Электронные книги? Аудиокниги? Смешать, но не взбалтывать
На связи Юрий Плотников из Ростелекома. Мы по прежнему занимается разработкой нашего семейства продуктов "Лукоморье", ключевым из которых является "Яга". С последнего времени прошло много изменений - мы выпустили несколько релизов, у нас появились (пока наши внутренние) реальные пользователи.
Однако, жизнь состоит не только из этого, иногда мы ходим в отпуск, а это то самое время, когда можно "уйти с работы от большого компьютера и сесть дома за свой уютный ноутбук".
Поэтому сегодняшняя статья - о хобби. И поговорим об одной из любимых тем - читалка и все, что с ней связано.
Введение получилось как в том самом анекдоте, когда студент сельхозинститута выучил только билет про блох и все вопросы к нему сводил к ответам о блохах. И да, о блохах мы и поговорим )
Введение
Напомню, что есть предыдущий цикл статей (1, 2, 3) и для полноты картины есть смысл начать с них. Но если вкратце - наша читалка KnownReader, основанная на кодовой базе CoolReader, со своими многочисленными "плюшками" уже давно стала для меня эдаким полигоном для изучения разных фишек, связанных с мобильной разработкой, например:
- Геолокация и определение расстояний (так родилась функция "в наушниках в транспорте")
- Акселерометр и гироскоп (функция "листание наклоном")
- Словари, словари и еще раз словари
- И много других разных
Не скажу, что к проекту CoolReader сейчас проявляется жгучий интерес, тем более программа в очередной раз заброшена и не обновляется (хотя продолжают жить ее последователи - мы, coolreader-ng, koreader), однако периодически появляются интересные люди, которые привносят свои идеи и, как правило, делающие свои сборки. И тут есть пара примеров:
- Один чувак сделал модификацию для VR-очков (однако оценить его работу я не могу)
- Про вторую фишку, собственно эта статья
Как мне кажется, читающие люди склонны к классификациям, с них и начнем:
И начнем мы с классификации сюжетов книг.
Нет, на самом деле классификация сюжетов книг для повествования не сильно нужна, поэтому просто опубликую несколько интересных находок и рассуждений.
Прекрасное - от Станислава Лема:

"Великий аргентинский писатель Хорхе Луис Борхес потряс в свое время литературный мир, заявив, что существует всего четыре типа сюжетов. И в эти четыре книги укладывается абсолютно любая книга из тех, что существовали когда-то или появятся в будущем. "Историй всего четыре. И сколько бы времени нам ни осталось, мы будем пересказывать их - в том или ином виде", - так завершается его экстремально короткое эссе под названием "Четыре цикла":
- История об осажденном городе, который штурмуют и обороняют
- История о возвращении
- История о поиске
- История о самоубийстве бога
Процитирую также современных писателей, Lleo:
- «Выживание» (или «Я теряю мир»)
- «Возвращение» (или «Мир потерял меня»)
- «Волшебный друг» (или «Магия в моем мире»)
- «Особенный» (или «Магия во мне»)
- «Избранный» (или «Заговор переодетого мира»)
- «За того парня» (или «Заговор переодетого меня»)
Собственно, немного отвлеклись на сюжеты, пойдем классифицировать читателей, это нам пригодится
Классификация читателей
- Люди
- Не читают книги. С этими все более менее понятно - "а ещё я в неё ем"
- Читают книги. С этими как раз поработаем )
- Читают только бумажные книги. Воображение рисует тут либо людей возрастных, либо эдаких хипстеров со смузи и фотоаппаратом "зенит". В реальности это не так, так как даже среди знакомых есть вполне себе прогрессивные и адекватные люди, предпочитающие бумажную страницу электронной
- Читают электронные книги. Это наша целевая аудитория. Ну, что здесь можно сказать? Выбор понятен и более чем адекватен - современные устройства, качественное изображение, много книг, тонны дополнительных возможностей - шрифты, размер, поиск, словари
- На eink читалках. Самый правильный выбор, изображение максимально приближено к бумажному, есть подсветка, глаза не устают. Личное предпочтение здесь - всецело на стороне Onyx - все-таки, полноценный Android дает массу преимуществ. В последних моделях используются достаточно свежие версии (раньше долгое время был 4.4). Отмечу, что представители российского офиса Onyx периодически предоставляют нам книги для разработки и тестирования.
- На смартфонах. Для меня этот вариант удобнее, так как носить с собой и читалку и смарфон - не хочется. Да и все быстрее и все же удобнее - есть в eink своя медлительность. На раскладных экранах samsung fold смотрится вообще роскошно (пришлось немного доработать режим отображения двух страниц). Есть интересные варианты eink сматрфонов (в т.ч. и цветные и с двумя экранами, может быть когда нибудь попробую - интересно)
- Слушают аудиокниги. Ну а действительно - почему бы и нет? Главное же, восприятие произведения, а не способ - глазами или ушами. К сожалению, лично я так и не привык (хоть и одобряю). Над какими то страницами хочется задержаться подольше, подумать. Прочтение диктором не всегда совпадает "по ощущениям" с собственным, "внутренним"
- Со специально записанной озвучкой. Т.е. книгу читает живой человек, нередко известный актер. Это, конечно, максимально качественный вариант, но озвучка есть далеко не для каждой книги, поэтому:
- Со сгенерированной озвучкой, т.е. книгу читает "механический голос" (tts, text-to-speech). Как по мне - такой вариант вызывает отторжение, но на самом деле очень многие пользуются. Есть старые, проверенные движки озвучки, типа RHVoice и вообще на эту тему есть много материалов. В последнее время наметился мощный тренд в сторону нейронок, Алисы и т.д. и, как мне кажется, этот вариант и победит. Классический TTS у нас есть, была мысль прикрутить и Алису (через Яндекс.Облако), но этот путь достаточно непрост, а главное ещё и дорогой (я когда-то рассчитывал и у меня получалось, что за озвучку, например, двух томов Дон Кихота читатель заплатит около 400 рублей). Понятно, что сам Яндекс в своей читалке может себе позволить свой же движок озвучки, но - мы не Яндекс. Если знаете бесплатные или даже оффлайновые движки озвучки - приходите в сообщения. Что то я находил сам (1, 2), но пока изучил только бегло, на самом деле очень любопытно (и даже с примерами кода), но, по ощущениям, для наших целей не вполне пригодно (посмотрел примеры озвучки - без специальной расстановки ударений звучит плохо, с ударениями - вполне достойно).
Идея
А что если совместить? - подумал пользователь github'а с ником teleshoes (по имени Elliot Wolk).
Ну и собственно он сделал доработку в своем форке CoolReader (а также оформил PR). В сам CoolReader его вряд ли вольют, но нам в KnownReader как раз ничего не мешает.
Самое время рассказать об идее, но для начала все таки, для полной ясности проговорим как работает классический tts (или любой движок-озвучиватель):
- Пользователь включает озвучку (на любой странице)
- Выделяется первое предложение
- Оно отправляется в движок проговаривателя
- Движок его произносит
- Выделяется следующее предложение
- Уходим на п.3
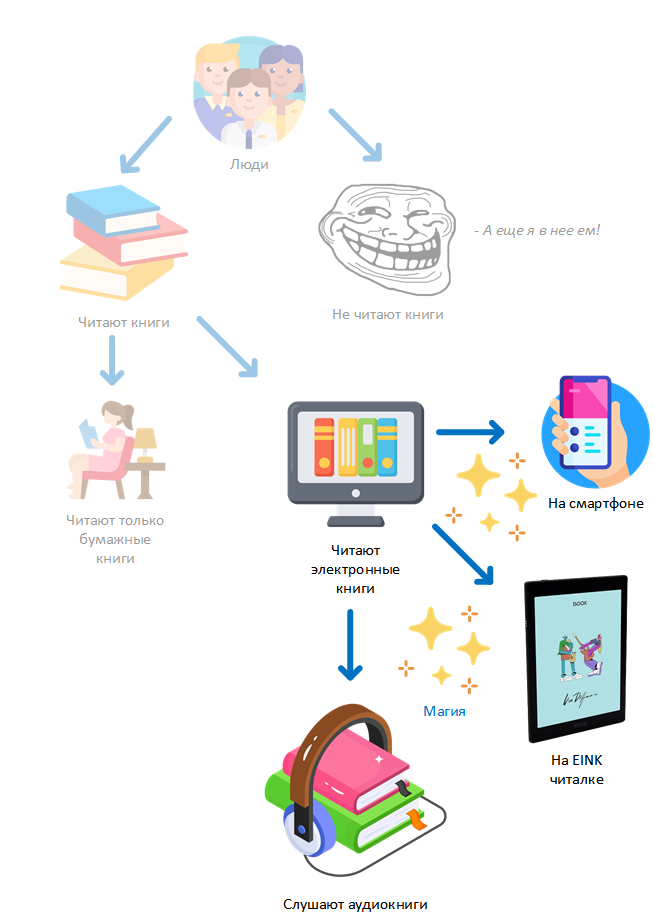
Вот теперь мы, собственно, добрались до идеи:
- Берем электронную книгу. Совершенно обычную, мы проверяли на формате fb2. В качестве референса я тренировался на Александре Сергеевиче "Дубровский" (после того как мне на глаза попалось это прикольное описание)
- Берем аудиокнигу, т.е. специально подготовленную, начитанную профессиональным диктором и т.д. Я просто скачивал из интернетов, нашлась какая-то от радио "Вера". Аудиокнига - это набор звуковых файлов (в данном примере - по главам)
- Магия
- Включаем проговаривание в KnownReader, вместо движка tts включается аудиокнига. При этом выделяются предложения в тексте книги, как и при обычном tts режиме
Магия
Всякая идея ценна практической реализацией и вот мы как раз к этому и подошли. В этом разделе будет уже много технического, линуксов и питонов и т.д., но для начала обозначим основные проблемы:
- Нам надо разбить книгу на составляющие, в рамках которых мы и будем оперировать. Пока все просто - это предложения, разделенные чаще всего точками, но бывают еще другие знаки препинания (как минимум - ?, !)
- Надо разбить так электронную книгу (текстовую, fb2, epub). Тут в целом все прозрачно, читалка так и делает, это ее штатная работа
- И надо преобразовать аудиокнигу в текст. Вот это уже задача посложнее
- После чего как то совместить два текста (которые хоть и одна книга, но на 100 процентов, разумеется, не совпадают)
- Ну и синхронизировать показ выделенных предложений в тексте с читаемыми
- Небольшая ремарка - есть смысл "ведущей" считать все таки аудиокнигу, а текст выделять "как получится" - чтобы ничего никуда не "прыгало". Рассмотрим пример: допустим, в аудиокниге есть предложения "А. Б. В.", а в тексте только "А. В.". В этом случае аудиокнига должна читаться так, как читается, полностью, а в тексте же будет по очереди выделяться "А. Ничего. В."
Реализация
У нас есть следующие подготовительные вводные:
- Доработанный KnownReader (версия 20231007 или более поздняя), в который перенесена реализация из форка Эллиота
- Репозиторий от него же (https://github.com/teleshoes/ebook-audiobook-wordtiming) с инструментами, которые потребуются для дальнейшего
Итак, начинаем
- Для начала нам потребуется открыть книгу (здесь и далее под книгой я буду иметь в виду электронную книгу, а аудиокнигу буду так и называть аудиокнигой) на телефоне, перейти в раздел "о книге" и сохранить файл (нажать кнопку - см. ниже) с информацией о предложениях (sentenceinfo). Эллиот предлагает другой вариант, но он у меня так и не заработал

- Далее этот файл нам потребуется (и на телефоне и на компьютере). Ниже показано из чего этот файл, в итоге, состоит:
/FictionBook/body[1]/section[1]/title/p/text().0,Том первый /FictionBook/body[1]/section[1]/section[1]/title/p/text().0,Глава I /FictionBook/body[1]/section[1]/section[1]/p[1]/text().0,Несколько лет тому назад в одном из своих поместий жил старинный русский барин, Кирила Петрович Троекуров. /FictionBook/body[1]/section[1]/section[1]/p[1]/text().107,Его богатство, знатный род и связи давали ему большой вес в губерниях, где находилось его имение. /FictionBook/body[1]/section[1]/section[1]/p[1]/text().205,Соседи рады были угождать малейшим его прихотям; губернские чиновники трепетали при его имени; Кирила Петрович принимал знаки подобострастия как надлежащую дань; дом его всегда был полон гостями, готовыми тешить его барскую праздность, разделяя шумные, а иногда и буйные его увеселения. /FictionBook/body[1]/section[1]/section[1]/p[1]/text().492,Никто не дерзал отказываться от его приглашения или в известные дни не являться с должным почтением в село Покровское. /FictionBook/body[1]/section[1]/section[1]/p[1]/text().611,В домашнем быту Кирила Петрович выказывал все пороки человека необразованного. /FictionBook/body[1]/section[1]/section[1]/p[1]/text().690,Избалованный всем, что только окружало его, он привык давать полную волю всем порывам пылкого своего нрава и всем затеям довольно ограниченного ума. /FictionBook/body[1]/section[1]/section[1]/p[1]/text().839,Несмотря на необыкновенную силу физических способностей, он раза два в неделю страдал от обжорства и каждый вечер бывал навеселе. /FictionBook/body[1]/section[1]/section[1]/p[1]/text().969,В одном из флигелей его дома жили шестнадцать горничных, занимаясь рукоделиями, свойственными их полу. /FictionBook/body[1]/section[1]/section[1]/p[1]/text().1072,Окна во флигеле были загорожены деревянною решеткою; двери запирались замками, от коих ключи хранились у Кирила Петровича. /FictionBook/body[1]/section[1]/section[1]/p[1]/text().1195,Молодые затворницы в положенные часы сходили в сад и прогуливались под надзором двух старух. /FictionBook/body[1]/section[1]/section[1]/p[1]/text().1288,От времени до времени Кирила Петрович выдавал некоторых из них замуж, и новые поступали на их место. /FictionBook/body[1]/section[1]/section[1]/p[1]/text().1389,С крестьянами и дворовыми обходился он строго и своенравно; несмотря на то, они были ему преданы: они тщеславились богатством и славою своего господина и в свою очередь позволяли себе многое в отношении к их соседам, надеясь на его сильное покровительство. /FictionBook/body[1]/section[1]/section[1]/p[2]/text().0,Всегдашние занятия Троекурова состояли в разъездах около пространных его владений, в продолжительных пирах и в проказах, ежедневно притом изобретаемых и жертвою коих бывал обыкновенно какой-нибудь новый знакомец; хотя и старинные приятели не всегда их избегали за исключением одного Андрея Гавриловича Дубровского. /FictionBook/body[1]/section[1]/section[1]/p[2]/text().315,Сей Дубровский, отставной поручик гвардии, был ему ближайшим соседом и владел семидесятью душами. /FictionBook/body[1]/section[1]/section[1]/p[2]/text().413,Троекуров, надменный в сношениях с людьми самого высшего звания, уважал Дубровского, несмотря на его смиренное состояние. /FictionBook/body[1]/section[1]/section[1]/p[2]/text().535,Некогда были они товарищами по службе, и Троекуров знал по опыту нетерпеливость и решительность его характера. /FictionBook/body[1]/section[1]/section[1]/p[2]/text().646,Обстоятельства разлучили их надолго.
- Уходим за компьютер, взяв туда этот файл (sentenceinfo). Под компьютером я буду предполагать обычный комп с обычной же современной "убунтой" (версии 22) - на винде и других линуксах я не пробовал, но вполне возможно, что и заведется
- Скачиваем на компьютер аудиокнигу - в какую-нибудь папку. Если книга состоит из нескольких аудиофайлов, то приводим наименования в порядок, а именно - даем им имена так, чтобы они сортировались естественным образом. И желательно покороче. В моем примере было "Дубровский. Глава 1", я поменял на что-то типа "D0101.mp3". Также Эллиот настойчиво советует преобразовать формат mp3 во flac, этим мы тоже займемся
- Клонируем репозиторий Эллиота (git clone https://github.com/teleshoes/ebook-audiobook-wordtiming) и идем в него разбираться. Там есть установочный скрипт, но я предпочел все сделать руками
- Пару слов о том, какого результата мы хотим добиться. Напомню - у нас есть сама книга, аудио к ней и файл sentenceinfo с разбивкой книги на предложения в специальном формате. А хотим мы получить файл, в котором будут записаны временные отметки - с какой минуты и секунды начинается слово в аудиофайле - файл wordtiming. На основе этой информации алгоритм Эллиота в KnownReader будет "сшивать" текст с аудио. В конечном итоге все эти файлы должны лежать рядом с книгой (на телефоне). Приступим:
- Установим библиотеку pandoc:
sudo apt install pandoc
Она у нас используется для преобразования файла книги в простой текст. Это была ранняя реализация и текущий алгоритм использует только файл sentenceinfo, так что скорее всего она уже нужна, но надо пробовать, изначально я ставил ее, поэтому пока этот шаг оставил
- Скрипты Эллиота написаны на Perl/Python, поэтому нам нужны они оба. Perl в убунте был по умолчанию, но, однако не хватило одной библиотеки, доставим ее:
sudo cpan install Data::UUID
install cpan reload cpan
sudo apt install ffmpeg
sudo apt install python3-venv python3 -m venv /opt/python-vosk sudo apt install python3-pip /opt/python-vosk/bin/pip install vosk
vosk - это как раз библиотека по распознаванию аудио в текст.
Лирическое отступление - как можно применить это в "рабочей" жизни.
С помощью нехитрого скрипта (все тот же ffmpeg и vosk) я извлек аудиодорожку из видеофайла - записи рабочей встречи (мы проводим их в TrueConf) и преобразовал в текст. Немного помогает при составлении протоколов совещаний
Для vosk нужно ещё скачать модель русского языка. Находится тут: https://alphacephei.com/vosk/models
Я скачал эту: vosk-model-ru-0.22
Распаковал, положил в отдельную папочку.
- Немного поговорим еще про файл sentenceinfo. Для его создания Эллиот предложил вариант с установкой (доработанной) десктопной версией CoolReader / KnownReader (тут без разницы), но у меня этот вариант не взлетел (линуксы у нас разные, мы не стали глубоко разбираться). Именно поэтому я и тащу этот файл с телефона, а не генерирую "в общем процессе"
- Вроде бы всего хватает, начнем, помоляся. Преобразуем звуковые файлы во flac:
ffmpeg -i D0101.mp3 D0101.flac ffmpeg -i D0102.mp3 D0101.flac ... И так все главы
./ebook-audiobook-wordtiming /path/to/Pushkin_Dubrovsky.fb2 /path/to/D*.flac -o /path/to/Pushkin_Dubrovsky.wordtiming --cr3
13.11,том,D0101.flac 13.83,первый,D0101.flac 15.6,глава,D0101.flac 16.08,i,D0101.flac 17.91,несколько,D0101.flac 18.6,лет,D0101.flac 18.84,тому,D0101.flac 19.11,назад,D0101.flac 20.07,в,D0101.flac 20.28,одном,D0101.flac 20.58,из,D0101.flac 20.67,своих,D0101.flac 21.06,поместий,D0101.flac 21.63,жил,D0101.flac 21.93,старинный,D0101.flac 22.68,русский,D0101.flac 23.25,барин,D0101.flac 24.48,кирила,D0101.flac 25.08,петрович,D0101.flac 26.1,троекуров,D0101.flac 27.9,его,D0101.flac 28.2,богатство,D0101.flac 28.95,знатный,D0101.flac 29.52,род,D0101.flac 29.82,и,D0101.flac 29.91,связи,D0101.flac 30.48,давали,D0101.flac 30.84,ему,D0101.flac 31.02,большой,D0101.flac 31.5,вес,D0101.flac 31.89,в,D0101.flac 31.98,губерниях,D0101.flac 32.73,где,D0101.flac 33,находилось,D0101.flac 33.66,его,D0101.flac 33.93,имение,D0101.flac 35.16,соседи,D0101.flac 35.79,рады,D0101.flac 36.12,были,D0101.flac 36.36,угождать,D0101.flac 36.96,малейшим,D0101.flac 37.5,его,D0101.flac 37.77,прихотям,D0101.flac
Собственно мы на финишной прямой - записываем все файлы в одну папку (в плоской структуре, без подпапок) на телефоне (у меня она называется "Дубровский"):
- Саму книгу, в данном примере она в формате fb2
- Файл sentenceinfo (ну, он у нас и так уже лежит, так как мы его с телефона и получали)
- Файл wordtiming
- Все аудиофайлы
Запускаем аудирование в KnownReader, наслаждаемся (в конце статьи видео с примером отрывка)
Дочитали? Попробовали? Не получилось? У меня тоже не сразу, поэтому надо сказать, что я поменял в скриптах Эллиота, чтобы они у меня завелись:
Файл word-vosk-json. Он написан на питоне. Несмотря на то, что у него можно в качестве параметров передать язык и путь к модели, в общем процессе он вызывается из перл скрипта без этих параметров (я уже создал issue в сторону Эллиота и он обещал сделать), поэтому "закостылим" их:
... DEFAULT_MODEL_LANG = "ru" ... model = Model(model_path="/path/to/vosk-model-ru-0.42/") ...
Файл ebook-audiobook-wordtiming. Написан на Perl. Здесь немного посложнее. Дело в том, что работа скрипта построена таким образом, что файл sentenceinfo генерируется в общем процессе обработки - либо через pandoc (но не рекомендовано), либо через установленный на компьютере CR/KR (но у меня этот способ не заработал). Именно поэтому я и взял этот файл с телефона. Но теперь надо научить скрипт, не генерировать этот файл, а брать готовый. У Эллиота используется хитрый метод кеширования, который позволяет "начинать с того места, с которого прервались (если прервались)" и кеширование файла sentenceinfo - тоже один из шагов. Таким образом я сначала запустил скрипт, чтобы он "сругался" на отсутствие этого файла, а потом записал его туда, где он ожидался скриптом (переименовав соответстсвующим образом). Получилось достаточно топорно, но главное получилось. Также обсудили этот момент, он обещал сделать более "дружелюбно", но пока - такие костыли:
# Это не до конца уже помню зачем, но видимо перл скрипт без этого не находил питон скрипт.
#my $voskExec = "vosk-words-json";
my $voskExec = "./vosk-words-json";
...
if(-e $cacheFile){
#Эту строчку комментарим
#die "ERROR: $cacheFile already exists, possible race condition\n";
}
if(not -e $cacheFile){ #А следующую обернем дополнительным "ифом"
&$processFileSub($file, $cacheFile);
}
Пример аудирования (в нем кстати видно "левый" (рекламный) текст на стыке глав, который просто пропускается):
https://disk.yandex.ru/i/uozK_eLr7tPDYg
Заключение
Внимательный читатель спросит - а нафига все это надо? Включай аудиокнигу в плеере / автомобиле и радуйся жизни. Ненадолго включу душнилу:
- (Наверное) поможет при изучении иностранных языков, так как мы видим и текст и озвучку и можем запоминать, тем самым обучаясь, как на фильмах с субтитрами
- И да, можно чуть докрутить идею (я собираюсь это сделать) и сделать вызов словарей из интерфейса проговаривания. Тогда функциональность "замкнется" - у нас есть текст, озвучка и перевод
- Выглядит это просто роскошно
- Ну и наверное есть ещё плюсы, может быть кто-нибудь в комментариях еще накинет?
А если чуть менее формально - искусство не обязательно должно приносить пользу (это не ремесло). Оно вполне может быть просто красивым.
По традиции - котики. Возможно, знакомый уже вам с прошлых публикаций кот Николай, а вот у кошки Маши сегодня дебют.
