Large Parallelism Post: Part V. FSDP: Fully Sharded Data Parallel
FSDP - параллелизм с полным шардингом данных. Реализован за счет разбиения операции AllReduce на две - ReduceScatter и AllGather, а также за счет перегруппировки этих операций. Имея шард модели, данные весов собираются с других GPU за счет AllGather, далее происходит Forward pass, после чего снова собираются веса через AllGather, и только потом проиходит Backward pass. В конце градиенты обновляются с помощью ReduceScatter. Имеет 3 типа шардинга - DDP, Hybrid Sharding и Full Sharding.
Source: HuggingFace, Habr, Meta
Обратимся к разобранному ранее методу DDP - модель копировалась на каждую машину с GPU, далее проходил расчет Forward и Backward проходов, а полученные значения градиентов усреднялись с помощью AllReduce.
Разработчики задаись вопросо - почему бы не изменить пайплайн усреднения и передачи данных? Ведь это можно сделать с помощью разбиения операции AllReduce на две: ReduceScatter и AllGather.

На фазе ReduceScatter градиенты суммируются в виде одинаковых блоков по рангам на каждом GPU на основании индексов их рангов. На фазе AllGather шард-порция агрегированных градиентов, имеющаяся на каждом GPU, делается доступной всем GPU.
Далее операции ReduceScatter и AllGather перегруппировываются таким образом, чтобы каждому DDP-воркеру нужно было бы хранить лишь единственный шард параметров и состояний оптимизатора.


Более подробный пайплайн полного прохода FSDP на трех нодах [0-2] изображен на рисунке ниже.

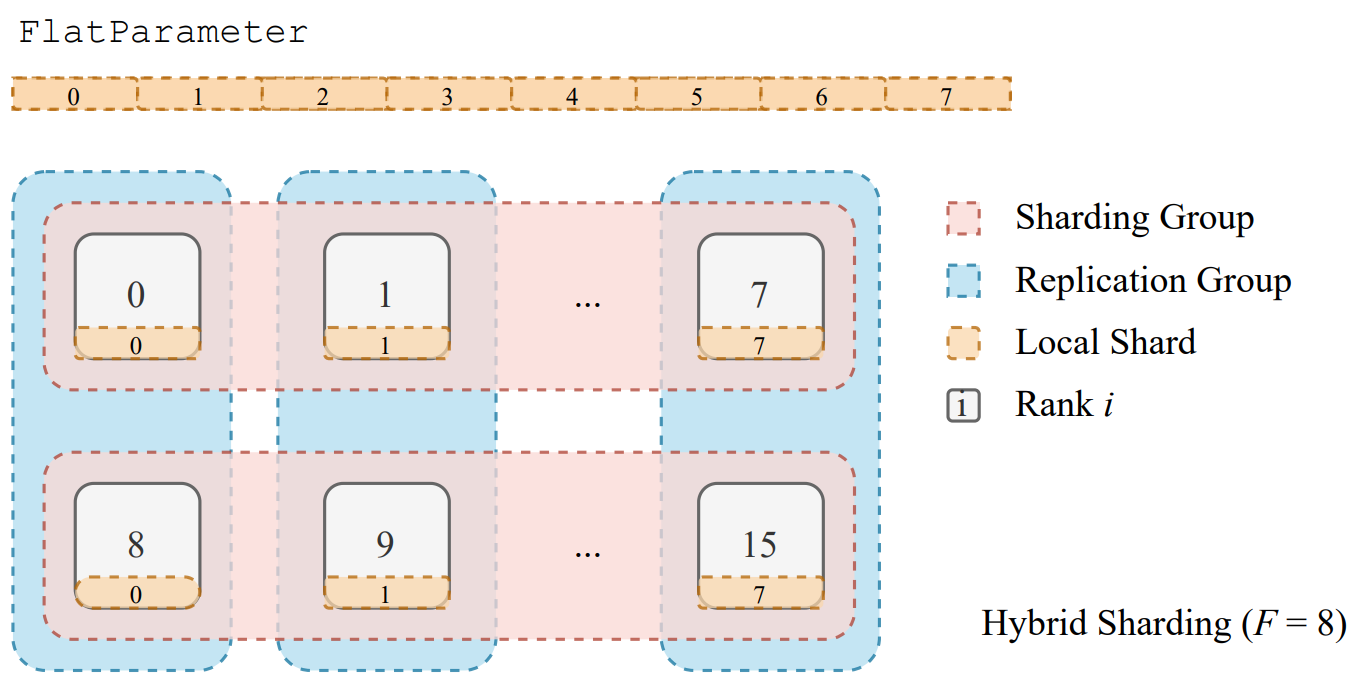
Разработчики также отмечают, что существуют разные стратегии шардинга параметров. Для их классификации они вводят коэффициент F - количество уровней, на которые распределяется модель. Например, если F равен 1, то вся модель будет загружена на каждую моду и мы получим классический DDP - этот случай разобран в прошлом посте. Если F задать количество GPU (обозначим это количество за W), то тогда на каждой ноде будет 1/W часть модели. Также есть гибридный шардинг - когда F принимает значения между 1 и W. Кратко отмечу параметры Full Sharding (F=W) и Hybrid Sharding (1<F<W) для случая с 16 GPU:
Full Sharding - вся модель шардится по всем GPU. На рисунке видно, что все веса разделяются между нодами, при этом они состовляют единую группу шардинга, так как являются частями одной модели. Этот способ обеспечивает наименьший объем занимаемой памяти, но требует наибольших затрат на коммуникацию параметров (в 1,5 раза больше, чем в DDP)

Hybrid Sharding - это нечто среднее между DDP и Full Sharding. В этом случае у нас есть частичная репликация модели, а также шардинг ее параметров. Розовым выделены части шардинга модели - то есть модель копируется два раза, а веса каждой копии (репликация) распределяются между GPU (в данном случае 8). Чтобы проще это понять, представьте, что вы взяли 16 GPU и задали параметр шардинга 8 - это значит, что у вас будет 16/8 = 2 группы шардинга на 8 GPU - то есть на 16 GPU будет лежать 2 модели. А веса этих двух одинаковых моделей распределяться по группам репликации - для каждой группы по 2 GPU. Так как каждая модель разбивается на 8 частей - вот и получается 16 GPU. Такой способ используется для моделей средних размеров - они слишком малы для полного шардинга из-за низкой скорости коммуникации и слишком большие, чтобы их тренировать классическим DDP.
Для финала приведу показатели TFLPOS на каждое GPU от размера моделей. Видно, что Full Sharding немного выигрывает в каждом варианте - однако не стоит забывать, что у него самый низкий показатель коммуникации параметров.
