Сергей Протько «Солидный код»

Расшифровку подготовил канал Hash. Пишем про разработку и всякое.
Гитхаб Сергея Протько ака Фесора: https://github.com/fesor
Сергей: о себе я много расcказывать не буду. Скажу просто что пхпшник, работаю в аутсорсе. У нас очень много различных проектов, всякого пришлось повидать. Мой текущий проект — это e-commerce платформа, на которой люди могут зарегистрироваться, начать продавать или покупать какие-то товары.
В этом случае важно, чтобы никто, например, не смог продавать наркотики. Таких продавцов нужно сразу блокировать и удалять все продукты из каталога. Как мы это сделали?

У нас есть мерчанты — это модуль продавцов. И есть модуль каталога — продукты. Мы добавили флаг, например, isBanned у продавца и сделали inner join на продукты. Все, вроде бы, хорошо. Но тут мы вспоминаем, что у нас есть список категорий.

Он должен отображать только те категории, в которых есть продукты. Делаем там тоже join на продукты и на мерчантов. Стрелочки показывают зависимости, и мы видим, что уже все плохо.
Еще присоединяются фейвориты. По нашим бизнес правилам, в них нельзя удалять продукты просто так. Нужно показывать их со статусом "недоступны для продажи" и отображать их внизу списка.

Делаем еще join, делаем сортировки и, вроде, все красиво. Что у нас здесь не так? Судя по количеству стрелочек у нас начинается легкий ад. Как он будет выражается? Например, если к нам придут новые требования. Допустим, мерчант может продавать максимум на 1000 $ в месяц и, если он хочет продавать больше, то ему надо заплатить денюжку. Для бизнеса это очень простая задача. Чтобы ее заприметить, нам нужно пробежаться по всем этим стрелочкам, добавить условия, усложнить выборки и добавить пару реплик для баз данных.
С тестами тоже интересно — они начинают фейлиться от любого чиха. Покрыть такую логику мы можем только интеграционными тестами.
Прим. ред. Почитать про различные виды тестирования и подходы, можно в замечательной статье на хабре: https://habr.com/ru/post/358950/

Тесты эти работать будут медленно, запускать мы их будем редко и, постепенно, когда при добавлении очередного функционала у нас снова фейляться тесты, мы начинаем думать как-то так: "Да к черту эти тесты! Я трачу безумное время на поддержку, а пользу они не приносят. Зачем их писать?" Как сделать так, чтобы наш код не разрастался такими вот стрелочками? Чтобы все было связанно со всем? И, грубо говоря, чтобы жить стало проще и бизнесу было дешевле просить у нас какие-то новые хотелки?

Ответом на этот вопрос являются принципы SOLID. Принципы эти придуманы были достаточно давно. Cобрал их воедино Роберт Мартин или дядя Боб в 1996 году. Тогда они еще назывались принципы объекто-ориентированного дизайна. Их было 10 штук. В принципе, они были логичными. Потом кто-то ему подсказал, что по некоторым принципам можно собрать SOLID. Так и повелось. Лучше продается, чем design principles of OOP.
Тут сразу хочу остановится на паре моментов. Мы будем говорить про SOLID в контексте модулей. Модули именно как функция элементов декомпозиции системы. Эти принципы прекрасно ложатся на любой уровень декомпозиции: отдельные классы, на которых обычно все эти принципы рассматривают, отдельно методы, отдельные компоненты подсистемы и т.п.

О чем вообще SOLID? Он про управление зависимостями. Как мы видели на диаграмках, у нас проблема с тем, что у нас много изменений из-за того, что поменялись наши зависимости. Все принципы, которые приводит дядя Боб, он почерпнул из проблем в проектах, которые были у него еще в 70-х. В некоторых докладах он рассказывает о своих проектах и какие у него были проблемы, как он накосячил и почему он больше так не будет.
Когда мы говорим про зависимости, почему они меняются, можно попытаться сначала подойти к вопросу: "А как сделать, чтобы они никогда не менялись?"

Именно об этом один из самых основных принципов. Это принцип открытости/закрытости. Он гласит очень простую вещь — модуль должен быть открыт для расширения функциональности, но закрыт для изменения кода. Если говорить очень абстрагировано — вы можете добавить любую фичу в вашу систему только добавляя новый код. Ни строчки другого кода при этом менять не нужно. Звучит как идеал. В принципе, так оно и есть.
Есть некоторые люди, которые говорят, что это было возможно, что они даже достигли принципа открытости/закрытости на своей системе, но как правило это загоны, которых можно избежать. Но стремиться к этому принципу конечно надо.

Почему наш код меняется? Почему мы его меняем? В языках программирования обычно на эту тему есть какие-то конкретные виновники. Самый популярный случай — это switch case и любые варианты логик ветвления и магических констант, которые разбросаны по коду, и оператор new.
Проблема не в самом операторе, проблема в том, что мы хардкодим кого мы инстанцируем. Если мы захотим в нашу функцию, которая, например, проводит оплату товара, добавить новый метод оплаты, то нам придется добавить еще одну ветку switch. Или, если мы захотим переименовать какой-нибудь метод, надо будет снова поправить этот кусочек кода. Если же нам понадобится для оплаты наличкой поменять instant invoice (неоплаченный invoice с кэшем), нам придется влезть сюда и поправить название класса. Как можно это все исправить?

Одним из основных механизмов для достижения open/close считается механизм инверсии зависимостей. Он гласит, что мы должны зависеть от абстракции и не зависеть от конкретных вещей.

Как это выражается? В нашем примере был какой-то модуль платежей, которому нужны методы платежек. На этой диаграмме у нас есть только один метод платежа, допустим кэшем, теперь мы хотим добавить карточки. Что мы можем в этом случае сделать? Мы можем из нашего модуля, который выражает конкретный платеж, взять абстракцию и просто "payment methood".

Таким образом, мы получим инвертированное направление зависимостей. Теперь конкретный метод payment реализует абстрактный метод payment. Поэтому стрелочка меняет свое направление.

С другой стороны, модуль теперь понятия не имеет как работает этот payment.
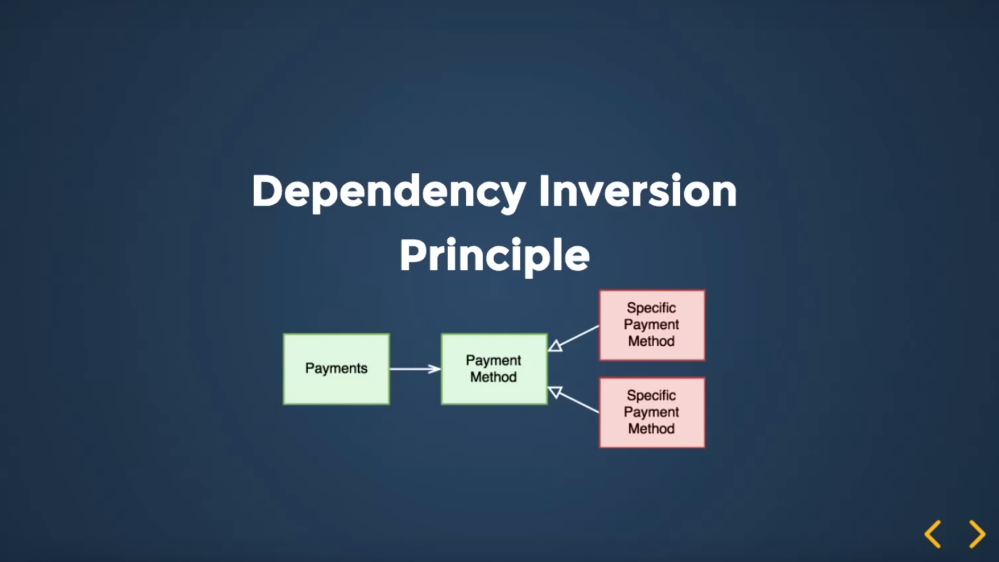
Соответственно, у нас появляется возможность подменять реализации и, если у нас реализация работает некорректно, мы можем заменить ее на другую.

Выражается это примерно так — у нас есть вот такая абстракция, какой-то интерфейс, который выражает какой-то payment метод. Какие проблемы он решает? Во-первых, он решает вопросы со switch. Потому что у нас switch заменяется на простой пробег по всем вариантам. Приходится спрашивать у каждого: "Ты то можешь? — Нет. — Ты можешь? — Да. Окей, значит ты это будешь делать".
Есть механизм оплаты. Мы абстрагируемся от того, как происходит оплата, как мы получаем invoice и какой invoice. Мы избавляемся от оператора new и от всех захардкодженных констант. Только за счет этого просто шага.

Остальные паттерны тоже из банды четырех, они тоже нам помогают достичь open/close. Их можно воспринимать как маленькие рецептики.
Прим. ред. Вот вам отличный сайт с паттернами и примерами их реализации: https://refactoring.guru/ru/design-patterns

Допустим, на этом слайде я выложу invoice. Но он может быть для каких-то методов оплачен, а для каких-то — нет. К какому переходить дальше? Мы не очень хотим хардкодить, потому что это будет потом вызывать боль с изменениями.
Поэтому мы можем воспользоваться паттерном state, который будет декларировать следующий step — надо переходить к оплате или просто к success страничке. Главное понимать проблему, потому что очень часто разработчики просто берут паттерны и бездумно их пихают.

Иногда разработчики, когда думают об open/close, видят фразу "открыт для расширения" и пытаются решить вопрос расширения функциональности за счет наследования.
Допустим, у нас есть в системе какая-то функциональность, связанная абстрактно с юзером. Например, это логин на восстановление доступа к аккаунту. Есть какой-то функционал, специфичный для кастомеров. Кастомеры могут, например, покупать, а мерчанты - продавать или декларировать юридический адрес.

Поведение различается, поэтому общую часть мы выносим в юзера и смело наследуемся от всех. Что плохого в этой схеме? Во-первых, когда мы видим вызов parent конструктора, это свидетельствует о проблеме — если у нашего базового класса поменяются зависимости, нам придется прокидывать их во всех наследников. Это не очень удобно и иногда вызывает огромный каскад изменений.
Во-вторых, вызов конструктора — это неявное инстанцирование базового класса. По сути мы хардкодим кого мы инстанцируем. Это тоже может повлиять на то, что нам придется залезть в класс и что-то подправить.

Интересный момент: мы можем избавиться от этих проблем просто прокинув айдишку готового юзера и при этом все будет хорошо. В принципе, в нашей системе там где нужен функционал юзера — нужен именно юзер. А там где нужен кастомер — нужен именно кастомер.
Я в своей практике не встречал, чтобы возникала ситуация, при которой одновременно нужен был и функционал юзера, и функционал кастомера, поэтому нет смысла городить подтипы. Если вы мне не верите, давайте попробуем кейс: "Что будет если мы будем просто так плодить подтипы?"

Мы можем сломать принцип подстановки Барбары Лисков. Это один из самых сложных принципов SOLID в плане восприятия и требует много бэкграунда знаний. Например, что такое контракты, что такое контрактное программирование, предусловия, постусловия, инварианты. Я об этом сейчас говорить не буду, это все можно почитать. Почему этот принцип важен?

Допустим, у нас были деньги в системе. Обычный класс денег. Он умел математические операции, например, добавить деньги, умножить деньги. Пока все хорошо. Однажды к нам приходит требование, что деньги надо обменивать между собой, причем у нас есть несколько типов денег по поведению: криптовалюты, обычные деньги и т.п. — у всех есть свои особенности в плане правил обмена.

Поэтому мы добавили абстрактный метод exchange и реализуем во всех наследниках. После к нам снова приходят и говорят добавить бонусы. Бонусы — это вид денег, который нельзя обменять обратно на деньги, но покупать за них продуты можно. То есть действовать как деньги они могут, но участвовать в обмене они не могут. Чтобы реализовать это правило, мы решаем кидать там исключение.
Что будет, если в метод, который проводит exchange, попадают бонусы, и мы не делаем никаких проверок на типы и трайкетчик? Код просто ломается, ломается рантайм и пользователи расстраиваются. Причем, может быть это звучит не очень реалистично, но не уследить за зависимостями вполне легко и это очень часто случается.

Вот такие записи в коде — симптом проблемы. Если у вас есть в коде instanceof, значит, имеет смысл это исправить. Но это не обязательно говорит о том, то у вас нарушились liskov substitution. На моем опыте, в 80% — это нарушение. В 20% — так и надо было.
Проблема здесь в том, что мы заставляем наш клиентский код, который использует нашу зависимость, думать: "Ага, нам пришли бонусы. Мы обрабатываем их отдельно, а все остальное пойдет отдельно". Если у нас будет множится количество подтипов, которые ведут себя немного по-разному, нам придется добавлять больше проверок и больше задумываться над тем, все ли мы учли.

Решить эту проблему может принцип сегрегации интерфейсов. Он регламентирует, что много маленьких специализированных интерфейсов намного лучше, чем интерфейс общего назначения.
Приведу в пример аналогию. К вам приходит человек, которого вы попросили об услуге, и он говорит: "Я могу еще вот это, вот это и вот это". Он ходит по всему вашему дому (проекту) и кто-нибудь из ваших соседей соглашается на другие его услуги. Через какое-то время вы решаете заменить этого человека на другого. Но в отличии от предыдущего, наш новый рабочий умеет решат только нашу проблему. Нам хорошо, а соседи сломались, ведь вы даже не знали о том, что кто-то пользуется его другими услугами. В целом система становится намного более хрупкой и чувствительной к изменениям.

Если у нас есть функция, которой нужен exchanges валют, мы можем проверять, поддерживает ли этот интерфейс тот объект, который к нам пришел. Таким образом, мы избавляем класс Money от ненужного ему метода. Там все еще остаются математически все операции, но уже не все деньги можно менять. Теперь это очень четко и явно выражено в коде, что немаловажно, потому что решает много проблем при внедрении новых разработчиков.

Если снова говорить про стрелочки направления зависимостей, можно вывести интересную мысль — наш код будет меньше меняться, если наши зависимости не меняются. То есть, мы будем менять требования нашего кода, а не подстраиваться под зависимости. Отсюда следует принцип стабильных зависимостей. Он регламентирует, что направление связи должно быть строго по направлению стабильности.

Стабильность — это очень интересная вещь, потому что она выражается в том, как часто у нас что-то меняется.
Здесь я сделаю ремарку, чтобы люди не путали. Когда люди говорят о изменениях в проекте, в системе, они часто путают багфикс с изменениями. Что рефакторинг — это изменение. Но мы говорим только об изменении поведения, поэтому багфиксы — это исправления поведения. Нет ничего страшного, чтобы немного поменять код. Это не будет нарушением open/close.
Но, если нам нужно часто рефакторить, потому что нам потребовалось увеличить производительность, это не считается изменением в поведении. Оно будет быстрее работать, но поведение от этого не изменится.

Если мы снова посмотрим на наш пример с каталогом продуктов и путаницу со стрелочками, сможем разметить примерную частоту изменений.
Существует модуль категорий (списки категорий). С точки зрения бизнес-логики, он стабильный. Есть продукт, который мы уже разобрали. Иногда в нем происходят изменения, но нечасто. Есть модуль с продавцами, где у нас постоянно идут изменения в плане управления продавцами. Здесь происходят изменения с точки зрения владельцев нашего сервиса. И есть фэйвориты, где мы не можем определиться с тем, как формировать списки, поэтому часто что-то меняем.
Если учитывать такое разделение, то стрелочки неправильно выставлены. У нас стабильные категории зависят от продуктов, на них же делают inner join и надо это как-то исправить.
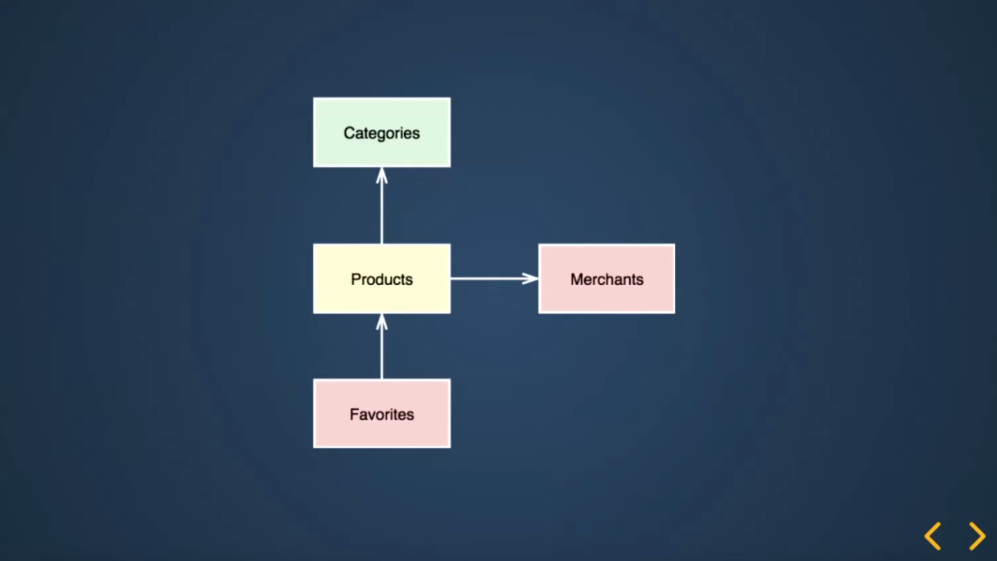
На данный момент, мы хотим получить такую картинку. Как этого можно добиться?
Вместо inner join можно выставить флаг на самом продукте. Для этого мерчанта модуль может кидать event, когда происходит событие, при котором надо все продукты в каталоге скрывать, например, мерчант забанен.
Таким образом, мы можем полностью вынести логику триггера операции в модуль мерчантов, а продукт — в простой интерфейс. В этом случае продукты могут узнать, какие продукты я спрятал, какие категории надо просмотреть.
Если модуль продуктов знает что у меня где, я могу сказать модулю категорий, какие категории пустые, а какие — нет. Таким образом, у нас все заменяется просто на флаги, логика вся выносится в какие-то триггеры, которые мы можем спокойно покрыть юнит-тестами. Они достаточно стабильны и не будут меняться без надобности. Не нужно будет тратить безумное количество времени на поддержку. Запросы упростятся, система станет изолированной, но у нас все еще есть связь между продуктами и мерчантами направлена не в ту сторону.

Что мы можем здесь сделать? Дробить систему дальше.
Предположим, у нас есть модуль мерчантов, из который нам нужно выделить самую стабильную часть. Стабильной частью здесь будут сами мерчанты. Именно то, что нужно пользователю: его профиль, его какие-то детали по кастомерам, взаимодействию с ними. Часть, которая нужна менеджменту, мы вынесем отдельно.

Получится как-то так. Но принцип единой ответственности говорит о том, что мы можем дробить систему так, чтобы у каждого элемента было единое предназначение (единая причина для изменений). Мораль тут проста — если у тебя есть штука и она выполняет одну роль, скорее всего поведение этой шутки не будет меняться. Тебе будет проще ввести еще одну сущность в систему, которая выполняет какое-то новое поведение, чем менять предыдущие. Таким образом мы не рискуем сломать проект.

Ведется много споров вокруг этого принципа. Что считать изменением и как считать цепочку, которая приводит к изменениям, ведь в зависимости от контекста один и тот же код может соблюдаться SRP, а может не соблюдать.
Расскажу интересный пример, который недавно обсуждали на Reddit. Пользователь пожаловался, что симфонии yaml не соблюдает SOLID, потому что огромный кусок кода, который никак не поделен.
С одной стороны, причина для изменения у этого модуля одна — поменялась спецификация yaml. С другой стороны — какой-то другой код с таким же набором, и где спецификация более гибкая, может меняться по частям, стоит дробить.
Также и здесь. Если мы говорим про репорт, там нашим бухгалтерам для нашей системы надо составить 3 репорта по продаже. Чтобы они могли выставлять invoice своим пользователям и т.п.
Тут у нас есть две части. Первая — табличка, UI или репрезентация данных. Второе — бизнес правила, по которым эти данные формируются. И у нас есть DBA или разработчики, которые хотят чуть-чуть оптимизировать базу, поменять SQL-запросы и т.д.
Причиной для изменений в конце цепочки все равно стоят люди. Но, допустим, у нас бухгалтер хочет добавить новую колонку. Это вызовет изменение на уровне бизнес требований, потому что у нас добавятся другие требования, чтобы получить данные для этой колонки. Поэтому у нас поменяются два объекта. А возможно еще и слой базы данных придется расширить и изменения будут сквозными. С другой стороны, чаще всего просят колонки поменять местами, поменять лейблы. В этом плане поменяется только один квадратик. Суть в том, что вещи, которые меняются чаще, должны быть максимально изолированные от более стабильных вещей.

Эти принципы очень хорошо работают в ретроспективе. Но мы не знаем будущего, что часто приводит к проблемам.
Пример. У нас пришел новый проект, и мы начинаем его проектировать, решая делать все по SOLID. Но мы не можем предсказать, как будет развиваться функционал нашего проекта. Мы можем начать придумывать, оценивать вероятность. Чем это чревато? В поисках нужных точек расширения, мы можем выстроить целую гору плохо обобщенных абстракций, которые не будут проносить никакой пользы и лишь усложнят систему. Преждевременные обобщения это один из основных источников связанности. И хуже всего то, что все ��авно придет продукт оунер и попросит сделать фичу которая никак не ложится на вашу систему. И ты думаешь про себя: "Ну вот, мне придется все переделывать".
Как с этим жить? Как писать по SOLID не зная будущего? Самый простой способ — дождаться каких-то изменений и применить их, а после сделать рефакторинг.

Рефакторинг — штука очень клевая, но многие думают, что это месяц пилить проект, а потом все с нуля. Это не так работает.
Планировать рефакторинг можно, просто чем реже это делаешь тем менее вероятно что планам будет суждено сбыться. Новые фичи будут требовать больше кастылей. Если чистить чаще то и времени на это уходить будет существенно меньше.
Если мы будем оглядываться назад каждый пару часов и смотреть, не нарушили ли мы каких-нибудь принципов, не стал ли наш код более неподдерживаемым, и будем сразу исправлять, то на это не уйдет много времени. То, что у нас уже идет что-то не так, видно в течение часа разработки. Мы можем потихоньку видоизменять систему, чтобы она соответствовала и нашим новым хотелкам, и нашим требованиям к архитектуре.
В тестах все также. Как только система будет разделена таким образом, что зависимости выставлены правильно (и мы за этим следим при помощи рефакторинга), наши тесты перестанут так часто меняться. Фраза "Юнит-тесты — это дорого" перестанет быть актуальной, потому что они не часто меняются, не нужно тратить время на их поддержку.
Более того, если у вас есть проекты и у вас все покрыто юнит-тестами, постоянно приходится править юнит-тесты, это симптом проблемы с принципом open/close. К сожалению, не многие из нас могут похвастаться возможностью стартануть проект с нуля. Что делать людям, которые уже сидят на легаси?

Кстати, вот это дядя Боб. Он обычно говорит о правиле бойскаута — оставь мир, в который ты пришел, чуть чище, чем он был до тебя.
Когда мы рефакторим свои маленькие изменения, мы можем начать делать новые фичи, постепенно видоизменяя старый код, который задеваем, оставляя его чуть чище. Возможно у вас есть свободных 15 минут. Вы можете покрыть тестами вот это страшное место, потому что вы просто проходили недалеко и знаете как оно работает.
Маленькими шажками, спустя время ваш проект уже не будет таким страшным. За последние полгода мы превратили проект, о котором я уже говорил, во что-то ужасное, но теперь приводим в порядок именно таким способом.

Если вам тяжело с точки зрения SOLID смотреть на вещи, почитайте принципы GRASP. Эти принципы были сформулированы Крейгом Ларманом в книге «Применение UML и шаблонов проектирования».
В некоторых местах они сформулированы более конкретно. Их легко трекать при помощи метрик кода, но так же легко упустить суть и делать дела только ради метрик.
На этом все.

Расшифровку подготовил канал Hash. Пишем про разработку и всякое.
Обязательно посмотрите другие доклады с fwdays, мы будем делать новые расшифровки, но не быстро.
Кстати, Сергей Протько, обитает в двух чатах в телеграмме:
https://t.me/symfony_php
Конференция PHP fwdays'17 прошла 11 июня 2017 года в Киеве, Украина: https://fwdays.com/en/event/php-fwdays-17
Презентация доклада: https://fwdays.com/en/event/php-fwday...
Facebook: https://www.facebook.com/fwdays/
Twitter: https://twitter.com/fwdays