Python ile Dizi Botu Yapmak
🕊 Bu döküman @KekikAkademi için oluşturulmuştur. ✌🏼

Dostlar merabayın,
Bu yazımızda requests ve BeautifulSoup modüllerini kullanarak dizibox sitesindeki bütün dizilerin bilgilerini çekmeyi öğreneceğiz.
Burada öğrenecekleriniz ile istediğiniz websitesinden istediğiniz veriyi rahatlıkla ayıklayabileceksiniz..
Hadi, hemen başlayalım;
Senaryo
- Siteye istek(
request) yolla ve sana yanıt versin. {Response [200]} - Sitedeki bütün dizi linklerini belirle. (
Web Crawling) - Belirlenen bağlantıları(linkleri) gez.
- Gezdiğin linklerden dizinin: Ad, Açıklama, Ülke ve Tür bilgilerini toparla.
(Web Scraping)
Web Crawling
Neydi bu olay; herhangi bir site üzerinde gezinmek ve hedef site üzerinde yer alan linkleri toplamak demekti.
Web Crawler’ın temelde yapacağı şey şudur; belirlenen adresin tüm linklerini taramak ve listelemektir. Daha sonra da listelediği bu linklere sırasıyla gider.
Bu işlemi otomatize etmek de Web Crawler kavramını doğurur.
Web Scraping
Neydi bu olay; Web crawler bir link’e uğradığı zaman devreye Web Scraping kavramı girer.
Web Scraping, link’teki belirtilen alanların toplanması işlemidir. Yani bir nevi; veri toplama veya yığından veri çıkarma olayıdır. Web Crawler ve Web Scrapingbirbirleriyle partner olan kavramlar.
Kod Zamanı
Öncelikle biz bir robot yazıyoruz değil mi?
Bakalım ilgili site robotlara ne tavsiye etmiş?
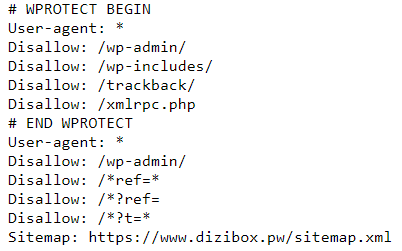
♦ Sitemap'e bakıp kendimize uygun haritayı bulalım ve oraya istek yollayalım.
♦ Ardından bir betik oluşturup kütüphaneleri ekleyerek başlayalım;
import requests # Websitelerine istek atmamızı sağlayacak arkadaş from bs4 import BeautifulSoup # HTML veya XML dosyalarını okuyan arkadaş
♦ Ardından isteğimizi gönderip cevabımıza bakalım;
link = "https://www.dizibox.pw/sitemap-tax-diziler.xml" istek = requests.get(link) # link'e istek gönderiyoruz print(istek) # <Response [?]>
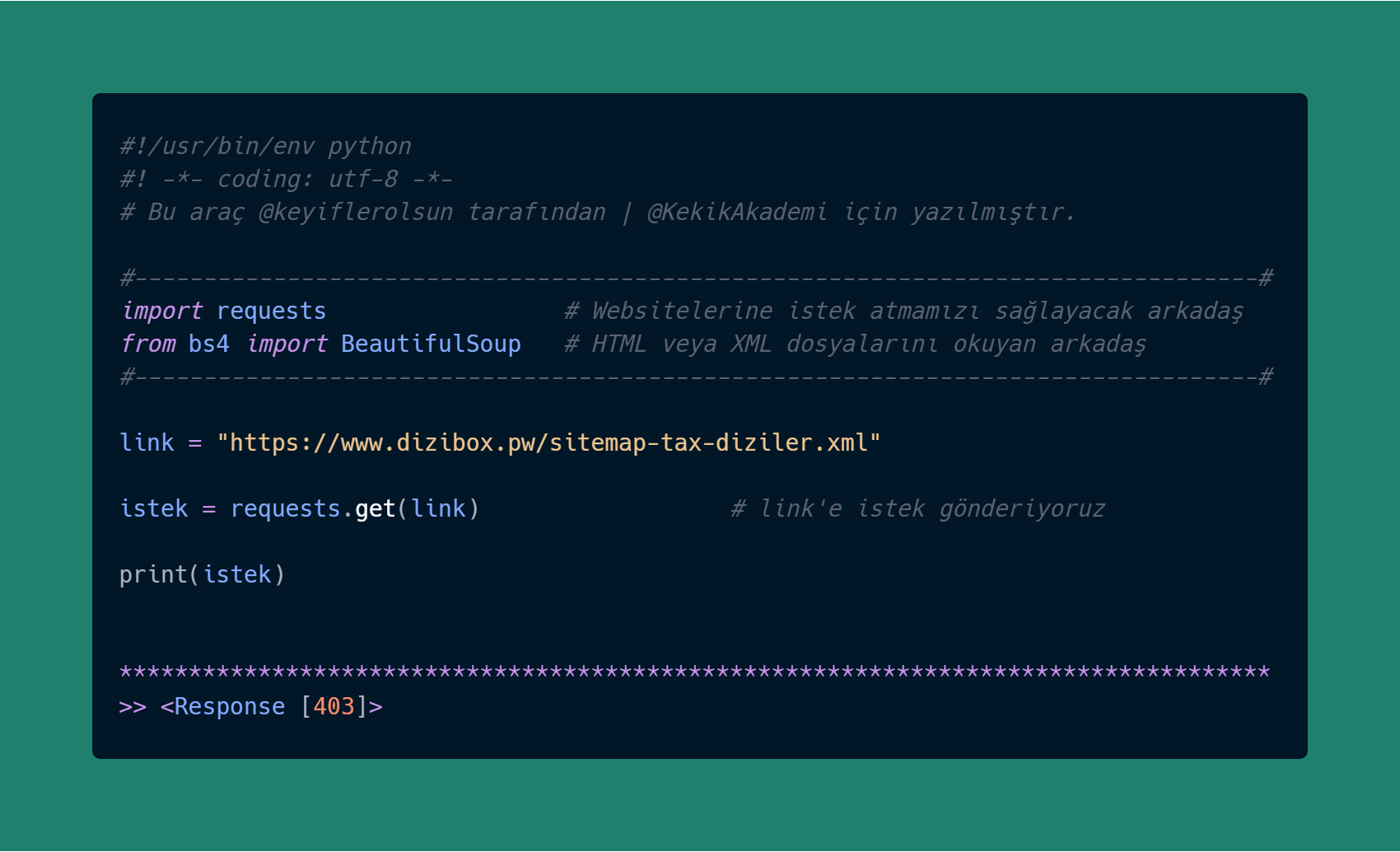
Ne oldu? 403 verdi.. Yani?
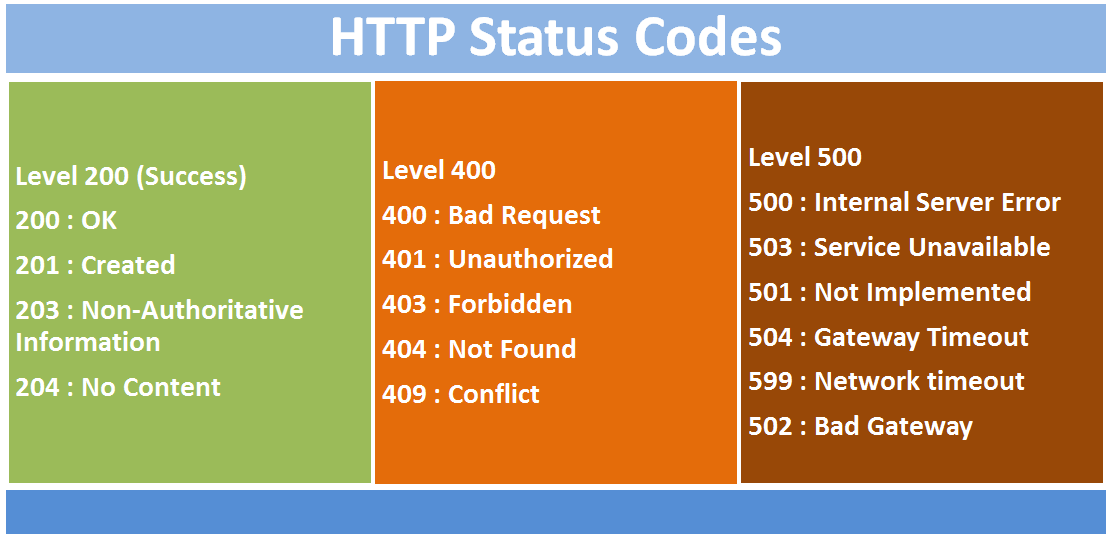
Neymiş 403 ?
Forbidden Erişim Engellendi
Neden Peki ?
İstek yolladığımız site bizi istemiyor olabilir.robots.txt ne diyordu?
Her türlü User-Agent yani kimlik kabulüm diyordu.
User-Agent tanımlamamız gerekiyor..
Deneyelim;
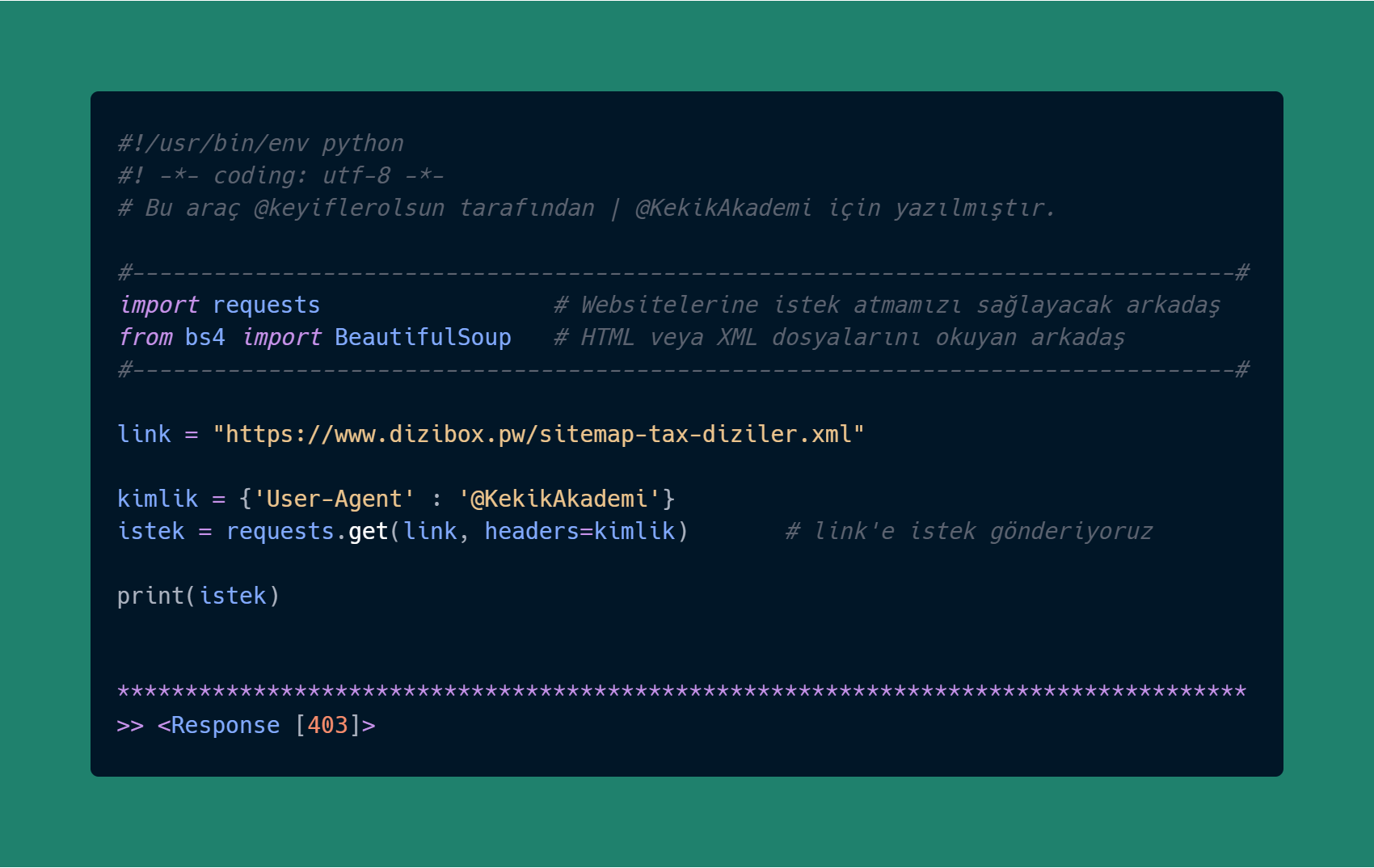
Neymiş? Yalan Söylemiş :)
Şimdi gerçek bir kimlik sunalım:
iyi hoş da; Gerçek Kimliği nasıl bulacağız?
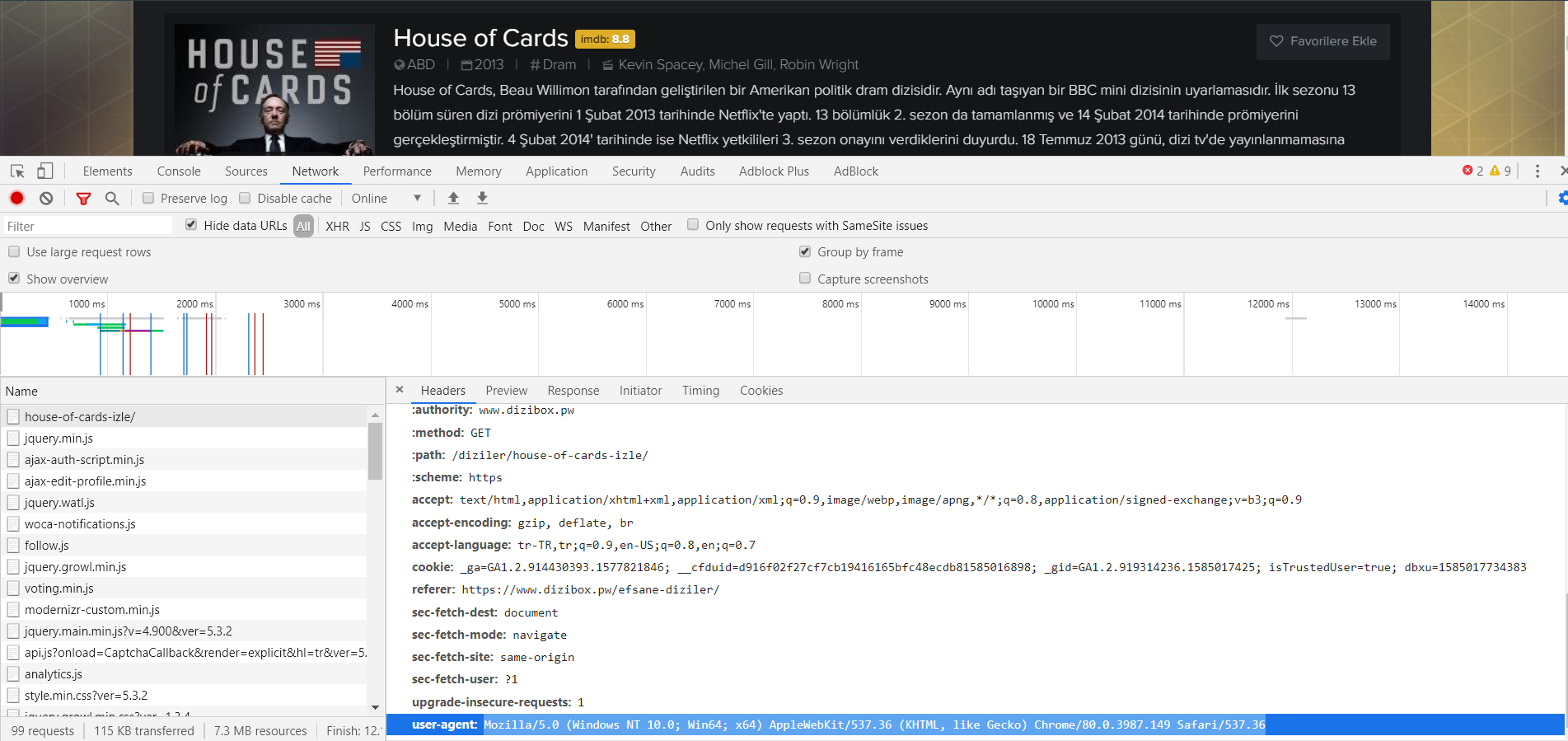
- Tarayıcımızla gerçek bir kullanıcı olarak websitesine gireceğiz.
- Sağ tıklayıp "Sayfayı İncele" veya "Öğeyi Denetle" olan bölümü açacağız.
- "Network" sekmesi altındaki "Headers" a geleceğiz.
- Kendimiz, şuan hangi kimlik ile istek attığımıza bakacağız.
- Bu kimliği kullanarak istek atmayı deneyeceğiz.
#!/usr/bin/env python
#! -*- coding: utf-8 -*-
# Bu araç @keyiflerolsun tarafından | @KekikAkademi için yazılmıştır.
#---------------------------------------------------------------------------------#
import requests # Websitelerine istek atmamızı sağlayacak arkadaş
from bs4 import BeautifulSoup # HTML veya XML dosyalarını okuyan arkadaş
#---------------------------------------------------------------------------------#
link = "https://www.dizibox.pw/sitemap-tax-diziler.xml"
# Gerçek Bir Tarayıcı Olmamız Lazım!
kimlik = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
istek = requests.get(link, headers=kimlik) # link'e kimlik bilgimizle istek gönderiyoruz
print(istek) # <Response [?]>
Haarika !
♦ Artık dönen bir verimiz var ve bunu BeautifulSoup ile işleyeceğiz..
soup = BeautifulSoup(istek.text, "html5lib") # Gelen veriyi html5lib ile ayrıştırmaya başlıyoruz print(soup)
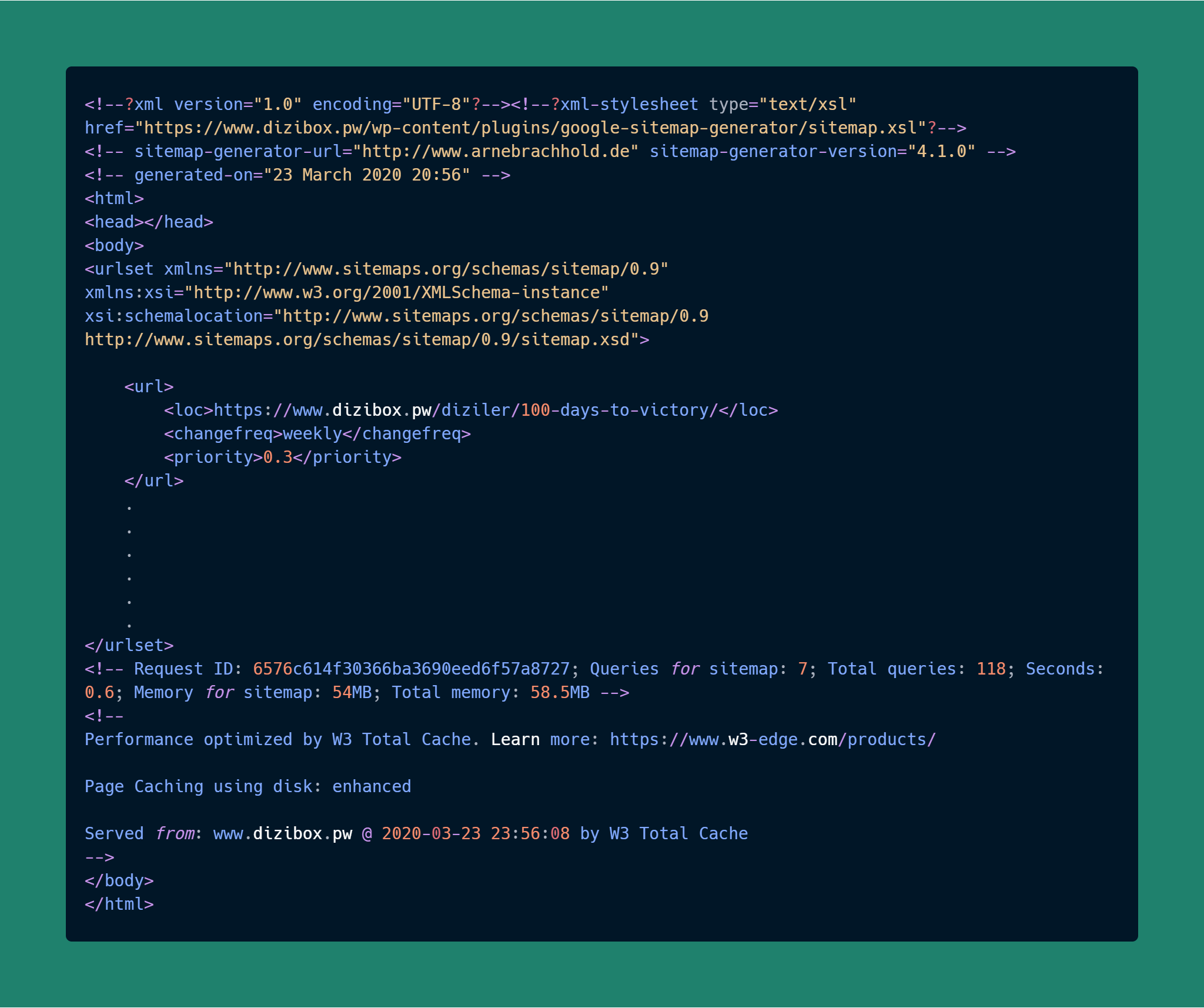
Evveeet!
Sonunda tarayıcı üzerinden erişebildiğimiz yere python ile ulaşmayı başardık!
Sayfanın tamamı elimizde. Şimdi ayıklama zamanı!
Ekranımızda ne var bize lazım olan? Dizi Bağlantıları(Linkleri)..
♦ Nerede bu linkler? <loc> diye bişeyin içinde.. Ayıklayalım!
print(soup.find('loc')) # Kaynak Kodundaki <loc>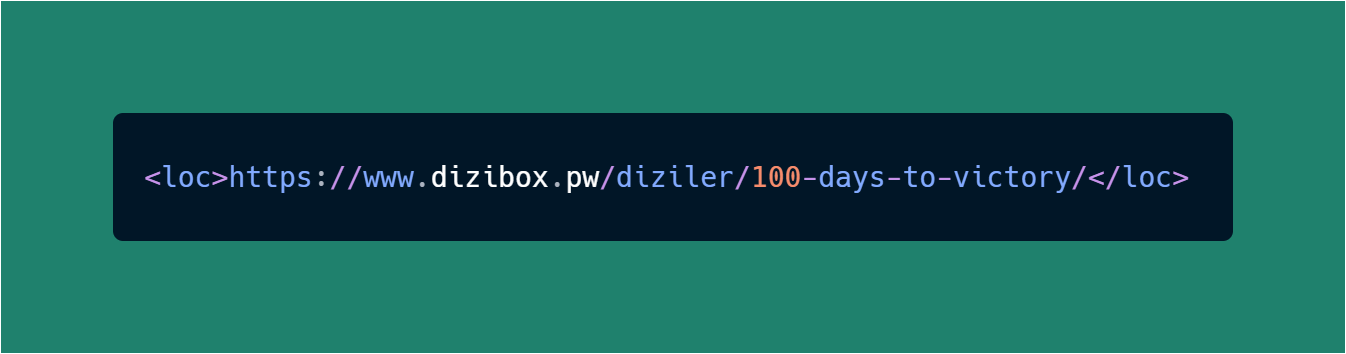
Tuttuk Mu? :)
soup.find diye ayıkladık ya hani; birde bunun findAll versiyonu var ;)
print(soup.findAll('loc')) # Kaynak Kodundaki <loc>'lar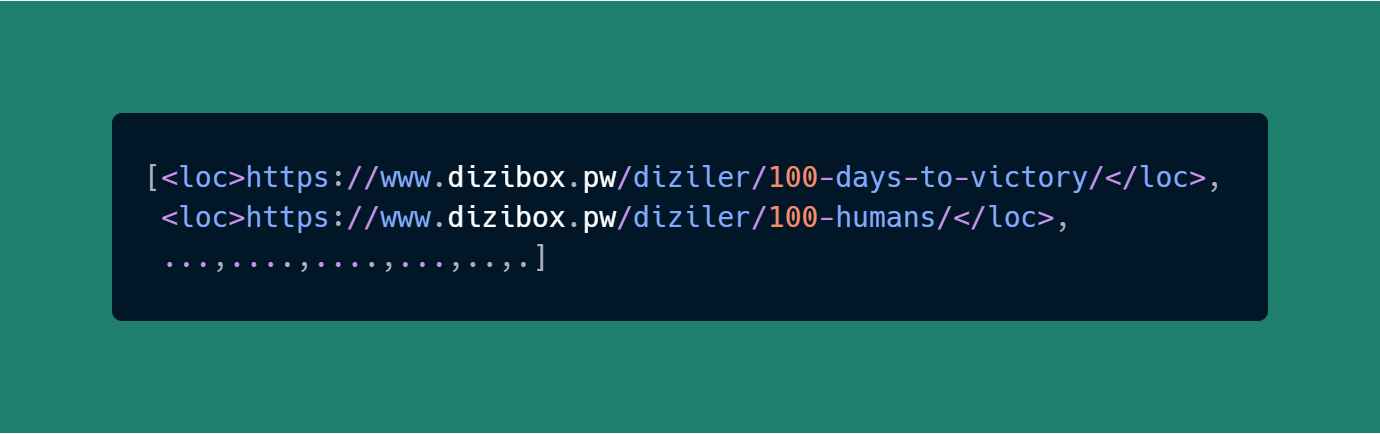
Ne Oldu? Hepsini tablo içinde verdi..
bu findAll olan arkadaşı for döngüsü içerisinde kullanırsak; yinelenebilir bir nesne döndürüyor...
for gelenlink in soup.findAll('loc'):
print(gelenlink)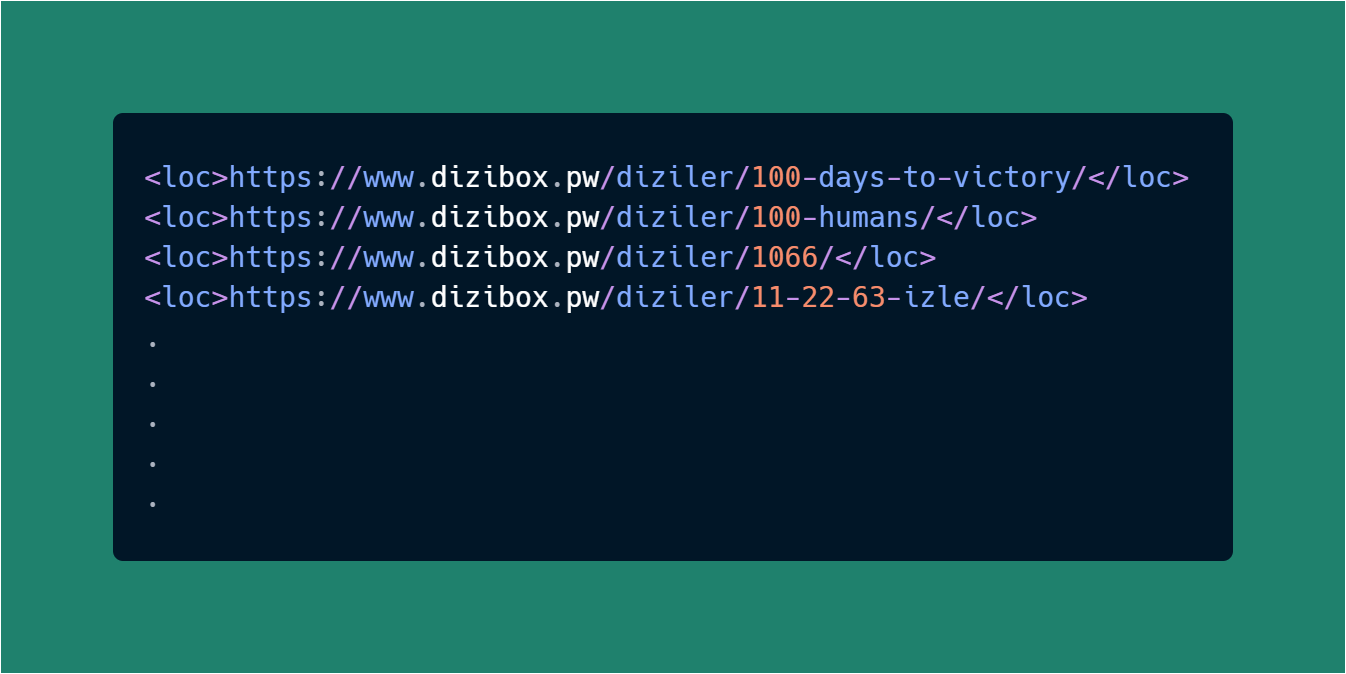
Hoppalaaa? Tamam düzgün verdi ama!!!
Kardeşim dur iki dakika sana aşama aşama öğretiyoruz .
Geldi mi babacım satır satır düzgünce? Geldi.
Şimdi kod bloğundan sıyırmak için sadece şunu yapıcaz;
for gelenlink in soup.findAll('loc'):
print(gelenlink.text)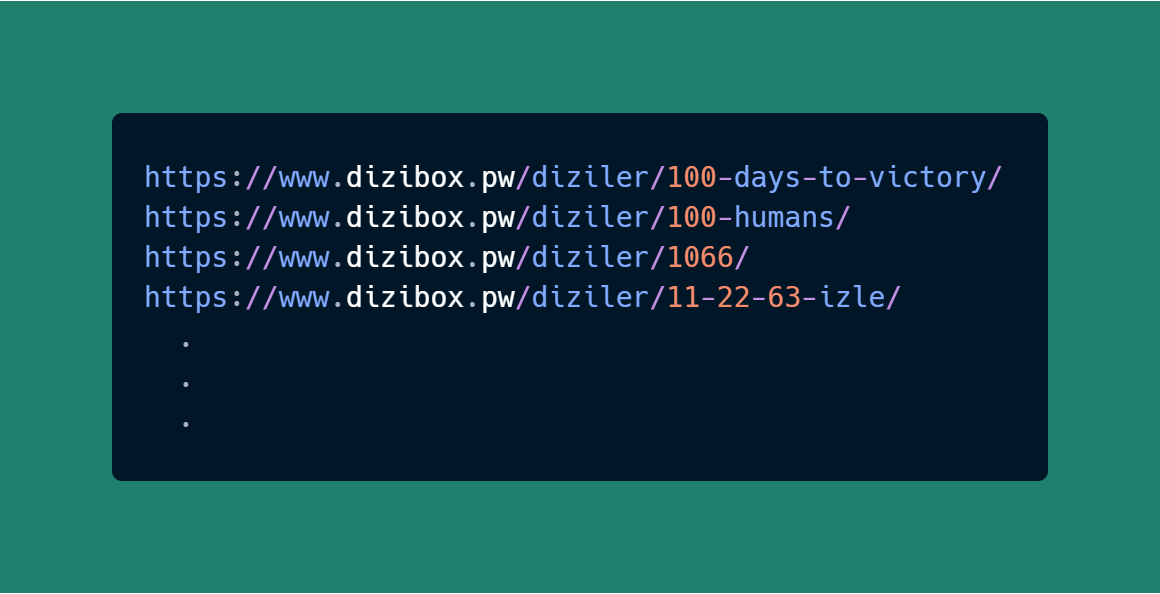
ulan sadece .text ekledin :) Atla deve değil, sen asıl olayı seyret şimdi :)
Kodları Toparlayalım
#!/usr/bin/env python
#! -*- coding: utf-8 -*-
# Bu araç @keyiflerolsun tarafından | @KekikAkademi için yazılmıştır.
#---------------------------------------------------------------------------------#
import requests # Websitelerine istek atmamızı sağlayacak arkadaş
from bs4 import BeautifulSoup # HTML veya XML dosyalarını okuyan arkadaş
#---------------------------------------------------------------------------------#
#----------------------------------------------------------------------------------------------------------------------#
link = "https://www.dizibox.pw/sitemap-tax-diziler.xml"
# Gerçek Bir Tarayıcı Olmamız Lazım!
kimlik = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
istek = requests.get(link, headers=kimlik) # link'e kimlik bilgimizle istek gönderiyoruz
soup = BeautifulSoup(istek.text, "html5lib") # Gelen veriyi html5lib ile ayrıştırmaya başlıyoruz
#----------------------------------------------------------------------------------------------------------------------#
#-------------------------------------------------------------#
#print(istek) # <Response [200]>
#print(soup) # Kaynak Kodlar
#print(soup.find('loc')) # Kaynak Kodundaki <loc>
#print(soup.findAll('loc')) # Kaynak Kodundaki <loc>'lar
#-------------------------------------------------------------#
for gelenlink in soup.findAll('loc'):
print(gelenlink.text)Senaryomuzun yarısını tamamladık.
Neydi? Siteden düzgün yanıt al ve bütün dizi linklerini toparla.
Şimdi bu gelen linklere tek tek girme vakti.
for dizi_adresleri in soup.findAll('loc'): # Örümceğimizi Başlattık!
diziLink = dizi_adresleri.text # Crawl ettiğimiz linkler = Dizi Linkleri
# Bu linklerin içine girelim
dizi_istek = requests.get(dizi_adresleri.text, headers=kimlik) # Her gelen link'e istek atıyorz
dizi_icerik = BeautifulSoup(dizi_istek.text, "html5lib") # html5lib ile parse ediyoruz
print(f"Nerdeyim? : {dizi_adresleri.text}") # istek attığımız yeri ekrana yazdır
print(dizi_icerik) # Kaynak Kodlar ekrana yazdır
break # Döngüyü Kır > Linklerin Hepsini Tarama!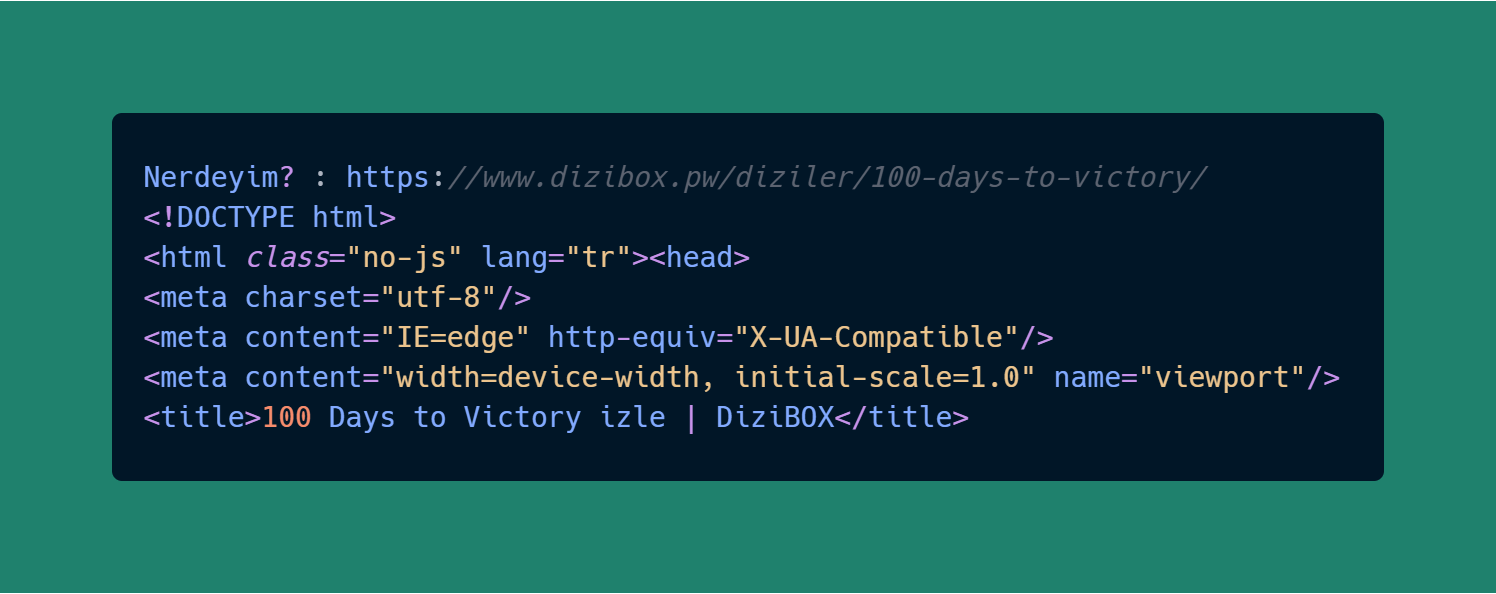
Naptık?
- Örümceği başlat
- dizi linklerini toplamıştık zaten
- bu linklerin içine gir(istek at)
- kaynak kodlarına ulaş
- ekrana nerede olduğumuzu yazdır
- kaynak kodlarını yazdır
- döngüyü kır
- döngü içerisinde olduğumuz için
- bütün linkleri gezmeden bitmez!
Geldi Mi? Geldi!
Devaaaam!
Hadi dizi adını alalım, çok basit!
print(dizi_icerik.title.text) # Bulunduğumuz Sayfa Başlığını yazdır

istediğimiz gibi geldi mi? Hayır.
.replace("falan","filan") Özelliğini Kullanalım..
print(dizi_icerik.title.text.replace(" izle | DiziBOX", ""))
Naptık? " izle | DiziBOX", olan yeri "" hiçbir şey ile değiştirdik ve istediğimiz sonucu elde ettik!
Devam etmeden önce kodlarımızın son haline göz atalım;
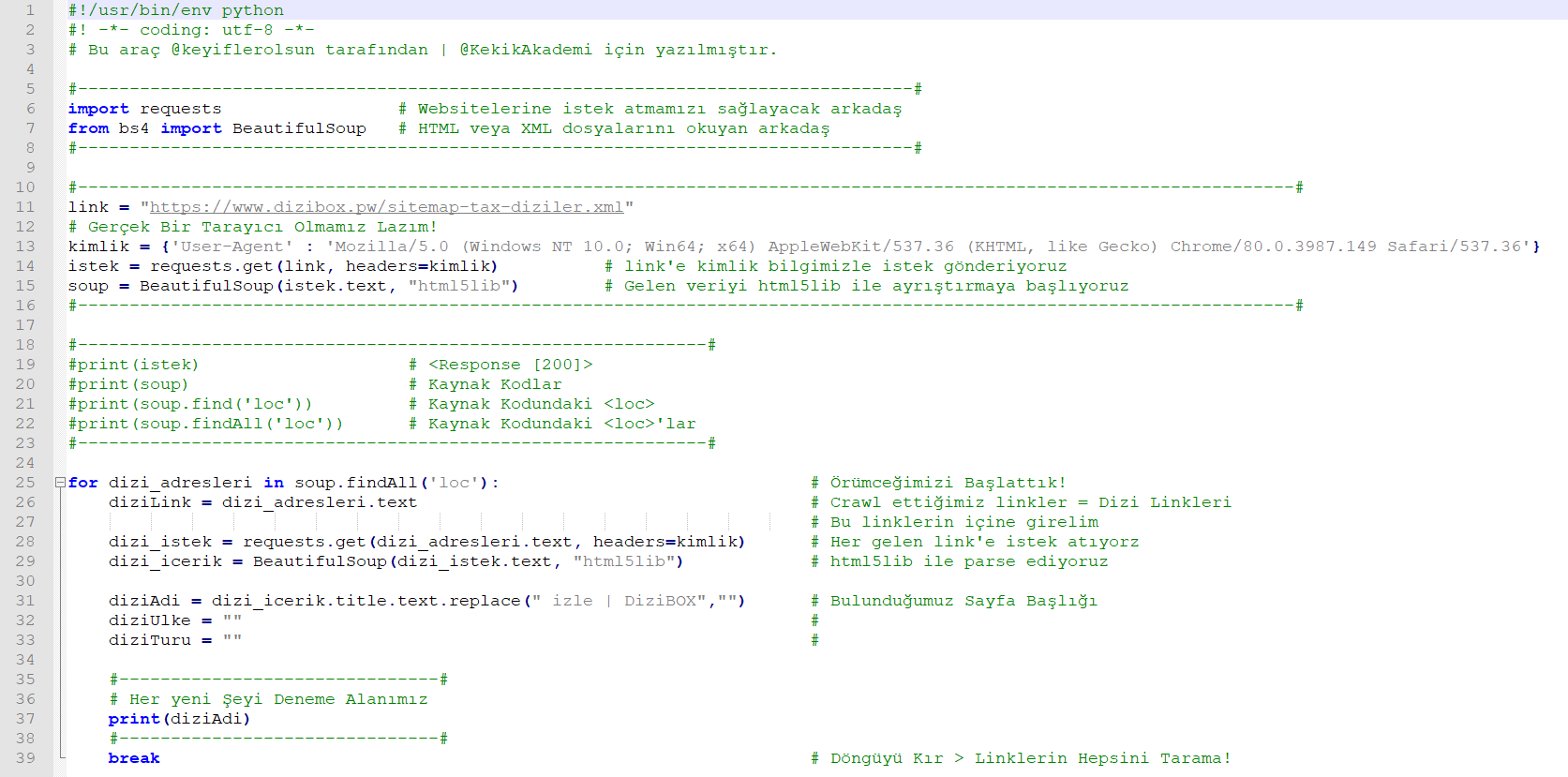
Yazı sonunda bu kodların hepsi github üzerinden paylaşılacak.
Dizi ülkesi ve türünü de çektik mi tamamdır bu senaryo.
şimdiiiii.....
Gelen dizi başlığı hangi adresten geliyordu?https://www.dizibox.pw/diziler/100-days-to-victory/
Bu adrese gidip ayıklamak istediğimiz alanın kaynağına bakalım;
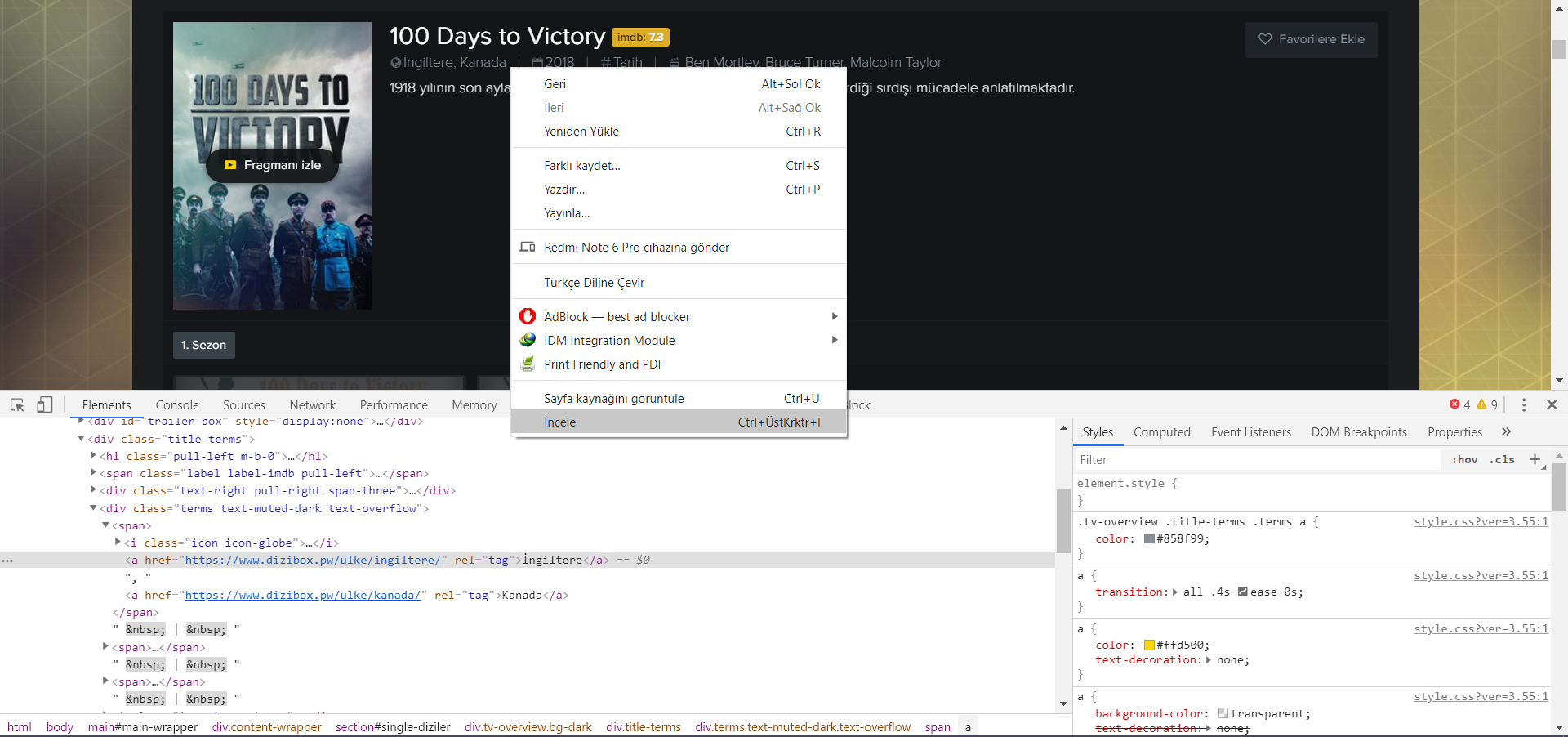
Nerdeymiş dizi ülkesi bilgimiz?
<a 'nın rel="tag" etiketi içerisinde yazı olarak geçiyormuş. Deneyelim bakalım kazımayı..
diziUlke = dizi_icerik.find("a", attrs={"rel": "tag"}).text
print(diziUlke)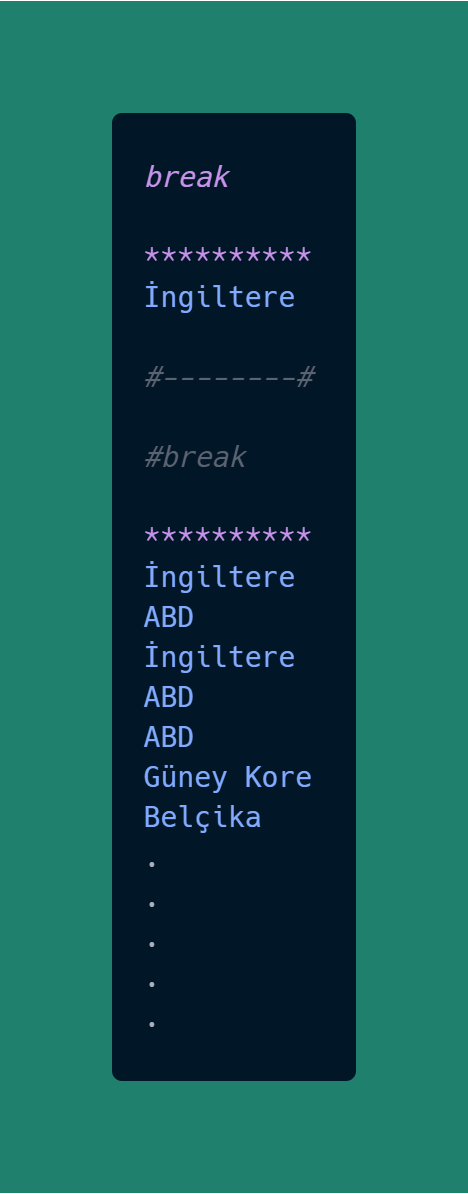
break ile döngüyü kırdığımız zaman İngiltere çıktısını aldık.
döngüyü kırmayıp devam ettirirsek sırayla diğer sayfaları taramaya devam edip çıktıları verdi.
Ancak şöyle bir sıkıntımız var;
https://www.dizibox.pw/diziler/100-days-to-victory/ adresinde Ülke bilgisinde İngiltere, Kanada yazıyor..
Demek ki doğru kazıma yapamamışız. Kodumuzla oynayarak doğru çıktıyı yakalamaya çalışıyoruz..
diziBilgi = []
for diziData in dizi_icerik.findAll("a", attrs={"rel": "tag"}): # Bulunduğumuz sayfa içerisinde Dizi Bilgisi
diziBilgi.append(diziData.text)
a = ''.join(map(str, diziBilgi[1]))[0]
if a != '2':
diziUlkesi = ', '.join(map(str, diziBilgi[:2]))
print(diziUlkesi)
elif a == '1':
diziUlkesi = ', '.join(map(str, diziBilgi[:1]))
print(diziUlkesi)
else:
diziUlkesi = ', '.join(map(str, diziBilgi[:1]))
print(diziUlkesi)gibi gibi fantezilere girilebilir tabiki ama konumuzdan çok uzakta :) biz tek ülke ile devam edelim açıkçası bitsin istiyorum artık şu yazı :D
velhasıl bu matematikle beraber her dizinin içine kadar gidebilirsiniz.
ve en son aşamada, örn' 1. sezon 1. bölüm linkinin içerisinde video linki var ;
https://www.dizibox.pw/freud-1-sezon-1-bolum-izle/5/
> içerisinde
https://odnoklassniki.ru/videoembed/1795922332305
> linki var
<a olanları ve href="../odnoklassniki.ru/videoembed/"
olan linkleri tut;
.findAll('a', attrs={'href':
re.compile("^https://odnoklassniki.ru/videoembed/")})gibi gibi ortalığın anasını bile ağlatabilirsiniz.
Kazıma işi çok sabır gerektiren bir iştir ve ben bu yazı için, aralıklı olarak, 13 saattir uğraşıyorum artık sıkıldım :)
Soru ve Sorunlarınız için @KekikSiber 'den bizlere ulaşabilirsiniz selam ve saygı ile..
Bu sayfada yazılan; Kodların Tamamı <<
Ben bu betikte, dönen veriyi print olarak aldım ama
Siz nasıl isterseniz öyle kullanabilirsiniz. Örn.;
- database oluşturun,
- ister json oluşturun,
- ister telegram'dan mesaj olarak atın,
gibi gibi, dönen veriyi nasıl kullanacağınız size kalmış.
Görseller carbon.now.sh Sayfası ile Oluşturulmuştur..
________________________________________________
📃 Yandex.Disk Bünyemizdeki veriler 1TB'a Ulaşmıştır.. 🎊
Paylaşılan Kursların Tümünü @KekikKahve Grubu notlarından Çağırabilirsiniz..
🕊️ Bize oy verip paylaşarak destek olmaya ne dersin? ✌🏼