Решение проблемы N+1 при работе с Kotlin Exposed

Предисловие
К написанию этой статьи я подошёл после продолжительного использования Kotlin Exposed в рабочих, а также персональных проектах, когда я начал анализировать генерируемые SQL запросы. В тот момент я познакомился с проблемой N+1)
Суть этой проблемы заключается в генерации ORM библиотекой дополнительных N SQL запросов для извлечения внешних сущностей вместо одного объединяющего запроса.
Что самое главное, в документации я нашёл лишь частичное решение этой проблемы. Благо Kotlin Exposed обладает открытым исходным кодом, что позволило мне самостоятельно прийти к решению.
Предварительная настройка
В качестве инструмента сборки в проекте будет использоваться Gradle с Kotlin в качестве языка скриптов. Начнём наполнять файл build.gradle.kts
Для подключения Exposed в проект необходимо добавить несколько зависимостей:
dependencies { implementation("org.jetbrains.exposed:exposed-core:$exposedVersion") implementation("org.jetbrains.exposed:exposed-jdbc:$exposedVersion") implementation("org.jetbrains.exposed:exposed-dao:$exposedVersion")}В качестве базы данных в статье будет использована легковесная H2, имеющая возможность инициализации в оперативной памяти, подробнее тут:
dependencies { testImplementation("com.h2database:h2:$h2Version")}Для контроля за генерацией SQL в тестовом проекте будут тесты, для этого необходимо подключить библиотеку JUnit:
tasks.test { useJUnitPlatform()}Подключение к базе данных
Для подключения к базе данных Kotlin Exposed предлагает два основных варианта:
- На основе экземпляра
javax.sql.DataSource - На основе
urlдля подключения к базе данных, а также дополнительных настроек (драйвер для подключения, логин/пароль), который использует под капотомjava.sql.DriverManager
В средне-крупных проектах рекомендуется первый вариант, но для тестового проекта сгодится и второй, чтобы не подключать лишних зависимостей.
Первым делом подключаемся к базе данных:
Database.connect( /* mem означает БД в оперативной памяти */ url = "jdbc:h2:mem:airport;DB_CLOSE_DELAY=-1", driver = "org.h2.Driver",)
Поскольку база данных инициализируется в оперативной памяти, она существует до первого закрытия соединения. Чтобы база данных существовала вплоть до завершения процесса, необходимо установить параметр DB_CLOSE_DELAY=-1 в строке url при подключении.
Каждый запрос в базу данных должен производится в транзакции, так что объявим top-level функцию для этого
fun <T> loggedTransaction(statement: Transaction.() -> T) = transaction { addLogger(StdOutSqlLogger) statement() }Обратите внимание, мы не указываем никаких ссылок на базу данных, так как по умолчанию при подключении в Database.connect созданное соединение сохраняется в экземпляреTransactionManager
Для логирования генерируемых SQL запросов установим отображение в стандартном потоке вывода с помощью addLogger(StdOutSqlLogger)
Более подробнее про подключение к базе данных можно ознакомится тут
Предметная область
В качестве предметной области я решил выбрать аэропорт, а именно смоделировать расписание авиарейсов.
class Flight( private val airplane: Airplane, private val toAirport: Airport,) { override fun toString(): String = "Рейс на [$airplane] в [$toAirport]"}class Airplane( private val yearReleased: Int, private val firm: String, private val model: String,) { override fun toString(): String = "Самолёт $firm $model $yearReleased года выпуска"}class Airport( private val country: String, private val city: String, private val iataCode: String,) { override fun toString(): String = "Аэропорт в н.п. $city, $country ($iataCode)"}На основе вышеперечисленных моделей создадим таблицы, ссылающиеся друг на друга:
object FlightTable : IntIdTable("flights") { val airplane = reference("airplane_id", AirplaneTable, onDelete = ReferenceOption.CASCADE) val toAirport = reference("to_airport_id", AirportTable, onDelete = ReferenceOption.CASCADE)}object AirportTable : IntIdTable("airports") { val iataCode = varchar("iata_code", 32) val country = varchar("country", 128) val city = varchar("city", 128)}object AirplaneTable : IntIdTable("airplanes") { val firm = varchar("firm", 128) val yearReleased = integer("year_released") val model = varchar("model", 128)}А также сущности. Если не знакомы с созданием сущностей, рекомендую ознакомиться
class FlightEntity(id: EntityID<Int>) : IntEntity(id) { companion object : IntEntityClass<FlightEntity>(FlightTable) val airplane by AirplaneEntity referencedOn FlightTable.airplane val toAirport by AirportEntity referencedOn FlightTable.toAirport fun toFlight(): Flight = Flight( airplane = airplane.toAirplane(), toAirport = toAirport.toAirport() )}class AirplaneEntity(id: EntityID<Int>): IntEntity(id) { companion object : IntEntityClass<AirplaneEntity>(AirplaneTable) val yearReleased by AirplaneTable.yearReleased val firm by AirplaneTable.firm val model by AirplaneTable.model fun toAirplane() = Airplane(yearReleased, firm, model)}class AirportEntity(id: EntityID<Int>) : IntEntity(id) { companion object : IntEntityClass<AirportEntity>(AirportTable) val country by AirportTable.country val city by AirportTable.city val iataCode by AirportTable.iataCode fun toAirport() = Airport(country, city, iataCode)}Для наглядности: ER-диаграмма схемы в базе данных:
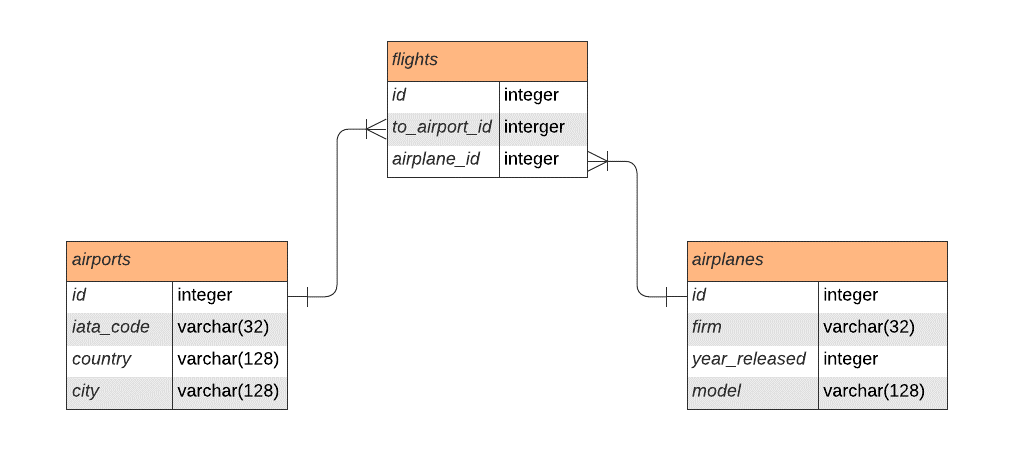
Также наполним таблицы тестовыми данными:
/* 1 */val airportID1 = AirportTable.insertAndGetId { it[iataCode] = "LED" it[country] = "Russia" it[city] = "St.Petersburg"}val planeID1 = AirplaneTable.insertAndGetId { it[yearReleased] = 2015 it[firm] = "Airbus" it[model] = "A320"}FlightTable.insert { it[toAirport] = airportID1 it[airplane] = planeID1}/* 2 */val airportID2 = AirportTable.insertAndGetId { it[iataCode] = "VKO" it[country] = "Russia" it[city] = "Moscow"}val planeID2 = AirplaneTable.insertAndGetId { it[yearReleased] = 2008 it[firm] = "Boeing" it[model] = "747"}FlightTable.insert { it[toAirport] = airportID2 it[airplane] = planeID2}/* 3 */val airportID3 = AirportTable.insertAndGetId { it[iataCode] = "DME" it[country] = "Russia" it[city] = "Moscow"}val planeID3 = AirplaneTable.insertAndGetId { it[yearReleased] = 2008 it[firm] = "Sukhoi" it[model] = "Superjet 100"}FlightTable.insert { it[toAirport] = airportID3 it[airplane] = planeID3}Когда все готово к созданию репозитория, рассмотрим запрос, который мы будем моделировать: необходимо найти все рейсы, направляющиеся в страну Россия на самолётах, выпущенных не позже 2011 года.
interface FlightRepository { fun getFlightsToCountryByAirplaneYoungerThan( destinationCountry: String, youngerThanYear: Int ): List<Flight>}Из запроса очевидно, что для его выполнения необходимо обращение к
связанным сущностям. Так что приступим
Наивный репозиторий
Из документации становится ясно, что библиотека предлагает два подхода для работы с базой данных:
Поскольку проблема N+1 свойственна подходу с ORM, будем использовать Exposed DAO
Из методов поиска у базового класса Entity есть несколько методов:
getдля получения сущности по ID или ошибки при отсутствии таковойfindByIdдля получения сущности по ID илиnullпри отсутствии таковойfindдля произвольного поиска, но с использованиемSqlExpressionBuilderallдля получения всех сущностей
class PlainDaoFlightRepository : FlightRepository { override fun getFlightsToCountryByAirplaneYoungerThan( destinationCountry: String, youngerThanYear: Int ): List<Flight> = loggedTransaction { FlightEntity.find { /* AirportTable.country.lowerCase() eq destinationCountry.lowercase() and (AirplaneTable.yearReleased less youngerThanYear) */ Op.nullOp() } FlightEntity.all().filter { flightEntity -> val targetCityMatches = flightEntity.toAirport.country.equals(destinationCountry, ignoreCase = true) val isYoungerThanYear = flightEntity.airplane.yearReleased <= youngerThanYear targetCityMatches && isYoungerThanYear }.map(FlightEntity::toFlight) } override fun toString(): String = "Наивный репозиторий, работающий через Exposed DAO"}При попытке использовать метод find с условием, ссылающимся на внешнюю таблицу, вылетает следующее исключение:
org.jetbrains.exposed.exceptions.ExposedSQLException: org.h2.jdbc.JdbcSQLSyntaxErrorException: Столбец "AIRPORTS.COUNTRY" не найден
Всё дело в том, что по умолчанию в SqlExpressionBuilder есть доступ только к столбцам таблицы сущности, на которой вызывается find
Пока будем использовать all и вернемся к решению этой проблемы позже
Выполнив запрос с фильтрацией всех сущностей, получаем следующий листинг сгенерированных SQL запросов:
SQL: SELECT FLIGHTS.ID, FLIGHTS.AIRPLANE_ID, FLIGHTS.TO_AIRPORT_ID FROM FLIGHTSSQL: SELECT AIRPORTS.ID, AIRPORTS.IATA_CODE, AIRPORTS.COUNTRY, AIRPORTS.CITY FROM AIRPORTS WHERE AIRPORTS.ID = 1SQL: SELECT AIRPLANES.ID, AIRPLANES.FIRM, AIRPLANES.YEAR_RELEASED, AIRPLANES.MODEL FROM AIRPLANES WHERE AIRPLANES.ID = 1SQL: SELECT AIRPORTS.ID, AIRPORTS.IATA_CODE, AIRPORTS.COUNTRY, AIRPORTS.CITY FROM AIRPORTS WHERE AIRPORTS.ID = 2SQL: SELECT AIRPLANES.ID, AIRPLANES.FIRM, AIRPLANES.YEAR_RELEASED, AIRPLANES.MODEL FROM AIRPLANES WHERE AIRPLANES.ID = 2SQL: SELECT AIRPORTS.ID, AIRPORTS.IATA_CODE, AIRPORTS.COUNTRY, AIRPORTS.CITY FROM AIRPORTS WHERE AIRPORTS.ID = 3SQL: SELECT AIRPLANES.ID, AIRPLANES.FIRM, AIRPLANES.YEAR_RELEASED, AIRPLANES.MODEL FROM AIRPLANES WHERE AIRPLANES.ID = 3
Типичная проблема N+1, когда N связанных сущностей подгружаются лениво по мере обращения к ним.
Но, казалось бы, у нас есть список всех сущностей, а значит можно понять, какие внешние сущности фигурируют в этом списке, чтобы подгружать их не последовательно, а сразу пачкой.
Решение из документации
В документации для этого есть отдельный раздел
Дописав, как указано в документации, загрузку внешних сущностей после вызова all следующим образом:
package com.strongmandrew.repositoryimport com.strongmandrew.domain.Flightimport com.strongmandrew.entity.FlightEntityimport com.strongmandrew.transaction.loggedTransactionimport org.jetbrains.exposed.dao.withclass MediumDaoFlightRepository : FlightRepository { override fun getFlightsToCountryByAirplaneYoungerThan( destinationCountry: String, youngerThanYear: Int ): List<Flight> = loggedTransaction { FlightEntity.all() .with(FlightEntity::toAirport, FlightEntity::airplane) /* !!! */ .filter { flightEntity -> val targetCityMatches = flightEntity.toAirport.country.equals(destinationCountry, ignoreCase = true) val isYoungerThanYear = flightEntity.airplane.yearReleased <= youngerThanYear targetCityMatches && isYoungerThanYear }.map(FlightEntity::toFlight) } override fun toString(): String = "Наивный репозиторий, работающий с Exposed DAO, но группирующий запросы к связаным сущностям"}Обратите внимание: мгновенную (eager) загрузку внешних сущностей можно использовать как на списке методомwith, так и на отдельной сущности методомload
Получаем меньшее кол-во сгенерированных запросов:
SQL: SELECT FLIGHTS.ID, FLIGHTS.AIRPLANE_ID, FLIGHTS.TO_AIRPORT_ID FROM FLIGHTSSQL: SELECT AIRPLANES.ID, AIRPLANES.FIRM, AIRPLANES.YEAR_RELEASED, AIRPLANES.MODEL FROM AIRPLANES WHERE AIRPLANES.ID IN (1, 2, 3)SQL: SELECT AIRPORTS.ID, AIRPORTS.IATA_CODE, AIRPORTS.COUNTRY, AIRPORTS.CITY FROM AIRPORTS WHERE AIRPORTS.ID IN (1, 2, 3)SQL: SELECT FLIGHTS.ID, FLIGHTS.AIRPLANE_ID, FLIGHTS.TO_AIRPORT_ID FROM FLIGHTS
Отлично, запросов стало меньше, но по какой-то причине запрос к таблице FLIGHTS выполнился дважды на 1 и 4 строках.
В поисках ответа обратимся к исходникам: для начала проверим что делает all
open fun all(): SizedIterable<T> = wrapRows(table.selectAll().notForUpdate())
Здесь мы видим, что объект класса Query – результат selectAll заворачивается в функцию wrapRows
Важно, что вызов selectAll не создаёт SQL запрос, а лишь создаёт обёртку в виде Query для последующего вызова. Переходим далее к реализации wrapRows
fun wrapRows(rows: SizedIterable<ResultRow>): SizedIterable<T> = rows mapLazy { wrapRow(it)}Видим перед собой неизвестную функцию mapLazy
infix fun <T, R> SizedIterable<T>.mapLazy(f: (T) -> R): SizedIterable<R> { val source = this return object : SizedIterable<R> { override fun limit(n: Int, offset: Long): SizedIterable<R> = source.copy().limit(n, offset).mapLazy(f) override fun forUpdate(option: ForUpdateOption): SizedIterable<R> = source.copy().forUpdate(option).mapLazy(f) override fun notForUpdate(): SizedIterable<R> = source.copy().notForUpdate().mapLazy(f) override fun count(): Long = source.count() override fun empty(): Boolean = source.empty() override fun copy(): SizedIterable<R> = source.copy().mapLazy(f) override fun orderBy(vararg order: Pair<Expression<*>, SortOrder>) = source.orderBy(*order).mapLazy(f) @Suppress("IteratorNotThrowingNoSuchElementException") override operator fun iterator(): Iterator<R> { val sourceIterator = source.iterator() return object : Iterator<R> { override operator fun next(): R = f(sourceIterator.next()) override fun hasNext(): Boolean = sourceIterator.hasNext() } } }}Интересно, что итератор первым делом обращается к итератору ресивера mapLazy, коим в нашем случае является объект класса Query, созданный в результате вызова selectAll
Значит следующим этапом необходимо проверить, как Query создаёт свой итератор.
override fun iterator(): Iterator<ResultRow> { val resultIterator = ResultIterator(transaction.exec(queryToExecute)!!) return if (transaction.db.supportsMultipleResultSets) { resultIterator } else { Iterable { resultIterator }.toList().iterator() }}Кажется, проблема найдена: для создания итератора Query каждый раз выполняет запрос в базу данных на 2 строке.
- Первый сгенерированный запрос к таблице
FLIGHTSпроизошёл при вызовеwith, который в начале своего тела вызываетtoList, вызывая тем самым итераторQuery - Второй запрос произошёл при вызове
filter, так какwithхоть и создаёт список, но дальше его не возвращает и следующий метод в цепочке опять обращается к итераторуQuery - Отработанный
filterвозвращает уже наполненный список. Именно по этой причине на вызовеmapне было сгенерировано третьего SQL запроса: он вызывался уже НЕ на ленивом списке.
Для решения этой проблемы достаточно сразу на результате вызова all вызвать toList, чтобы последующие методы работали уже с готовым списком
/* ... */FlightEntity.all().toList() /* !!! */ .with(FlightEntity::toAirport, FlightEntity::airplane) .filter { flightEntity -> val targetCityMatches = flightEntity.toAirport.country.equals(destinationCountry, ignoreCase = true) val isYoungerThanYear = flightEntity.airplane.yearReleased < youngerThanYear targetCityMatches && isYoungerThanYear}.map(FlightEntity::toFlight)/* ... */В итоге нам удалось избавиться от повторного SQL запроса (которых могло быть X, где X это количество вызовов методов на исходном ленивом итераторе)
SQL: SELECT FLIGHTS.ID, FLIGHTS.AIRPLANE_ID, FLIGHTS.TO_AIRPORT_ID FROM FLIGHTSSQL: SELECT AIRPLANES.ID, AIRPLANES.FIRM, AIRPLANES.YEAR_RELEASED, AIRPLANES.MODEL FROM AIRPLANES WHERE AIRPLANES.ID IN (1, 2, 3)SQL: SELECT AIRPORTS.ID, AIRPORTS.IATA_CODE, AIRPORTS.COUNTRY, AIRPORTS.CITY FROM AIRPORTS WHERE AIRPORTS.ID IN (1, 2, 3)
Совмещение DSL и DAO
Описанная выше оптимизация работы с DAO хоть и уменьшила кол-во генерируемых SQL запросов, но все равно ещё далеко от идеала.
Во-первых, что, если связанных сущностей в базе данных будет не 3, как в нашем случае, а, допустим, 3_000_000. В данном случае уже кажется не таким целесообразным запрашивать их все разом для дальнейшей фильтрации и хранить в памяти: with внутри себя кэширует связанные сущности.
В таком случае привлекательной выглядит возможность фильтрации сущностей средствами SQL, и в этом случае придётся обратиться к DSL с последующей конвертацией в сущности методом wrapRow
Объединить несколько таблиц и вместе их отфильтровать в синтаксисе SQL можно запросом с JOIN, которые в Exposed DSL выражаются в виде функций leftJoin, rightJoin, innerJoin и пр.
По сути они расширяют ColumnSet – список столбцов, которые далее будут участвовать в запросе, а это значит, что можно смело обращаться к внешним таблицам внутри select (запомним, это пригодится для следующей оптимизации DAO)
Таким образом, листинг репозитория, совмещающего DSL и DAO будет выглядеть следующим образом:
class MixedDaoDslFlightRepository : FlightRepository { override fun getFlightsToCountryByAirplaneYoungerThan( destinationCountry: String, youngerThanYear: Int ): List<Flight> = loggedTransaction { FlightTable.innerJoin(AirportTable).innerJoin(AirplaneTable).selectAll().where { AirportTable.country.lowerCase() eq destinationCountry.lowercase() }.andWhere { AirplaneTable.yearReleased lessEq youngerThanYear }.map { row -> FlightEntity.wrapRow(row).toFlight() } } override fun toString(): String = "Репозиторий, комбинирующий работу с Exposed DAO и DSL, а также кэширующий связанные сущности"}На выходе получаем не совсем ясную картину сгенерированных SQL запросов:
SQL: SELECT FLIGHTS.ID, FLIGHTS.AIRPLANE_ID, FLIGHTS.TO_AIRPORT_ID, AIRPORTS.ID, AIRPORTS.IATA_CODE, AIRPORTS.COUNTRY, AIRPORTS.CITY, AIRPLANES.ID, AIRPLANES.FIRM, AIRPLANES.YEAR_RELEASED, AIRPLANES.MODEL FROM FLIGHTS INNER JOIN AIRPORTS ON AIRPORTS.ID = FLIGHTS.TO_AIRPORT_ID INNER JOIN AIRPLANES ON AIRPLANES.ID = FLIGHTS.AIRPLANE_ID WHERE (LOWER(AIRPORTS.COUNTRY) = 'russia') AND (AIRPLANES.YEAR_RELEASED <= 2011)SQL: SELECT AIRPLANES.ID, AIRPLANES.FIRM, AIRPLANES.YEAR_RELEASED, AIRPLANES.MODEL FROM AIRPLANES WHERE AIRPLANES.ID = 2SQL: SELECT AIRPORTS.ID, AIRPORTS.IATA_CODE, AIRPORTS.COUNTRY, AIRPORTS.CITY FROM AIRPORTS WHERE AIRPORTS.ID = 2SQL: SELECT AIRPLANES.ID, AIRPLANES.FIRM, AIRPLANES.YEAR_RELEASED, AIRPLANES.MODEL FROM AIRPLANES WHERE AIRPLANES.ID = 3SQL: SELECT AIRPORTS.ID, AIRPORTS.IATA_CODE, AIRPORTS.COUNTRY, AIRPORTS.CITY FROM AIRPORTS WHERE AIRPORTS.ID = 3
Казалось бы, внутри map мы имеем ResultRow, в котором есть поля для всех связанных таблиц. Зачем Exposed обращается к связанным таблицам отдельными запросами?
В поисках ответа вновь обращаемся к исходному коду: начнём с делегатов, которыми FlightEntity получает связанные сущности. Для этого кликнем Ctrl + B по ключевому слову by
operator fun <REF : Comparable<REF>, RID : Comparable<RID>, T : Entity<RID>> Reference<REF, RID, T>.getValue( o: Entity<ID>, desc: KProperty<*> ): T { val outOfTransaction = TransactionManager.currentOrNull() == null if (outOfTransaction && reference in referenceCache) return getReferenceFromCache(reference) return executeAsPartOfEntityLifecycle { val refValue = reference.getValue(o, desc) when { refValue is EntityID<*> && reference.referee<REF>() == factory.table.id -> { factory.findById(refValue.value as RID).also { storeReferenceInCache(reference, it) } } else -> { // @formatter:off factory.findWithCacheCondition({ reference.referee!!.getValue(this, desc) == refValue }) { reference.referee<REF>()!! eq refValue }.singleOrNull()?.also { storeReferenceInCache(reference, it) } // @formatter:on } } ?: error("Cannot find ${factory.table.tableName} WHERE id=$refValue") } }В коде мы видим, что на 8 строке происходит получение некого refValue методом getValue
operator fun <T> Column<T>.getValue(o: Entity<ID>, desc: KProperty<*>): T = lookup()
Даже не заглядывая дальше внутрь lookup видно, что ресивером этой функции является Column и переданные аргументы касательно сущности никуда дальше не попадают.
Это означает, что для внешней сущности мы получим только её ID, по которому далее будет осуществляться поиск
Так и есть, на 10 строке мы наблюдаем проверку на то, является ли это значение внешним ключом с последующим поиском. Заглянем внутрь поиска в методе findById
open fun findById(id: EntityID<ID>): T? = testCache(id) ?: find { table.id eq id }.firstOrNull()Здесь-то всё встаёт на свои места. Прежде чем делать отдельный запрос в базу данных, сущность ищется в кэше. Вспоминаем, что для FlightEntity мы вызывали метод wrapRow
Углубившись в его реализацию, видим, что после создание сущности, она помещается в кэш
fun wrap(id: EntityID<ID>, row: ResultRow?): T { val transaction = TransactionManager.current() return transaction.entityCache.find(this, id) ?: createInstance(id, row).also { new -> new.klass = this new.db = transaction.db warmCache().store(this, new) /* кэширование */ } }Это значит, что нам ничего не мешает кэшировать все связанные сущности на основе полученного ResultRow
/* ... */FlightTable.innerJoin(AirportTable).innerJoin(AirplaneTable).selectAll().where { AirportTable.country.lowerCase() eq destinationCountry.lowercase()}.andWhere { AirplaneTable.yearReleased lessEq youngerThanYear}.map { row -> AirplaneEntity.wrapRow(row) /* кэширование */ AirportEntity.wrapRow(row) /* кэширование */ FlightEntity.wrapRow(row).toFlight()}/* ... */В результате всех оптимизацией, получаем весьма впечатляющий результат в виде одного (!) единственного запроса
SQL: SELECT FLIGHTS.ID, FLIGHTS.AIRPLANE_ID, FLIGHTS.TO_AIRPORT_ID, AIRPORTS.ID, AIRPORTS.IATA_CODE, AIRPORTS.COUNTRY, AIRPORTS.CITY, AIRPLANES.ID, AIRPLANES.FIRM, AIRPLANES.YEAR_RELEASED, AIRPLANES.MODEL FROM FLIGHTS INNER JOIN AIRPORTS ON AIRPORTS.ID = FLIGHTS.TO_AIRPORT_ID INNER JOIN AIRPLANES ON AIRPLANES.ID = FLIGHTS.AIRPLANE_ID WHERE (LOWER(AIRPORTS.COUNTRY) = 'russia') AND (AIRPLANES.YEAR_RELEASED <= 2011)
Несмотря на то, что мы смешали два подхода DSL и DAO, на выходе мы получаем сущности DAO, которые легко конвертируются в доменные модели
Необходимо помнить, что не во всех случаях в ResultRow будут находиться поля связанных сущностей. Например, в случае leftJoin или rightJoin
Поэтому перед кэшированием связанной сущности может понадобиться дополнительная проверка
.map { row -> if (row.getOrNull(AirplaneTable.id) != null) { AirplaneEntity.wrapRow(row) /* кэширование */ } AirportEntity.wrapRow(row) /* кэширование */ FlightEntity.wrapRow(row).toFlight()}Оптимизация фасадом
Думаю, из заголовка понятно, что теоретически всю эту цепочку innerJoin можно спрятать за фасадом Entity
В первой версии репозитория нам не удалось обратиться к связанным сущностям в методе find
Давайте разберёмся, почему так произошло:
fun find(op: Op<Boolean>): SizedIterable<T> { warmCache() return wrapRows(searchQuery(op))}В знакомый нам метод wrapRows заворачивается результат метода searchQuery
open val dependsOnTables: ColumnSet get() = tableopen val dependsOnColumns: List<Column<out Any?>> get() = dependsOnTables.columnsopen fun searchQuery(op: Op<Boolean>): Query = dependsOnTables.select(dependsOnColumns).where { op }.setForUpdateStatus()На самом деле, вся проблема заключалась в том, что по умолчанию find ищет только по столбцам таблицы, поверх которой создана Entity
То есть это означает, что при переопределении dependsOnTables метод find перестанет падать с ошибкой, но это ещё не всё.
class FlightEntity(id: EntityID<Int>) : IntEntity(id) { companion object : IntEntityClass<FlightEntity>(FlightTable) { override val dependsOnTables: ColumnSet = FlightTable.innerJoin(AirplaneTable).innerJoin(AirportTable) } val airplane by AirplaneEntity referencedOn FlightTable.airplane val toAirport by AirportEntity referencedOn FlightTable.toAirport fun toFlight(): Flight = Flight( airplane = airplane.toAirplane(), toAirport = toAirport.toAirport() )}Ещё до выполнения кода понятно, что избавившись от ошибки при поиске по связанным таблицам, мы не избавимся от проблемы N+1, так как внутри wrapRows кэширование ленивое.
Поскольку метод find является финальным, его нельзя переопределить, значит напишем свою версию find для оптимального кэширования:
open class EagerSearchEntityClass<ID : Comparable<ID>, out E : Entity<ID>>(table: IdTable<ID>) : EntityClass<ID, E>(table) { fun eagerFind( vararg foreignEntities: EntityClass<*, *>, op: SqlExpressionBuilder.() -> Op<Boolean>, ): SizedIterable<E> { warmCache() val entitiesBySearch = searchQuery(SqlExpressionBuilder.op()).map { resultRow -> foreignEntities.forEach { entity -> entity.wrapRow(resultRow) } this.wrapRow(resultRow) } return SizedCollection(entitiesBySearch) }}Унаследуемся от этой реализации в классе FlightEntity
class FlightEntity(id: EntityID<Int>) : IntEntity(id) { companion object : EagerSearchEntityClass<Int, FlightEntity>(FlightTable) { override val dependsOnTables: ColumnSet = FlightTable.innerJoin(AirplaneTable).innerJoin(AirportTable) }/* ... */Новая версия репозитория теперь выглядит следующим образом:
class ImprovedDaoFlightRepository : FlightRepository { override fun getFlightsToCountryByAirplaneYoungerThan( destinationCountry: String, youngerThanYear: Int ): List<Flight> = loggedTransaction { FlightEntity.eagerFind(AirportEntity, AirplaneEntity) { AirportTable.country.lowerCase() eq destinationCountry.lowercase() and (AirplaneTable.yearReleased lessEq youngerThanYear) }.map(FlightEntity::toFlight) } override fun toString(): String = "Репозиторий с переопределёнными методами поиска связанных сущностей в Entity-классе"}Условия, ссылающиеся на внешние таблицы теперь не упадут с ошибкой, поскольку свойство dependsOnTables переопределено в FlightEntity
Помимо этого, все связанные сущности, перечисленные в аргументах, будут кэшированы, что поможет избежать проблемы N+1.
В конце концов, количество сгенерированных SQL запросов не увеличилось, а код стал более читаемым:
SQL: SELECT FLIGHTS.ID, FLIGHTS.AIRPLANE_ID, FLIGHTS.TO_AIRPORT_ID, AIRPLANES.ID, AIRPLANES.FIRM, AIRPLANES.YEAR_RELEASED, AIRPLANES.MODEL, AIRPORTS.ID, AIRPORTS.IATA_CODE, AIRPORTS.COUNTRY, AIRPORTS.CITY FROM FLIGHTS INNER JOIN AIRPLANES ON AIRPLANES.ID = FLIGHTS.AIRPLANE_ID INNER JOIN AIRPORTS ON AIRPORTS.ID = FLIGHTS.TO_AIRPORT_ID WHERE (LOWER(AIRPORTS.COUNTRY) = 'russia') AND (AIRPLANES.YEAR_RELEASED <= 2011)
Однако у такой реализации есть одна существенная проблема: мы привязываемся к свойству dependsOnTables при выполнении запроса.
Поэтому с текущей реализацией не получится динамически изменять тип объединяющих запросов, к примеру, комбинировать произвольные типы JOIN.
При такой необходимости, можно внести аргумент типа ColumnSet в аргументы функции со значением по умолчанию в виде dependsOnTables
При этом, необходимо будет проверять наличие внешних сущностей в результирующем ResultRow
open class EagerSearchEntityClass<ID : Comparable<ID>, out E : Entity<ID>>(table: IdTable<ID>) : EntityClass<ID, E>(table) { fun eagerFind( vararg foreignEntities: EntityClass<*, *>, columnSet: ColumnSet = dependsOnTables, /* возможность изменить выборку */ op: SqlExpressionBuilder.() -> Op<Boolean>, ): SizedIterable<E> { warmCache() val entitiesBySearch = searchByColumnSet(columnSet, SqlExpressionBuilder.op()).map { resultRow -> foreignEntities.forEach { entity -> /* кэширование только при наличии */ if (resultRow.getOrNull(entity.table.id) != null) { entity.wrapRow(resultRow) } } this.wrapRow(resultRow) } return SizedCollection(entitiesBySearch) } open fun searchByColumnSet(columnSet: ColumnSet, op: Op<Boolean>): Query = columnSet.selectAll().where(op)}Заключение
Подводя итоги этой статьи, мы копнули глубже в исходный код библиотеки Kotlin Exposed и в очередной раз убедились в том, что всё всегда нужно проверять самостоятельно, и даже документация не всегда сможет ответить на все ваши вопросы.
Конечно, это актуально только для проектов с открытым исходным кодом.
Надеюсь, что после прочтения этой статьи ваши репозитории на Kotlin Exposed станут ещё эффективнее, а ваши отношения с администраторами баз данных более прозрачными)
Ознакомиться с тестовым проектом из статьи можно по ссылке