xLSTM: Extended Long Short-Term Memory
В статье разработано улучшение сети LSTM с помощью двух архитектур - sLSTM и mLSTM. Каждая архитектура, направлена на решение проблем оригинальной сети. Добавлены параллельные вычисления, способность корректировать запоминание информации, а также матричное представление данных внутри сети. Эксперименты доказывают, что xLSTM сравнима с GPT моделями.
Source: Arxive
Перед тем как разбирать новую архитектуру xLSTM, кратко напомню как работает оригинальная LSTM (если вы захотите прочитать больше, то крайне рекомендую источник).

- Вначале получаем взвешенную сумму входного вектора и вектора скрытого состояния (коэффициенты в этой сумме и есть весовые матрицы).
- Forget Gate - результат применения сигмоиды к скрытому и входному векторам. Результат умножается на вектор контекста, решая какую информацию нужно забыть с учетом полученных состояний.
- New Cell Content - получается с помощью гиперболического тангенса. Расчитывается новый контекст и одновременно решается какая информация в новом векторе релевантна с помощью умножения на сигмоиду результата взвешенной суммы входного и скртого состояния (Input Gate). Новый контекст прибавляется к прошлому - именно эта операция и отвечает за способность LSTM запоминать длинный контекст.
- Вычисляется новое скрытое состояние с помощью гиперболиечского тангенса финального вектора контекста и очередным умножением на сигмоиду суммы входного и скрытого векторов (Output Gate).
У такой архитектуры есть пара проблем:
- Невозможно производить вычисления параллельно
- Невозможно корректировать решения сети запоминать/забывать информацию
- Скалярность памяти вносит некоторые ограничения на ее эффективность
В новой статье ученые решили эти недостатки.
Во-первых уточню, что xLSTM состоит из двух архитектур - sLSTM и mLSTM. Начнем с sLSTM.
sLSTM

Давайте внимательно посмотрим что изменилось в схеме sLSTM.
- Сразу замечаем новую красную ячейку памяти n (normalization) над ячейкой контекста.
- Первые две сигмоиды заменяют экспоненциальные функции.
- Деление вместо гиперболического тангенса при расчете нового скрытого состояния.

Вот что пишут сами авторы о нововедениях:
Чтобы наделить LSTM способностью пересматривать решения о хранении, мы вводим экспоненциальные gates (красные) вместе с нормализацией и стабилизацией. В частности, input gates и forget gates могут иметь экспоненциальные функции активации.
Что произошло? Раньше мы не могли получать большие значения из-за ограниченности сигмоиды. Теперь, расчитывая экспоненту, у LSTM есть возможность регулировать релевантность информации в input gate и forget gate.
Например, если входной вектор является очень важным для сети, значение input gate будет высоким, а значит и умножение на вектор контекста даст большой результат. Одновременно с этим сеть понимает, что прошлые векторы были неважными, а значит мы получим малые значения в forget gate (кстати именно поэтому авторы на картинке указывают, что для forget gate можно применять как сигмоиду, так и экспоненту - неважно как сеть занулит прошлые значения).
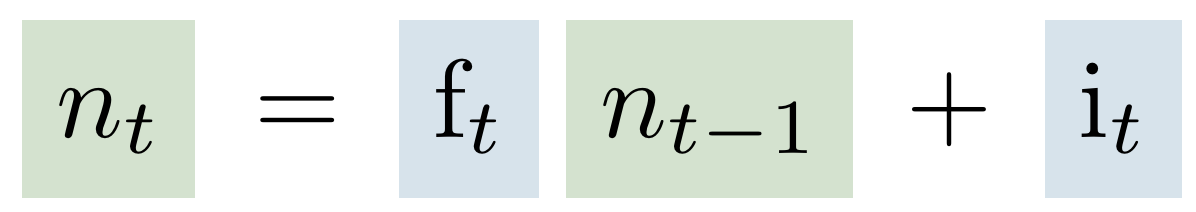

Теперь перейдем к новой ячейке нормализации. Расчет данного значения можно увидеть в формуле 9, но зачем он нужен? По формуле мы видим, что состояние нормализации постоянно увеличивается за счет накопления значений input gate. Да, есть возможность забывать прошлую информацию с помощью forget gate, однако в этой ячейке все равно аккумулирована вся релевантная информация текста. А теперь обращаемся к формуле 10 - частному вектора контекста и вектора нормализации. По сути здесь сеть вычисляет насколько релевантная информация содержится в векторе контекста по отношению ко всему тексту документа. А также это позволяет архитектуре передать значение этой релевантности в следующий слой.

Перейдем к последней части sLSTM - стабилизации. Мы понимаем, что экспонента может выдавать очень большие значения, которые приводят к переполнению памяти. Поэтому авторы вводят алгоритм стабилизации этих значений - состояние m (которое берут из статьи Online normalizer calculation for softmax). Оно выбирает максимум из двух значений: суммы прошлого состояния стабилизации с логарифмом forget gate и логарифма input gate (формула 15). Далее считаются новые значения input gate и forget gate по формулам 16 и 17.
На инференсе, конечно же, это является трюком для предотвращения взрыва градиентов и переполнения памяти. Однако на этапе тренировки данная часть вычислений очень важна и вот почему.
- Когда левая часть максимума с логарифмом forget gate и прошлым стабилизатором превосходит логарифм от input gate, то финальное значение forget gate обнуляется - то есть при высоком значении текущего forget gate и прошлой памяти, сеть умножает на ноль вектор контекста и нормализации.
- Напротив, когда логарифм input gate превосходит сумму логарифма forget gate и прошлого стабилизатора, то обнуляется финальное значение input gate, а значит зануляется текущий контекст и информация не добавляется в вектор нормализации.
Мы учим сеть находить баланс между добавлением и забыванием информации. Если инфомация важна, то нельзя сразу присвоить ей большое значение, иначе оно заглушит прошлые знания. Если мы хотим занулить текущую информацию, то, конечно, можно ей выдать высокие значения forget gate, однако на следующем шаге это действие может перевесить нечто важное в input gate, даже если forget gate будет мал, и тогда снова произойдет забывание.
Последнее, что сделали авторы - вместо работы с одной цепочкой блоков sLSTM авторы делают несколько голов с помощью матриц, подражая multi-head attention (они назвали это New Memory Mixing, хотя вообще то об этом известно уже очень давно. Ниже я приведу код для более подробного объяснения). Матрицы Wz, Wi, Wf, Wo, Rz, Ri, Rf, Ro являются теперь блочно-диагональными, где каждый диагональный блок задает отдельную голову. В этом случае, скаляры становятся, очевидно, векторами. Сам Memory Mixing может происходить только внутри каждой головы, а не между голов.

mLSTM
В сети mLSTM авторы увеличивают объем памяти с помощью агрейда скаляра с до матрицы C. Они используют терминологию трансформеров и вводят вектора q, k и v для хранения и извелечения памяти. Извелечение необходимой информации из памяти основано на правиле обновления ковариации, которое позволяет сохранять пары векторов (v, k):

Разберем на простом примере как это работает. Допустим нам нужно сделать 2 итерации по сохранению векторов (v, k) и мы получим :

А теперь нам нужно достать из сохраненной памяти вектор v0:


Это возможно из-за вычислений в пространстве большой размерности - мы предполагаем, что если векторы разные, то они практически ортогональны, а значит их произведение будет равно нулю. Напротив, умножая одинаковые векторы друг на друга, мы получаем 1.
Это правило встречалось уже ранее в статье Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention, разбор которой я делал в канале.
Итак, разберемся подробнее. Как я писал ранее - авторы используют вектора q, k и v наподобие трансформеров, вычисление которых вводится в формулах 22, 23 и 24. Здесь нет ничего нового - входной вектор умножается на матрицу весов и к результату добавляется bias. В случае k видим классическое сохранение размерности путем деления на корень из d - это реализовано в ванильном self-attention.
Важно отметить, что в input, forget, output gate теперь не используется скрытое состояние (формулы 25, 26, 27) - это очень важное обновление, поскольку теперь появляется возможность распараллелить процесс обучения.

Добавлю, что для input и forget gate используется тот же процесс стабилизации, что и в sLSTM.
Теперь снова вернемся к правилу ковариации и к формулам 19, 20 и 21.
В 19 формуле мы видим формирование матрицы C путем накопления пары векторов v и k. Да, мы снова прибегаем к forget, input gate для контроля забывания и релевантности накапливаемой информации.
Аналогично мы поступаем в формуле 20 с одним отличием - там происходит накопление только векторов k.
Наконец, в 21 авторы приводят расчет скрытого состояния архитектуры mLSTM - извлекают и нормализуют релевантную информацию из памяти. В правой части в числителе происходит извлечение необходимой информации из матрицы C с помощью вектора q. Да, в разобраном выше примере ковариации я использовал вектор k, однако в таком случае мы извлекали только один конкретный вектор v. В реальности нам необходимо регулировать извлечение релевантных векторов v, в зависимости от текущего контекста, поэтому извлечение происходит с помощью вектора q. Похожее извлечение мы видим и в знаменателе, только там мы работаем только с накопленными векторами k, и берем максимум между получившимся значением модуля произведения векторов и единицы - это необходимо чтобы избежать деления на малые значения, близкие к нулю. В конце мы умножаем результат на output gate, как это делали в sLSTM.
Выходом mLSTM является скрытое состояние h (это будет хорошо видно по коду далее).
xLSTM
Поздравляю, что вы дочитали до этого места, потому что представляю, как сложно за один раз уложить в голове все вышенаписанное (мне потребовалось 2,5 дня полной работы со статьей).
Последнее, что нам остается - собрать две архитектуры в единую структуру и назвать ее xLSTM. Для каждого модуля разработан свой вариант построения сети.

Для sLSTM все начинается с LayerNorm (LN), через который проходит входной вектор. Далее опционально применяется 1D свертка с окном 4 и нелинейная функция Swish перед подачей данных в input и forget gate. Потом для input, forget, z и output gate данные подаются через блочно-диагональные линейные слои с четырьмя диагональными блоками (или головами).
Этот момент мне кажется довольно непростым для понимания, поэтому я решил порыться в коде имплементации. Если захотите подробно разобраться в этом шаге, то вам нужен класс LinearHeadwiseExpand, но если описывать кратко, то в этом классе входные данные проецируются в более высокую размерность, разделяясь на несколько независимых линейных преобразований (тех самых голов), преобразуя входной тензор x в форму (..., num_heads, in_features // num_heads)
self.weight = nn.Parameter(
torch.empty(num_heads, out_features_per_head, in_features // num_heads),
requires_grad=config.trainable_weight,
)x = x.view(*shape[:-1], self.config.num_heads, -1)
x = torch.einsum("...hd,hod->...ho", x, self.weight)
x = x.reshape(*shape[:-1], -1)Каждая голова имеет свой собственный набор весов (по сути это и есть то самое New Memory Mixing). Их результаты объединяются в один выходной тензор.
Далее происходит сама работа sLSTM, где sLSTMCell_vanilla возвращает ячейки памяти:
return torch.stack((ynew, cnew, nnew, mnew), dim=0),
torch.stack((igate, fgate, zraw, ogate), dim=0)Которые в дальнейшем (метод forward в классе sLSTMLayer) проходят через Dropout, поступают в GroupNorm и передаются сначала в up-projection для увеличения размерности (снова происходит параллельное разделение с использованием функции GeLU), а после в down-projection для возвращения данных к первоначальному размеру. Здесь происходит что то вроде отсева качественных данных, если можно это назвать так грубо. Не забудем про skip-connections, которые добавляются к результату, чтобы побороть затухание градиента.

Теперь обратимся к сети с mLSTM. При разборе, я опирался на код ее слоя mLSTMLayer. Ее pipeline выглядит примерно также, только входные данные сначала проходят через LayerNorm и up-projection, одновременно разделяясь на 2 потока - один проходит через mLSTM, другой через активацию Swish (или SiLU). Данные, поданные в mLSTM, снова разделяются (авторы очень любят паралеллить, как вы заметили) и для векторов q и k они предварительно проходят через слой 1D свертки с окном 4 аналогично sLSTM (от сюда же данные добавляются через LearnableSkip в пост обработку - этот LS является обучаемым). Точно также с помощью LinearHeadwiseExpand данные переводятся в блочно-диагональный вид (Block Size = 4) для каждого вектора и подаются в mLSTMCell, который возвращает h, c, n и m значения (m - это переменная из стабилизации):
h, (c_state_new, n_state_new, m_state_new)
Вот так это выглядит в коде:
h_tilde_state, mlstm_state = self.mlstm_cell.step(q=q, k=k, v=v, mlstm_state=mlstm_state)
Я не очень понял множество линий передачи матриц q, k и v, которые авторы нарисовали в блоке mLSTM на картинке выше. В коде не нашел ничего подобного - все сводится к скрытому состоянию h, к которому добавляется значение из LearnableSkip. Результат умножается на output gate от результата skip-connection через Swish (или SiLU) функцию, проходит через понижение размерности down-projection, слой dropout и возвращается вместе с вычисленными состояниями mlstm_state, conv_state:
h_tilde_state_skip = h_tilde_state + (self.learnable_skip * x_mlstm_conv_act)
# output / z branch
h_state = h_tilde_state_skip * self.ogate_act_fn(z)
# down-projection
y = self.dropout(self.proj_down(h_state))
return y, {"mlstm_state": mlstm_state, "conv_state": conv_state}Нужно отметить, что данные действительно проходят через GroupNorm, только реализован он в mLSTMCell в виде:
h_state_norm = self.outnorm(h_state) # (B, NH, S, DH)
Как же работает xLSTM? Все просто - эти слои соединяются друг с другом, формируя единую сеть с названием xLSTM. Рекомендую посмотреть пример в ноутбуке. Количество блоков той или иной архитектуры регулируется пропорцией, то есть в xLSTM[7:1] будет 7 блоков mLSTM и 1 блок sLSTM (или 42 mLSTM и 6 sLSTM).
Результаты
Их много, поэтому как обычно приведу несколько, которые меня привлекли больше всего (также не хочу увеличивать размер статьи). Если хотите узнать больше, то рекомендую прочитать их тут. Канал gonzo уважаю)
Итак, при сравнении предсказания следующей лексемы при обучении на 15B из SlimPajama, xLSTM показывает лучшие результаты (правда Llama бралась не 70B, а 1.3B). Аналогичная ситуация при трейне на 300B.


Экстраполяция последовательностей в языковом моделировании. Это сравнение больших моделей xLSTM, RWKV-4, Llama и Mamba размером 1,3B при предсказании следующей лексемы на валидационном наборе SlimPajama после обучения на 300B лексем от туда же. Модели обучались на длине контекста 2048, а затем тестировались на длинах контекста до 16384. Слева: оценка сложности лексем при различных длинах контекста. В отличие от других методов, модели xLSTM остаются на низком уровне сложности для более длинных контекстов. Справа: Качество предсказания при экстраполяции на большие размеры контекста в терминах валидационной perplexity (PPL). xLSTM дает лучшие значения PPL.

Итог
В целом видно, что RNN все также сильны и да, к ним в последнее время проявляется интерес. Сложно сказать из-за чего это происходит, но я полагаю, что люди пока не изобрели что-то лучше трансформеров и SSM, поэтому обращаются к прошлому и улучшают его.
Я не думаю, что сейчас все бигтехи массово перейдут на эту архитектуру. И никто не будет переобучать gpt-4 и gpt-4o на xLSTM (хотя xLSTM уже приспособили для задач CV - вот статья Vision-LSTM: xLSTM as Generic Vision Backbone).
Мое мнение - крутой апгрейд RNN, который, вероятно, локально применят в NLP/CV отделах RnD, в стартапах и в науке. Если он хорошо себя зарекомендует, есть вероятность, что увидим развитие этой технологии, а также новые решения в проде :)
Спасибо, что дочитали до конца! Я знаю, что это было трудно, но вы справились)