Логирование в Python: руководство разработчика

Если вы — новичок, то вы, наверняка, привыкли пользоваться командой print(), выводя с её помощью определённые значения в ходе работы программы, проверяя, работает ли код так, как от него ожидается. Использование print() вполне может оправдать себя при отладке маленьких Python-программ. Но, когда вы перейдёте к более крупным и сложным проектам, вам понадобится постоянный журнал, содержащий больше информации о поведении вашего кода, помогающий вам планомерно отлаживать и отслеживать ошибки.
Из этого учебного руководства вы узнаете о том, как настроить логирование в Python, используя встроенный модуль logging. Вы изучите основы логирования, особенности вывода в журналы значений переменных и исключений, разберётесь с настройкой собственных логгеров, с форматировщиками вывода и со многим другим.
Вы, кроме того, узнаете о том, как Sentry Python SDK способен помочь вам в мониторинге приложений и в упрощении рабочих процессов, связанных с отладкой кода. Платформа Sentry обладает нативной интеграцией со встроенным Python-модулем logging, и, кроме того, предоставляет подробную информацию об ошибках приложения и о проблемах с производительностью, которые в нём возникают.
Начало работы с Python-модулем logging
В Python имеется встроенный модуль logging, применяемый для решения задач логирования. Им мы будем пользоваться в этом руководстве. Первый шаг к профессиональному логированию вы можете выполнить прямо сейчас, импортировав этот модуль в своё рабочее окружение.
import logging
Встроенный модуль логирования Python даёт нам простой в использовании функционал и предусматривает пять уровней логирования. Чем выше уровень — тем серьёзнее неприятность, о которой сообщает соответствующая запись. Самый низкий уровень логирования — это debug (10), а самый высокий — это critical (50).
Дадим краткие характеристики уровней логирования:
Debug (10): самый низкий уровень логирования, предназначенный для отладочных сообщений, для вывода диагностической информации о приложении.Info (20): этот уровень предназначен для вывода данных о фрагментах кода, работающих так, как ожидается.Warning (30): этот уровень логирования предусматривает вывод предупреждений, он применяется для записи сведений о событиях, на которые программист обычно обращает внимание. Такие события вполне могут привести к проблемам при работе приложения. Если явно не задать уровень логирования — по умолчанию используется именноwarning.Error (40): этот уровень логирования предусматривает вывод сведений об ошибках — о том, что часть приложения работает не так как ожидается, о том, что программа не смогла правильно выполниться.Critical (50): этот уровень используется для вывода сведений об очень серьёзных ошибках, наличие которых угрожает нормальному функционированию всего приложения. Если не исправить такую ошибку — это может привести к тому, что приложение прекратит работу.
В следующем фрагменте кода показано использование вышеперечисленных уровней логирования при выводе нескольких сообщений. Здесь используется синтаксическая конструкция logging.<level>(<message>).
logging.debug("A DEBUG Message")
logging.info("An INFO")
logging.warning("A WARNING")
logging.error("An ERROR")
logging.critical("A message of CRITICAL severity")Ниже приведён результат выполнения этого кода. Как видите, сообщения, выведенные с уровнями логирования warning, error и critical, попадают в консоль. А сообщения с уровнями debug и info — не попадают.
WARNING:root:A WARNING ERROR:root:An ERROR CRITICAL:root:A message of CRITICAL severity
Это так из-за того, что в консоль выводятся лишь сообщения с уровнями от warning и выше. Но это можно изменить, настроив логгер и указав ему, что в консоль надо выводить сообщения, начиная с некоего, заданного вами, уровня логирования.
Подобный подход к логированию, когда данные выводятся в консоль, не особо лучше использования print(). На практике может понадобиться записывать логируемые сообщения в файл. Этот файл будет хранить данные и после того, как работа программы завершится. Такой файл можно использовать в качестве журнала отладки.
Обратите внимание на то, что в примере, который мы будем тут разбирать, весь код находится в файле main.py. Когда мы производим рефакторинг существующего кода или добавляем новые модули — мы сообщаем о том, в какой файл (имя которого построено по схеме <module-name>.py) попадает новый код. Это поможет вам воспроизвести у себя то, о чём тут идёт речь.
Логирование в файл
Для того чтобы настроить простую систему логирования в файл — можно воспользоваться конструктором basicConfig(). Вот как это выглядит:
logging.basicConfig(level=logging.INFO, filename="py_log.log",filemode="w")
logging.debug("A DEBUG Message")
logging.info("An INFO")
logging.warning("A WARNING")
logging.error("An ERROR")
logging.critical("A message of CRITICAL severity")Поговорим о логгере root, рассмотрим параметры basicConfig():
level: это — уровень, на котором нужно начинать логирование. Если он установлен вinfo— это значит, что все сообщения с уровнемdebugигнорируются.filename: этот параметр указывает на объект обработчика файла. Тут можно указать имя файла, в который нужно осуществлять логирование.filemode: это — необязательный параметр, указывающий режим, в котором предполагается работать с файлом журнала, заданным параметромfilename. Установкаfilemodeв значениеw(write, запись) приводит к тому, что логи перезаписываются при каждом запуске модуля. По умолчанию параметрfilemodeустановлен в значениеa(append, присоединение), то есть — в файл будут попадать записи из всех сеансов работы программы.
После выполнения модуля main можно будет увидеть, что в текущей рабочей директории был создан файл журнала, py_log.log.
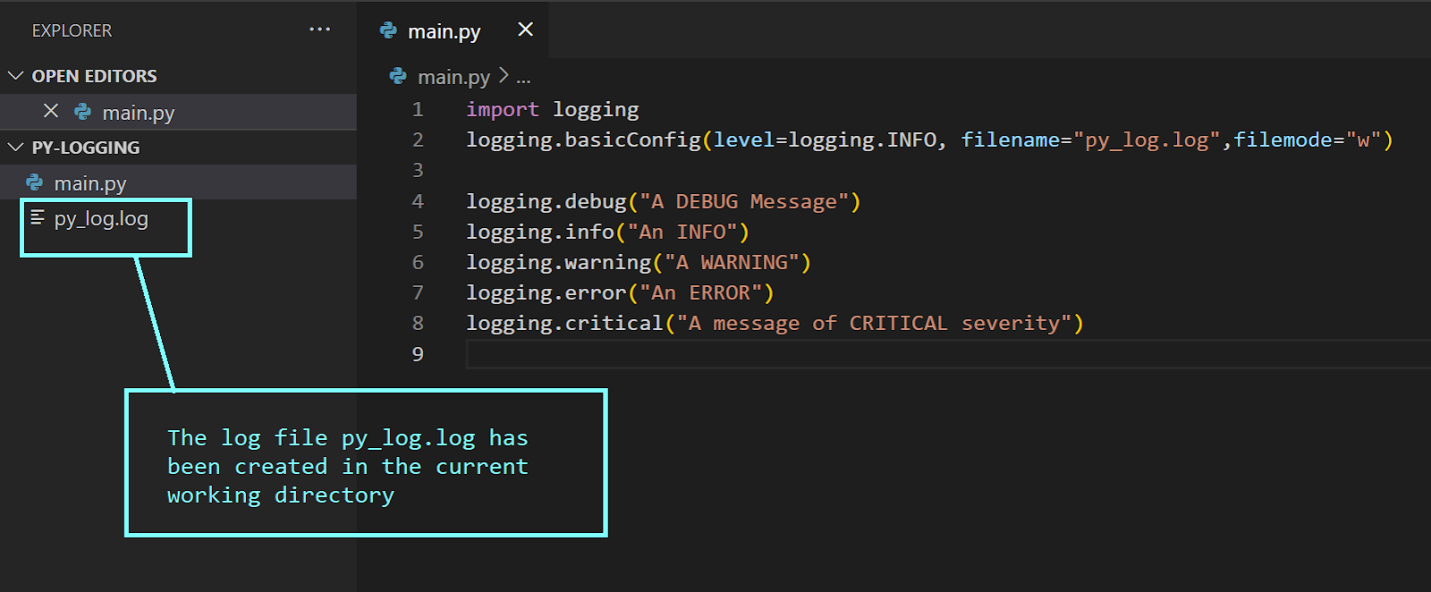
Так как мы установили уровень логирования в значение info — в файл попадут записи с уровнем info и с более высокими уровнями.
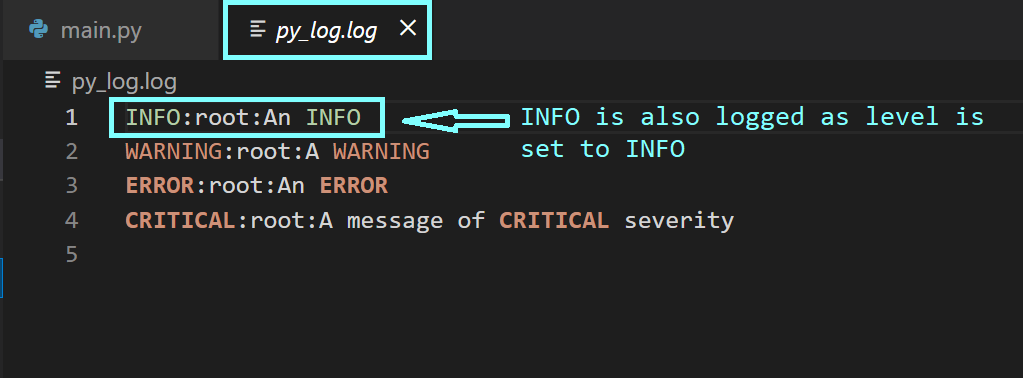
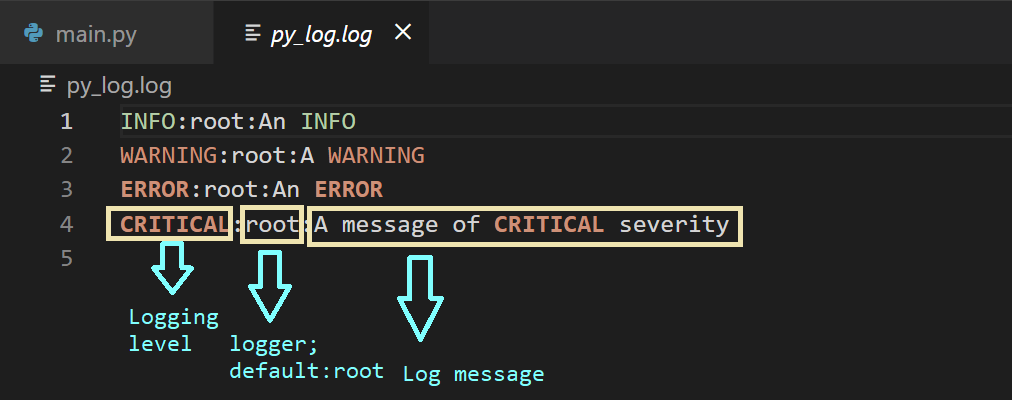
Записи в лог-файле имеют формат <logging-level>:<name-of-the-logger>:<message>. По умолчанию <name-of-the-logger>, имя логгера, установлено в root, так как мы пока не настраивали пользовательские логгеры.
Помимо базовой информации, выводимой в лог, может понадобится снабдить записи отметками времени, указывающими на момент вывода той или иной записи. Это упрощает анализ логов. Сделать это можно, воспользовавшись параметром конструктора format:
logging.basicConfig(level=logging.INFO, filename="py_log.log",filemode="w",
format="%(asctime)s %(levelname)s %(message)s")
logging.debug("A DEBUG Message")
logging.info("An INFO")
logging.warning("A WARNING")
logging.error("An ERROR")
logging.critical("A message of CRITICAL severity")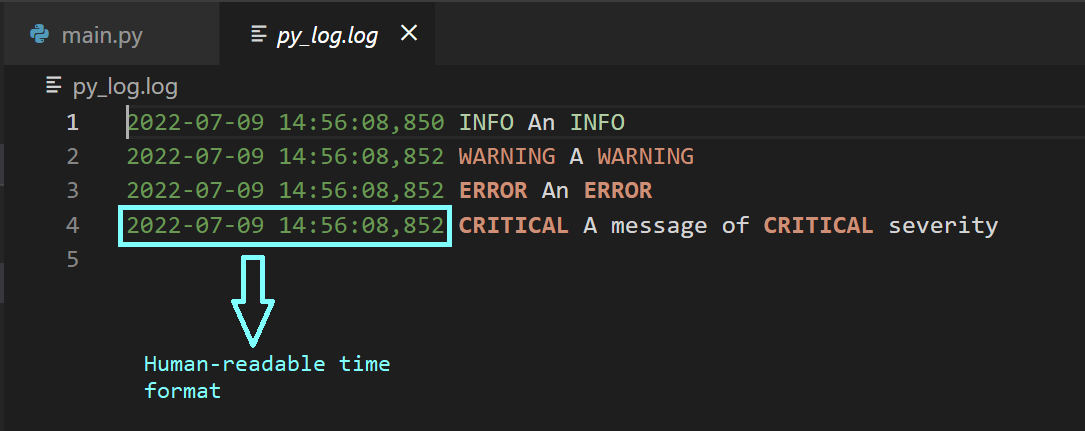
Существуют и многие другие атрибуты записи лога, которыми можно воспользоваться для того чтобы настроить внешний вид сообщений в лог-файле. Настраивая поведение логгера root — так, как это показано выше, проследите за тем, чтобы конструктор logging.basicConfig()вызывался бы лишь один раз. Обычно это делается в начале программы, до использования команд логирования. Последующие вызовы конструктора ничего не изменят — если только не установить параметр force в значение True.
Логирование значений переменных и исключений
Модифицируем файл main.py. Скажем — тут будут две переменных — x и y, и нам нужно вычислить значение выражения x/y. Мы знаем о том, что при y=0 мы столкнёмся с ошибкой ZeroDivisionError. Обработать эту ошибку можно в виде исключения с использованием блока try/except.
Далее — нужно залогировать исключение вместе с данными трассировки стека. Чтобы это сделать — можно воспользоваться logging.error(message, exc_info=True). Запустите следующий код и посмотрите на то, как в файл попадают записи с уровнем логирования info, указывающие на то, что код работает так, как ожидается.
x = 3
y = 4
logging.info(f"The values of x and y are {x} and {y}.")
try:
x/y
logging.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logging.error("ZeroDivisionError",exc_info=True)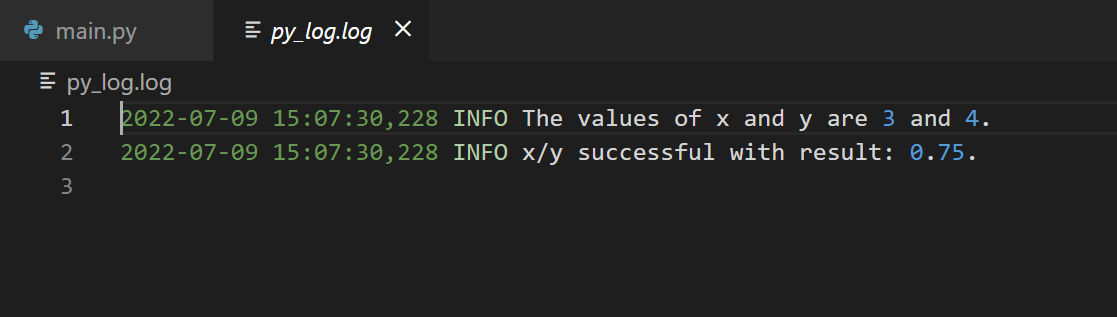
Теперь установите значение y в 0 и снова запустите модуль.
Исследуя лог-файл py_log.log, вы увидите, что сведения об исключении были записаны в него вместе со стек-трейсом.
x = 4
y = 0
logging.info(f"The values of x and y are {x} and {y}.")
try:
x/y
logging.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logging.error("ZeroDivisionError",exc_info=True)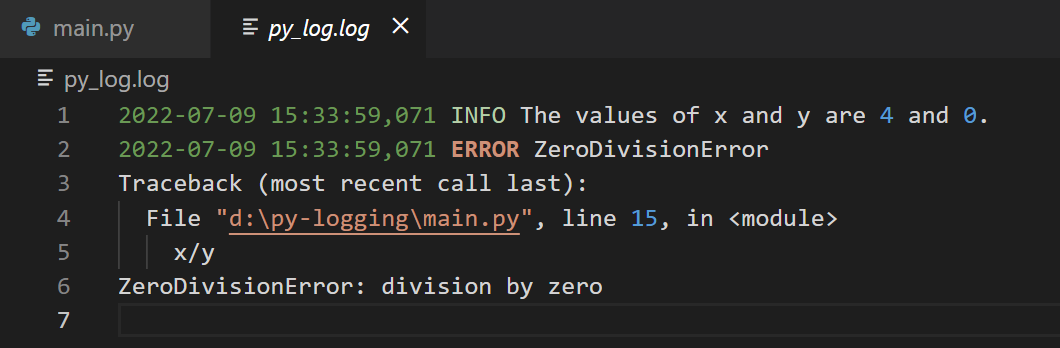
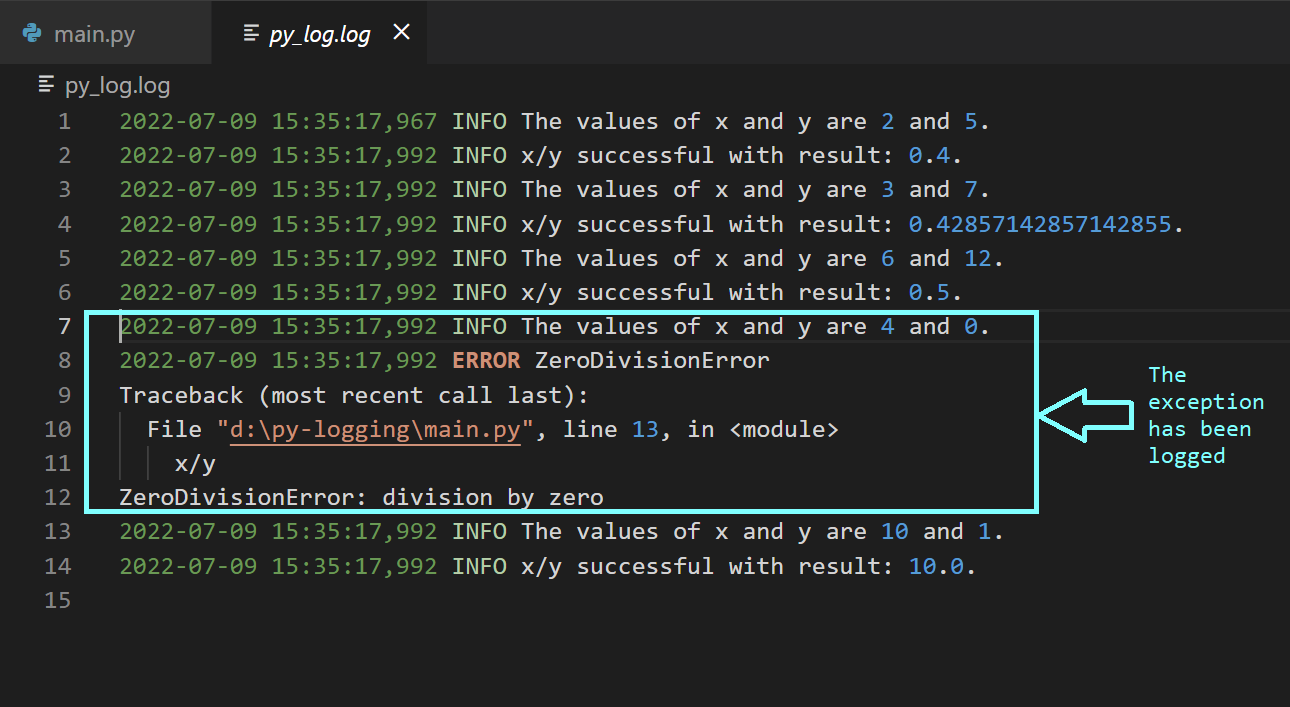
Теперь модифицируем код так, чтобы в нём имелись бы списки значений x и y, для которых нужно вычислить коэффициенты x/y. Для логирования исключений ещё можно воспользоваться конструкцией logging.exception(<message>).
x_vals = [2,3,6,4,10]
y_vals = [5,7,12,0,1]
for x_val,y_val in zip(x_vals,y_vals):
x,y = x_val,y_val
logging.info(f"The values of x and y are {x} and {y}.")
try:
x/y
logging.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logging.exception("ZeroDivisionError")Сразу после запуска этого кода можно будет увидеть, что в лог-файл попала информация и о событиях успешного вычисления коэффициента, и об ошибке, когда возникло исключение.
Настройка логирования с помощью пользовательских логгеров, обработчиков и форматировщиков
Отрефакторим код, который у нас уже есть. Объявим функцию test_division.
def test_division(x,y):
try:
x/y
logger2.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logger2.exception("ZeroDivisionError")Объявление этой функции находится в модуле test_div. В модуле main будут лишь вызовы функций. Настроим пользовательские логгеры в модулях main и test_div, проиллюстрировав это примерами кода.
Настройка пользовательского логгера для модуля test_div
import logging
logger2 = logging.getLogger(__name__)
logger2.setLevel(logging.INFO)
# настройка обработчика и форматировщика для logger2
handler2 = logging.FileHandler(f"{__name__}.log", mode='w')
formatter2 = logging.Formatter("%(name)s %(asctime)s %(levelname)s %(message)s")
# добавление форматировщика к обработчику
handler2.setFormatter(formatter2)
# добавление обработчика к логгеру
logger2.addHandler(handler2)
logger2.info(f"Testing the custom logger for module {__name__}...")
def test_division(x,y):
try:
x/y
logger2.info(f"x/y successful with result: {x/y}.")
except ZeroDivisionError as err:
logger2.exception("ZeroDivisionError")Настройка пользовательского логгера для модуля main
import logging
from test_div import test_division
# получение пользовательского логгера и установка уровня логирования
py_logger = logging.getLogger(__name__)
py_logger.setLevel(logging.INFO)
# настройка обработчика и форматировщика в соответствии с нашими нуждами
py_handler = logging.FileHandler(f"{__name__}.log", mode='w')
py_formatter = logging.Formatter("%(name)s %(asctime)s %(levelname)s %(message)s")
# добавление форматировщика к обработчику
py_handler.setFormatter(py_formatter)
# добавление обработчика к логгеру
py_logger.addHandler(py_handler)
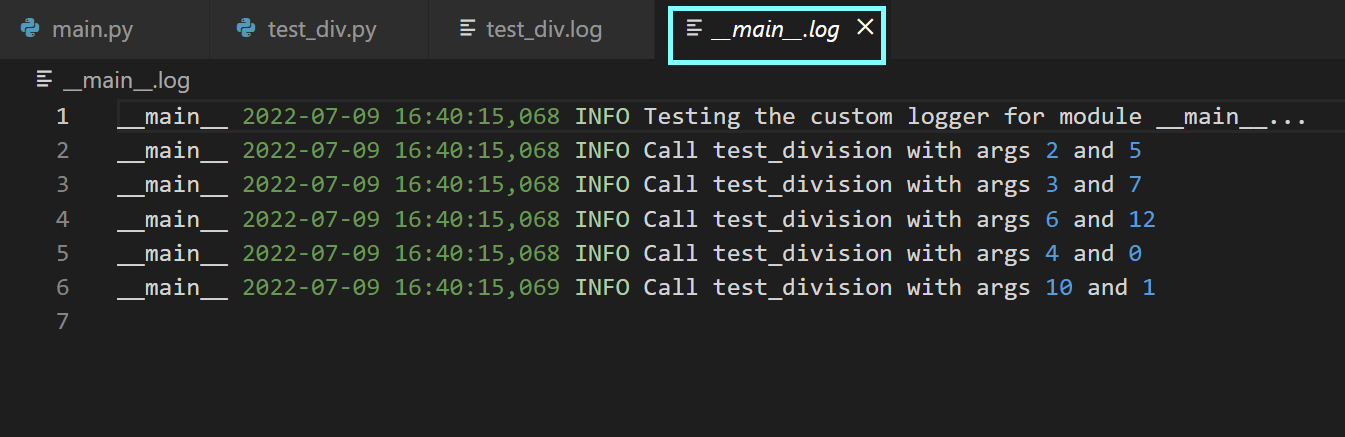
py_logger.info(f"Testing the custom logger for module {__name__}...")
x_vals = [2,3,6,4,10]
y_vals = [5,7,12,0,1]
for x_val,y_val in zip(x_vals,y_vals):
x,y = x_val, y_val
# вызов test_division
test_division(x,y)
py_logger.info(f"Call test_division with args {x} and {y}")
Разберёмся с тем, что происходит коде, где настраиваются пользовательские логгеры.
Сначала мы получаем логгер и задаём уровень логирования. Команда logging.getLogger(name) возвращает логгер с заданным именем в том случае, если он существует. В противном случае она создаёт логгер с заданным именем. На практике имя логгера устанавливают с использованием специальной переменной name, которая соответствует имени модуля. Мы назначаем объект логгера переменной. Затем мы, используя команду logging.setLevel(level), устанавливаем нужный нам уровень логирования.
Далее мы настраиваем обработчик. Так как мы хотим записывать сведения о событиях в файл, мы пользуемся FileHandler. Конструкция logging.FileHandler(filename) возвращает объект обработчика файла. Помимо имени лог-файла, можно, что необязательно, задать режим работы с этим файлом. В данном примере режим (mode) установлен в значение write. Есть и другие обработчики, например — StreamHandler, HTTPHandler, SMTPHandler.
Затем мы создаём объект форматировщика, используя конструкцию logging.Formatter(format). В этом примере мы помещаем имя логгера (строку) в начале форматной строки, а потом идёт то, чем мы уже пользовались ранее при оформлении сообщений.
Потом мы добавляем форматировщик к обработчику, пользуясь конструкцией вида <handler>.setFormatter(<formatter>). А в итоге добавляем обработчик к объекту логгера, пользуясь конструкцией <logger>.addHandler(<handler>).
Теперь можно запустить модуль main и исследовать сгенерированные лог-файлы.

Рекомендации по организации логирования в Python
До сих пор мы говорили о том, как логировать значения переменных и исключения, как настраивать пользовательские логгеры. Теперь же предлагаю вашему вниманию рекомендации по логированию.
- Устанавливайте оптимальный уровень логирования. Логи полезны лишь тогда, когда их можно использовать для отслеживания важных ошибок, которые нужно исправлять. Подберите такой уровень логирования, который соответствует специфике конкретного приложения. Вывод в лог сообщений о слишком большом количестве событий может быть, с точки зрения отладки, не самой удачной стратегией. Дело в том, что при таком подходе возникнут сложности с фильтрацией логов при поиске ошибок, которым нужно немедленно уделить внимание.
- Конфигурируйте логгеры на уровне модуля. Когда вы работаете над приложением, состоящим из множества модулей — вам стоит задуматься о том, чтобы настроить свой логгер для каждого модуля. Установка имени логгера в
nameпомогает идентифицировать модуль приложения, в котором имеются проблемы, нуждающиеся в решении. - Включайте в состав сообщений логов отметку времени и обеспечьте единообразное форматирование сообщений. Всегда включайте в сообщения логов отметки времени, так как они полезны в деле поиска того момента, когда произошла ошибка. Единообразно форматируйте сообщения логов, придерживаясь одного и того же подхода в разных модулях.
- Применяйте ротацию лог-файлов ради упрощения отладки. При работе над большим приложением, в состав которого входит несколько модулей, вы, вполне вероятно, столкнётесь с тем, что размер ваших лог-файлов окажется очень большим. Очень длинные логи сложно просматривать в поисках ошибок. Поэтому стоит подумать о ротации лог-файлов. Сделать это можно, воспользовавшись обработчиком
RotatingFileHandler, применив конструкцию, которая строится по следующей схеме:logging.handlers.RotatingFileHandler(filename, maxBytes, backupCount). Когда размер текущего лог-файла достигнет размераmaxBytes, следующие записи будут попадать в другие файлы, количество которых зависит от значения параметраbackupCount. Если установить этот параметр в значениеK— у вас будетKфайлов журнала.
Сильные и слабые стороны логирования
Теперь, когда мы разобрались с основами логирования в Python, поговорим о сильных и слабых сторонах этого механизма.
Мы уже видели, как логирование позволяет поддерживать файлы журналов для различных модулей, из которых состоит приложение. Мы, кроме того, можем конфигурировать подсистему логирования и подстраивать её под свои нужды. Но эта система не лишена недостатков. Даже когда уровень логирования устанавливают в значение warning, или в любое значение, которое выше warning, размеры лог-файлов способны быстро увеличиваться. Происходит это в том случае, когда в один и тот же журнал пишут данные, полученные после нескольких сеансов работы с приложением. В результате использование лог-файлов для отладки программ превращается в нетривиальную задачу.
Кроме того, исследование логов ошибок — это сложно, особенно в том случае, если сообщения об ошибках не содержат достаточных сведений о контекстах, в которых происходят ошибки. Когда выполняют команду logging.error(message), не устанавливая при этом exc_info в True, сложно обнаружить и исследовать первопричину ошибки в том случае, если сообщение об ошибке не слишком информативно.
В то время как логирование даёт диагностическую информацию, сообщает о том, что в приложении нужно исправить, инструменты для мониторинга приложений, вроде Sentry, могут предоставить более детальную информацию, которая способна помочь в диагностике приложения и в исправлении проблем с производительностью.
В следующем разделе мы поговорим о том, как интегрировать в Python-проект поддержку Sentry, что позволит упростить процесс отладки кода.
Интеграция Sentry в Python-проект
Установить Sentry Python SDK можно, воспользовавшись менеджером пакетов pip.
pip install sentry-sdk
После установки SDK для настройки мониторинга приложения нужно воспользоваться таким кодом:
sentry_sdk.init(
dsn="<your-dsn-key-here>",
traces_sample_rate=0.85,
)Как можно видеть — вам, для настройки мониторинга, понадобится ключ dsn. DSN расшифровывается как Data Source Name (имя источника данных). Найти этот ключ можно, перейдя в Your-Project > Settings > Client Keys (DSN).
После того, как вы запустите Python-приложение, вы можете перейти на Sentry.io и открыть панель управления проекта. Там должны быть сведения о залогированных ошибках и о других проблемах приложения. В нашем примере можно видеть сообщение об исключении, соответствующем ошибке ZeroDivisionError.
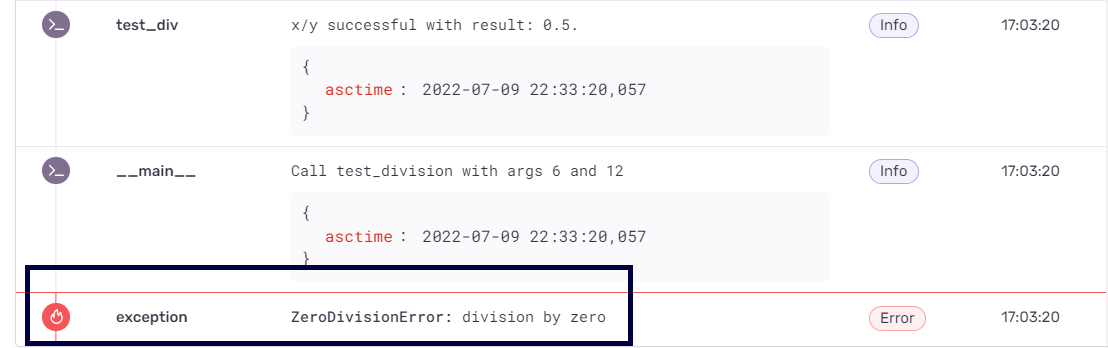
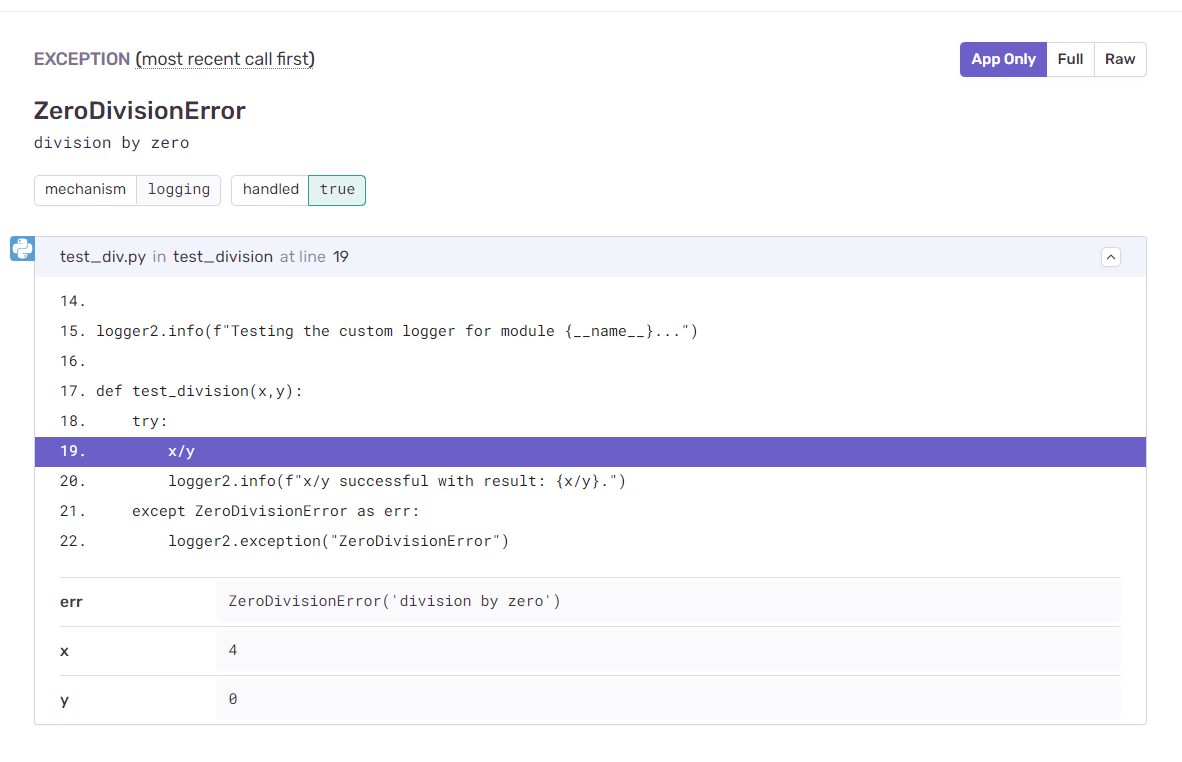
Изучая подробности об ошибке, вы можете увидеть, что Sentry предоставляет подробную информацию о том, где именно произошла ошибка, а так же — об аргументах x и y, работа с которыми привела к появлению исключения.
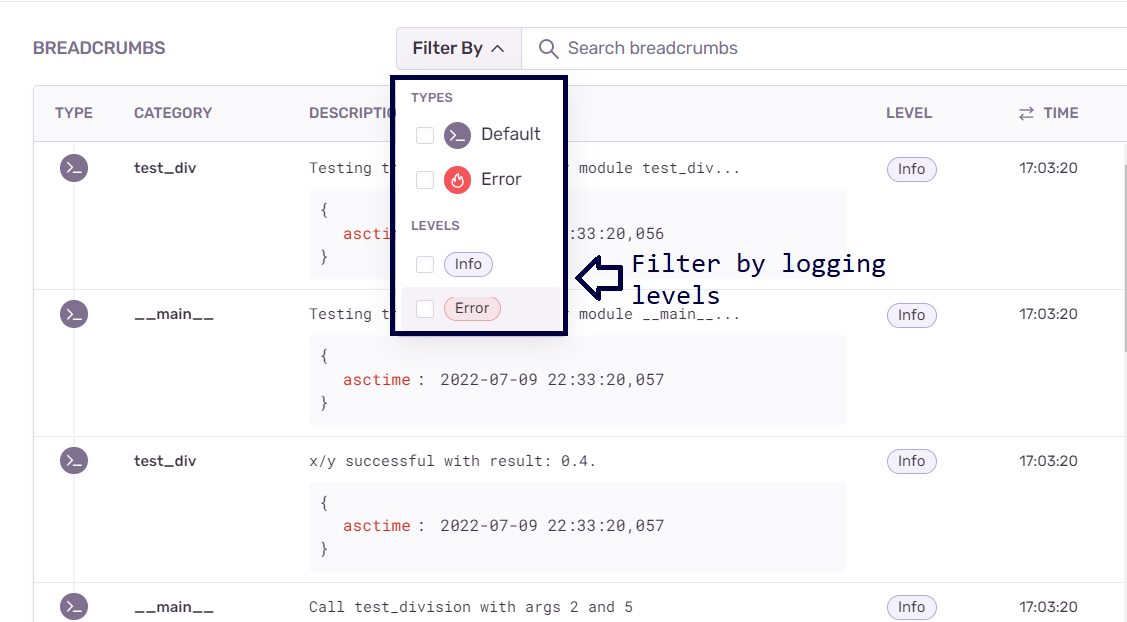
Продолжая изучение логов, можно увидеть, помимо записей уровня error, записи уровня info. Налаживая мониторинг приложения с использованием Sentry, нужно учитывать, что эта платформа интегрирована с модулем logging. Вспомните — в нашем экспериментальном проекте уровень логирования был установлен в значение info. В результате Sentry записывает все события, уровень которых соответствует info и более высоким уровням, делая это в стиле «навигационной цепочки», что упрощает отслеживание ошибок.
Sentry позволяет фильтровать записи по уровням логирования, таким, как info и error. Это удобнее, чем просмотр больших лог-файлов в поиске потенциальных ошибок и сопутствующих сведений. Это позволяет назначать решению проблем приоритеты, зависящие от серьёзности этих проблем, и, кроме того, позволяет, используя навигационные цепочки, находить источники неполадок.
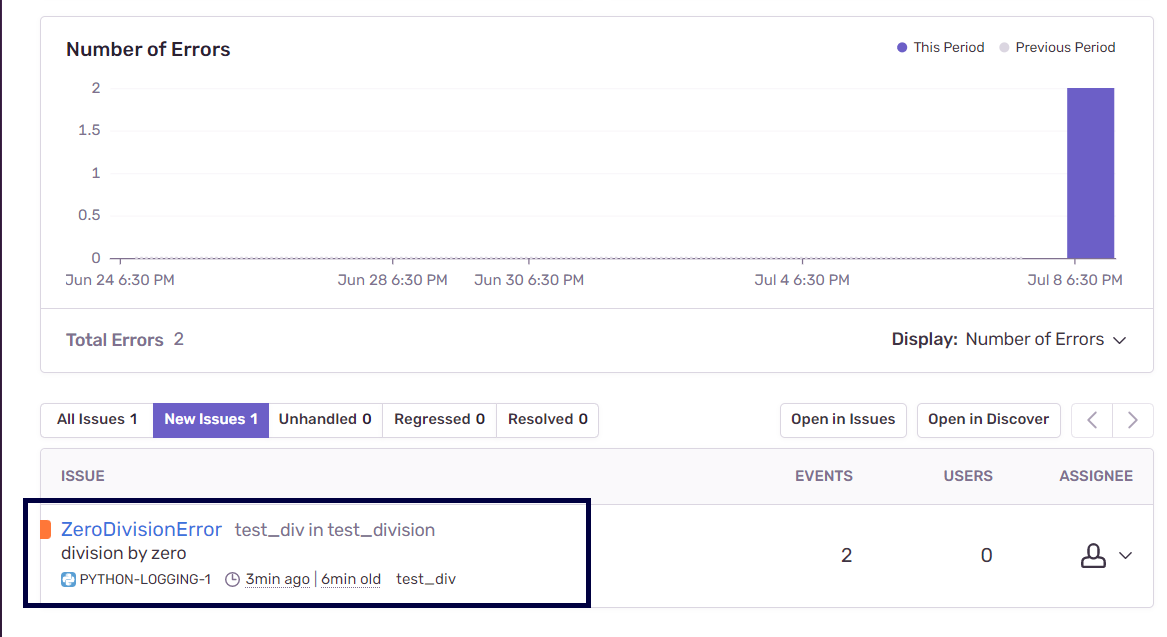
В данном примере мы рассматриваем ZeroDivisionError как исключение. В более крупных проектах, даже если мы не реализуем подобный механизм обработки исключений, Sentry автоматически предоставит диагностическую информацию о наличии необработанных исключений. С помощью Sentry, кроме того, можно анализировать проблемы с производительностью кода.
Код, использованный в данном руководстве, можно найти в этом GitHub-репозитории.
Итоги
Освоив это руководство, вы узнали о том, как настраивать логирование с использованием стандартного Python-модуля logging. Вы освоили основы настройки логгера root и пользовательских логгеров, ознакомились с рекомендациями по логированию. Вы, кроме того, узнали о том, как платформа Sentry может помочь вам в деле мониторинга ваших приложений, обеспечивая вас сведениями о проблемах с производительностью и о других ошибках, и используя при этом все возможности модуля logging.
Когда вы будете работать над своим следующим Python-проектом — не забудьте реализовать в нём механизмы логирования. И можете испытать бесплатную пробную версию Sentry.