Основы информационных технологий
Последнее время я часто сталкиваюсь с потребностью окружающих меня людей в объяснении фундаментальных концепций в ИТ. К сожалению, обзорных материалов, в которых было бы ёмко собраны основные объекты и понятия информационных технологий, очень мало и они обычно ограничиваются одним или двумя концепциями.
В этой обзорной статье я вкратце расскажу, что такое вычисление и вычислительный процесс, чем он обеспечен и как реализуется на практике. Что такое программирование и его языки и как они восходят к машинным инструкциям. Где у процессора память и зачем нужны операционные системы.
Статья будет крайне интересна всем, кто в ИТ недавно, а так же, возможно, даже старожилам, которые пропустили, в своё время, некоторые вещи.
Данные и процессы
Всё программирование строится на двух китах: процессе и данных. Понимание этих двух концепций и того, как глубоко они прорастают, — важнейшее знание для любого ИТ-специалиста.
Любой процесс может быть представлен общей схемой ниже.
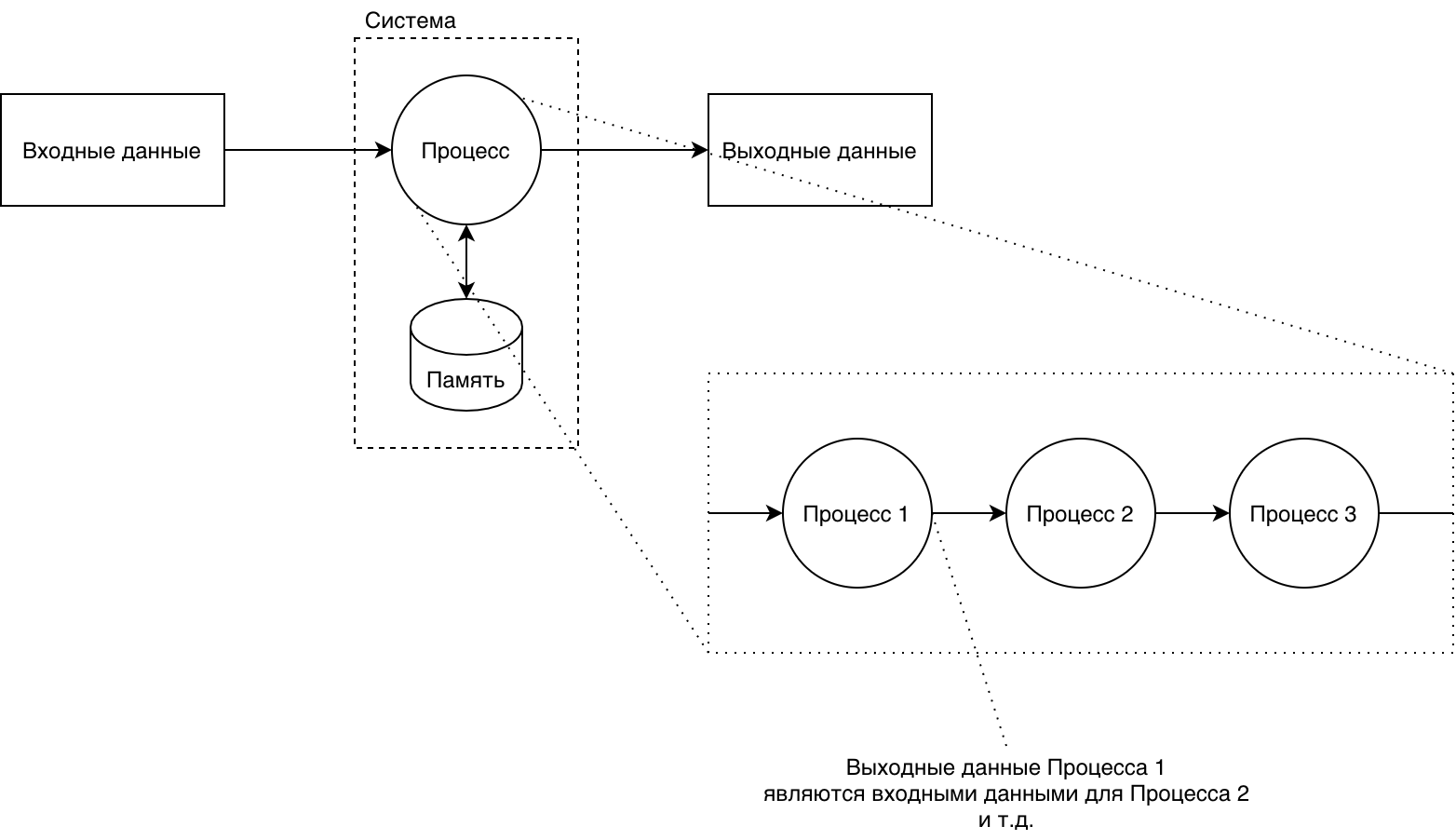
У процесса есть входные данные и выходные. Кроме того, у процесса может быть своя память. Несмотря на то, что процесс и данные, как сущности, могут существовать друг без друга, в таком случае они не имеют смысла. Данные сами по себе — набор ничего не значащей информации, а процесс без данных просто не работает.
Так же любой, сколь угодно сложный, процесс обладает свойством иерархичности: он всегда представим как сумма более простых процессов, лежащих в его основе. При этом для подпроцессов выходные данные предыдущего подпроцесса будут являться входными для следующего. Точно так же у подпроцессов может быть своя память.
В принципе, каждый уровень разложения процесса на составляющие подпроцессы и совпадает со слоями абстракции. От самого высокого внешнего, до нижних внутренних.
На самом деле, сам схема на рис. 1.1 может быть представлена в ещё более общем виде (рис. 1.2), когда память процесса превращается в обратную связь выхода со входом.

Несмотря на то, что такая схема обычно трудна для восприятия, она хорошо демонстрирует родство процесса со всеми другими физическими явлениями, его точно так же теоретически можно представить, например, как дифференциальное (или конечно-разностное) уравнение.
Ветвления
На первой схеме, изображающей процесс, не показано важнейшее свойство реальных процессов: ветвления. Было бы более обще представить детализацию в виде следующего рисунка.

Таким образом, в зависимости от выходных данных одного процесса, может быть выбран или один или другой путь. Соответственно, выходные данные надпроцесса могут так же варьироваться в зависимости от результата ветвления.
Данные и их формат
Сами по себе "данные" без формата не несут никакой полезной нагрузки. Это всё равно, что читать текст на незнакомом языке: вы знаете, что информация там есть, но не можете её извлечь. Язык на котором записаны данные — и есть их формат, его так же иногда называют протоколом.
Кроме этого, данные, даже записанные на нужном языке, могут не представлять ценности, если в них нет той информации, которая вам нужна. То есть, предложение может быть на известном вам языке, но в нём не будет того, чего вы хотели. В таком случае, они так же бесполезны, как и данные в неизвестном формате.

Точно так же как и процесс, данные могут быть вложены друг в друга, при этом быть обрамлены совершенно разными протоколами. Интересно, что в отличие от вложенных процессов, в данных отношение слоёв абстракции обычно отсчитывается в обратную сторону: внешний протокол считается низкоуровневым, а внутренний — высокоуровневым.
Иерархичность
Как уже было отмечено, важнейшим свойством процессов и данных является их иерархичность. Таким образом, даже очень сложная задача делится на набор более простых процессов, а они, в свою очередь, — на набор ещё более простых. И могут быть вынесены в виде отдельных модулей программы, отдельных программ или даже отдельных физических устройств.
Надо понимать, что при этом, несмотря на то, что общая сложность системы не меняется, она распределяется между подмодулями и вытесняется с верхних уровней. Таким образом, даже очень сложный процесс можно вполне понять и спроектировать на каждом отдельном уровне.
Программирование
Будучи знакомым с этими центральными понятиями, можно сформулировать, что программирование — это проектирование процессов и определение форматов данных, решающих поставленную задачу, с последующей их реализацией.
API
В общем случае, каждое взаимодействие одного процесса с другим представляет из себя некоторый интерфейс, который известен обоим процессам. Это некоторый общий язык, на котором они могут продуктивно общаться. Такой язык, интерфейс и называется программным интерфейсом или API.
Элементарные операции
Разбивать вычислительный процесс на составляющие подпроцессы можно вплоть до так называемых элементарных операций. Именно они, в итоге, физически и выполняются компьютером.
Так получилось (в основном, по техническим соображениям, но об этом ниже), что компьютеры сделаны бинарными — для них есть только числа 0 и 1, — биты. Поэтому настоящие элементарные операции работают именно с битами, хотя их можно представить и для любых других чисел.
Представленные ниже операции так же сильно пересекаются с так называемой булевой алгеброй или булевой логикой, поэтому часто имеют логические коннотации.
Операция «И»

Выход, результат операции, равен 1 только если оба входа равны 1, иначе — 0. Её так же называют операцией логического умножения.
То есть результат операции при разных входах будет следующим.
Операция «ИЛИ»

Выход, результат операции равен 1, если хотя бы один вход равен 1, иначе — 0. Её так же называют операцией логического сложения.
Результат операции при разных входах будет следующим.
Операция «НЕ»

Эта операция унарная, т.е. имеет только один вход, в отличие от предыдущих. Она "переворачивает" входное значение: из 0 делает 1 и из 1 делает 0.
Её так же называют логическим отрицанием.
Из перечисленных выше трёх операций всегда можно сложить сколь угодно сложные конструкции, точно так же как процесс в схемах выше делится на более мелкие процессы.
Простой калькулятор
На логических операциях можно сделать, например, калькулятор, который складывает числа. То есть операцию сложения двух чисел или процесс сложения.
Что бы пример был максимально простым, возьмём сложение двух одноразрядных (с одним знаком) двоичных чисел. Нам нужно спроектировать процесс, который на вход принимает два таких числа, а на выходе предоставляет их сумму. Точно то же самое, по аналогии, можно сделать и для любых других чисел, просто полученная схема будет сложнее.

Операция сложения может привести к появлению числа, разряд которого выше, чем у исходных чисел. Например, если мы сложим 1 + 1, то получим 2, что в бинарном виде представляет из себя 10, т.е. число уже с двумя бинарными разрядами. Поэтому на выходе получившиеся число Х3 разбито на два компонента: L X3 и H X3. L X3 будет содержать младший разряд, а H X3 — старший.
Таким образом, через три элементарных операций мы выразили сложение. Точно так же можно выразить вычитание, умножение и деление.
Реальный процессор
В настоящем процессоре элементарные логические операции выше реализуются на обычных электрических транзисторах. Все производители процессоров бьются за уменьшение техпроцесса, что на самом деле означает уменьшение размера одного транзистора, а, соответственно, таких транзисторов можно упаковать больше на одной микросхеме. Понятно, что чем больше транзисторов, тем больше операций может выполнять процессор в единицу времени.
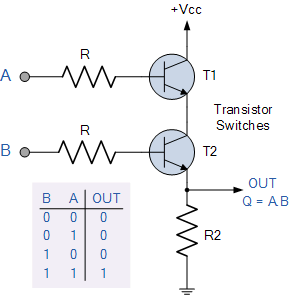
Сам по себе транзистор в процессорах — это электронный ключ, который либо открывается, либо закрывается в зависимости от напряжения на своей базе. На схеме выше, если напряжение на входе А равно логическому 1, то верхний транзистор открывается и соединяет нижний с логическим 1. Если напряжение на входе B так же равно 1, то открывается нижний транзистор и, в сумме, они соединяют выход Q с логическим 1. Если хоть один из входов равен 0, то Q будет надёжно соединён с нулём. Это полностью совпадает с поведением логического "И".
Именно отсюда растут корни бинарности процессоров — с электрической точки зрения очень удобно иметь всего два уровня — 0 и 1, которые соответствуют напряжению 0 вольт и, обычно, 5 вольт. Кроме того, из-за температуры, состояния блока питания и тому подобного, напряжения и характеристики электроники немного "плавают": логический "1" в реальности в разные моменты времени может быть равным и 5 вольтам, и 5.1 вольт, и 4.7 вольта. Поэтому удобно иметь широкую разделительную полосу между уровнями.
Однако, речь про элементарные операции. Несмотря на то, что трёх описанных операций достаточно, что бы производить любые вычисления с числами, а так же логические вычисления (с той самой булевой логикой), их не хватает для загрузки и сохранения данных, общения с другими устройствами и ветвлений.
Надо оговориться, что ветвления и большинство из перечисленного на самом деле можно организовать на элементарных операциях и так действительно делают для программируемых логических матриц (ПЛИС или FPGA), там где критична скорость работы, а не универсальность. В них программа-процесс зашивается прямо в микросхему, но после программирования такое устройство не может выполнять ничего другого. Ставка же процессоров — универсальность.
Поэтому работа процессоров организована по-другому. Они считывают программу в виде последовательности инструкций и данных в оперативную память. Затем, процессор начинает выбирать инструкции из памяти по одной и выполнять её. Инструкцию за инструкцией, вплоть до окончания "ленты" команд.
Инструкции процессора
Инструкция — это определённый производителем процессора код, который сообщает о необходимости совершить некоторую операцию, выполнить команду. Вообще, для каждого процессора может быть свой набор таких кодов, однако за годы индустрия выработала большие стандартные наборы, которые поддерживают все выпускаемые процессоры.
Примером таких инструкций может служить:
- сложение двух чисел;
- загрузка числа из оперативной памяти;
- получение числа от другого устройства;
- сохранение числа в оперативную память;
- отправка числа в устройство;
- условный и безусловный переходы;
- и многие другие.
Надо понимать, что внутри, в большинстве своём, такие команды работают через множество тех самых элементарных операций, о которых говорилось выше. Но они уже организуются в более сложные и осмысленные инструкции.
Например, мы можем сделать программу, получающую два числа от внешнего устройства, складывающую их и отправляющую обратно.
ПОЛУЧИ число1 ПОЛУЧИ число2 СЛОЖИ число1, число2, ПОЛОЖИ_В число3 ОТПРАВЬ число3
Ветвления
На этом моменте можно спросить: если программа выполняется инструкция за инструкцией, как лента, то какие тут могут быть ветвления? Как раз для них существуют специальные команды "перемотки": они переводят (или передают) управление в другую часть программы. Реализуется это через инструкции условных и безусловных переходов.
Безусловный переход просто перематывает ленту к указанной в нём инструкции. Условный же делает это только в случае, если выполнено некоторое условие: обычно равенства или неравенства одного числа другому.
Например, можно представить бесконечную программу деления, которая защищает себя от деления на ноль при помощи условного перехода.
1: ПОЛУЧИ число1 2: ПОЛУЧИ число2 3: ПЕРЕЙДИ_ЕСЛИ_НОЛЬ число2, МЕТКА 7 4: ПОДЕЛИ число1, число2, ПОЛОЖИ_В число3 5: ОТПРАВЬ число3 6: ПЕРЕЙДИ МЕТКА 1 7: ОТПРАВЬ 0 8: ПЕРЕЙДИ МЕТКА 1
Выполняя её, процессор сначала получит число 1, затем число 2. Далее, он проверит, если число 2 оказалось нулём, то перемотает ленту на метку 7, где он отправит обратно 0 и перейдёт обратно в начало программы, к получению числа 1. Если число 2 — не ноль, он выполнит деление, отправит результат обратно и опять перейдёт в начало программы.
В этом примере инструкция ПЕРЕЙДИ — безусловный переход, выполняющийся всегда, ПЕРЕЙДИ_ЕСЛИ_НОЛЬ — условный. В настоящем процессоре это будут инструкции JMP (jump) и JZ (jump if zero) соответственно.
Нечисловые данные
До этого все примеры были исключительно с числами, причём целыми. Как быть с другими данными: текстом, изображениями, звуком?
Процессоры в самом деле, вообще говоря, оперируют только целыми числами. На уровне инструкций процессора уже редко можно встретить отдельные биты и минимальное число для них — байт. Это такое число, которое состоит ровно из 8 бит и может быть представлено десятичным числом от 0 до 255. Другие числа для процессора всегда кратны байту: число с двумя байтами, с 4-мя , с 8-ю и даже с 16.
Однако, при помощи придуманных специальных форматов данных, текст и изображения представимы как массивы чисел, тех самых байт. Для текста, например, есть разработанная очень давно кодировка ASCII, которая как раз говорит, как представить символ алфавита байтом:
Строка "I see dead celebrities" после кодирования превращается в последовательность цифр: "73 32 115 101 101 32 100 101 97 100 32 99 101 108 101 98 114 105 116 105 101 115". И, в таком виде, с ними можно делать все те же операции, что и с числами: читать, записывать, сравнивать и даже преобразовывать.
С изображениями похожая история. Мы можем разбить его на отдельные точки, в самом начале изображения представить двумя числами ширину и высоту (в точках), а дальше сплошняком записать цвет каждой точки изображения. Один из реальных форматов так и делает: на каждую точку приходится по три байта, кодирующих оттенок синего (от 0 до 255), зеленого и красного. Прочитав этот массив информации мы всегда сможем воспроизвести такую картинку на экране.
Аналогично, звук так же превращается в наборы байт которые отправляются туда-сюда. С этим, кстати, как и в изображениях, связаны потери качества: из-за необходимости представить звук в числовом виде он как бы огрубляется при оцифровке.
Прерывания
Есть ещё один важный класс объектов, про которые необходимо рассказать отдельно. Процессор, как уже понятно, не существует сам по себе, в вакууме, без внешних устройств, которые бы предоставляли ему, например, ленту инструкций, или данные. Так же он часто должен быть способен реагировать на события, а не "уходить в себя".
Для организации такой работы были придуманы прерывания. Это механизм, когда при наступлении некоторого внешнего или внутреннего события, процессор останавливает выполнение ленты команд и перематывает её в заранее определённое место, где будет находится обработчик прерывания. После выполнения инструкций обработчика прерывания, процессор переключается обратно на то место ленты, на котором остановился.
Например, часто через прерывания работают таймеры реального времени (вызываем прерывание каждую секунду). Или работа с устройствами, когда мы либо сообщаем им, через прерывание, что они могут забирать данные, либо они нам сообщают, что они закончили и мы можем получить результат их работы.
Операционные системы
В примерах выше мы сделали программу, которая считывает два числа из некоего "внешнего устройства", делит их и отправляет результат обратно. Но в реальной жизни всё не так просто.
Во-первых, сам по себе процессор не знает ни про внешние устройства (кроме некоторых зашитых), ни про формат общения с ними. Например: как считать файл с жёсткого диска? А как с него же загрузить код программы в память? Как отправить число по сети? Во-вторых, мы выполняли на процессоре только одну программу, а как же многозадачность? Что делать, если я хочу одновременно и делить числа и воспроизводить звук?
На все эти вопросы отвечают как раз операционные системы. Они представляют из себя фундамент (или, если угодно, окружение) для прикладных процессов, которые в них работают.

В результате, создавая программу для Windows, например, вам не нужно заботится, как через прерывания надо вызывать обработчик отправки точек на экран компьютера, что бы отрисовать окно, это за программу сделает операционная система. Вам так же не нужно переживать, что при работе вашей программы останавливается другая программа, об этом так же позаботиться ваша ОС.
Программы (или процессы), которые работают внутри ОС, обычно называют пользовательскими (или прикладными) программами, а программы, которые составляют ОС — системными.
Планировщик задач
Важнейшей частью любой ОС является планировщик задач (или диспетчер). Это системная программа, которая, грубо говоря, постоянно переключает процессор с одной выполняемой пользовательской программы на другую, запускает и останавливает их. Именно через этот механизм, в основном, реализуется многозадачность.

То есть, на самом деле, просто представьте: каждый раз, когда вы двигаете курсор мыши (от мыши поступает сигнал, что она передвинута), планировщик задач ОС останавливает все запущенные приложения, запускает программу перерисовки курсора в другой точке, затем возвращает выполнение тех программ, которые он остановил. То же происходит, например, при прослушивании звука и ведении чата в социальной сети: пока вы чатитесь, ОС постоянно на доли секунды приостанавливает работу браузера, переключается на звуковое приложение, даёт ему отправить в звуковую карту очередную порцию данных, и, затем, возвращает браузер на место. Обычно, это всё происходит настолько быстро, что абсолютно незаметно.
Реальное положение вещей, конечно, сложнее: в процессорах уже давно существует и конвейер команд, который позволяет выполнят их с опережением, и многоядерность, специально для параллельного выполнения разных инструкций (это как процессор в процессоре), но, в целом, механизм остаётся тем же самым.
В следующий раз, когда ваша ОС будет "тормозить", знайте: это планировщик задач не может справится со своей работой так, что бы это было незаметно, из-за большой загрузки разными задачами.
Драйверы
Некоторые внешние по отношению к процессору устройства "знает" сам процессор, работа с некоторыми есть в BIOS, но большая часть работы с ними запрограммирована в специальные подпрограммы ОС, которые обычно называют драйверами.
Драйвер — это мост, интерфейс между прикладными программами и реальным физическим устройством, который делает работу с ними удобной. Например, что бы отправить два байта по сети без драйвера, вам потребуется совершить очень много действий, которые будут, скорее всего, включать:
- загрузить первый байт в регистр;
- выставить адрес сетевой карты на внутренней шине;
- вызвать прерывание установки адреса, что бы сетевая карта перешла в режим чтения данных с шины;
- выставить байт из регистра на внутренней шине;
- вызвать прерывание установки данных, что бы сетевая карта прочитала данные с шины;
- повторить это для второго байта;
- и так далее.
Драйвер сетевой карты же скроет в себе эту сложность. Ему на вход можно передать сразу оба байта, а он сам, внутри себя, выполнит нужные операции.
Точно так же происходит и с остальным: со звуком, с жестким диском, с видеокартой и экраном.
Файловая система
Отдельно стоит отметить работу с жестким диском. Дело в том, что файлы, как и сама файловая система, существуют только на уровне ОС и её драйверов . При работе с устройством напрямую вы будете видеть только сектора и смещения, отдельные ячейки, в которых находятся какие-то бессмысленные байты.
Базовая файловая система — это таблица разметки жесткого диска на папки и файлы. Грубо говоря, в этой таблице зафиксировано: "файл1.txt начинается в секторе 6 со смещением 267, а заканчивается — в секторе 8 со смещением 11". Содержимое файлов же, байты, хранятся сплошняком, поэтому без такой таблицы размещения содержимое диска превращается в бессвязную кашу.
Собственно, одна из самых старых файловых систем так и называется — FAT, что означает "File Allocation Table", таблица размещения файлов.
Прерывания
В операционных системах общего назначения обычно запрещают пользовательскому коду самостоятельно работать с прерываниями, потому что они только мешают диспетчеру задач выполнять свою работу. Аппаратные же прерывания обрабатываются самой ОС.
Таким образом, операционная система — важнейшая часть практически любой информационной системы. Без неё работа с голым процессором и периферийными устройствами была бы колоссально сложна и неудобна.
Языки программирования
Пример программы для процессора выше был простым, но настолько простые вычисления уже давно не интересны индустрии. Реальные современные программы состоят из миллиардов таких инструкций, со сложными ветвлениями и работой с периферийными устройствами. Составить сложную программу на языке инструкций процессора чрезвычайно сложно, если не невозможно.
Именно за этим были придуманы языки программирования. Они предоставляют собой сильно более понятный человеку язык (хотя всё равно специфичный), который позволяет скрыть сложность машинных кодов и особенностей работы с шинами данных и сосредоточиться на решаемой задаче. Язык программирования — такая же абстракция над машинными инструкциями, как сами машинные инструкции над элементарными побитовыми логическими операциями. Именно поэтому большинство из них называют языками высокого уровня.
Представим предыдущую программу деления двух чисел на языке высокого уровня С#. Мы модифицируем её так, что бы она брала данные не из некоего периферийного устройства, как в примере выше, а из консоли ОС.
static void Main() {
while (true) {
var number1 = int.Parse(Console.ReadLine());
var number2 = int.Parse(Console.ReadLine());
if (number2 == 0) {
Console.WriteLine("0");
}
else {
var number3 = number1 / number2;
Console.WriteLine(number3.ToString());
}
}
}Как можно видеть, тут уже нет команд переходов, зато есть бесконечный цикл — WHILE и условное ветвление — IF ... ELSE. Программа уже стало более удобной для чтения.
Но тут можно заметить, что, по сравнению с предыдущим примером, она явно не стала меньше, а даже больше. Это потому, что, на самом деле, она делает намного больше работы, чем предыдущая версия. В примере с инструкциями процессора мы не вдавались в детали, откуда мы читаем данные и как это делаем. В реальности же, даже с простейшим периферийным устройством, она бы растянулась на несколько десятков строк.
В этом же примере, мы не просто считываем данные, мы считываем их из командной строки (Console.ReadLine), которая уже является надстройкой ОС. Которая, в свою очередь, под капотом, работает с клавиатурой и экраном через соответствующие драйверы. Кроме того, мы получаем данные из консоли не в числовом виде, не байтами, а в виде строки. А затем преобразовываем эту строку в 4-х байтное число (int.Parse). Затем мы отправляем результат операции обратно в консоль (Console.WriteLine), преобразовав полученное число обратно к строке (.ToString). Аналогичная программа в инструкциях процессора заняла бы добрых пару сотен строк.
Стоит обратить отдельное внимание на то, что команды работы с командной строкой (консолью) — это интерфейс, предоставляемый именно операционной системой и часто такие команды называют системными вызовами (потому, что в этом месте "вызывается" подпрограмма системы, т.е. ОС).
Сеть
Взаимодействие процессов, однако, не ограничивается одним компьютером и устройствам, в нём непосредственно расположенными. Современный мир — век сетевой связанности устройств друг с другом. Как же организуется такая работа?

Если не вдаваться в детали, то, что бы отправить данные другому устройству в сети, процессору необходимо скинуть их в сетевую карту. Она, в свою очередь, упакует их в свой протокол и через электрические сигналы передаст к маршрутизатору. Маршрутизатор по информации в переданных данных определит адресата и передаст данные его сетевой карте. На принимающей стороне сетевая карта расшифрует электрические сигналы, распакует сообщение и передаст в процессор.
Тут необходимо отметить, что маршрутизатор между источником и приёмником может быть не один, их могут быть сотни — они и составляют основу Интернета. Сам же маршрутизатор — это просто коммутатор, который работает как телефонистки на заре телефонов. Он определяет, в какой провод дальше отправить данные, пришедшие из другого провода.
Иерархия протоколов и модель OSI
Как я уже отметил, сетевая карта "оборачивает" данные, которые надо передать, в свой собственный протокол. Но на самом деле таких протоколов несколько, каждый из них предназначен для решения одной из проблем при передаче данных. Все они обычно сводятся в общепринятую модель OSI.

В ней оборачиваемые протоколы идут от самых близких к значимым данным до самых базовых, предназначенных для передачи отдельных сигналов. В принципе, данные в сетевую карту можно передавать начиная с четвертого, транспортного уровня.
Кроме этого, в реальной жизни, зачастую протокол одной прикладной программы на самом высоком уровне OSI упаковывается в протокол другой программы, который так же находится на 7-м уровне. Так регулярно происходит, например, с HTTP, в который оборачивают данные программы.
IP
Это интернет-протокол (так и расшифровывается) сетевого уровня (3-го в модели), который отвечает на вопрос "куда доставить?" В нём каждому устройству в сети предоставлен свой адрес, который кодируется четырьмя байтами (в версии IPv4), отправитель сообщения должен знать этот адрес и, на этом уровне, как раз его выставляет. Маршрутизаторы, основываясь на этом адресе назначения, прокидывают отправленные данные до адресата.
У этого протокола есть альтернативы, но они уже практически не используются, или используются в очень узких областях.
Ваш IP-адрес — это и есть "почтовый" адрес устройства, по которому вашему компьютеру доставляются данные.
Однако в реальных применениях просто адресованная передача байт не очень интересна. Два набора данных, например, могут перепутаться при передаче или быть потеряны. Кроме того, данные может быть необходимо зашифровать при передаче. Эти проблемы на себя обычно берут протоколы 4, 5 и 6-го уровней: транспортного, сеансового и представления. Эти уровни формируют из исходных данных специальные программы, которые работают либо в ОС, либо прямо в сетевой карте.
UDP и TCP
Двумя самыми распространёнными протоколами данных над IP являются UDP и TCP.
UDP — протокол передачи датаграмм, т.е. массивов данных адресатам. Он очень простой и предоставляет мало преимуществ перед сырым IP. Данные могут потеряться при передаче, сообщения могут перепутаться местами. Однако, он играет важнейшую роль — из-за его простоты через него можно передавать огромное количество не очень важных сообщений. Например, при управлении чем-то в реальном времени или при отправке каких-либо показаний.
TCP, наоборот, это протокол, который устанавливает и поддерживает соединение при передаче данных. Внутри он следит как за потерей кусков данных, так и за очерёдностью их доставки. Он сильно более надёжен, но и от этого более сложен и ресурсоёмок. Для передачи байта по сети через UDP достаточно просто передать этот байт, завернув в "конверт" UDP, в TCP для этого требуется:
- отправить приветствие и дождаться ответа на приветствие (в реальности эта процедура происходит аж в 3 этапа);
- передать кусок данных, дождаться подтверждения передачи куска;
- отправить сообщение о закрытии соединения.
Однако, именно TCP в интернете используется чаще всего для передачи данных между пользовательскими программами.
Порты
Представим, что на компьютере 1 запущено две программы — программа1 и программа2, на другом компьютере в той же сети, так же запущены программа3 и программа4.
Когда мы отправляем данные из программы1 с первого компьютера программе3 на втором, как мы укажем, для какой именно программы они предназначаются? Для решения этой проблемы были придуманы так называемые порты. Это обычные числа (от 1 до 65535), которые занимают "слушающие" программы при своей работе. Отправляющая программа при передаче указывает, на какой порт адресата она отправляет сообщение. При этом, пока порт кем-то используется, другая программа не может его занять.
В примере выше, программа4 на компьютере 2 может занять порт, скажем, 1234. И при отправке сообщения, программа1, кроме адреса компьютера, укажет порт 1234, сообщение будет доставлено по адресу.
Доменные имена
Я уверен, что никто уже очень давно не вбивал в адресной строке браузера IP-адрес, что бы открыть какую-то страницу (хотя это можно сделать). Вместо непонятных цифр IP-адреса мы привыкли работать с доменными именами вроде google.com.
За обеспечение этого удобства ответственна интернет-служба доменных имён — DNS. Специальные серверы, с которыми постоянно синхронизируются компьютеры, хранят информацию о том, какое доменное имя соответствует какому IP-адресу.
То есть, когда вы в следующий раз откроете главную страницу Google, ваш компьютер под капотом определит IP-адрес устройства, которое обслужит ваш запрос, и отправит данные именно ему через протокол IP.
HTTP
Обзор был бы неполон без рассмотрения одного из самых популярных прикладных протоколов (7-й уровень OSI) современного интернета — HTTP. Который переводится как HyperText Transfer Protocol. Именно он, на самом высоком уровне OSI, используется для открытия страниц браузером, как и в очень многих других случаях общения программы с программой. Просто хотя бы из-за своей распространённости.
Этот протокол основывается на модели запрос-ответ. Т.е. клиент формирует некоторые данные запроса, которые отправляются другой системе, а она на них отвечает. Важнейшим его свойством является то, что после ответа "сеанс связи" всегда заканчивается. Кроме этого, HTTP является текстовым протоколом, что позволяет легко смотреть содержимое общения.
Рассмотрим пример такого запроса и ответа, на которых можно будет разобрать основные части.
POST some-page.html HTTP/1.1
Content-Type: application/json, encoding=cp1251
Accept: text/html
Authorization: Basic 123
{"координата": 1, "скорость": 2}200 OK Content-Type: text/html, encoding=utf-8 <b>спасибо</b>
Как можно заметить сразу, сообщения явно состоят из некоторого заголовка и содержимого, так называемого тела запроса/ответа. Соединившись с сервером, клиент отправляет запрос: "действие POST, ресурс some-page.html, версия протокола 1.1".
Далее, идёт набор заголовков, которые сообщают дополнительные данные принимающей стороне:
- Content-Type — в каком формате передаётся тело сообщения, в данном случае — application/json, что соответствует популярному формату данных JSON; так же может быть указана кодировка текста в теле запроса, в данном случае русская ASCII;
- Accept — в каком формате отправитель хочет получить ответ;
- Authorization — отправитель сообщает информацию о своей авторизации (например, логин и пароль).
После чего, через один перевод строки, следует тело запроса, собственно, в формате JSON и в указанной кодировке.
На этот запрос сервер отвечает похожим образом: "всё хорошо, код ответа 200 ОК". Далее, сообщает формат тела ответа и кодировку (в данном случае UTF-8) и, после перевода строки, отправляет само тело в указанном ранее формате.
Как нетрудно заметить, в таких "конвертах" можно передавать абсолютно любые сообщения между двумя программами.
Локальное общение
Описанные сетевые технологии могут быть использованы не только для реальной связи по сети между двумя машинами, зачастую они используются для связи двух программ внутри одного и того же компьютера. В этом случае используют зарезервированный IP адрес 127.0.0.1 или специальное имя localhost. Хотя данные никуда не уходят за пределы машины, для программ всё остаётся так, как будто они работают с удалённым устройством.
Таким образом, мы быстро, но достаточно подробно рассмотрели все основные объекты информационных технологий: от процессов и данных, элементарных логических команд и организации процессоров, до ОС, языков программирования и взаимодействий процессов друг с другом по сети.