Flat map в Python 🐍

Некоторое время назад мы касались вопросов функционального программирования на Swift в контексте монад и функторов (flatMap там тоже был). Теперь давайте рассмотрим концепцию flat_map в языке Python.
Ну, здесь нет built-in функции flat_map. Но её можно имплементировать самостоятельно, причём несколькими разными способами. Поэтому, вместо того чтобы дискутировать на тему на создания «pure pythonic» функции flat_map, давайте лучше рассмотрим более интересный вопрос:
Как создать функцию flat_map в python наиболее эффективным способом?Определение
Начнём с определения. flat_map это операция, которая принимает список элементов типа A и функцию f типа A -> [B]. Функция f таким образом применяется ко всем элементам первоначального списка, и затем все результаты конкатенируются. Простой пример:

Хотя данная операция довольно простая, идея, лежащая в её основе называется «монада». Насколько я знаю, есть 4 простых способа создать flat_map в Python:
- цикл for и extend
- двойной list comprehension
- map и reduce
- map и sum
Измерение
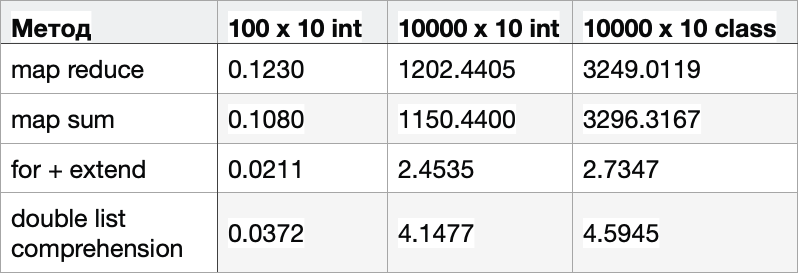
Какой подход будет наиболее эффективным? Чтобы ответить на этот вопрос, я собираюсь проверить время исполнения программы в 3 различных случаях:
a) 100 списков, каждый содержит 10 чисел типа int
b) 10 000 списков, каждый содержит 10 чисел типа int
c) 10 000 списков, каждый содержит 10 объектов (инстансов класса)
Чтобы сделать это, я буду использовать функцию check_time и дополнительную простую функцию id для её передачи в flat_map:
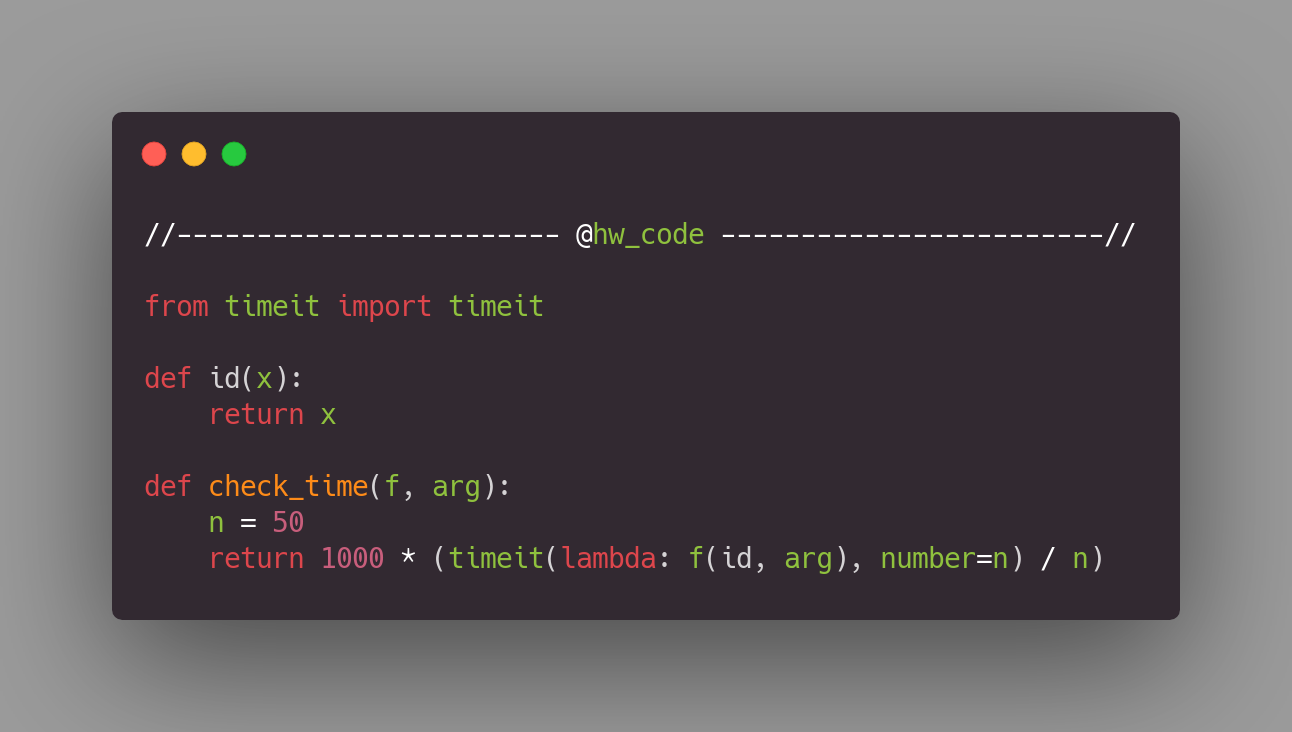
Весь используемый код можно найти по ссылке.
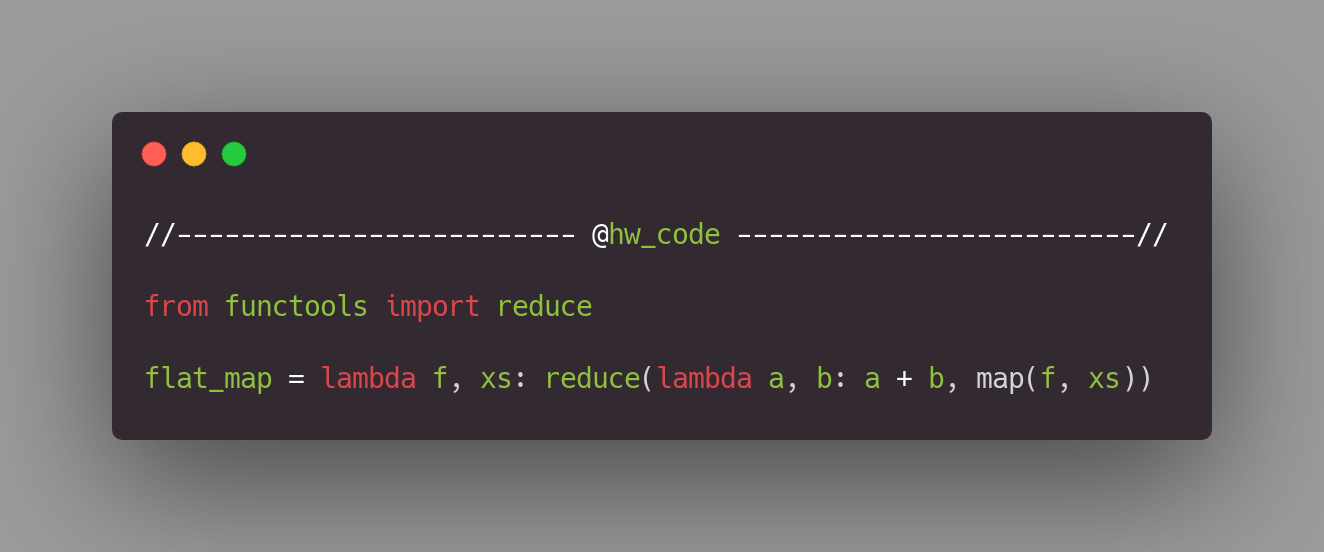
Map reduce
Наиболее «функциональный» ответ на поставленную задачу – это комбинация map и reduce. Потребуется импорт библиотеки functools (документация), так что даже при всей его крутизне, это всё таки не решение в одну строчку.
Результат:
a) 0.1230 мс
b) 1202.4405 мс
c) 3249.0119 мс
Тут map можно легко заменить на list comprehension, но особой разницы заметно не будет.
Map sum
Другое «функциональное» решение – это использовать sum. Мне нравится этот подход, но его производительность также оставляет желать лучшего. Результаты в принципе не лучше, чем в предыдущем случае.

Результат:
a) 0.1080 мс
b) 1150.4400 мс
c) 3296.3167 мс
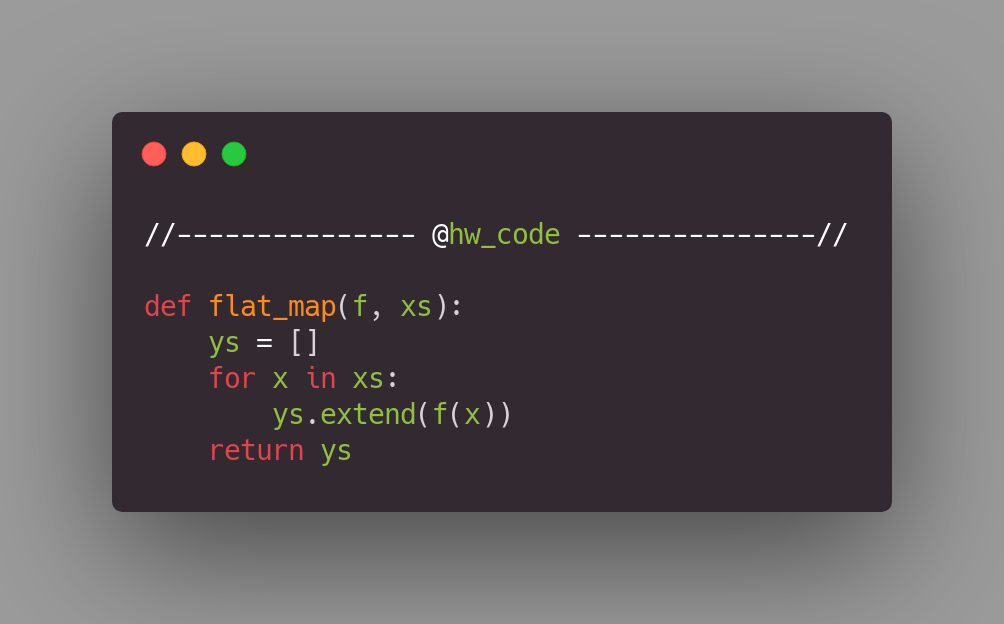
For extend
До сих пор наши имплементации функции flat_map работали относительно быстро для малого размера списка, и были медленными для большого. Однако данная «классическая» имплементация в 1000 раз быстрее! Жаль конечно что это не решение в одну строчку. Но, наверное, это относительно небольшая цена за такую производительность.
Результат:
a) 0.0211 мс
b) 2.4535 мс
c) 2.7347 мс
Интересно то, что разница между скоростью работы flat_map в случае со списком интов и списком классов теперь не такая уж и большая.
List comprehension
Настоящий «pythonic» подход (и в принципе тоже функциональный). Единственный минус данной реализации, это слегка запутанный двойной for цикл.
Результат:
a) 0.0372 мс
b) 4.1477 мс
c) 4.5945 мс
Как мы видим, производительность действительно потрясающая. Немного медленнее, чем в предыдущем варианте, но теперь то это настоящее решение в одну строчку.
Давайте посмотрим что будет если мы заменим list comprehension на generator expression в последнем примере:

Результат:
a) 0.0008 мс
b) 0.0008 мс
c) 0.0007 мс
Так вот он наш победитель? А стоп, мы не развернули само выражение. Давайте развернем, чтобы проверить его реальную производительность. Кроме того, развернем и list comprehension, для того, чтобы посмотреть как ведёт себя код в идентичных условиях:
list comprehension:
a) 0.0537 мс
b) 5.3700 мс
c) 5.7781 мс
generator expression:
a) 0.1512 мс
b) 13.0335 мс
c) 13.3203 мс
Таким образом, мы видим, что первоначальное ускорение было ошибкой: код не был выполнен, поэтому замер времени был некорректен. Всегда помните о том, что реальная производительность (в контексте какой-либо конкретной задачи) может быть гораздо ниже.
Заключение
Простая проблема, много решений, но только один победитель... ну или два. Я считаю разумным отдать первое место как for+extend, так и list comprehension. Первый вариант хорош тогда, когда ваша главная забота – производительность. Второй вариант – это действительно хороший выбор, когда вам нужно удобное решение в одну строчку.
Поэтому в следующий раз, когда вам нужно будет применить flat_map в Python, просто используйте list comprehension. И самое главное, не поддавайтесь соблазну использовать reduce или sum для длинных списков!
Статья подготовлена для канала Hello World.