Обход гугл капчи

В данной статье я хочу рассказать о своем опыте автоматизированного решения капчи компании «Google» — «reCAPTCHA». Хотелось бы заранее предупредить читателя о том, что на момент написания статьи прототип работает не так эффективно, как может показаться из заголовка, однако, результат демонстрирует, что реализуемый подход способен решать поставленную задачу. Наверное, каждый в своей жизни сталкивался с капчей: ввести текст из картинки, решить несложное выражение или сложное уравнение, выбрать автомобили, пожарные гидранты, пешеходные переходы… Защита ресурсов от автоматизированных систем необходима и играет немалую роль в безопасности: капча защищает от DDoS-атак, автоматических регистраций и постингов, парсинга, предотвращает от спама и подбора паролей к учетным записям.
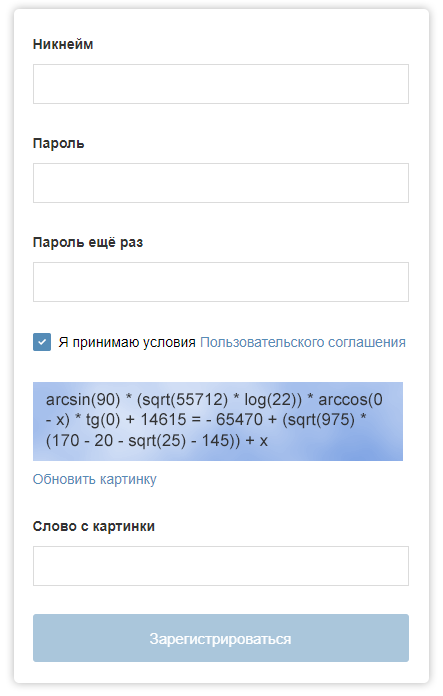
Форма регистрации на «Хабре» могла бы быть и с такой капчей. С развитием технологий машинного обучения эффективность работы капчи может оказаться под угрозой. В данной статье я описываю ключевые моменты работы программы, которая может решить проблему ручного выбора изображений в «Google reCAPTCHA» (к радости, пока не всегда). Чтобы пройти капчу, необходимо решить такие задачи как: определение требуемого капчей класса, обнаружение и классификация объектов, обнаружение ячеек капчи, имитация деятельности человека в решении капчи (движение курсором, клик). Для поиска объектов на изображении используются обученные нейронные сети, которые можно загрузить на компьютер и распознавать объекты на изображениях или видео. Но для решения капчи недостаточно одного лишь обнаружения объектов: необходимо определить положение ячеек и узнать, какие именно ячейки требуется выбрать (или не выбирать ячейки вообще). Для этого используются средства компьютерного зрения: в данной работе это известная библиотека «OpenCV». Для того, чтобы найти объекты на изображении, во-первых, требуется само изображение. Я получаю скриншот части экрана при помощи модуля «PyAutoGUI» с достаточными для обнаружения объектов размерами. В оставшейся части экрана я вывожу окна для отладки и мониторинга процессов программы.
Обнаружение объектов
Обнаружение и классификация объектов — это то, чем занимается нейросеть. Библиотека, которая позволяет нам работать с нейронными сетями называется «Tensorflow» (разработана компанией «Google»). Сегодня к Вашему выбору есть множество различных обученных моделей на разных данных, а значит, что все они могут возвращать различный результат обнаружения: какие-то модели будут лучше обнаруживать объекты, а какие-то хуже.
В данной работе я использую модель «ssd_mobilenet_v1_coco». Выбранная модель обучена на наборе данных «COCO», в котором выделены 90 различных классов (от людей и автомобилей до зубной щетки и расчески). Сейчас есть и другие модели, которые обучены на тех же данных, но с другими параметрами. Кроме того, данная модель имеет оптимальные параметры производительности и точности, что немаловажно для настольного компьютера. В источнике сообщается, что время обработки одного кадра размером 300 x 300 пикселей составляет 30 миллисекунд. На «Nvidia GeForce GTX TITAN X».
Результатом работы нейросети является набор массивов:
- с перечнем классов обнаруженных объектов (их идентификаторами);
- со списком оценок обнаруженных объектов (в процентах);
- со списком координат обнаруженных объектов («боксов»).
Индексы элементов в данных массивах соответствуют друг другу, то есть: третий элемент в массиве классов объектов соответствует третьему элементу в массиве «боксов» обнаруженных объектов и третьему элементу в массиве оценок объектов.

Выбранная модель позволяет обнаруживать объекты из 90 классов в реальном времени.
Обнаружение ячеек
«OpenCV» предоставляет нам возможность оперирования сущностями, которые называются «контуры»: Их можно обнаружить одной лишь функцией «findContours()» из библиотеки «OpenCV». На вход такой функции необходимо подать бинарное изображение, которое можно получить функцией порогового преобразования:
_retval, binImage = cv2.threshold(image,254,255,cv2.THRESH_BINARY) contours = cv2.findContours(binImage, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
Установив крайние значения параметров функции порогового преобразования, мы еще и избавляемся от различного рода зашумлений. Также, для минимизации количества лишних мелких элементов и шумов, можно применить
морфологические преобразования: функции эрозии (сжатия) и наращивания (расширения). Данные функции так же входят в состав «OpenCV». После преобразований отбираются контуры, число вершин у которых равно четырем (предварительно выполнив над контурами функцию аппроксимации).

В первом окне результат порогового преобразования. Во втором — пример морфологического преобразования. В третьем окне уже отобраны ячейки и шапка капчи: выделены цветом программно.
После всех преобразований в конечный массив с ячейками всё равно попадают контуры, которые не являются ячейками. Для того, чтобы отсеять ненужные шумы, я произвожу отбор по значениям длины (периметра) и площади контуров.
Экспериментально выявлено, что величины интересуемых контуров лежат в диапазоне от 360 до 900 единиц. Данная величина подобрана на экране с диагональю 15,6 дюймов и разрешением 1366 x 768 пикселей. В дальнейшем, указанные величины контуров можно вычислять в зависимости от размера экрана пользователя, но в создаваемом прототипе такой привязки нет.
Главное преимущество выбранного подхода к обнаружению ячеек заключается в том, что нам всё равно, как будет выглядеть сетка и сколько всего будет показано ячеек на странице капчи: 8, 9 или 16.
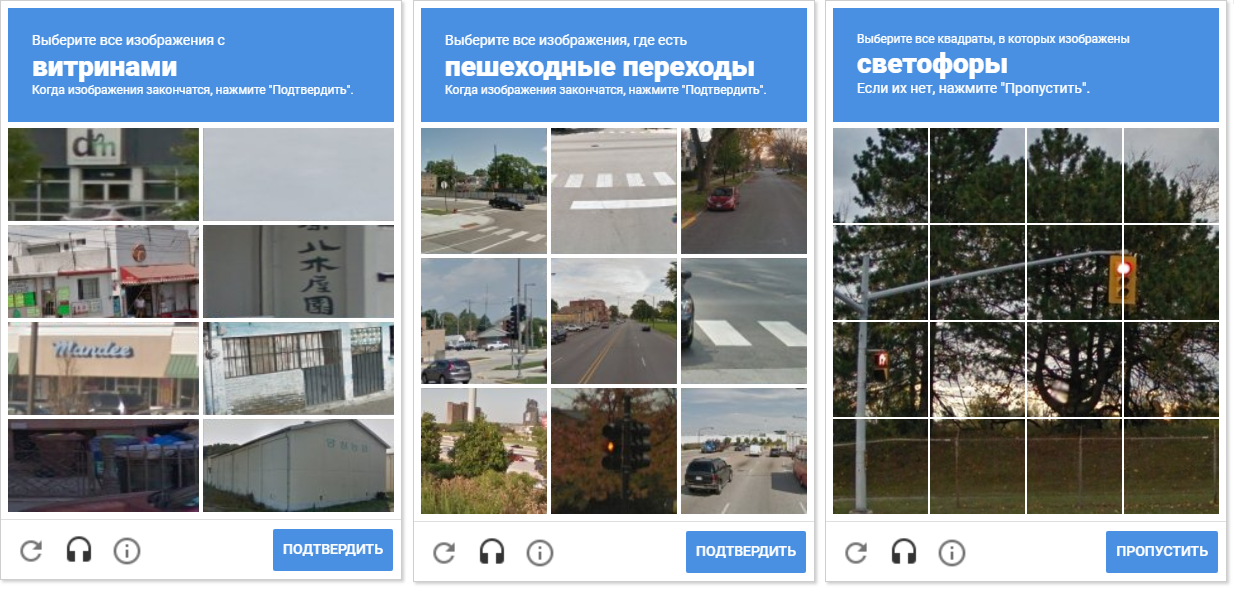
На изображении показаны разновидности сеток капчи. Обратите внимание, что расстояние между ячейками — разное. Отделить ячейки друг от друга позволяет морфологическое сжатие.
Дополнительным преимуществом обнаружения контуров является и то, что «OpenCV» позволяет нам обнаружить их центры (они нужны нам для определения координат перемещения и клика мышкой).
Отбор ячеек для выбора
Имея массив с чистыми контурами ячеек капчи без лишних контуров шумов, мы можем в цикле пройти по каждой ячейке капчи («контуру» в терминологии «OpenCV») и проверить её на факт пересечения с обнаруженным «боксом» объекта, полученным от нейросети.
Для установления этого факта, применялся перевод обнаруженного «бокса» в аналогичный ячейкам контур. Но такой подход оказался неправильным, потому что случай, когда объект располагается внутри ячейки, не считается за пересечение. Естественно, что такие ячейки не выделялись в капче.
Проблема была решена перерисовкой контура каждой ячейки (с белой заливкой) на черный лист. Аналогичным образом было получено бинарное изображение рамки с объектом. Возникает вопрос — как теперь установить факт пересечения ячейки с закрашенной рамкой объекта? В каждой итерации массива с ячейками, над двумя бинарными изображениями производится операция дизъюнкци (логическое или). В её результате мы получаем новое бинарное изображение, в котором будут выделены пересекаемые участки. То есть, если такие участки имеются — значит ячейка и рамка объекта пересекаются. Программно такую проверку можно сделать методом «.any()»: она вернет «True» если в массиве имеется хотя бы один элемент равный единице или «False», если единиц нет.
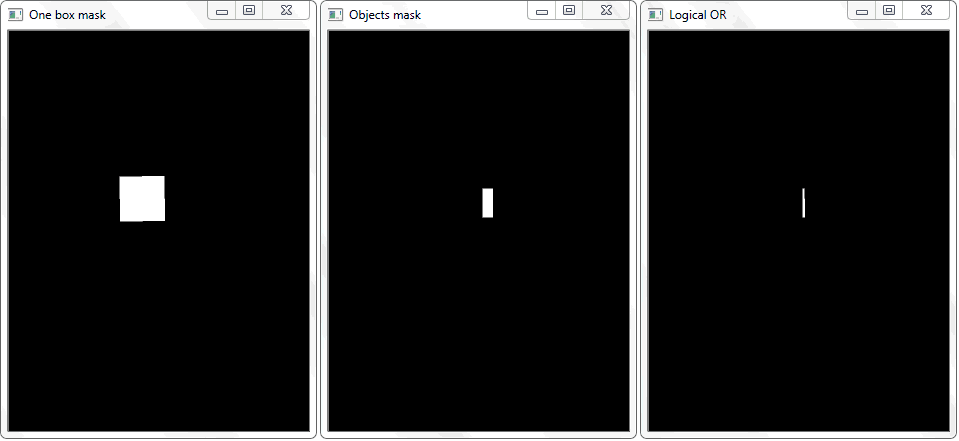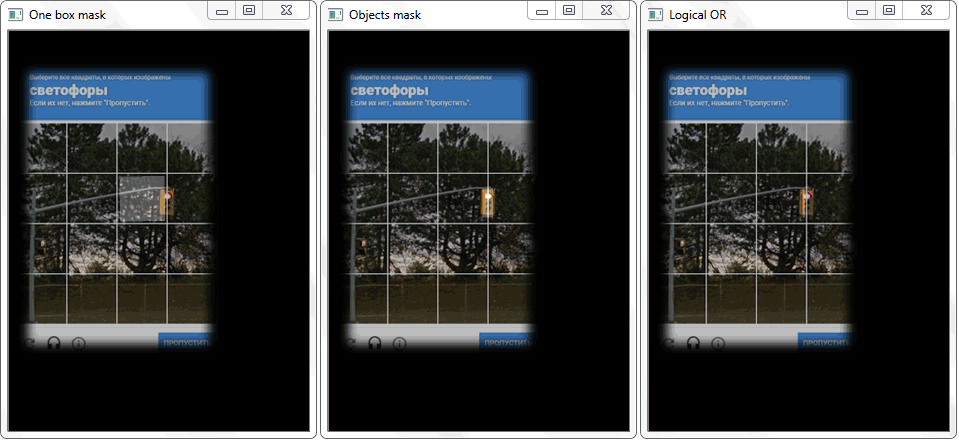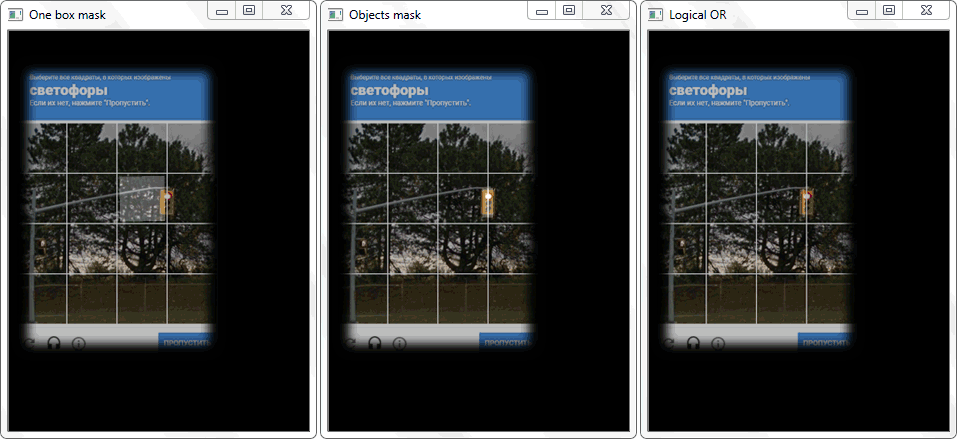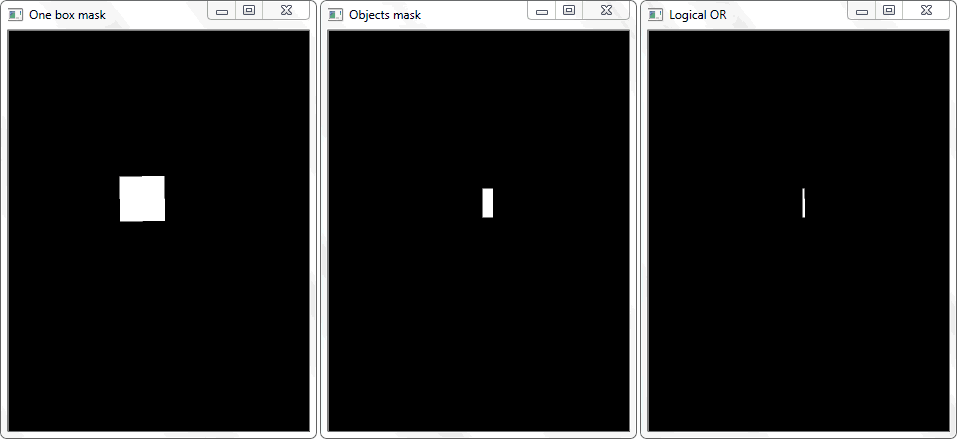
Функция «any()» для изображения «Logical OR» в данном случае вернет истину и тем самым установит факт пересечения ячейки с областью рамки обнаруженного объекта.
Управление
Управление курсором в «Python» становится доступным благодаря модулю «win32api» (однако позднее выяснилось, что уже импортированный в проект «PyAutoGUI» тоже умеет это делать). Нажатие и отпускание левой кнопки мыши, а также перемещение курсора в нужные координаты производится соответствующими функциями модуля «win32api». Но в прототипе они были завернуты в пользовательские функции для того, чтобы обеспечить визуальное наблюдение за движением курсора. Это негативно влияет на производительность и было реализовано исключительно для демонстрации.
В процессе разработки возникла идея выбора ячеек в случайном порядке. Возможно, что это не имеет практического смысла (по объяснимым причинам «Google» не дает нам комментариев и описания механизмов работы капчи), однако перемещение курсора по ячейкам в хаотичном порядке выглядит забавнее.
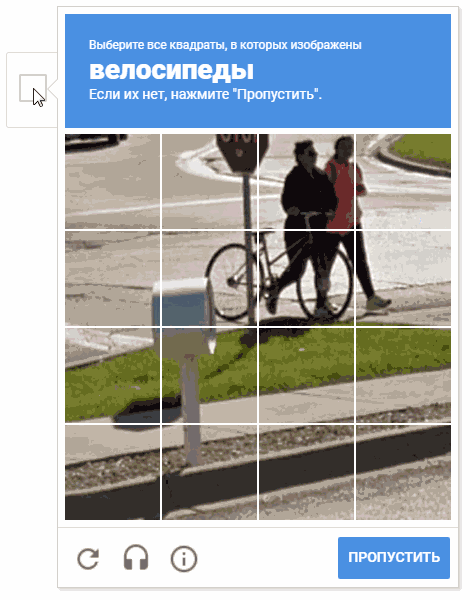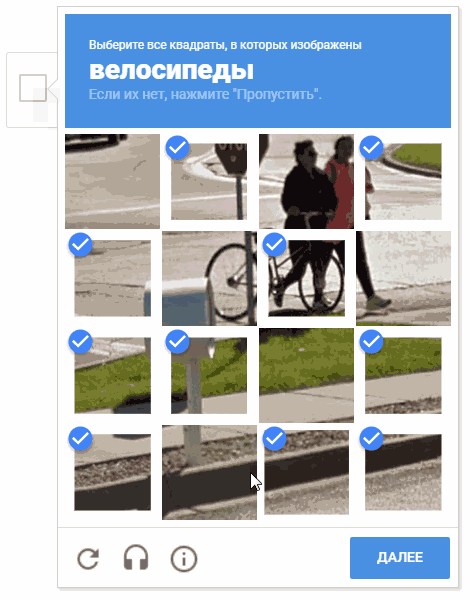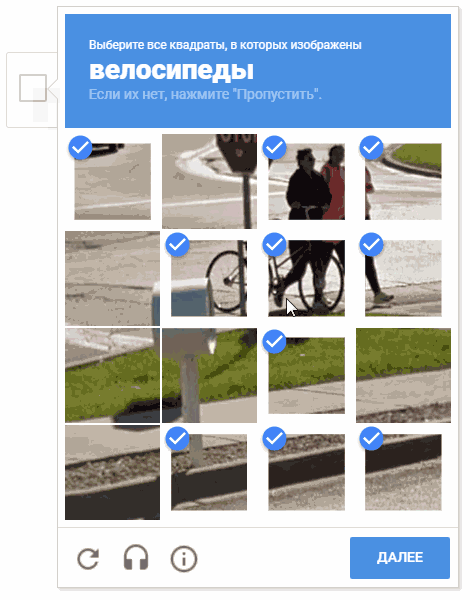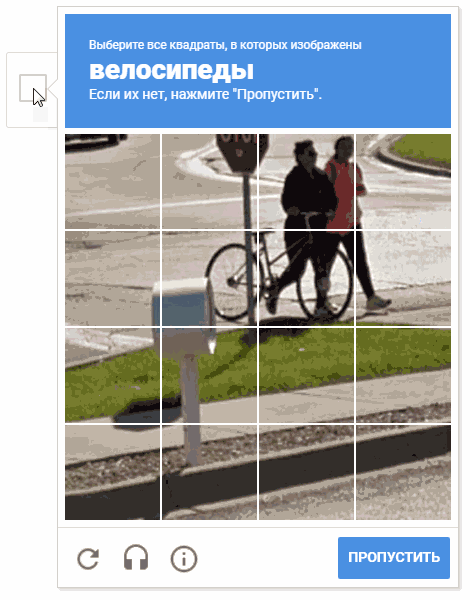
На анимации результат «random.shuffle(boxesForSelect)».
Распознавание текста
Для того, чтобы объединить все имеющиеся наработки в единое целое, требуется еще одно звено: блок распознавания требуемого от капчи класса. Мы уже умеем распознавать и отличать разные объекты на изображении, мы умеем кликать на произвольные ячейки капчи, однако мы не знаем на какие именно ячейки нужно нажать. Одно из направлений решения данной проблемы — распознавать текст из шапки капчи. Первым делом я попробовал реализовать распознавание текста при помощи средства оптического распознавания символов «Tesseract-OCR».
В последних версиях имеется возможность установки языковых пакетов прямо в окне программы установки (раньше это делалось вручную). После установки и импорта «Tesseract-OCR» в свой проект, я попытался распознать текст из шапки капчи.
Результат, к сожалению, меня совершенно не впечатлил. Я решил, что текст в шапке выделен жирным и слитным начертанием не просто так, поэтому я попробовал применить к изображению различные преобразования: операции бинаризации, сужения, расширения, размытия, искажения и изменения размеров. К сожалению, это не дало хорошего результата: в лучших случаях определялась лишь часть букв класса, а когда результат получался удовлетворительным, я применял эти же преобразования, но для других шапок (с другим текстом), и результат снова получался плохим.

Распознавание шапки с «Tesseract-OCR» обычно приводило к неудовлетворительным результатам.
Нельзя однозначно сказать, что «Tesseract-OCR» плохо распознает текст, это не так: с другими изображениями (не шапками капчи) инструмент справляется значительно лучше.
Я решил воспользоваться сторонним сервисом, который бесплатно предлагал API для работы с ним (требуется регистрация и получение ключа на электронный адрес). В сервисе установлено ограничение на 500 распознаваний в день, однако за весь период разработки никаких проблем с ограничениями у меня не возникло. Напротив: я подавал в сервис оригинальное изображение шапки (не применяя абсолютно никаких преобразований) и результат меня приятно впечатлил.
Слова от сервиса возвращались практически без ошибок (обычно даже те, которые написаны мелким шрифтом). Более того, они возвращались в очень удобном формате — разбитые по строкам символами переноса строки. Во всех изображениях меня интересовала только вторая строка, поэтому я напрямую обращался к ней. Это не могло не радовать, так как такой формат освободил меня от необходимости подготавливать строку: мне не пришлось резать начало или конец всего текста, делать «тримы», замены, работать с регулярными выражениями и совершать прочие операции над строкой, направленные на выделение одного слова (а иногда двух!) — приятный бонус!
text = serviceResponse['ParsedResults'][0]['ParsedText'] #получил текст из JSON
lines = text.splitlines() #Разбил на элементы
print("Recognized " + lines[1]) #Готово к использованию!
Сервис, который распознавал текст, практически никогда не ошибался с названием класса, но я всё равно решил оставить часть названия класса для возможной ошибки. Это необязательно, но я заметил, что «Tesseract-OCR» в некоторых случаях неправильно распознавал конец слова начиная с середины. Кроме того, такой подход исключает ошибку приложения, в случае длинного названия класса или названия из двух слов (в таком случае сервис вернет не 3, а 4 строки, и я не смогу найти во второй строке вхождение полного наименования класса).
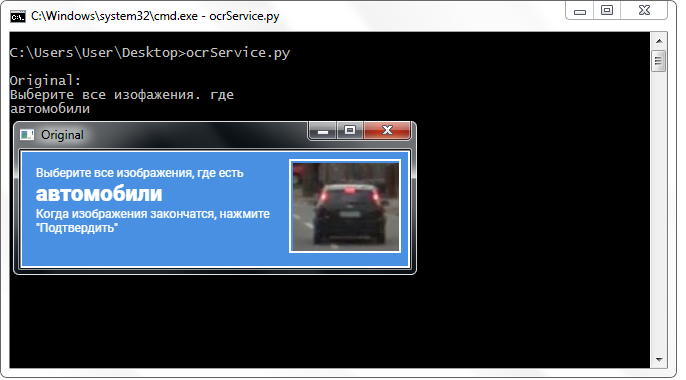
Сторонний сервис хорошо распознает наименование класса без каких-либо преобразований над изображением.
Слияние наработок
Получить текст из шапки — мало. Его нужно сопоставить с идентификаторами имеющихся классов модели, потому что в массиве классов нейронная сеть возвращает именно идентификатор класса, а не его название, как это может показаться. При обучении модели, как правило, создается файл, в котором сопоставляются названия классов и их идентификаторы (он же «label map»). Я решил поступить проще и указать идентификаторы классов вручную, так как капча всё равно требует классы на русском языке (к слову, это можно изменить):
if "автом" in query: # ищем вхождение класса в запросе капчи classNum = 3 # присваиваем соответствующий "label map" идентификатор elif "свето" in query: classNum = 10 elif "пожар" in query: classNum = 11 ...
Все описанное выше, воспроизводится в основном цикле программы: определяются рамки объекта, ячейки, их пересечения, производятся перемещения курсора и клики. При обнаружении шапки производится распознавание текста. Если нейронная сеть не может обнаружить требуемый класс, то совершается произвольный сдвиг изображения до 5 раз (то есть меняются входные в нейросеть данные), и если обнаружения по прежнему не произошло, то выполняется клик на кнопку «Пропустить/Подтвердить» (её положение обнаруживается аналогично обнаружению ячеек и шапки).
Если Вы часто решаете капчу, Вы могли наблюдать картину, когда выбранная ячейка пропадает, а на её месте медленно и не спеша появляется новая. Поскольку прототип запрограммирован на моментальный переход к следующей странице после выбора всех ячеек, мной было принято решение делать 3 секундные паузы, чтобы исключить нажатия на кнопку «Далее» без обнаружения объектов на медленно появляющейся ячейке.
Статья была бы не полной, если бы в ней не было описания самого главного — галочки успешного прохождения капчи. Я решил, что с такой задачей может справиться простое сравнение по шаблону. Стоит отметить, что сравнение по шаблону — далеко не самый лучший путь для обнаружения объектов. Мне, например, пришлось выставить чувствительность обнаружения на значение «0.01», чтобы функция перестала во всем видеть галочки, но видела её, когда галочка действительно есть. Аналогичным образом я поступил с пустым чекбосом, который встречает пользователя и с которого начинается прохождение капчи (там проблем с чувствительностью не было).
Результат
Результатом всех описанных действий стало приложение, работоспособность которого я протестировал на «Тостере»:
Стоит признать, что ролик снят не с первой попытки, так как я нередко сталкивался с необходимостью выбора классов, которые отсутствуют в модели (например, пешеходные переходы, лестницы или витрины).
«Google reCAPTCHA» возвращает сайту некую величину, показывающую насколько «Вы робот», а администраторы сайта, в свою очередь, могут установить порог прохождения этой величины. Возможно, что на «Тостере» был установлен относительно низкий порог прохождения капчи. Это объясняет достаточно легкое прохождение капчи программой, несмотря на то, что она дважды ошиблась, не увидев светофор из первой страницы и пожарный гидрант из четвертой страницы капчи.
Помимо «Тостера», были проведены эксперименты на официальной
демонстрационной странице «reCAPTCHA». В результате, замечено, что после множественных ошибочных обнаружений (и необнаружений), пройти капчу становится крайне затруднительно даже человеку: требуются новые классы (вроде тракторов и пальм), в выборках появляются ячейки без объектов (почти монотонные цвета) и резко увеличивается количество страниц, которые нужно пройти. Это было особенно заметно, когда я решил попробовать кликать по случайным ячейкам в случае необнаружения объектов (ввиду их отсутствия в модели).
Поэтому можно точно утверждать, что случайные клики не приведут к решению задачи. Чтобы избавиться от такого «завала» экзаменатором, производился реконнект Интернет-соединения и очистка данных браузера, потому что пройти такой тест становилось невозможным — он был практически бесконечным!

При сомнении в Вашей человечности возможен и такой исход.
Развитие
Если статья и приложение вызовет интерес у читателя, я с удовольствием продолжу его реализацию, тесты и дальнейшее описание в более детальном виде.
Речь идет об обнаружении классов, которые не входят в состав текущей сети, это значительно улучшит эффективность работы приложения. На данный момент имеется острая необходимость в распознавании как минимум таких как классов как: пешеходные переходы, витрины и дымовые трубы — я расскажу, как можно переобучить модель. Во время разработки я составил небольшой список наиболее часто встречающихся классов:
- пешеходные переходы;
- пожарные гидранты;
- витрины;
- дымовые трубы;
- автомобили;
- автобусы;
- светофоры;
- велосипеды;
- транспортные средства;
- лестницы;
- знаки.
Улучшения качества обнаружения объектов можно добиться и путем использования нескольких моделей одновременно: это может ухудшить производительность, но повысить точность.
Другой способ улучшения качества обнаружения объектов — изменение входного в нейросеть изображения: на видео можно увидеть, что при необнаружении объектов я несколько раз делаю произвольное смещение изображения (в пределах 10 пикселей по горизонтали и вертикали), и зачастую такая операция позволяет увидеть объекты, которые ранее не были обнаружены.
К выявлению необнаруженных объектов приводит и увеличение изображения из маленького квадрата в большой (до 300 x 300 пикселей).

Слева объекты не обнаружены: оригинальный квадрат стороной 100 пикселей. Справа автобус обнаружен: увеличенный квадрат до 300 x 300 пикселей.
Еще одним интересным преобразованием можно отметить удаление белой сетки над изображением средствами «OpenCV»: возможно, что пожарный гидрант на видео не обнаружился именно по этой причине (такой класс присутствует в нейронной сети).
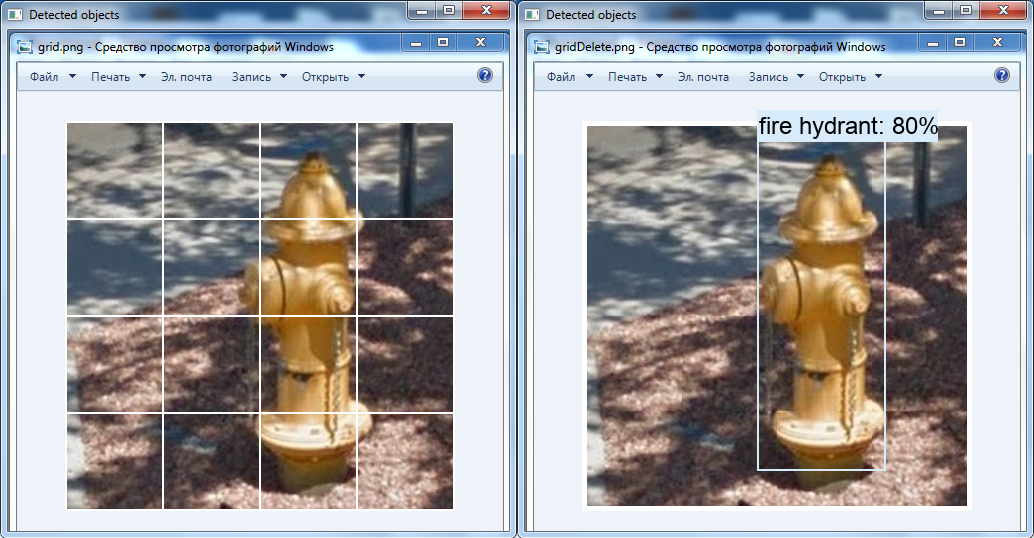
Слева оригинальное изображение, а справа — измененное в графическом редакторе: сетка удалена, ячейки перемещены друг к другу.
Итоги
Данной статьей я хотел рассказать Вам о том, что капча, вероятно, не самая лучшая защита от ботов, и вполне возможно, что в скором времени возникнет потребность в новых средствах защиты от автоматизированных систем.
Разработанный прототип, даже будучи в незавершенном состоянии, демонстрирует, что при наличии требуемых классов в модели нейронной сети и применении преобразований над изображениями, можно достигнуть автоматизации процесса, который автоматизированным быть не должен.
Также, я хотел бы обратить внимание компании «Google» на то, что помимо способа обхода капчи, описанного в данной статье, имеется еще и иной способ, в котором производится транскрибация аудио-образца. На мой взгляд, уже сейчас необходимо принимать меры, связанные с улучшением качества программных продуктов и алгоритмов против роботов.
Из содержания и сути материала может показаться, что я не люблю «Google» и в частности «reCAPTCHA», однако это далеко не так, и, если следующей реализации быть — я расскажу почему.
Разработано и продемонстрировано в целях повышения уровня образования и улучшения методов, направленных на обеспечение безопасности информации.
Спасибо за внимание.
Источник: habr.com