DenseAttention: No-Compromise Exact All NxN Interactions Algorithm with O(N) Space and Time Complexity
Возможны ли нейросети без нелинейностей? Возможно ли сделать сеть только из матричных умножений - наиболее эффективных по вычислениям и с возможностью параллелизма? И самое главное - не потерять при этом точность работы трансформера. В этой статье показывается, что это возможно. Определив и выкинув наиболее слабые части архитектуры, автор заменяет их матричными умножениями, а где-то вводит новые преобразования для повышения эффективности модели. В результате получается DenseAttention - структура с повышенной точностью и эффективностью вычислений.
Source: Architecture's author - Andrew Argatkiny, DenseAttention paper, DenseAttention Github, VK Lab Meeting
Motivation
Основным минусом нелинейностей является их неэффективность в вычислениях. Например, метрика Model FLOPS Utilization (MFU), которая является отношением наблюдаемой пропускной способности к теоретической максимальной пропускной способности, если бы модель работала с пиковым значением FLOPS без накладных расходов на память или связь, довольно низка в современных архитектурах:
MosaicBERT - 40%
PaLM - 46%
FlashAttention 2 - 72%
Так происходит, потому что GPUs не производят никаких вычислений, пока считывается/записывается память. В статье Data Movement Is All You Need показано, что матричные умножения в модели BERT-large составляют 99.8% всех вычислений (FLOPS), но они занимают лишь 61% времени вычисления. А 31% времени тратится на вычисление оставшихся операций (которые составляют 0.02% FLOPS). То есть трансформер, из-за ограниченности памяти, вычислительно неэффективен.
Углубляясь в проблему, приведу метрику Arithmetic Intensity (ArIn) - отношение общего количества операций FLOPS к общему количеству перемещений данных (байт):
Для эффективности алгоритма необходимо (но не достаточно), чтобы его значение ArIn было выше, чем ArIn ускорителя. Иначе часть времени ускоритель будет простаивать, что и было показано в статье выше.
Чему же равны метрики ArIn современных ускорителей и вычислительных операций, применяющихся в трансформере? У NVIDIA A100 этот показатель равен 156 FLOPS/B, тогда как в трансформере мы имеет следующие значения:
То есть мы видим разницу ArIn минимум в 3-4 порядка. Это оказывает колоссальное влияние на время работы трансформера. Добавлю, что эти нематричные операции выполняются не на тензорных ядрах, а на обычных, что также снижает их эффективность.
Однако и с матричными вычислениями не все в порядке. Основная операция Attention - softmax(Q *K^T)*V - имеет 32 FLOPS/B.
Можно ли заменить эти операции и даже избавиться от них и создать новую, более эффективную архитектуру?
Designing DenseAttention
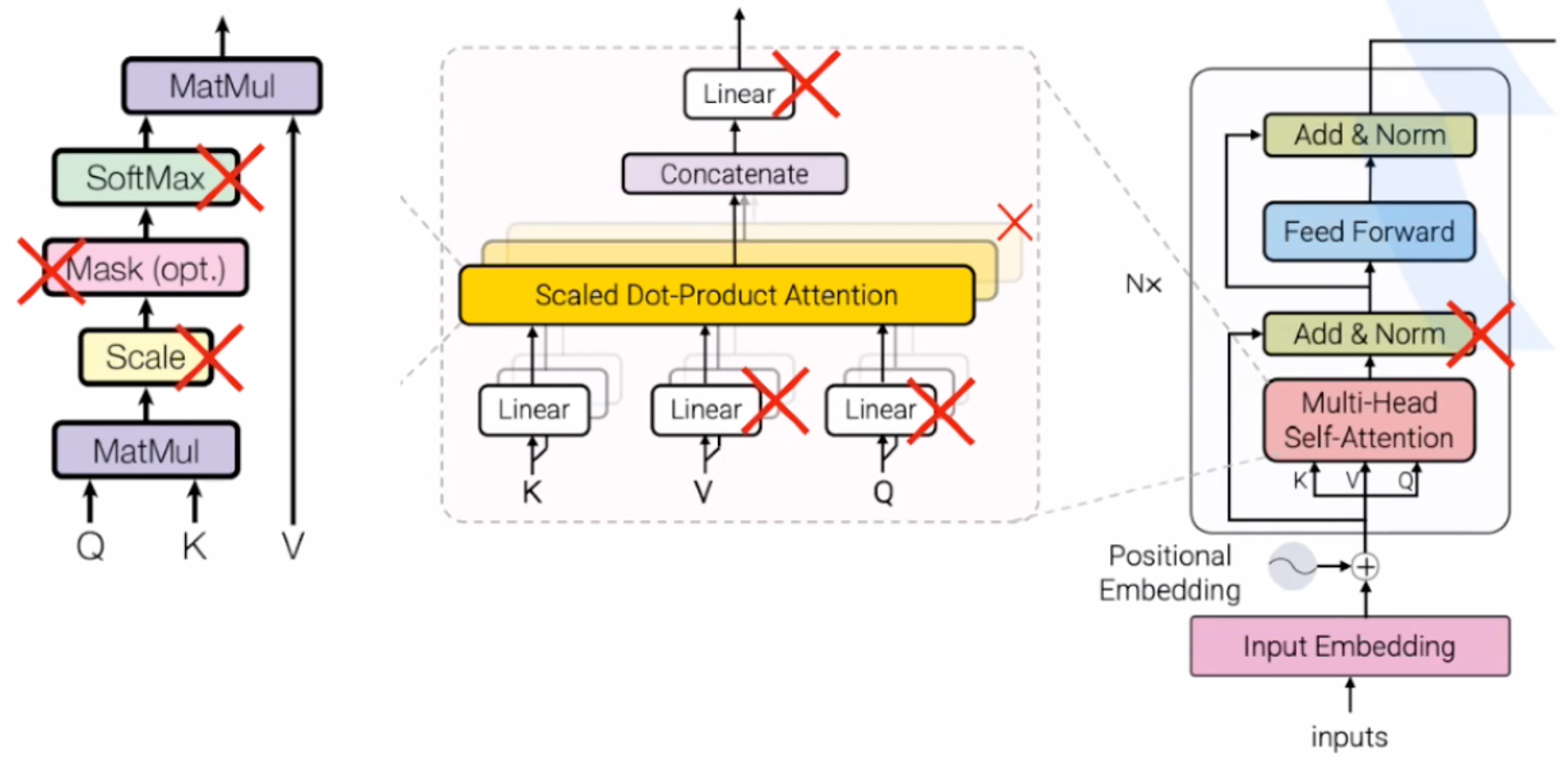
Для начала автор удаляет некоторые составляющие:
- Dropouts - на этапе pre-train они не нужны, но их можно добавить в этап fine-tune
- Masking - можно убрать с энкодера (и с декодера тоже можно)
- Scale - его можно перенести
- Softmax
- W_keys, W_values, W_output
- Между слоями Attention и FNN убираем LayerNorm и skip-connections
Самой большой проблемой является softmax - без него выходы Attention неограничены, возрастают в полиномиальной степени и в итоге сходятся либо к нулю, либо к бесконечности.
Давайте попробуем разобраться почему это происходит. Рассмотрим упрощенную матрицу attention
Стандартное отклонение каждого элемента матрицы Y ограничено снизу, но не ограничено сверху. Даже если матрицы X и W независимо распределенные, проблема остается - мы не знаем точное распределение X. А это распределение получается с толстыми и тяжелыми хвостами -> на каждом новом слое оно уходит в бесконечность, а значит понять распределение Y невозможно.В этом случае LayerNorm не помогает, потому что опирается на L2-норму.
Давайте попробуем поменять норму. Возьмем бесконечную норму - модуль максимального значения этой матрицы:
Для этой нормы мы можем вывести такие условия, при которых выход attention будет ограничен. Введем для исследования матрицу Z, которая будет произведением трех матриц X:
Тогда, если бесконечная норма матрицы Z ограничена, то и выход attention будет ограничен.
В статье приводится детальное доказательство этого факта, основанного на ограничении дисперсии произведения матрицы X и W.
Вводя новый scale factor, равный 1/N^(1/3), норма матрицы будет ограничена сверху размерностью эмбеддинга. Тем самым мы полностью можем избавиться от softmax без потери качества работы алгоритма.
Тогда введем новую операцию - MaxNormActivation:

Такая норма не центрирована, в ней нет bias и нет никаких весов.
Введя такой трюк, мы получаем большую эффективность - без softmax мы получаем ассоциативность матричных умножений:
То есть теперь мы можем варьировать нашу вычислительную сложность в зависимости от размера датасета и эмбеддинга. Но в любом случае наш алгоритм будет работать намного быстрее, чем раньше.

Также в DenseAttention автор уменьшает количество голов в архитектуре - рассматривается два варианта: либо одна большая, либо 4 маленьких. Таким образом получается выигрыш по вычислениям и точности модели. Так, используя только одну голову с размерностью d=1024 для модели BERTLarge операции умножения матриц уже составляют 205 FLOPS/B, против 32.
Продолжая тематику удаления вычислений из трансформера, автор удаляет матрицу keys - W_keys. В стандартном механизме attention каждый раз происходит перемножение двух низкоранговых матриц - queries и keys. Они низкоранговые, потому что имеют размерность d эмбеддинга / d головы. В DenseAttention ранг выходной матрицы гораздо выше, а значит операция перемножения ее на низкоранговую избыточна. Поэтому мы можем удалить матрицу keys для экономии ресурсов. Матрицы W_values, W_output удаляются по той же причине.
Последним удалением в архитектуре является LayerNorm и skip-connections. Эмпирически показано, что их удаление не ведет к уменьшению метрик модели.
Теперь в нашей архитектуре нелинейности остались лишь в конце блока attention и FFN!
Финальная архитектура DenseAttention имеет вид:

В формулах для общего случая нескольких голов это выглядит так:


Благодаря этому, обновленная архитектура attention имеет вычислительную сложность 11Nd^2 в случае O(N) и 9Nd^2 + 2dN^2 в случае O(N^2), что вычислительно превосходит стандартную архитектуру, особенно на длинных последовательностях.
Cosine RelPE
Помимо повышения эффективности вычислений, автор вводит новую функцию positional encoding. Дело в том, что современные модели чаще всего используют Rotary Positional Embeddings (RoPE), который применяет преобразования к матрицам Q и K. Однако в работе RoFormer: Enhanced Transformer with Rotary Position Embedding авторы показали, что параметризация, используемая в RoPE приводит к долгосрочному снижению нормы выхода attention. Более того, преобразования RoPE неэффективны в вычислительном отношении, поскольку их вычисление требует дорогостоящих изменений структуры тензора и нескольких поэлементных операций с низкой ArIn, отдельно для Q и K.
Автор вводит новое преобразование g1, которое вычислительно более эффективно, ведь оно допускает только одно element-wise умножение, вместо двух:
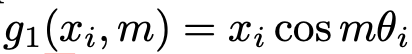
Тогда новое преобразование Cosine RelPE:

Автор использует его перед слоем DenseAttention и отмечает, что хоть такое преобразование влияет на матрицу, оно не ухудшает производительность.
LocalAttention
Последним улучшением в данной статье является применение технологии LocalAttention, которая в последнее время стала популярна благодаря снижению вычислительных затрат и потребления памяти. LocalAttention определяет окно фиксированного размера, в пределах которого каждый элемент может взаимодействовать только за соседними элементами.
Автор также вводит LocalAttention, однако делает это не ради повышения эффективности вычисления, а ради увеличения качества модели. LocalAttention в данном случае состоит из трех уровней: LocalAttention, ShiftedLocalAttention и global DenseAttention.

LocalAttention классически разбивает последовательность на окна равного размера w, но в таком случае половина информации теряется. Поэтому вводится ShiftedLocalAttention, который смещен на w/2 относительно первого, что позволяет всем токенам иметь симметричное соседство после двух последовательных слоев. Последний слой global DenseAttention охватывает весь контекст последовательности. Все 3 слоя могут соединяться вместе, как обычные слои трансформера.
Experiments
Как обычно, по экспериментам пройдусь быстро.
Long Range Arena - это сложный набор из 6 классификационных тестов, предназначенных для изучения возможностей эффективных моделей с длительным контекстом на больших последовательностях длиной от 1к до 16к.

BERT pre-train с размерностью модели d = 1024 на тех же датасетах - Wikipedia и BookCorpus. Отмечу, что BERT-large был увеличен с 24 до 32 слоев, чтобы сохранять одинаковое количество параметров.

SpeedTest алгоритмов DenseAttention, standard BERT и FlashAttention-2:
