Архитектура Kubernetes
В этой главе мы рассмотрим архитектуру Kubernetes, различные компоненты master (главный узел) и worker nodes (рабочий узлов), управление состоянием кластера с помощью etcd и требования к настройке сети. Мы также поговорим о спецификации сети Container Network Interface (CNI), которая используется Kubernetes.
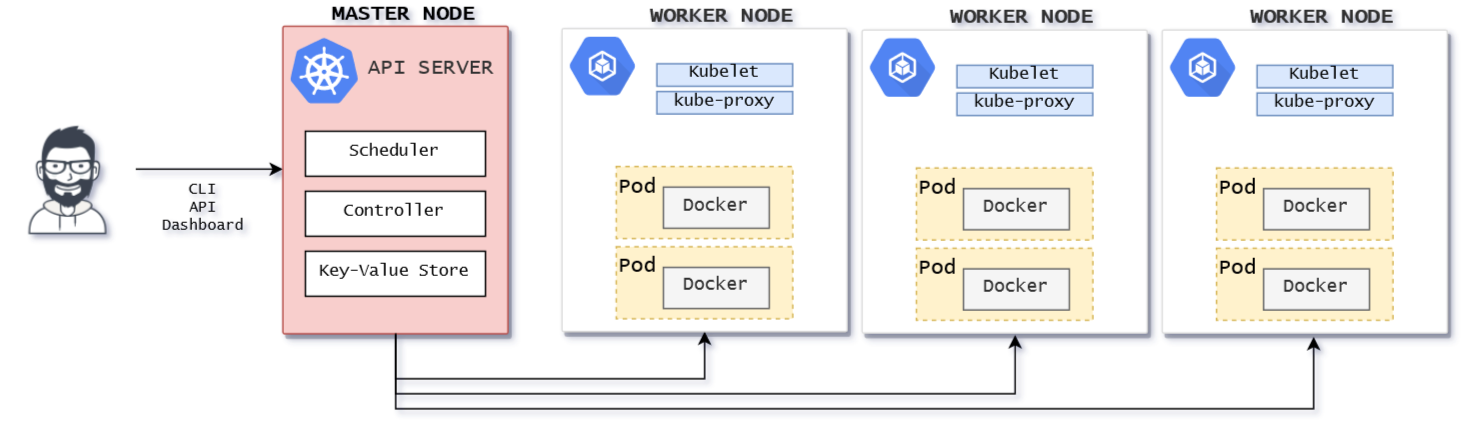
Если рассматривать Kubernetes на “высоком” уровне, то он имеет следующие компоненты:
- Один или несколько главных узлов (master)
- Один или несколько рабочих узлов (worket node)
- Распределенное хранилище ключей и значений, например etcd.
Master Node
Главный узел (master) отвечает за управление кластером Kubernetes и является точкой входа. Мы можем связаться с главным узлом через CLI, GUI (Dashboard), или через API.
Для обеспечения отказоустойчивости в кластере может быть несколько главных узлов. Если у нас есть более одного главного узла, они будут находиться в режиме HA (High Availability), и только один из них будет ведущим, выполняющим все операции. Остальные главные узлы будут последовательными.
Для управления состоянием кластера Kubernetes использует etcd, и все главные узлы подключаются к нему. etcd — это распределенное хранилище ключей и значений. Хранилище ключ-значение может быть частью главного узла. Он также может быть настроен извне, в этом случае главные узлы будут подключаться к нему.
Компоненты главного узла
Главный узел имеет следующие компоненты:
- API server
- Scheduler
- Controller manager
- etcd
API Server
Все административные задачи выполняются через сервер API на главном узле. Пользователь / администратор отправляет команды REST на сервер API, который затем проверяет и обрабатывает запросы. После выполнения запросов результирующее состояние кластера сохраняется в распределенном хранилище ключ-значение.
Scheduler
Как следует из названия, планировщик планирует работу на разных рабочих узлах. Планировщик содержит сведения об использовании ресурсов для каждого рабочего узла. Он также знает об ограничениях, которые могут быть установлены пользователями/администраторами, например о планировании работы на узле с меткой disk==ssd. Перед планированием работы, планировщик также учитывает качество обслуживания требований, сведения населенного пункта, близость, анти-аффинити, и т. д. Планировщик планирует работу с точки зрения модулей и служб.
Controller Manager
Диспетчер контроллера управляет различными непрерывными циклами управления, которые регулируют состояние кластера Kubernetes. Каждый из этих циклов управления знает о желаемом состоянии объектов, которыми он управляет,и отслеживает их текущее состояние через сервер API. В цикле управления, если текущее состояние управляемых им объектов не соответствует требуемому состоянию, цикл управления выполняет корректирующие действия, чтобы убедиться, что текущее состояние совпадает с требуемым состоянием.
etcd
Как обсуждалось ранее, etcd — это распределенное хранилище ключ-значение, которое используется для хранения состояния кластера. Он может входить в состав мастера Kubernetes или настраиваться извне, в этом случае к нему будут подключаться главные узлы.
Worker node
Рабочий узел (node) — это сервер (виртуальная машина, физический сервер и т. д.), который запускает приложения с помощью Pod и управляется главным узлом. Pods планируются на рабочих узлах, которые имеют необходимые инструменты для их запуска и подключения. Pod — это единица планирования в Kubernetes. Это логическая коллекция одного или нескольких контейнеров, которые всегда планируются вместе.
Рабочий узел имеет следующие компоненты:
- Container runtime
- kubelet
- kube-proxy
Container runtime
Для запуска и управления жизненным циклом контейнера необходима среда выполнения контейнера на рабочем узле. Некоторые примеры сред выполнения контейнеров:
Docker также называют средой выполнения контейнера, но если быть точным, Docker — это платформа, которая использует containerd в качестве среды выполнения контейнера.
kubelet
Kubelet — это агент, который работает на каждом рабочем узле (worker node) и взаимодействует с главным узлом (master). Он получает определение пода с помощью различных средств (в первую очередь, через сервер API), и запускает контейнеры, связанные с подом. Он также постоянно проверяет, что контейнеры которые являются частью подов, работают корректно и без сбоев.
Kubelet подключается к среде выполнения контейнера с помощью Container Runtime Interface (CRI). Интерфейс среды выполнения контейнера состоит из буферов протоколов, gRPC AP и библиотек.
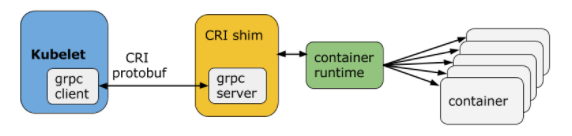
Как показано выше, kubelet (клиент grpc) подключается к оболочке совместимости CRI (сервер grpc) для выполнения операций с контейнерами и образами. CRI реализует два сервиса: ImageService и RuntimeService. ImageService отвечает за все операции, связанные с образом, в то время как RuntimeService отвечает за все поды и связанные с контейнером операции.
Среды выполнения контейнеров раньше были жестко запрограммированы в Kubernetes, но с развитием CRI теперь в Kubernetes можно использовать другие среды выполнения контейнеров без необходимости перекомпиляции. Любая среда выполнения контейнера, реализующая CRI, может использоваться Kubernetes для управления модулями, контейнерами и образами контейнеров.
kubelet: CRI shims
- dockershim
С помощью dockershim контейнеры создаются с помощью Docker, установленного на рабочих узлах. Внутри Docker использует containerd для создания контейнеров и управления ими.
- cri-containerd
С cri-containerd, мы можем напрямую использовать меньшие потомство Docker containerd для создания и управления контейнерами.
- CRI-O
CRI-O позволяет, используя любой Open Container Initiative (OCI), совместимых сред с Kubernetes. Во время создания этого курса CRI-O поддерживал runC и lear Containers в качестве сред выполнения контейнеров. Однако, в принципе, любая OCI-совместимая среда выполнения может быть подключена.
kube-proxy
Вместо прямого подключения к модулям для доступа к приложениям мы используем логическую конструкцию Service в качестве конечной точки подключения. Service группирует связанные модули и при доступе балансирует нагрузку на них.
kube-proxy — это сетевой прокси, который работает на каждом рабочем узле и прослушивает сервер API для каждого создания/удаления конечной точки службы. Для каждой конечной точки службы kube-proxy настраивает маршруты таким образом, чтобы можно было добраться до нее.
State Management with etcd
Управление состоянием с etcd
Kubernetes использует etcd для хранения состояния кластера. etcd-это распределенное хранилище ключей и значений, основанное на алгоритме консенсуса плотов. “Плот” позволяет коллекции машин работать, как единая группа, которая может пережить отказы некоторых из ее членов. В любой момент времени один из узлов в группе будет мастером, а остальные - последователями. Любой узел можно рассматривать, как главный.
etcd написан на языке программирования Go. В Kubernetes, помимо хранения состояния кластера, etcd также используется для хранения сведений о конфигурации, таких как подсети, карты конфигурации, секреты и т.д.
Network Setup
Настройка сети
Чтобы иметь полностью функциональный кластер Kubernetes, необходимо убедиться в следующем:
- Каждому поду присваивается уникальный IP-адрес
- Контейнеры пода могут взаимодействовать друг с другом
- Под может взаимодействовать с другими подом в кластере
- Приложение, развернутое в поде, доступно из Интернета.
Назначение уникального IP-адреса каждому модулю
В Kubernetes каждый модуль получает уникальный IP-адрес. Для контейнерной сети существует две основные спецификации:
- Container Network Model (CNM), by Docker
- Container Network Interface (CNI), by CoreOS
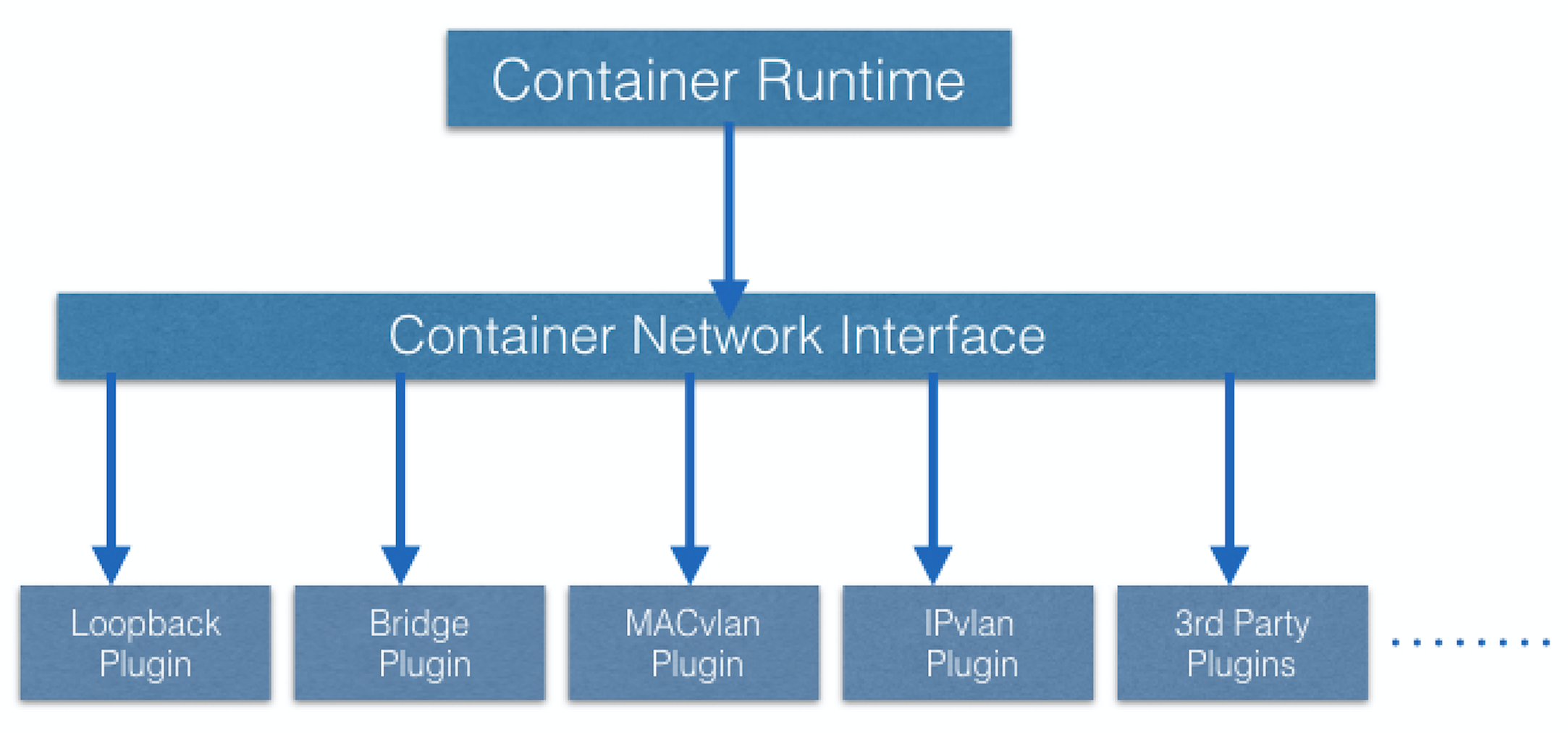
Kubernetes использует CNI для назначения IP-адреса каждому поду.
Среда выполнения контейнера разгружает назначение IP к CNI, который соединяется с базовым настроенным плагином, как мост или MACvlan, для получения IP-адреса. Как только IP-адрес дается соответствующим плагином, CNI передает его назад к запрошенной контейнерной среде выполнения.
Связь контейнер-контейнер внутри пода
С помощью базовой операционной системы все среды выполнения контейнера обычно создают изолированную сетевую сущность для каждого запускаемого контейнера. В Linux эта сущность называется сетевым пространством имен (network namespace). Эти сетевые пространства имен могут совместно использоваться контейнерами или операционной системой узла.
Внутри пода контейнеры совместно используют сетевые пространства имен, чтобы они могли достигать друг друга через localhost.
Pod-to-Pod связь внутри ноды
В кластерной среде поды можно запланировать на любом узле. Мы должны убедиться, что поды могут взаимодействовать между нодами, и все ноды должны быть в состоянии достичь любого пода. Kubernetes также ставит условие, что не должно быть никакого преобразования сетевых адресов (NAT) при выполнении Pod-to-Pod связи между хостами. Мы можем достичь этого с помощью:
- Маршрутизируемые поды и ноды, использующие базовую физическую инфраструктуру, например Google Kubernetes Engine.
- Используя програмное обеспечение Flannel, Weave, Calico
Более детально описано в документации.
Связь между внешним миром и подами
Предоставляя наши сервисы внешнему миру с помощью kube-proxy, мы можем получить доступ к нашим приложениям извне кластера.