured to index absolutely all information found . Even though the administrators of the web resources had no intention of publishing this material.
However, the most interesting thing about Google Dorking is the sheer amount of information that can help anyone in the process of learning about Google's search process. It can help beginners in finding missing relatives, or it can teach you how to extract information for your own benefit. In general, each resource is interesting and amazing in its own way and can help everyone in what they are looking for.
What information can be found through Dorks?
Starting from remote access controllers of various factory mechanisms to configuration interfaces of important systems. There is an assumption that no one will ever find a huge amount of information posted on the network.
However, let's take it in order. Imagine a new security camera that allows you to view its broadcast on your phone at any time. You set up and connect to it via Wi-Fi, and download an application to authenticate the login of the surveillance camera. After that, you can access the same camera from anywhere in the world.
In the background, not everything looks so simple. The camera sends a request to the Chinese server and plays the video in real time, allowing you to log in and open the live video hosted on the server in China from your phone. This server may not require a password to access the feed from your webcam, making it publicly available to anyone who searches for the text contained on the camera view page.
Google is ruthlessly efficient at finding any device on the internet running on HTTP and HTTPS servers. And since most of these devices contain some kind of web framework to customize them, it means that a lot of things that weren't meant to be on Google end up there.
By far the most serious type of file is the one that carries the credentials of users or the entire company. This usually happens in two ways. In the first, the server is configured incorrectly and exposes its administrative logs or logs to the public on the Internet. When passwords are changed or the user is unable to log in, these archives can be leaked along with the credentials.
The second option occurs when configuration files containing the same information (logins, passwords, database names, etc.) become public.
This article illustrates the use of Google Dorks to show not only how to find all these files, but also how vulnerable platforms can be that contain information in the form of a list of addresses, email, pictures, and even a list of webcams in the public domain.
Parsing Search Operators
Dorking can be used on various search engines, not just Google. In everyday use, search engines such as Google, Bing, Yahoo, and DuckDuckGo accept a search term or search string and return the corresponding results. Also, these same systems are programmed to accept more advanced and complex operators that greatly narrow these search terms.
An operator is a keyword or phrase that has a special meaning for a search engine.
Here are examples of commonly used operators: "inurl", "intext", "site", "feed", "language". Each operator is followed by a colon followed by the corresponding passphrase or phrases.
These operators allow you to search for more specific information, such as certain lines of text within the pages of a website, or files located at a specific URL. Among other things, Google Dorking can also find hidden login pages, error messages giving information about available vulnerabilities, and shared files. The main reason is that the website administrator may have simply forgotten to exclude from public access.
The most practical and at the same time interesting Google service is the ability to search for deleted or archived pages. This can be done using the "cache:" operator. The operator works in such a way that it shows a saved (deleted) version of a web page stored in the Google cache. The syntax for this operator is shown here:

After making the above request to Google, access to a previous or outdated version of the Youtube web page is provided. The command allows you to call the full version of the page, the text version, or the source of the page itself (integral code). It also indicates the exact time (date, hour, minute, second) of the indexing done by the Google spider. The page is displayed as a graphic file, although the search on the page itself is carried out in the same way as in a regular HTML page (key combination CTRL + F). The results of running the "cache:" command depend on how often the web page has been indexed by Googlebot. If the developer himself sets the indicator with a certain frequency of visits in the title of the HTML document, then Google recognizes the page as secondary and usually ignores it in favor of the PageRank coefficient, which is the main factor in the frequency of page indexing. Therefore, if a particular web page has been modified between Googlebot visits, it will not be indexed and will not be read using the "cache:" command. Examples that work particularly well when testing this feature are frequently updated blogs, social media accounts, and internet portals.
Deleted information or data that was posted by mistake or needs to be deleted at some point can be recovered very easily. The negligence of a web platform administrator may put him at risk of spreading unwanted information.
User information
Searching for information about users is used with advanced operators that make the search results precise and detailed. The "@" operator is used to search for user indexing in social networks: Twitter, Facebook, Instagram. Using the example of the same Polish university, you can find its official representative on one of the social platforms using this operator as follows:

This request on Twitter finds the user "minregion_ua". Assuming that the place or work name of the user we are looking for (Ministry for the Development of Communities and Territories of Ukraine) and his name are known, you can ask a more specific request. And instead of tediously searching the entire institution's web page, you can make a valid query based on an email address and assume that the name of the address should contain at least the name of the requested user or institution. For example:

- site: www.minregion.gov.ua "@minregion.ua"
You can also use a less complicated method and send the request only to email addresses, as shown below, in the hope of luck and lack of professionalism of the web resource administrator.

In addition, you can try to get email addresses from a web page with the following query:

The query shown above will search for the keyword "email" on the web page of the Ministry for the Development of Communities and Territories of Ukraine. Searching email addresses is of limited use and mostly requires a little preparation and collecting information about users in advance.
Searching for indexed phone numbers through Google's "phonebook" is limited to the United States only. For example:

User information search is also possible through Google "image search" or reverse image search. This allows you to find identical or similar photos on sites indexed by Google.
Web resource information
Google has some useful operators, notably "related:" which displays a list of "similar" websites to the one you want. Similarity is based on functional links, not logical or substantive links.
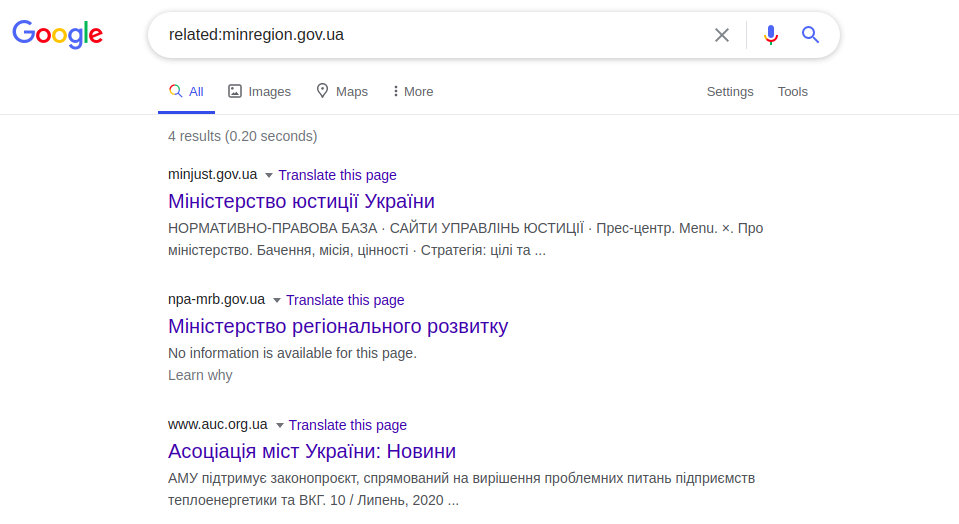
This example displays the pages of other Ministries of Ukraine. This operator works like the "Related Pages" button in advanced Google search. This is exactly how an “info:” query works, which displays information on a specific web page. This is the specific information of a web page presented in the website header (), namely in the meta description tags (<meta name = “Description”). Example:

Another query, "define:" is quite useful in finding a research paper. It allows you to get word definitions from sources such as encyclopedias and online dictionaries. An example of its application:

The universal operator - tilde ("~"), allows you to search for similar words or words synonyms:

The above query displays both websites with the words "community" (territories) and "rozvitku" (development) as well as websites with the synonym "community". The "link:" operator, which modifies the query, limits the scope of the search to links specified for a specific page.

However, this operator does not display all results and does not expand the search criteria.
Hashtags are a kind of identification numbers that allow you to group information. They are currently used on Instagram, Facebook, Tumblr and TikTok. Google allows you to search on many social networks at the same time or only recommended ones. An example of a typical query to any search engine is:

The "AROUND(n)" operator allows you to search for two words that are a certain number of words apart from each other. Example:
The result of the above query is to display websites that contain these two words ("Ministry" and "Ukraine"), but they are separated from each other by four other words.
Searching by file type is also extremely useful, as Google indexes content according to the format in which it was recorded. For this, the "filetype:" operator is used. There is currently a very wide range of file searches in use. Of all the available search engines, Google provides the most sophisticated set of operators for searching open source code.
As an alternative to the above operators, tools such as Maltego and Oryon OSINT Browser are recommended. They provide automatic data retrieval and do not require the knowledge of special operators. The mechanism of the programs is very simple: with the right request sent to Google or Bing, documents published by the institution of interest to you are found and the metadata from these documents is analyzed. A potential information resource for such programs is any file with any extension, for example: ".doc", ".pdf", ".ppt", ".odt", ".xls" or ".jpg".
In addition, it should be said about how to properly take care of "cleaning up your metadata" before making files public. Some web guides provide at least several ways to get rid of meta information. However, it is impossible to deduce the best way, because it all depends on the individual preferences of the administrator himself. The general recommendation is to write files in a format that doesn't store metadata natively, and then make the files available. There are numerous freeware metadata cleaners available on the Internet, mainly for images. ExifCleaner can be considered as one of the most desirable. In the case of text files, manual cleanup is highly recommended.
Information unknowingly left by site owners
Resources indexed by Google remain public (for example, internal documents and company materials left on the server), or they are left for ease of use by the same people (for example, music files or movie files). Searching for such content can be done with Google through many different ways and the easiest one is just guessing. If, for example, there are files 5.jpg, 8.jpg and 9.jpg in a certain directory, you can predict that there are files from 1 to 4, from 6 to 7, and even more than 9. Therefore, you can access materials that should not be were to be in public. Another way is to search for certain types of content on websites. You can search for music files, photos, movies, and books (e-books, audio books).
In another case, these may be files that the user has left unconsciously in the public domain (for example, music on an FTP server for his own use). Such information can be obtained in two ways: using the "filetype:" operator or the "inurl:" operator. For example:

You can also search for program files using a search query and filtering the searched file by its extension:
Information about the structure of web pages
In order to view the structure of a certain web page and reveal its entire structure, which will help further the server and its vulnerabilities, you can do this using only the "site:" operator. Let's analyze the following sentence:

- site: www.minregion.gov.ua minregion
We start searching for the word "minregion" in the domain "www.minregion.gov.ua". Every site from this domain (Google searches both in the text, in the headings and in the title of the site) contains this word. Thus, getting the complete structure of all sites of this particular domain. Once the directory structure is available, a more accurate result (although this may not always happen) can be obtained with the following query:
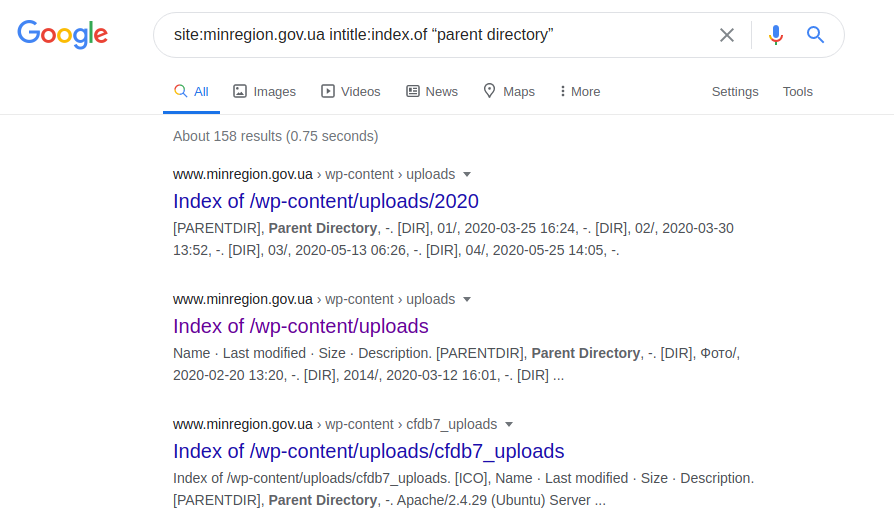
It shows the least secure "minregion.gov.ua" subdomains, sometimes searchable throughout the directory, along with possible file uploads. Therefore, of course, such a request does not apply to all domains, since they may be protected or run by some other server.


This operator allows you to access the configuration parameters of various servers. After making the request, go to the robots.txt file, look for the path to "web.config" and navigate to the specified file path. To get the server name, version, and other parameters (such as ports), the following request is made:

Each server has its own unique phrases on the header pages, for example, Internet Information Service (IIS):

The definition of the server itself and the technologies used in it depends only on the ingenuity of the given query. You can, for example, try to do this by updating the technical specification, manual or so-called help pages. To demonstrate this capability, you can use the following query:

Access can be more advanced, for example, thanks to a file with SQL errors:

Errors in a SQL database can, in particular, provide information about the structure and content of databases. In turn, the entire web page, its original and (or) its updated versions can be accessed by the following request:

Currently, the use of the above operators rarely gives the expected results, since they can be blocked in advance by knowledgeable users.
Also, using the FOCA program, you can find the same content as when searching for the above-mentioned operators. To get started, the program needs the name of a domain name, after which it will analyze the structure of the entire domain and all other subdomains connected to the servers of a particular institution. Such information can be found in the dialog box on the "Network" tab:

Thus, a potential attacker can intercept data left by web administrators, internal documents and company materials left even on a hidden server.
If you want to know even more information about all possible indexing operators, you can check out the target database of all Google Dorking operators here . You can also get acquainted with one interesting project on GitHub, which has collected all the most common and vulnerable URL links and try to look for something interesting for yourself, you can see it here at this link .
Combining and getting results
For more specific examples, below is a small compilation of commonly used Google operators. In a combination of various additional information and the same commands, the search results show a more detailed look at the process of obtaining confidential information. After all, for a regular Google search engine, such a process of collecting information can be quite interesting.
Search for budgets on the US Department of Homeland Security and Cybersecurity website.
The following combination exposes all public indexed Excel spreadsheets containing the word "budget":

Since the "filetype:" operator does not automatically recognize different versions of the same file format (e.g. doc vs. odt or xlsx vs. csv), each of these formats must be split separately:

The following dork will return the PDF files on the NASA website:

Another interesting example of using dork with the keyword “budget” is searching for US cybersecurity documents in “pdf” format on the official website of the Department of Homeland Defense.

Same application of dork, but this time the search engine will return .xlsx spreadsheets containing the word "budget" on the US Department of Homeland Security website:

Password search
Searching for information by login and password can be useful as a search for vulnerabilities on a resource. Passwords can be stored in shared documents on web servers. You can try to apply the following combinations in various search engines:

If you try to enter such a query in another search engine, you can get completely different results. For example, if you run this query without the term "site: [site name] ", Google will return document results containing the real usernames and passwords of some American high schools. Other search engines do not show this information on the first pages of results. As you can see below, Yahoo and DuckDuckGo are examples.


House prices in London
Another interesting example concerns information about the price of housing in London. Below are the results of a query that was entered in four different search engines:
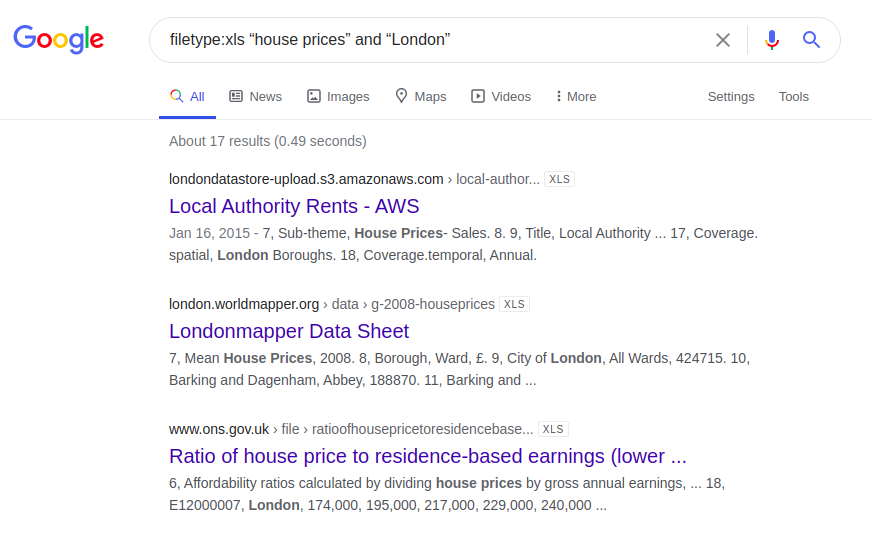
You may now have your own ideas and ideas about which websites you would like to focus on in your own search for information.
Alternative Search Indexing Tools
There are also other methods of collecting information using Google Dorking. All of them are an alternative and act as an automation of search processes. Below we offer a look at some of the most popular projects that are not a sin to share.
Google Hacking Online
Google Hacking Online is an online integration of Google Dorking search of various data through a web page using established operators, which you can find here . The tool is a simple input field to search for the desired IP address or URL of a link to a resource of interest, along with the suggested search options.

As you can see from the picture above, a search by several parameters is provided in the form of several options:
- Finding Public and Vulnerable Directories
- Configuration files
- Database files
- Logs
- Old data and backup data
- Authentication Pages
- SQL errors
- Shared documents
- php configuration information on the server ("phpinfo")
- Common Gateway Interface (CGI) Files
Everything works on vanilla JS, which is written in the web page file itself. At the beginning, the entered user information is taken, namely the host name or IP address of the web page. And then a request is made with the operators for the entered information. A link to search for a specific resource opens in a new pop-up window, with the results provided.
BinGoo
BinGoo is a versatile tool written in pure bash. It uses Google and Bing search operators to filter a large number of links based on the given search terms. You can choose to search one operator at a time, or list one operator per line and perform a bulk scan. Once the initial information gathering process is over, or you have links collected in other ways, you can move on to analysis tools to check for common signs of vulnerabilities.
The results are neatly sorted into their respective files based on the results obtained. But the analysis doesn't stop here either, you can go even further and run them with additional SQL or LFI functionality, or you can use the SQLMAP and FIMAP wrapper tools, which work much better, with accurate results.
Also included are a few handy features to make life easier, such as "geodorking" based on domain type, domain country codes, and a shared hosting check that uses pre-configured Bing search and a list of dorks to look for possible vulnerabilities on other sites. Also included is a simple search for admin pages based on the provided list and server response codes for confirmation. In general, this is a very interesting and compact package of tools that performs the main collection and analysis of the given information! You can get acquainted with him here .
pagodo
The purpose of the Pagodo tool is to passively index Google Dorking operators to collect potentially vulnerable web pages and applications over the Internet. The program consists of two parts. The first is ghdb_scraper.py, which queries and collects Google Dorks statements, and the second is pagodo.py, which uses statements and information collected through ghdb_scraper.py and parses it through Google queries.
To start, the pagodo.py file needs a list of Google Dorks operators. Such a file is either provided in the project's own repository, or you can simply query the entire database with a single GET request using ghdb_scraper.py. And then just copy the individual dorks statements into a text file or put into json if additional contextual data is required.
In order to perform this operation, you need to enter the following command:
python3 ghdb_scraper.py -j -s
Now that we have a file with all the necessary statements, we can redirect it to pagodo.py with the "-g" option to start collecting potentially vulnerable and public applications. The pagodo.py file uses the "google" library to search for such sites using statements like this:
Unfortunately, the process of such a huge number of requests (namely ~ 4600) through Google, simply will not work. Google will immediately identify you as a bot and block your IP address for a certain period. To make search queries look more organic, several improvements have been added.
For the Python module, "google" made special adjustments to ensure user agent randomization across Google search queries. This feature is available in module version 1.9.3 and allows you to randomize the different user agents used for each search query. This feature allows you to emulate various browsers used in a large corporate environment.
The second improvement focuses on the randomization of time between search queries. The minimum delay is specified using the "-e" parameter, and the jitter factor is used to add time to the minimum number of delays. A list of 50 jitters is generated and one of them is randomly added to the minimum latency for each Google search process.
self.jitter = numpy.random.uniform(low=self.delay, high=jitter * self.delay, size=(50,))
Next, in the script, a random time is selected from the jitter array and added to the delay in creating requests:
pause_time = self.delay + random.choice(self.jitter)
You can experiment with the values yourself, but the default settings work just fine. Please note that the tool may take several days to complete (average 3; depending on the number of operators set and the query interval), so make sure you have time for this.
To run the tool itself, the following command is enough, where "example.com" is a link to the website of interest, and "dorks.txt" is the text file that ghdb_scraper.py created:
python3 pagodo.py -d example.com -g dorks.txt -l 50 -s -e 35.0 -j 1.1
And you can feel and familiarize yourself with the instrument itself by clicking on this link .
AND IF YOU LIKED THIS CONTENT , AND WANT MORE LIKE THIS JOIN OUR OFFICIAL CHANNEL LIKE FREE FOR NOW. Hackfreaks.
Conclusion
Google Dorking is an integral part of the confidential information collection and analysis process. It can rightfully be considered one of the most root and main OSINT tools .
Google Dorking operators help both in testing their own server and in finding all possible information about a potential victim . This is indeed a very striking example of the correct use of search engines for the purpose of reconnaissance of specific information.
Alternative methods and automation tools provide even more opportunities and convenience for analyzing web resources. Some of them, like BinGoo, extend the usual indexed search on Bing and analyze all the information received through additional tools (SqlMap, Fimap). They, in turn, present more accurate and specific information about the security of the selected web resource.