Large Parallelism Post: Part IV. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
В данной статье разработан метод параллельного обучения моделей с большим количеством параметров (от 100млрд до 1трл). ZeRO позволяет параллельно хранить и вычислять параметры модели, градиенты и параметры оптимизатора, сохраняя при этом низкий объем коммуникаций и высокую гранулярность вычислений.
Source: Arxive, ZeRO&DeepSpeed
Многие методы параллелизма неоптималены, когда речь идет про тяжелые модели и огромное количество данных. При этом хочется, чтобы паралеллизм сохранялся и в модели, и в данных. Ребята из Microsoft придумали Zero Redundancy Optimizer (ZeRO) - метод тренировки очень больших моделей (>100B параметров).
Для начала опишу проблему тренировки больших моделей - модель с 1 триллионом параметров и оптимизатором Adam в точности FP16 требует 16 Тб данных для хранения ее параметров, градиетов и значений оптимизатора. Такой объем данных необходимо разделять не только по памяти, но и вычислительно.
ZeRO имеет два подхода - ZeRO-DP (Data Parallel - сам механизм параллелизма) и ZeRO-R (Residual - оптимизация работы с памятью, чтобы ZeRO-DP работал корректно).
Начнем с ZeRO-DP - он имеет три вида оптимизации, которые соответствуют трем видам разделения параметров памяти:
1) Параметры модели. Это синий цвет и они имеют точность FP16
2) Градиенты точностью FP16 (оранжевый цвет), которые будут использованы для обновления весов на Backward проходе
3) Состояния оптимизатора. Выделены зеленым цветом - в него входят точные значения градиентов, дисперсия, моменты в точности FP32. Если вы используете SGD, то он не будет занимать много памяти, но вот если Adam, то памяти нужно будет тратить гораздо больше. Эти данные используются только после вычисления оранжевых градиентов.
FP16, FP32 - это точность, где 16 и 32 это сколько бит отводится под хранение. Подробнее про стандарт IEEE 754 можно посмотреть вот здесь.

ZeRO-R разработан для оптимизации работы с остаточной памятью во время работы ZeRO-DP. Вот что он делает:
1) Сохраняя промежуточные активации на Forward pass, чтобы использовать их на Backward pass, можно оптимизировать вычисления (Training Deep Nets with Sublinear Memory Cost), но это не работает на больших моделях. ZeRO-R разделяет и удаляет отработавшие реплики активаций.
2) Определяет соответствующий размер временного буффера для нахождения баланса памяти и вычислений (я не смог найти исходный код, поэтому не могу подробно рассказать как он это делает)
3) Предотвращает фрагментацию памяти. ZeRO-R управляет памятью, основываясь на различном времени жизни тензоров - скорее всего в зависимости от создания тензора он двигает его в ячейках памяти, чтобы не нарваться на OOM ошибку.
Фрагментация памяти - возникает когда вы заняли место в памяти, потом освободили часть из нее и пытаетесь записать память большего рамера. Проблема заключается в неудаленном фрагменте, который находится как бы посередине и из-за которого необходимо увеличивать ресурс, что может привести к ошибке переполнения (OOM) при одновременной доступности свободной памяти. Наглядно продемонстрировано тут
Давайте разберемся как оба подхода работают вместе.
Допустим у нас есть 4 карточки и тогда разделим входые данные на 4 части. Сама модель тоже делится на 4 части M [0-3], каждая из которых хранится на отдельном GPU (помним, что модель очень большая и хранить ее целиком на одной карте мы не можем). На каждой GPU создаем временные буфферы, в которых будем хранить промежуточные активации - они понадобятся на Backward pass. Далее с помощью broadcast распределяем параметры модели (голубые) с GPU [0] на каждое GPU [1-3] - параметров не так много и эта операция довольно дешевая.

На каждом GPU считаем Forward pass. Нужно заметить, что здесь мы сохраняем в буффер лишь часть активаций, чтобы не вызвать переполнение памяти.

Мы уже сталкивались с Activation Checkpointing в прошлой статье, однако я снова хочу остановиться на этом месте и объяснить более подробно, почему мы сохраняем лишь часть актиаций и что мы будем делать с ними потом. Я долго искал кодовую имплементацию ZeRO-R, но нашел лишь ZeRO-DP, где реализован случай полного параллелизма (ZeRO3 - случай os+g+p). Однако в документации AWS Neuron подробно и понятно описано это решение. Все дело в памяти и скорости вычислений - мы хотим сохранять расчитанные активации на Forward pass, чтобы не рассчитывать их снова на Backward pass и экономить время для вычисления градиентов. Однако при работе с большими моделями, у нас не хватит памяти сохранять сразу все активации, поэтому мы сохраняем лишь активации последнего слоя. Когда начинается Backward pass, мы досчитываем необходимые активации между сохраненными слоями, применяем их для вычисления градиентов, обновляем веса и удаляем все рассчитанные активации из памяти. Так мы одновременно экономим на вычислениях и памяти - что-то вроде trade-off между памятью и вычислениями. Хотя я наткнулся на дискуссию в GitHub, где говорят, что использовать такой метод доподсчета активаций не очень выгодно - видимо все зависит от размера модели.
После расчета части параметров модели M0, мы удаляем эти параметры из памяти GPU [1-3] (вот тут начинает работать ZeRO-R), потому что сохранив промежуточные активации, нам нет надобности хранить эту часть данных - нам придется так делать с каждой частью модели, а вся она точно не поместиться.

Так мы делаем для каждой части модели M [0-3] (то есть по очереди бродкастим параметры каждой части модели на остальные карты, считаем forward pass, сохраняем часть активаций и удаляем параметры). Когда процесс заканчивается на части M3, то на каждом GPU вычисляется значение Loss. Далее начинается Backward pass.

На каждом GPU дорасчитываются активации Forward (а часть уже сохранена) и на каждой карточке рассчитываются градиенты. Далее эти градиенты пересылаются на GPU [3], со всех остальных GPU и аккумулируются. Здесь происходит группировка градиентов - в оригинале авторы применяют на каждом процессе используют Reduce вместо AllReduce для экономии памяти.
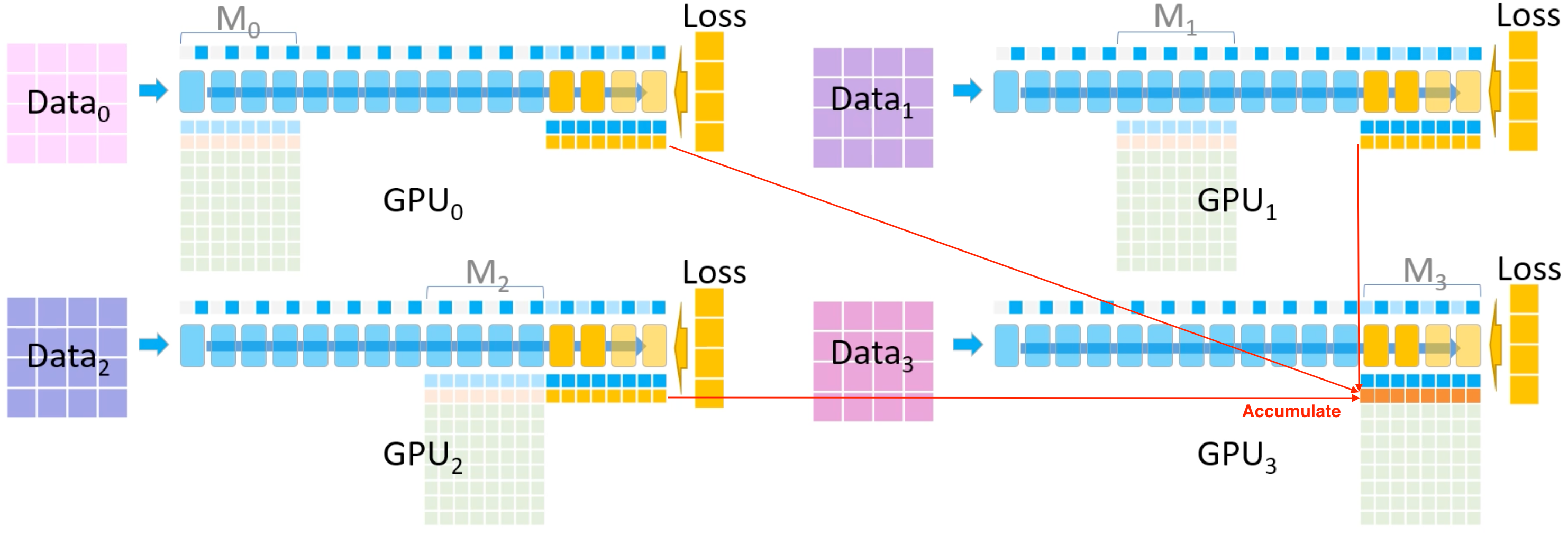
После расчета градиентов M3 с каждой карты и сохранения их на GPU [3], на других GPU данные промежуточных активаций, градиентов и параметров модели удаляются для освобождения памяти.

Аналогично пройдемся по остальным частям модели M [0-2] (во время Backward pass будем также делать broadcast параметров моделей на каждую карту и дорасчитывать параметры активаций) и в конце получим на каждом GPU параметры градиентов. Далее параметры градиентов запускаем в оптимизатор для обновления весов. Оптимизатор определит новые параметры модели в точности FP32, которые далее переведем в точность FP16. На этом шаге цикл завершается и все прошлые шаги повторяются заново.

Добавлю, что в 2023 году вышла статья ZeRO++: Extremely Efficient Collective Communication for Giant Model Training, в которой сделано 3 улучшения - в совокупности они повышают эффективность работы алгоритма в 4 раза:
- Квантование параметров с FP16 до INT8
- Иерархическое разбиение, которое позволяет избавиться от повторного вычисления данных
- Квантование градиентов, которое позволяет применять all-to-all обмен данными (вместо AllReduce)
Пишите в комментариях, если хотите разбор статьи :)
Results
По результатам пробегуcь как всегда быстро, потому что кто бы публиковал статью с плохими результатами?)))
Видим, что ZeRO-DP отлично превосходит 10 и 15 Pflops на моделях с большим количеством параметров, когда другие методы проседают.

Таблица с пояснением каждой конфигурации ZeRO - понадобиться для следующих графиков. С ZeRO-DP, думаю, все понятно - эти параметры нам встречались и ранее. А вот параметры ZeRO-R я прокомментирую:
- CB - Constant Size Buffers - при больших моделях используется постоянный размер буфера (если модели маленькие, то буфер уменьшается)
- MD - Memory Defragmentation - понятно, что фрагментация памяти так или иначе возникает при работе ZeRO, однако при работе с очень большими моделями он может выполнять дефрагментацию во время работы, предварительно выделяя смежные участки памяти для контрольных точек активации и градиентов и копируя их в предварительно выделенную память по мере их создания
- Pa - Partitioned Activation Checkpointing - стандартный Activation Checkpointing, но в случае очень больших моделей и очень ограниченной памяти, данные могут быть перегружены на CPU

На рисунке 6 показаны размеры моделей при использовании различных оптимизаций ZeRO для фиксированного batch-size = 16. На рисунке 7 показано максимальное количество памяти, кэшируемой PyTorch во время каждой итерации обучения для модели с параметрами 40B и 100B. Интересно, что 100В модель при конфигурации ZeRO 5 показывает примерно ту же кэшируемость, что и 40В на конфигурации 2 и 3. На рисунке 8 показано количество операций в секунду в зависимости от конфигурации ZeRO.
