Один день из жизни JVM-инженера

Можно разрабатывать на Java, а можно разрабатывать Java. Есть люди, чей код исполняет виртуальная машина — а есть люди, чей код и есть виртуальная машина.
Вроде бы те и другие существуют в одной Java-экосистеме, но задачи совершенно разные. Поэтому редкое место, где они пересекаются и могут что-то поведать друг другу — Java-конференции. Мы проводим их регулярно (уже в апреле будет JPoint). И на предыдущей нашей конференции Иван Углянский dbg_nsk поделился с Java-разработчиками тем, как всё выглядит с его стороны.
Чем он вообще занимается? Почему JVM-инженеры всё так медленно делают? На каком языке стоит писать рантайм, а на каком компилятор? Как «папка бога» в Windows привела к неожиданным последствиям? Может ли «обычный джавист» стать JVM-инженером?
Для тех, кому удобнее видео, прикладываем ссылку на ютуб. Далее повествование идёт от лица Ивана.
Экосистема Java состоит из двух слоев. Верхний слой — прекрасный город с великолепной архитектурой и красивыми высокими зданиями. В этом городе живут эльфы, которые программируют на джаве. У них есть классные фреймворки, Spring, Hibernate, системы сборки и так далее. Все высокоуровнево. А под этим красивым Ривенделом есть пещера с гномами. Они сидят в своей пещере, света солнечного не видят, копошатся в кишках и делают виртуальную машину. У них совсем другие темы для обсуждения: JIT, сборщики мусора, они больше говорят про C++, чем про джаву, и копаются в байтиках.
Я изначально как раз из этого нижнего мира — тот самый гном, который сидит и делает виртуальные машины. Восемь лет я делал это в компании Excelsior, там была собственная виртуальная машина Excelsior JET. Последние три года я занимаюсь этим в Huawei.
Так что сегодня я расскажу вам, кто такие эти гномы, что они делают и зачем они нужны. Расскажу, как конкретно разрабатываются фичи в JVM в бытовом смысле: как выглядит день JVM-инженера, как он работает? Ну и, конечно же, потравлю байки: за 11 лет я видел много чего интересного в странно работающих Java-приложениях. А еще отвечу на вопрос «Почему вы всё так долго делаете».
Как работает Java?
Начнем с самого высокого уровня. У нас есть какая-то программа на джаве:
public static void main(String[] args){
for (int i = 0; i < 10; i++){
Object obj = new Object();
System.out.println(obj.hashCode());
}
}
test.javaЧто с ней нужно сделать в первую очередь?
Сначала нужно запустить инструмент javac: Java-компилятор, который превратит исходный код на Java в код на джава-байткоде, немного другом языке программирования. Это тоже часть JVM, но мы относимся к ней как к «фронтенду»: как к самому краешку, такому «игрушечному» компилятору, который просто транслирует один язык в другой, почти без всяких оптимизаций. Вот такая у нас фронтенд-разработка, правда, совсем без JavaScript.

Когда у вас появился байткод, его нужно скормить черному ящику, который называется Java Virtual Machine, виртуальная машина. Они бывают разные: классические вроде HotSpot и разные другие реализации, об этом ещё поговорим. А на выходе мы получаем счастье: отлично работающую Java-программу, которая точно соответствует семантике того, что вы написали.
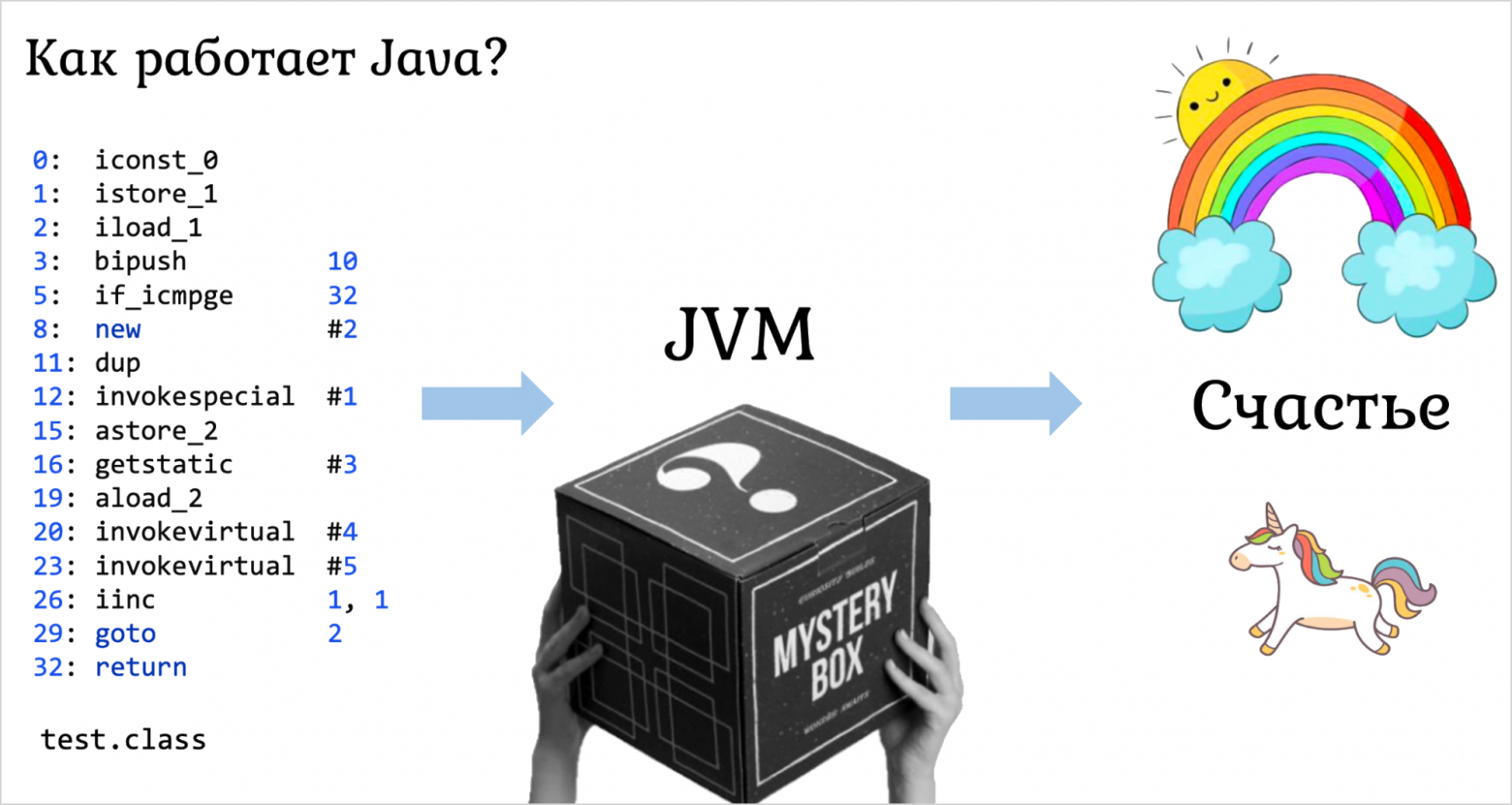
Что такое счастье? Это ассемблер. И на выходе мы должны получить работающий машинный код. Каким-то образом появившийся, каким-то образом исполненный.
Есть разные подходы, как можно получить такой код. Можно проинтерпретировать. К сожалению, в некоторых кругах за джавой до сих пор закрепилось поверье, что что это именно интерпретируемый язык, со всеми вытекающими из этого последствиями..
Конечно, в современном мире это не так. Кроме интерпретации у нас есть, например, JIT-компиляция, когда вы на лету компилируете что-то в машинный код, а уже потом он будет исполняться. Также сейчас уже довольно популярна AOT-компиляция джавы, когда вы заранее превращаете весь байткод в машинный код, как будто у вас просто приложение на C++. Раньше по-серьезному таким занимались только мы в Excelsior, но сейчас благодаря GraalVM и Native Image это стало популярнее, и никого этим уже не удивишь.
Кроме компиляторов, есть рантайм. Он должен поддерживать исполнение вашего кода, сгенерированного каким-то образом. Это очень важная часть, и сегодня здесь на конференции много говорил Владимир Воскресенский. О ней тоже еще поговорим.
Теперь конкретнее. Чем в этих частях занимаются JVM-инженеры? Если вы JVM-инженер в компиляторе, то глобально вам нужно породить тот самый машинный код под нужную платформу (хотите на Intel — значит, на Intel, если на ARM — то на ARM). При этом код должен быть корректным, должен сохранять семантику джава-программы. Ну и совсем уже желательно, чтобы он был эффективным, чтобы ваша джава-программа работала быстро после этой самой компиляции.
Если говорить предметно, то вам в компиляторе нужно делать какие-то абсолютно классические вещи, о которых вы наверняка слышали в университете: parsing -> lowering -> code generation. Несколько примеров оптимизации: удаление избыточного кода (DCE), inline, loop unrolling, global value numbering, scalar replacement, register allocation, bounds-checking optimizations, …
Это всё хорошо описано в классической литературе. Например, в одной из самых известных книг по компиляторам, книге дракона «Compilers. Principles, Techniques, and Tools» by Alfred V.Aho, Ravi Sethi, Jeffrey D.Ullman.
Единственное, что стоит отметить: современные компиляторщики находятся на передовом крае этой науки. Чтобы сгенерировать еще более оптимальный, еще более быстро работающий код, нужно не просто пользоваться тем, что было, а придумать какие-то новые алгоритмы и новые подходы, нужно двигать науку вперед. И они этим активно занимаются.
Так как я сам рантаймщик, я буду больше говорить про дела в рантайме. Глобально нам просто нужно помочь полученному машинному коду работать эффективно. Если говорить чуть более предметно, то у нас есть очень много очень непохожих друг на друга задач. Из того, что больше всего на слуху — это, конечно, автоматическое управление памятью. Аллоцировать объекты, собирать мусор. Это, безусловно, важная часть рантайма, поэтому про это есть огромное количество прекрасных докладов. Также это поддержка tiered-компиляции: переход от интерпретатора к более оптимизированному коду (и обратно!).
На самом деле это только вершина айсберга. В рантайме гораздо больше задач, и глобально их можно описать так: реализация высокоуровневых фич языков. Речь про исключения, синхронизацию, трединг, рефлексию, интероп и так далее. Для вас эти фичи работают как-то из коробки. Вы просто берете и выбрасываете исключения. Но чтобы это работало из коробки, кто-то должен был это написать. И это работа для рантайм-инженера.
Вот вам пара экзотических примеров.
Пример 1: Неявные исключения
Начнем с рантайма. Допустим, у меня есть код на С:
struct st {
int a, b;
};
int main() {
struct st * ptr = NULL;
ptr->a = 42;
}Есть какая-то структура, два поля. Я завожу указатель на эту структуру, потом записываю туда NULL. И дальше «доступаюсь» к какому-то полю этой самой структуры. Что случается, если я запущу такую программу на С? У меня будет сегфолт. Точнее, будет undefined behavior, но именно в этом случае можно быть уверенным, что у вас будет Segmentation fault (core dumped).
Что будет, если я так сделаю в джаве?
class Test {
int a;
}
public static void main(String[] args) {
Test t = null;
t.a = 42;
}Мы заводим класс с каким-нибудь полем, возьмем ссылку NULL и попытаемся доступиться к этому полю. Вылетит красивый NullPointerException:
Exception in thread “main” java.lang.NullPointerException: Cannot assign field “a” because “t” is null at Main.main(Main.java:9)
В современных версиях Java он вот даже пишет, где и в какое поле вы пытались что-то записать. Эти исключения можно поймать, обработать, перевыбросить — в общем, ваша программа точно не крэшнулась, всё корректно, и вы можете продолжать с этим работать.
Как это реализовать? Как добиться такого поведения со стороны JVM?
Самое простое, что можно сделать — это полагаться на компилятор. Компилятор мог бы найти все такие места доступа к полям или вызова методов от каких-то объектов и просто автоматически сгенерировать проверки.
public static void foo(Test t) {
if (t != null) { // [ COMPILER-GENERATED]
t.a = 42;
} else { // [ COMPILER-GENERATED]
throw new NullPointerException();
}
}
foo(null);Если не NULL, то делай что написано, а если NULL, то просто выбрасывай NullPointerException. Некоторые компиляторы так и делают. Но кажется, что если каждый доступ к полю, каждый вызов функции обрамлять проверкой — это же очень дорого.
Даже если вы сможете оптимизировать разные доступы к полям, вынести всё под какое-то одно условие, то всё равно это сильно просадит вашу производительность, потому что в вашем коде появятся какие-то переходы.
Как это работает на самом деле. Напишем вот такой метод foo:
public static void foo(Test t) {
t.a = 42;
}
foo(null);И чтобы понять, как это работает, надо посмотреть на ассемблер. Добавим PrintAssembly, UnlockDiagnosticVMOptions и видим, что весь наш метод превратился в маленький красивый mov, который просто берет значение 0x2a (то есть 42 в шестнадцатеричной системе) и записывает по нашему офсету C. Офсет C — это офсет первого поля в объекте t. Нет никаких проверок, ничего дополнительного, просто один лаконичный mov:

Более того, у вас рядом появятся комментарии, что это какой-то putfield, и даже будет подписано исключение, которое вас куда-то отправляет. Давайте разберемся, что это такое и как это работает.
Компилятор с рантаймом в этом месте договариваются так: не будем ничего генерировать, пусть взрывается. Пусть, если приходит NULL, у нас случится сегфолт, как в С. Но задача рантайма — обработать и отфильтровать все эти сегфолты. Например, ваш сегфолт очень похож на NullPointerException. Если он случился в точке, где запись в поле говорит, что офсет доступов должен был быть именно 12, ровно по этому офсету поля a, тогда это и правда NullPointerException, стоит остановить происходящий «развал» и выбросить NPE. Но если мы никак не смогли его распознать, тогда это core dump и ваша виртуальная машина правда крэшнулась.

Получается, что такие исключения (NullPointerException) вообще бесплатные, когда не случаются. Чаще всего никаких NPE у вас нет, и всё работает максимально быстро.
Однако если вдруг они случились, то это, конечно, дорого. Но, с одной стороны, зачем вы написали такой код, в котором постоянно случаются NPE? С другой стороны, если это и правда горячее место, и раз за разом происходит NullPointerException, то виртуальная машина заметит это (особенно в случае JIT-а), деоптимизирует ваш код и все-таки вставит явную проверку (это будет выгоднее, чем все время крэшиться, перехватывать сегфолт и оборачиваеть его в NPE).
На самом деле этот трюк, когда вы позволяете «развалиться», а потом разбираетесь, что же пошло не так, очень популярен в рантайме. Многие вещи делаются с его помощью. Например, stack overflow. Никто не делает явной проверки в прологе, кончился у вас стек или нет. Вместо этого мы пытаемся достучаться до page guard. Если случится развал — заметим это и скажем, что у вас stack overflow. То же самое с safe points для сборщика мусора. Это супер-инструмент, который помогает оптимизировать производительность, излюбленный трюк, как JIT-, так и AOT-компиляторов. Главное, что вы этого не замечаете. Рантайм здесь всячески работает за вас. С точки зрения сгенерированного кода это абсолютно невидимо, и это здорово.
Пример 2: new-то ненастоящий!
Обратный пример. Когда у нас компилятор делает что-то такое, чтобы рантайм поменьше работал. Я имею в виду удаление избыточных операторов new. Вообще выделять объекты, исполнить оператор new — это очень накладная штука. Даже не потому, что вы саллоцируете память, аллокаторы зачастую быстрые. А потому что вы нагрузите сборщик мусора. Потом ему придется прийти и почистить эту память. Вы таким образом сильно утяжеляете его работу, поэтому любая виртуальная машина старается этого избежать. Как это сделать?
В компиляторе есть замечательный Escape Analysis (анализ утеканий), который поможет вам понять, утекает ли куда-то ваш объект, нужен ли он кому-то за пределами локального метода, который сейчас исполняется, или все-таки нет.
Представим, сделали вы вот тут аллокацию, сказали, что Test obj = new Test();
class Test {
int a, b;
}
public void foo() {
Test obj = new Test();
obj.a = 42;
obj.b = 10;
System.out.println(obj.a + obj.b);
}И потом исключительно локально, в пределах foo(), пользуетесь этим объектом. Зачем здесь что-то аллоцировать в хипе? Он ведь тут же помрет, и его нужно будет собирать сборщиком мусора. Конечно же никакой аллокации здесь не будет. Вместо этого сработает знаменитая оптимизация Scalar Replacement, которая заменит использование этого объекта на использование его полей. Она как будто взорвет его, аннигилирует на атомы, и мы будем работать с его полями как с обычными локалами. То есть не будет никакой аллокации, просто появятся два локала с нужными значениями, и на этом все.
Это очень эффективная тактика. Во-первых, new не срабатывал, сборщик мусора не напрягался. Во-вторых, вы потратили даже меньше памяти, чем на обычный объект, потому что у обычного объекта есть еще заголовки, а здесь вы просто работаете с полями. В-третьих, поля этого объекта скорее всего попадут на регистры — а значит, мы будем работать с ними гораздо быстрее, чем если бы это был просто объект в памяти.
class Test {
int a, b;
}
public void bar(Test arg){
arg.b = 10;
System.out.println(arg.a + arg.b);
}
public void foo() {
Test obj = new Test();
obj.a = 42;
bar(obj);
}У нас есть аллокация объекта Test, мы немного поиспользовали его внутри метода foo(), а потом передаем его в метод bar(), который тоже сам по себе очень хорош, никакого утекания здесь не происходит. Предположим, что метод bar никак не проинлайнился. По какой-то причине bar остался в коде. Тогда объект уже просто так не взорвешь. Вроде бы и утекания никакого нет. Но с другой стороны, если вы объект расщепите на атомы, то передать внутрь метода bar придется не один указатель на начало объекта, а все его поля, придется его копировать, что может быть просто не эффективно. Становится дороже передавать внутренности объекта в функции, чем просто ссылку на этот объект, и получится пессимизация, а не оптимизация.
Однако здесь тоже можно кое-что сделать. Если мы замечаем, что наш объект действительно используется локально, никуда не утекает, кроме передачи вызова какой-нибудь функции и передачи его туда в качестве аргумента, где он тоже хорош и не утекает, то мы можем заменить аллокацию в хипе такого объекта на аллокацию на стеке.

Во фрейме метода foo() распишем этот объект: у него будет заголовок и поля. С ним немного по-другому будет работать сборщик мусора, он не будет пытаться его собрать, хотя обработка все равно нужна. В результате, с одной стороны, мы сможем передавать указатель на него внутрь новых функций, а с другой стороны, как только мы выйдем из foo, фрейм счеркнется, и мы моментально соберем память из-под него. Это тоже очень мощная оптимизация.
И наконец есть совсем плохой случай:
class Test {
int a, b;
}
static Test t;
public void foo(boolean shouldEscape){
Test obj = new Test();
obj.a = 42;
obj.b = 10;
System.out.println(obj.a + obj.b);
if (shouldEscape) {
t = obj;
}
}Допустим, у меня есть метод, в котором объект obj в основном локален, но есть один неприятный холодный путь исполнения под условием shouldEscape, в котором все-таки происходит утекание. Я в глобальное поле t записываю ссылку на этот объект. С точки зрения любого escape-анализа здесь будет утекание. Здесь нельзя сделать ни scalar replacement, ни stack allocation. Но с другой стороны, мы же видим, что это просто один путь, всего лишь одна точка, где что-то пошло не так.
Есть анализы помощнее: partial escape analysis, который не просто скажет, что есть утекание (бинарный ответ, да или нет), а скажет: вот здесь объект используется локально, а в этих точках он действительно утекает. И тогда можно взорвать объект частично. Глобально не будет никакой аллокации, в самом начале мы начинаем работать с полями, а ровно перед точкой утекания мы эвакуируем наш объект в хип. То есть создаем новый объект, записываем его поля и присваиваем его куда нужно.
Такая оптимизация есть, например, в компиляторе Graal. Она очень эффективна на примере кода стримов или на примере Scala-кода, то есть именно на этих бенчах Graal себя очень хорошо чувствует. Во многом благодаря оптимизации Partial Escape Analysis.
Что получается: удаление new — это обратная реальная история от неявных исключений. Компилятор делает всё, чтобы рантайму ничего не нужно было делать. Многие new — тоже бесплатные, можно не бояться их ставить в своем коде, JVM постарается их убрать.
Scalar replacement — очень популярная оптимизация, она есть в HotSpot и не только. Partial Escape Analysis чуть более редкая штука, но встречается в Graal, во многих других современных виртуальных машинах тоже.
Stack allocation — более редкая оптимизация. Ее нет в HotSpot, зато она есть в IBM OpenJ9. Для HotSpot есть только proposal и прототип, который сделали люди из IBM. Они показываю, что это можно сделать, что это даст бенефиты на бенчмарках. Но пока кажется, что всё осталось на уровне предложения.
Это были какие-то конкретные примеры. Если говорить совсем глобально, то кроме того, чтобы компилятор сгенерировал вам корректный код, а рантайм его поддержал, они оба (чаще совместно) работают над оптимизацией производительности и потребления памяти вашей программы. И в этом взаимодействии, в этих оптимизациях и кроется львиная доля задач, которыми занимаются JVM-инженеры.
Если вы хотите узнать побольше примеров таких задач, то я очень советую почитать замечательный цикл статей Алексея Шипилёва. Они называются JVM Anatomy Quarks. В целом эти статьи построены как ответы на вопрос со стороны «а как в JVM что-то работает?», но по факту они так же описывают конкретные маленькие задачи, которые в этой JVM нужно сделать нам, JVM-инженерам. Если вам интересно посмотреть еще примеры наших повседневных задач, почитайте обязательно.
Обсудили, что делают JVM-инженеры. Теперь давайте поговорим, как они это делают.
Как разрабатывать JVM?
На каком языке программирования вы бы писали рантаймы и компиляторы?
С++ часто выбирается в качестве языка, который используется для разработки рантаймов компиляторов. Причин две:
Причина 1: производительность. То, что вы напишете, будет очень быстро работать.
Причина 2: связь с низким уровнем. Мы же вроде пишем внутренность языка, наверное, это должно как-то взаимодействовать с байтиками, с операционной системой и так далее.
Разбиваем вопрос на два: на чем писать компилятор и на чем писать рантайм.
На чем писать компилятор?
С компилятором всё довольно интересно. Задача компилятора — породить машинный код, корректный, эффективный, под нужную платформу.
Если совсем упростить задачу, то мы берем байты на вход (исходную программу) и генерируем байты на выходе (машинный код). И где тут связь с низким уровнем? Ничего такого нет, вам просто нужно уметь генерировать байты. В общем-то с этим справится любой язык, где есть какой-нибудь байт-буфер. Например, наша любимая Java. Так что обозначенная выше причина номер два здесь теряет смысл. Остается причина номер один, производительность.
Здесь тоже не всё так однозначно. Насколько быстро нам нужно скомпилировать этот код? Зависит от компилятора. Если у вас AOT-компилятор, то кажется, что у вас есть вообще всё время мира. Вы же заранее компилируете, вы никак не конкурируете с программой. Хоть 8 часов компилируйте, применяйте все оптимизации, которые хотите, всё будет замечательно. Конечно, наши клиенты почему-то со мной не согласны и спрашивают, а почему их Spring Boot-приложение компилируется 8 часов. Но на самом деле так-то ограничений у вас никаких нет. Вы не конкурируете за ресурсы с приложением.
С JIT-компиляторами всё немного хуже, потому что они работают параллельно с приложением. Если они будут это делать слишком долго, то стартап замедлится, что зачастую неприемлемо. Давайте посмотрим на реальные примеры, на разные компиляторы, режим их работы и на чем они написаны.
Начнем с «ненастоящего» компилятора javac.

Это AOT- или JIT-компилятор? Если вы ответили AOT, то в целом правильно, в основном он используется заранее, его можно дернуть в рантайме и что-то покомпилировать, но в целом да, это AOT. И он написан на чистой Java. И так обстоят дела уже очень давно, лишь самые первые версии javac были написаны на C, по понятным причинам. Конечно, можно сказать, что там мало оптимизаций, но на практике он и правда может работать довольно долго, и в целом это никого особо не напрягает. Это такой интересный знак.
Посмотрим на компиляторы в боевых реализациях виртуальных машин. Самые известные в HotSpot, C1/C2 — это JIT-компиляторы, написанные на С++. В IBM их OpenJ9 — тоже JIT, но может может использоваться как AOT, и он тоже написан на С++. Но во многом это сделано по историческим причинам. В тот момент, когда их делали, никому в голову не могла прийти идея начать писать на джаве. Тогда казалось очевидным, что если производительность, то С++.
А вот если посмотреть на что-то современное, например, на тот же Graal-компилятор — он тоже используется как JIT и как AOT, и он написан на чистой джаве. И никого это не беспокоит.
В Excelsior у нас в основном был AOT-компилятор, но был еще дополнительный JIT. И первый был написан вообще на Scala. Вдумайтесь — на Scala, на языке, который навернут над джавой. То есть там всё должно было работать еще медленнее. Но для написания оптимизирующего AOT-компилятора Scala идеально подходит. JIT-компилятор был написан на джаве, но опять-таки он вполне себе нормально работал.
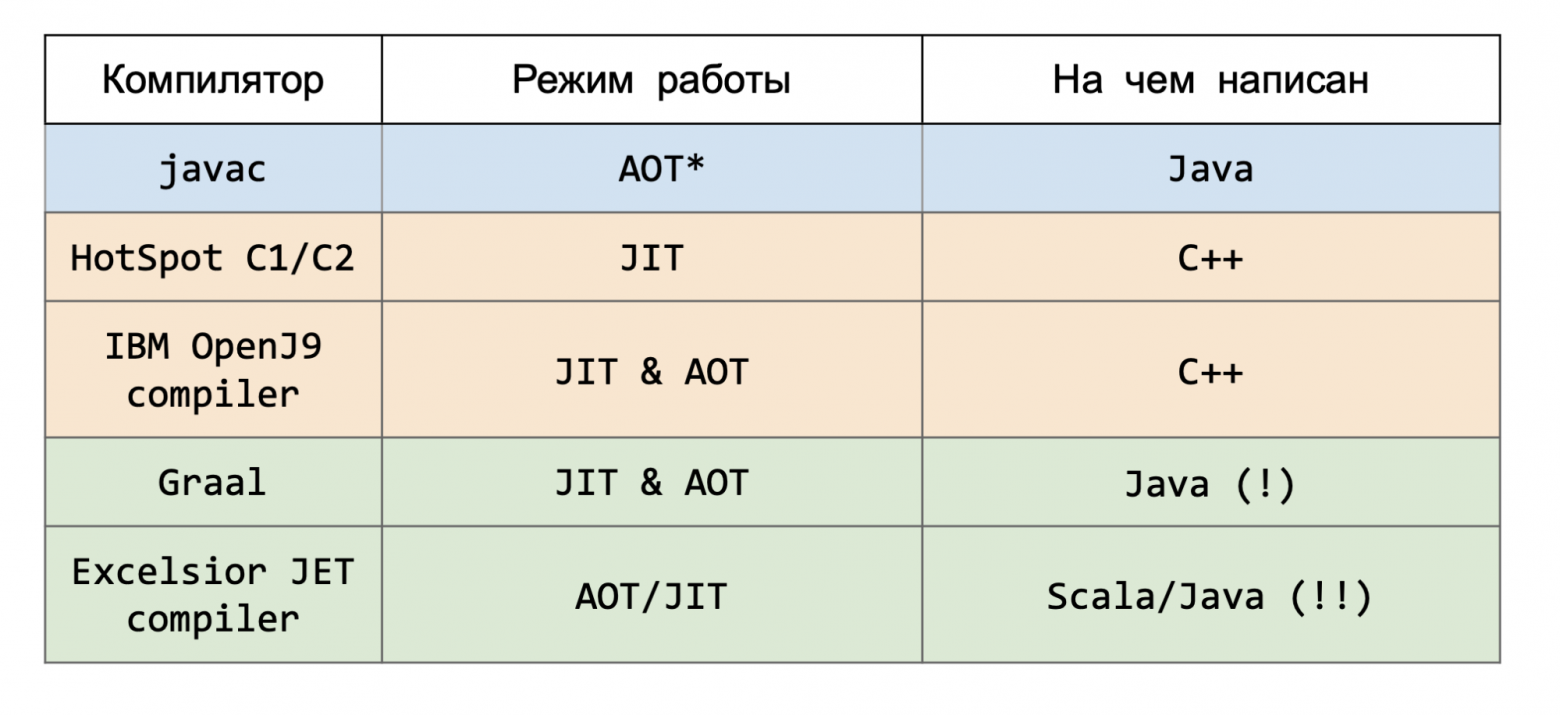
Так что здесь С++ вообще не обязателен. Можно писать на каких-нибудь managed-языках.
На чем писать рантайм?
У нас снова те же проблемы: производительность и связь с низким уровнем. И вот в рантайме вы от этого не уйдете. Рантайм всегда работает параллельно с приложением. Его нельзя замедлять, он должен быть очень быстрым. Чем он будет быстрее, тем лучше. И связь с низким уровнем в рантайме как раз во все поля, потому что именно рантайм и позволяет связываться с операционной системой. Я вам показывал, как ловятся сегфолты — это как раз связь с операционной системой. И здесь просто необходимо иметь связь с низким уровнем. Более того, нам еще нужна предсказуемость и непрерывность исполнения и полный контроль над ним.
Представьте, что вы написали на джаве сборщик мусора. Вот он работает во время работы приложения. И сам он тоже останавливается для того, чтобы пособирать мусор. Это наверняка будет неожиданно, и паузы могут получиться ну совсем неприятные.
Значит, идем к С++? Не стоит торопиться. Давайте сначала посмотрим, а что в проекте Graal? В нем есть интересная подпапка substratevm. Про нее очень скромно написано, что это фреймворк для AOT-компиляции с Native Image. На самом деле это полноценный рантайм для Native Image. На чем же он написан?
Заходим в папку и видим GC.java. Получается, что как раз-таки сборщик мусора написан на джаве. Это интерфейс, у него есть реализация. И в одной из его реализаций есть такой интересный метод collectWithoutAllocating:

Это самое настоящее тело сборщика мусора, где внутри всё и происходит. А еще на нем есть интересные аннотации. Во-первых, @Uninterruptable — дескать, его нельзя прерывать. А во-вторых, @RestrictHeapAccess — нельзя аллоцировать. Согласитесь, будет странно, если ваш сборщик мусора начнет аллоцировать память. Вроде бы он должен делать всё наоборот. Соответственно, аннотация @RestrictHeapAccess как раз и говорит, что никаких new там быть не должно.
Эти аннотации обрабатываются компилятором, который тоже под контролем во всем проекте GraalVM. В результате вам гарантируется, что там всё будет замечательно. Вы как бы пишете на джаве, но при этом джавовский код получается хорошим.
А вот что про Substrate VM говорят сами оракловцы:

https://www.oracle.com/technetwork/java/jvmls2016-wimmer-3125555.pdf
То есть это джава с некоторыми ограничениями. Но на это можно посмотреть и по-другому. Например, в самой джаве вы же не можете сказать, что вот этот метод должен быть без аллокации, а в Substrate VM вам такую фичу дают. То есть в каком-то смысле это расширение джавы для того, чтобы писать вот такой системный код.
В итоге на чистой джаве рантайм не напишешь, но можно делать свои специализированные полу-managed языки. Пример — как раз Substrate VM / SystemJava.
Что в итоге
Глобально получается так: что рантаймы, что компиляторы в современных виртуальных машинах можно писать на managed-языках (Java, Scala, их вариации для рантайма). И это дает нам много интересных плюшек. Например, разработка в IntelliJ IDEA, юнит-тесты, которые вы можете запускать просто на JUnit, всякие code coverage, более низкий порог входа в разработку и так далее. То есть не так страшен черт. Современная разработка виртуальных машин может быть довольно близка к обычной джава-разработке.
Отлаживай так, словно никто не видит
С разработкой разобрались, а что с отладкой?
Допустим, вы совершили какую-нибудь ошибку. Например, в коде сборщика мусора. Что это значит?

После этого могут начать собираться живые объекты, и это очень неприятно. Это значит, что у вас могут происходить развалы виртуальной машины (чего вообще не должно никогда происходить). Но это полбеды.
Гораздо хуже, когда у вас начнет происходить некорректное поведение. Например, вы пытаетесь породить какую-нибудь пдфку программой на джаве, а у вас вместо этого выводятся всякие каракули. Если какие-то объекты оказались побитыми сборщиком мусора, такое вполне может произойти.
Может быть и обратная ситуация. Допустим, вы ошиблись так, что вы не собираете мертвые объекты. Формально, это не баг, но это будут утечки памяти, и ваши клиенты вам за это спасибо не скажут.
Ладно, скажете вы, все мы люди, подумаешь, ошиблись. Давайте возьмем и отладим это. А как отладить? Зачастую такие проблемы проявляются раз в N запусков, где N может быть ~10000. Самый долгий баг, который я отлаживал, проявлялся раз в год. При этом каждую ночь шло нагрузочное тестирование на десятки тысяч тестов. За две попытки я его вроде бы починил. Может быть еще через пару лет он снова выстрелит, но пока прошел третий год, ничего не упало — я считаю, что баг починен.
Так что если вы попытаетесь что-то проявить в отладчике, то шансы у вас довольно несерьезные. Более того, отладчик вам еще и тайминги побьет, и в результате у вас точно ничего хорошего не получится. Вы можете сказать: а давайте старым дедовским способом будем вставлять логи. Но логи тоже не помогут — диска не хватит.
Допустим, вы хотите логировать аллокацию каждого объекта или очистку памяти из-под каждого объекта. Объектов миллиарды, они создаются, пропадают, прокачка памяти может достигать сотен гигабайт или уже даже терабайт. У вас никакого диска не хватит. Вы просто не сможете записать эти логи, а потом не сможете их обработать. Поэтому здесь тоже не получится ничего хорошего. Что с этим делать?
В качестве отладки здесь работает измененная психика рантаймщика. Все рантаймщики — ужасные параноики. Если посмотреть на код любого рантайма любой виртуальной машины, он весь покрыт ассертами, иногда, казалось бы, совсем очевидными. Но они и правда нужны, потому что если вдруг по какой-то причине какой-то инвариант разломается, то самым неожиданным образом ваша виртуальная машина тоже может разломаться. Так что — куча ассертов.
Если вдруг что-то все-таки ломается, мы оставляем ловушки. «Если вдруг что-то пошло не так, давай вот здесь не просто ассерт упадет, а пусть у нас будет огромная печать: мы не просто сохраним хипдамп, мы еще вычислим много всего и распечатаем это всё в отдельный специальный файл». А потом мы терпеливо, несколько недель или месяцев, ждем, пока этот развал случится, и жадно читаем полученный лог.
Есть еще один инструмент — формальная верификация. Иногда это звучит как магия, но современная наука уже довольно хорошо продвинулась к тому, чтобы математически доказывать, что у вас нет никаких багов в вашем коде. И рантаймы, и компиляторы — это область, в которой очень хочется строить формальные модели и ими доказывать, что всё в порядке. Некоторые части нашего рантайма мы вот таким образом формально верифицировали. И были более-менее спокойны, что там нет никаких ошибок.
Когда вы ошибаетесь, это еще полбеды. Бывают гораздо более странные случаи, которые вызывают самый настоящий эффект бабочки.
Эффект бабочки
В Excelsior мы, JVM-инженеры, сами сидели на саппорте. У каждого была особая смена, когда ты откладываешь все дела и садишься отвечать клиентам. Если у них что-то ломается, ты пытаешься им помочь и всё отладить, разобраться, что пошло не так.
И вот сижу я как-то на саппорте, мне пишет клиент. Говорит, знаете, у меня на вашей JVM джава-приложение разваливается, вот крэш-лог. Смотрю крэш-лог, он указывает куда-то в дебри msvcr100.dll (это происходит на винде), поэтому выходит, что это где-то в нативном коде что-то сломалось, а не у нас. Конечно же на нашей стороне ничего не воспроизводится, такие вещи вообще редко когда воспроизводятся. Я уже готовлюсь писать плохое письмо и говорить, что дело скорее всего не в нас, и как вам помочь — непонятно. Но в последний момент решают погуглить лог такого развала. И оказывается, что у очень многих людей на разных виртуальных машинах всё разваливается одинаково, всё точно так же уходит в нативный код, в один и тот же метод в msvcr100.dll. И всех людей, у кого это разваливается, есть еще кое-что общее: Windows 10 Creators Update и вот такая папка на рабочем столе:

GODMODE.{ED7BA470-8E54-465E-825C-99712043E01C}
Это какой-то хитрый бэкдор в винде. Если создадите такую папку, то нажимая на нее, вы получаете контрольную панель, шорткаты к настройкам винды. Называется это «Папка Бога», на ютубе есть куча роликов про то, как ее создать и использовать (кто бы мог подумать, что кому-то это может быть интересно и полезно).
И у всех, кто жалуются на развалы, оказывается такая папка на рабочем столе. Я спрашиваю у нашего клиента: «А у вас совершенно случайно на рабочем столе нет папки GODMODE…?» Я представляю, что он подумал, это было как раз в разгар историй про русских хакеров, подумал небось, что мы за ним следим. Еще больше он удивился, когда я попросил удалить эту папку, и после этого у него всё заработало.
Что это было? В Windows 10 Creators Update изменилось поведение системного вызова IShellFolder::GetDisplayNameOf(...). При некоторых входных данных она начала возвращать NULL, а раньше такого не было. В JDK есть какое-то количество нативных методов на С, которые дергают этот системный вызов, не проверяя результат. Вот и получается: поменяли системный вызов, поведение всех нативов изменилось, и в результате что у нас, что на HotSpot, всё начало взрываться. При этом проявлялось это далеко не у всех пользователей: нужно было, чтобы звезды сошлись — правильное приложение, правильная версия Windows, папка бога на рабочем столе… Вот такая комбинация вызывала случайные развалы.
Может показаться, что это какая-то очень странная байка, но на самом деле в разработке JVM похожие истории случаются часто. Если вы что-то изменили, вдруг может пойти эффект бабочки совсем в другой части виртуальной машины. Или даже какой-то другой писатель операционной системы что-то у себя изменил, и всё может начать ооочень странно разваливаться именно в вашем коде.
В общем, отладка багов в JVM — это интересная детективная история. Обычно когда ты ее разматываешь, ты под конец как детектив восклицаешь: «Так вот кто убийца!». Это классное ощущение. Но в процессе придется, конечно, помучаться. Отдельно доставляет, что на поведение сильно влияют операционная система и железо. И зачастую, если в вашем джава-приложении начинаются случайные крэши, стоит проверить железо. Вы как пользователь можете запустить memtest и проверить, не побилась ли у вас память. Потому что настолько плотно и хорошо расставлены ассерты в рантайме, что если что-то ломается — это абсолютно невозможная история, и скорее всего что-то пошло не так с железом. И здесь как раз парадоксальным образом использование managed-языков программирования вроде джавы добавляет вам безопасности при разработке компиляторов и рантаймов.
Клиенты — Java-программисты
Еще один аспект нашей работы — это тот факт, что наши клиенты — это Java-программисты. В целом это очень круто. Любой разработчик тулов меня поймет: когда твои клиенты — тоже программисты, вы с ними на одной волне, у вас общая культура. Если у тебя что-то разваливается, они тебя прощают, потому что думают — ну это ж тоже программист, понятно, что у них там что-то может не работать.

В общем, приятная история. До тех пор, пока эти программисты не лезут в sun.misc.Unsafe. Потому что после этого начинаются очередные ужасы.
История из жизни. Какое-то количество клиентов стали репортить нам, что они используют библиотеку Kryo, и у них внезапно полезли вот такие стек трейсы:

Исключительно на нашей виртуальной машине. На HotSpot это не проявляется. Значит, мы что-то сломали. Идем разбираться. Стек-трейсы идут вот из такого кода:
offset = unsafe().objectFieldOffset(f);
…
public Object getField(Object object)
throws IllegalArgumentException, IllegalAccessException {
if (offset >=0) {
return unsafe().getObject(object, offset);
} else
throw new KryoException("Unknown offset");
}Kryo же библиотека для сериализации/десериализации, так что логично, что она работает с офсетами. Получили офсет-поле через objectFieldOffset(f) из unsafe(). Потом берем getField() и проверяем: смотрите, офсет, который нам сюда передали, обязательно больше или равен 0, иначе выкидываем ошибку. Звучит чертовски логично, какие офсеты могут быть отрицательными? Это же действительно странно. Офсеты должны начинаться с нуля.
Но на самом деле, если посмотреть на метод objectFieldOffset(), там английским по белому написано:
/**
* Reports the location of a given field in the storage
* allocation of its class. Do not expect to perform any
* sort of arithmetic on this offset; it is just a cookie
* which is passed to the unsafe heap memory accessors.
* ...
*
*/
@ForceInline
public long objectFieldOffset(Field f) { ... }Эти штуки — это не офсеты. Не важно, что они так называются, это просто какие-то очень специальные значения, куки, вы не можете проводить с ними никакие арифметические операции. Даже сравнивать их не можете, это не числа, это просто какие-то волшебные штуки.
У нас они получились отрицательными. Вопрос, почему? Всё очень просто. Если посмотреть на офсеты, то это long. long — это 64 бита. Таких длинных офсетов не бывает, не нужно столько места. Так вышло, что это long, но бывает. Обычно используются какие-то нижние биты. Вот у меня офсет 12, 4 бита я использовал, еще 60 свободно.

И кажется неплохой идеей взять старшие биты, которые никогда не будут заняты, и что-то туда сложить. В нашем случае мы туда складывали дополнительную информацию о том, было ли это поле интерфейсного типа или нет, и если да, еще немного мета-информации. Имеем право. Эта информация нужна только для unsafe, мы ее только там и обрабатывали, и мы ее использовали, чтобы unsafe работал быстрее. Мы его разгоняли по сравнению с тем, как он работает в HotSpot. Казалось бы, делали доброе дело.
Но есть небольшая проблема: если в верхние биты офсета что-нибудь записать, то это будет уже не 12, это будет (long) offset == -6917529027641081844. Ну и если вы начинаете дословно проверять это значение на >=0, то вы увидите здоровое отрицательное число. Правка неправильная. К счастью, это опенсорс, так что мы отправили пулл-реквест, что надо проверять на специальную константу, которая заведена в этом unsafe:
public Object getField(Object object)
throws IllegalArgumantException, IllegalAccessException {
if (offset != Unsafe.INVALID_FIELD_OFFSET) {
return unsafe().getObject(object, offset);
} else
throw new KryoException("Unknown offset")
}И только если оказалось, что это равно специальной константе, тогда выбрасывай исключение, иначе доставай объект. Я думал, что такой пулл-реквест никогда не примут (там был довольно длинный текст, почему нельзя пользоваться unsafe в таком контексте). Думал, нас пошлют, но мейнтейнер моментально всё замержил и поблагодарил. Это было очень приятно. Это как раз тот момент, когда чувствуешь: клиенты — Java-разработчики. Это очень классно.
Ну а глобально вывод такой: приватные API лучше не использовать. Понятно, что всем надо, очень важно взять unsafe и что-то там поделать. Если вы это делаете, то будьте готовы в развалам и плохой работе с кастомными JVM. Речь даже не о том, что вы берете какую-то другую JVM. Вы можете просто обновиться до следующей версии джавы, внутреннее поведение с unsafe изменится, и в результате у вас всё может пойти как-то по-другому. Если вы хотите быть абсолютно уверенным, идите в исходники своей виртуальной машины и проверяйте, например, что офсеты у вас обрабатываются так, как вы думаете. Тогда можно делать такие правки, но опять-таки, под кучей комментов и объяснений.
Чтобы у вас не было ощущения, что я ругаю джава-разработчиков и говорю, какие JVM-разработчики молодцы, вот вам история, как JVM-разработчики всё сломали.
Почему JVM-разработчики так долго всё делают
В джаве есть интересная фича: на любом объекте можно синхронизироваться.
synchronized (obj) {
…
}Фича сомнительная, многие языки ее не поддерживают, только на каких-то специальных объектах. А в джаве можно синхронизироваться на всем подряд. Ну а раз она есть, нужно ее как-то реализовывать. Самое базовое и понятное решение, которое есть — это когда мы у себя пришли в synchronized и создаем объекту зеркальный объект, который будет представлять из себя нативный монитор. И уже на нем мы будем синхронизироваться, через средства операционной системы засыпать или потом просыпаться и так далее.

Хорошее решение, правда, работает довольно медленно. Более того, генерация новых объектов — это очень неприятно, нужно потом думать, куда их деть и так далее. Поэтому стали думать над оптимизациями, как сделать это лучше.
Первая идея для оптимизации: чаще всего, даже если вы пишете synchronized, никакой конкуренции нет. У вас всё равно в один момент времени только один тред приходит и захватывает объект. Исходя из этой идеи сделали первую оптимизацию, которая называлась Thin lock: вместо настоящего объекта с нативным монитором просто на стеке аллоцировали объект с Thin lock, с помощью которого через обычные CAS-ы происходила синхронизация, что уже гораздо быстрее.

Если вдруг contention случался, то тогда можно откатиться к предыдущей схеме. Но и этого недостаточно. Есть еще одна идея для оптимизации.
Вторая идея для оптимизации: зачастую вообще только один тред входит в synchronized block. Ну просто код так написан, что метод synchronized, а никакого многопоточного кода нет, всё происходит локально. И в таком случае можно пойти дальше и уже даже не делать thin lock, а просто внутрь объекта, в его заголовок записать id треда при первом посещении synchronized, который туда и будет приходить. Тогда первый synchronized будет чуть дороже, зато во всех остальных даже CAS делать не нужно будет, мы сможем просто обычной проверкой узнавать, захватили мы его или нет. Это знаменитая оптимизация Biased Locking, которая реализована буквально во всех виртуальных машинах и даже в HotSpot, но до Java 19.

Звучит очень круто и в общем-то просто. Но есть нюанс… Если вы посмотрите внутрь кода того же HotSpot, то там будет нарисована примерно вот такая схема, в каких стейтах бывает объект относительно этого bias:

Обратите внимание, что на схеме сказано simplified, то есть это упрощенная схема, которая на самом деле выглядит немного сложнее. А теперь представьте, что вы рантайм-инженер и вам нужно сделать новую фичу, которая явно сильно трогает трединг и синхронизацию. Например, в проекте Loom вы хотите сделать новые виртуальные треды, которые работают явно как-то по-другому, в том числе в синхронизации. Берем эту схему и умножаем на два. Получается еще более монструозная история.
Это сильно ухудшало жизнь JVM-разработчикам. Более того, были и до сих пор остаются контр-примеры среди пользовательского кода, которым Biased Locking только мешает. Например, в Одноклассниках на Cassandra всегда был отключен Biased Locking, потому что конкретно в случае Кассандры это просто пессимизация, ухудшение производительности.
Что с этим сделать? Конечно же удалить! В JDK 15 Biased Locking задепрекейтили и отключили, в JDK 19 удалили. Всё замечательно, разделались с техническим долгом, у пользователей всё ускорилось, все должны быть довольны, разработчики могут делать новые крутые фичи.
Правильно? Нет. Пару недель назад в мейлинг лист написал Эндрю Динн из RedHat и говорит: «У нас клиенты жалуются, что у них вот такой, казалось бы, очень простой код ни с того, ни с сего просел на новой джаве».
boolean contentChanged = false;
BufferedInputStream oldContent = ...;
BufferedInputStream newContent = ...;
try {
int newByte = newContent.read();
int oldByte = oldContent.read();
while (newByte != =1 && oldByte != -1 && newByte == oldByte) {
newByte = newContent.read();
oldByte = oldContent.read();
}
contentChanged = newByte != oldByte;
} catch (IOException e) {
contentChanged = true;
}
...Что делает этот код: у него есть два BufferedInputStream, мы по очереди читаем из них байтики и сравниваем их. И внезапно почему-то на Java 19 всё стало как-то медленно работать. Потому что метод read — synchronized, в коде контеншена нет, мы всё делаем локально, но без Biased Locking оно просто просело:
public synchronized int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}Насколько именно просело, решил выяснить Алексей Шипилёв: https://gist.github.com/shipilev/71fd881f7cbf3f87028bf87385e84889
Как выглядели бенчмарки? У нас просто есть readOut, который берет какой-то InputStream и из него побайтово что-то читает. И есть два бенчмарка. Первый — это мы просто передаем FileInputStream:
private void readOut(Blackhole bh, InputStream s) throws IOException {
int b;
while ((b = s.read()) != -1) {
bh.consume(b);
}
}
@Benchmark
public void fis(Blackhole bh) throws IOException {
try (InputStream s = new new FileInputStream(file)) {
readOut(bh, s);
}
}А второй — мы туда передаем BufferedInputStream:
@Benchmark
public void fis_bis(Blackhole bh) throws IOException {
try (InputStream s = new BufferedInputStream(new FileInputStream(file))) {
readOut(bh, s);
}
}Сравниваем и выясняем, что версия с BufferedInputStream, которая по идее должна быть быстрой (она правда быстрая), просела в Java 19 больше чем в два раза. Просто с ходу код, который 20-25 лет работал замечательно, стал работать в два раза медленнее. И с этим абсолютно ничего нельзя сделать, кроме того чтобы переписать его на какие-то более современные средства.

И получилось, что тут была вилка: слишком сложный код в рантайме, который трудно поддерживать, или клиенты, у которых теперь тормозит код (причем у «молчаливых» клиентов, у которых все всегда было замечательно). Хорошего решения нет, но удаление biased locking выходит боком: так как у вас даже нет ручки, чтобы его включить или выключить, вы подставляете пользователя, который раньше этим совершенно спокойно пользовался.
В других виртуальных машинах biased locking остался, и зачастую он сделан проще. Схема, о которой я чуть раньше рассказывал, у них тоже довольно монструозная, но все же попроще, так что поддерживать biased locking проще, и может быть это хороший путь, по которому и стоило пойти. Но однозначного ответа тут нет.
Что в итоге
Разработка JVM — это вызов, научный и инженерный. Научный, потому что вы расширяете научное знание, чтобы придумать какие-то новые оптимизации в компиляторе или алгоритме сборщика мусора, то есть то, что еще никто вообще в мире не придумывал. Инженерный, потому что, например, в обработке неявных исключений ничего супернаучного нет, но это крутой инженерный трюк, который тоже очень интересно проделывать.
Разработка JVM — это еще и детектив. Когда у вас что-то разваливается и вы очень долго это отлаживаете, это буквально как будто вы читаете томик про Шерлока Холмса, где вы и Холмс, и Ватсон и зачастую Мориарти.
И еще это общение с клиентами Java-программистами, что обычно очень здорово, пока они не забредают в sun.misc.Unsafe.
Наконец, несмотря на все те ужасы, которые мы раз за разом рассказываем вам на джава-конференциях, люди продолжают спрашивать меня: вот я джавист, можно мне стать JVM-инженером? Или гномом можно только родиться?
Конечно, можно. Я знаю довольно много примеров таких людей, которые начинали как джависты и потом в какой-то момент им нужно было всё глубже и глубже опускаться в дебри, и они в конце концов превращались в гномов. Если вы вдруг задумываетесь об этом, пожалуйста, начните с чтения статей Алексея Шипилёва. Если вам нравится, что там написано, если вам кажется, что это классный вызов, то это хороший признак.
Ну а потом смотрите на исходники:
github.com/openjdk/jdk/tree/master/src/hotspot
github.com/oracle/graal
Сам HotSpot уже давно на гитхабе, и несмотря на то, что это плюсовый код, вы вполне можете пойти посмотреть на эти сорцы и понять, нравится вам с таким работать или нет. Ну и более милые современные проекты вроде Graal тоже в открытом доступе. Имея джава-бэкграунд, можно вполне начать разбираться с тем, что там происходит. А потом можно взять какой-нибудь issue, разобраться и решить. Например, вот что добавилось в ноябре в проекте Graal:

Вместе с OOM безусловно создается core dump. Наверное, это неправильно, нужно исправить!
Или сделайте что-нибудь в грааль-компиляторе. Дел очень много. Приходите и пробуйте. Это прекрасное опенсорсное комьюнити, и у вас всё получится.