Large Parallelism Post: Part II. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Во второй части мы углубимся в Tensor Parallelism на основе статьи Megatron-LM. В ней представлен способ параллельных вычислений внутри блоков MLP и Attention. Благодаря разделению весовых матриц по столбцам и строкам, становится возможным распараллелить блоки MLP и Attention между GPU с минимальными коммуникациями между нодами. Также разберем пайплайн TP+DP.
Source: Arxive, Tensor Parallelism
В прошлом посте Large Parallelism Post: Part I мы разбирали Model Parallelism, который включает в себя два типа параллелизма:
- Вертикальный - несколько слоев модели на каждом GPU
- Горизонтальный - мы размещаем часть всей модели на каждом GPU
Горизонтальный параллелизм модели и называется Tensor Parallelism (TP) и именно с ним мы сегодня будем разбираться.
Главное отличие горизонтального параллелизма от вертикального в том, что он исключает простаивание GPU благодаря разделению всех слоев модели между нодами. На схеме ниже показаны их основные различия: в вертикальном мы на каждом GPU храним отдельный кусок слоя; в горизонтальном мы делим каждый слой модели между всеми GPU, после снова собитраем в один слой и снова делим между нодами

Для начала обозначим, что именно мы будем параллелить - это классический слой трансформера, который изображен на схеме ниже. Глобально, он состоит из двух блоков - MLP и Attention. Внутри каждого блока есть слой Dropout, который в совокупности также хотелось бы параллелить.

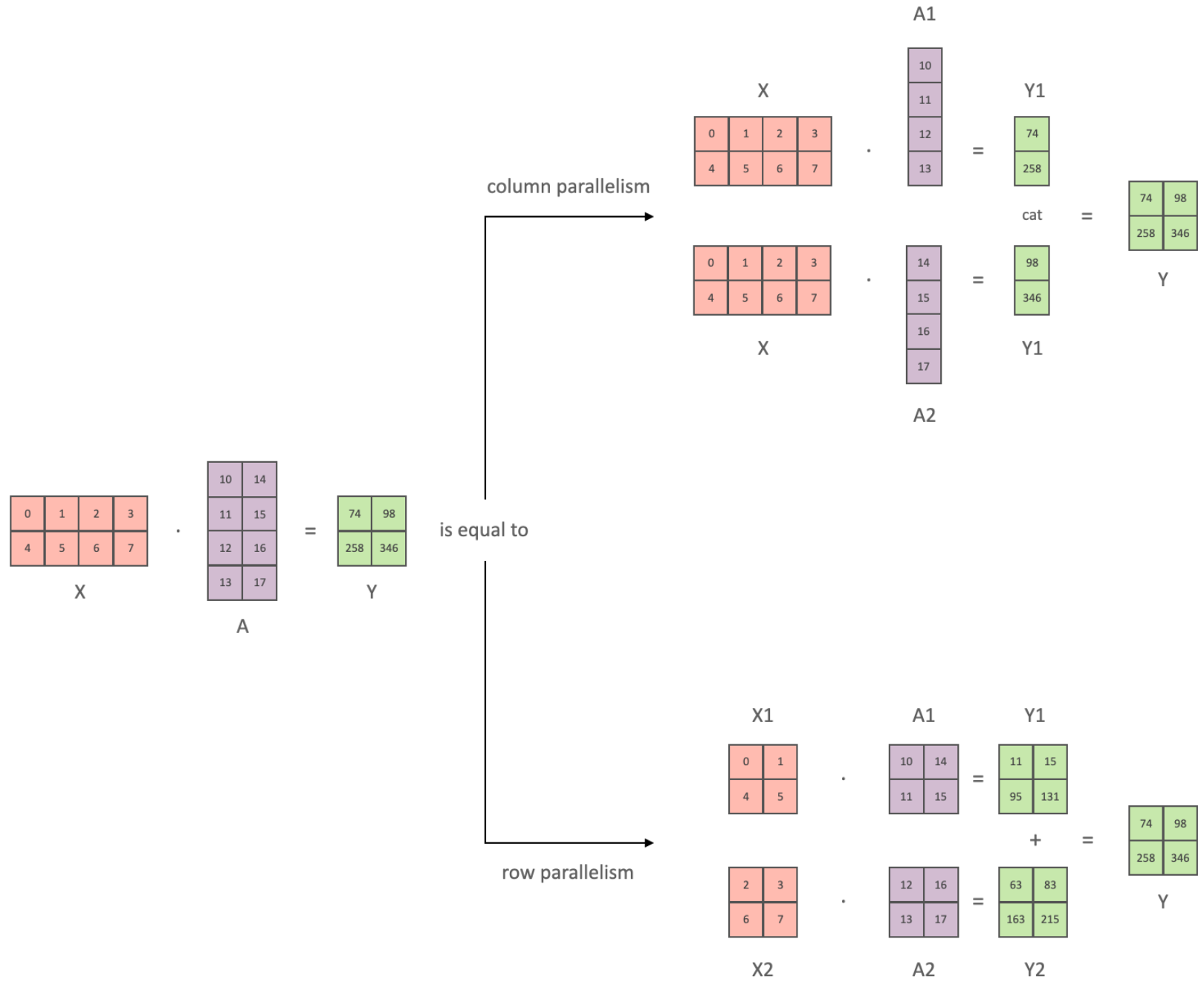
Перед разбором статьи, обратимся к схеме из HuggingFace, которая поможет нам более детально понимать будущие расчеты. Ее суть в том, что мы можем параллелить данные входной матрицы и весов двумя способами - по столбцам и строкам.
В случае параллелизма по столбцам, мы распределяем матрицу весов на два столбца, умножаем на входные данные (важно, что входная матрица X одинакова для A1 и A2 в этом случае), получаем два выходных столбца Y1 и Y2 и конкатенируем их в выходную матрицу Y.
Для параллелизма по строкам, мы уже способны разделить входную матрицу X, но разделяем ее по столбцам, а вот матрицу весов A делим по строкам, производим умножение соответствующих частей, получаем выход Y1 и Y2, складываем их и получаем финальную матрицу Y.
Обратимся теперь к статье - как мы обсуждали ранее, в ней представлен параллелизм двух блоков: Multi-Layer Perceptron (MLP) и Attention.
Начнем с параллелизма MLP. В обычном варианте без параллелизма выход из этого блока можно записать простым уравнением с перемножением матриц входных данных и весов, а после применить нелинейную функцию активации.

Первые мысли, которые могут возникнуть, когда мы хотим что-то параллелить - давайте поделим матрицы входа и весов (row parallelism):

Однако, это не сработает, потому что GeLU является нелинейной функцией и у нас не получится получить финальную матрицу с помощью сложения:

Однако, мы можем решить эту проблему, если сначала распараллелим в этом случае только матрицу весов (column parallelism). Тогда выходом из такой операции будет два столбца Y, которые мы сконкатенируем:

Обращу внимание, что матрица входных данных остается одинаковой для каждой матрицы A1, A2 и не параллелится.

После получения выходных матриц Y1, Y2, они подаются в следующий слой, где матрицы весов B1, B2 разделены по строкам (row parallelism), после чего формируются выходные матрицы Z1, Z2 и они подаются в оператор g, а дальше формируется финальная матрица Z, после прохода Dropout слоя.
Подробнее расскажу, что за операторы f и g на схеме выше - это AllReduce оператор на Backward и Forward pass соответственно. g работает, когда после Forward pass необходимо собрать все данные для формирования выходной матрицы, а f после Backward pass формирует матрицу градиентов.
Теперь разберем параллелизм Attention слоя. На самом деле, там все работает аналогично MLP, только матриц чуть больше. Сначала применяется column parallelism для матриц Query, Key, Value, далее их результат проходит через Sofmax и Dropout, после чего матрицы Y1, Y2 умножаются на веса B1, B2 в слое Dropout, который работает с помощью row parallelism, а потом все подается в оператор g и формируется финальная матрица Z.

Вот общий пайплайн tensor parallelism - по сути в каждом разобранном блоке у нас есть верхняя и нижняя часть, которые мы можем отправить на отдельные GPU. Тогда у нас остается только 4 операции AllReduce, которые мы будем делать для сбора финальных матриц оператором g и сбора матриц градиентов оператором f.

Еще одна схема пайплайна tensor parallelism трансформера. Я ее прикрепил для понимания, почему всего будет 4 операции AllReduce, а также для комментария, что в пайплайне присутствуют Skip Connections.

Матрицу входных эмбеддингов авторы параллелят по столбцам E = [E1, E2]. Для выходных эмбеддингов Y1, Y2 авторы для них высчитывают Cross-Entropy Loss и после, с помощью AllGather, получают финальные вероятности. Это сделано для сокращения времени коммуникации между GPU, поскольку сводит размер финального пространства к b x s (b - batch-size, s - sequence length).
Также добавлю, что авторы используют Activation Checkpointing. Он заключается в сохранении только конечных активаций каждого слоя на Forward pass, а на Backward pass все активации между сохраненными слоями будут рассчитываться повторно и использоваться для получения градиентов. Это экономит затраты памяти и вычислительные ресурсы.
До этого мы обсуждали, что делим трансформер между двумя карточками, но, конечно же, его можно делить между многими GPU. Я думаю этот факт более чем очевиден, поэтому перейдем к части совмещения TP и DP. Да, так можно делать и вот схема пайплайна:

Если кратко, то вы можете создать ноду с 8 GPU (то есть разделить модель на 8 частей), потом перекопировать эту ноду 64 раза, а в каждой ноде подавать на определенное GPU определенную часть данных (да да, это тот самый самый простой DP). То есть, например на GPU [1, 9, 17 ... 505] в каждой ноде вы подаете данные Group1, на GPU [2, 10, 18 ... 506] данные Group2 и так далее. Градиенты будут аккамулироваться как в DP, а каждая нода теперь способна вместить в себя большую модель (хватило бы только GPU).
Results
Судя по графикам, пайплайн TP+DP довольно неплохо справляется с большим количеством GPU - есть небольшая просадка на несколько процентов по сравнению только TP, но это скорее из-за малой задержки NCCL операций между карточками.

Добавлю еще вот такую табличку, которая показывает сколько дней тратится на одну эпоху, обучая GPT-2 в разных конфигурациях на 512 GPUs (одна эпоха это 68507 итераций).
