Почему размытие плохо скрывает конфиденциальную информацию
Наверняка все видели по телевизору и в интернете фотографии людей, специально размытые, чтобы скрыть их лица. Например, Билл Гейтс:

По большей части это работает, поскольку нет удобного способа обратить размытие обратно в достаточно детализированное фото, чтобы распознать лицо. Так что с лицами всё нормально. Однако многие прибегают к размытию конфиденциальных чисел и текста. Я покажу, почему это плохая идея.
Предположим, кто-то выложил в интернет фотографию своего чека или кредитной карты по какой-то ужасной причине (доказывая на форуме, что он заработал миллион долларов или показывая что-то смешное, или сравнивая размер чего-то с кредитной картой и т. д.), размыл изображение с помощью слишком распространённого эффекта мозаики, чтобы скрыть цифры:

Кажется безопасным, ведь никто не прочитает цифры? НЕПРАВИЛЬНЫЙ ОТВЕТ. На эту схему есть атака:
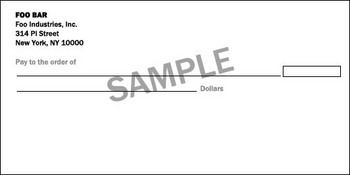
Шаг 1. Получите чистое изображение чека
Есть два способа сделать это. Вы можете или убрать цифры в графическом редакторе, или завести счёт в том же банке и сфотографировать собственную карточку с такого же угла, совместить баланс белого и контраст. Затем уберите с неё номера в графическом редакторе (на фотографии высокого разрешения это проще сделать).
На наших примерах, конечно, это легко делается:
Шаг 2. Итерации
Используйте скрипт для перебора всех возможных номеров счетов и создания чека для каждого, разделяя группы цифр. Например, на картах VISA цифры сгруппированы по 4, поэтому вы можете индивидуально обработать каждый раздел. Это требует всего 4×10000 = 40000 изображений, что легко генерируется скриптом.
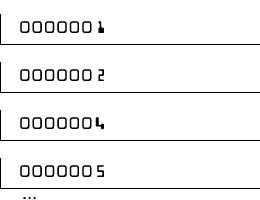
Шаг 3. Размойте каждое изображение идентично исходному
Определите точный размер и смещение в пикселях мозаичных плиток, используемых для размытия исходного изображения (легко), а затем сделайте то же самое с каждым из ваших размытых изображений. В этом случае мы видим, что размытое изображение состоит из мозаики 8x8 пикселей, а смещение определяется подсчётом от верхней границы изображения (не показано):

Теперь перебираем все изображения, размывая их так же, как исходное, и получаем что-то вроде этого:

Шаг 4. Определите вектор яркости мозаики каждого размытого изображения
Что это значит? Ну, давайте возьмём мозаичную версию 0000001 (увеличено):

… и определите уровень яркости (0-255) каждой области мозаики, именуя их некоторым согласованным образом как


В этом случае номер счёта 0000001 создаёт вектор яркости мозаики

Мы находим вектор яркости мозаики для каждого номера счёта аналогичным образом, используя скрипт для размытия каждого изображения и считывания яркости. Пусть a(x) - функция номера счета х. Тогда a(x)i, обозначает i-тое векторное значение вектора яркости мозаики ai, полученное из номера счета x. Выше a(0000001)1 = 213
Теперь делаем то же самое для исходного контрольного изображения, которое мы нашли в интернете или где угодно, получая вектор, который мы здесь назовём


Шаг 5. Найдите то, которое ближе всех к исходному изображению
Определите вектор яркости мозаики исходного изображения, назовём его
а затем просто вычислите расстояние от каждого номера счёта, обозначенного

до вектора яркости мозаики (после нормализации):

где N(a(x)) и N(z) — константы нормализации, заданные


Теперь просто найдём наименьший d(x)
Для кредитных карт только небольшая часть возможных номеров подтверждает гипотетически возможные номера кредитных карт, поэтому здесь тоже ничего сложного.
Например, в нашем случае вычисляем,



а затем приступим к расчёту расстояний:




Может, номер счёта соответствует мозаике 1124588?
«Но ты использовал собственное изображение, которое легко расшифровать!»
В реальном мире настоящие фотографии, а не фиктивные примеры, сделанные в Photoshop. У нас есть искажения текста из-за угла камеры, несовершенного выравнивания и так далее. Но это не мешает человеку точно определить тип искажения и создать соответствующий скрипт! В любом случае, несколько минимальных определённых расстояний могут рассматриваться как кандидаты, и особенно в мире кредитных карт, где номера красиво разбиты на группы по 4, и только 1 из 10 номеров на самом деле является валидным номером, что позволяет легко выбрать из нескольких наиболее вероятных кандидатов.
Чтобы реализовать это на реальных фотографиях, следует улучшить алгоритм расстояния. Например, можно переписать приведённую выше формулу расстояния для нормализации стандартных отклонений в дополнение к средним. Можно также независимо обрабатывать значения RGB или HSV для каждой области мозаики, а также использовать скрипты для искажения текста на несколько пикселей в каждом направлении и сравнения (что по-прежнему оставляет вам вполне ограниченное количество сравнений на быстром ПК). Можно использовать алгоритмы, аналогичные существующим алгоритмам ближайшего соседа, чтобы повысить надёжность работы на реальных фотографиях.
Так что да, я использовал своё изображение и приспособил его для данного случая. Но алгоритм, безусловно, можно улучшить для реального применения. Но у меня нет ни времени, ни желания что-либо улучшать, потому что я не охочусь за вашей информацией. Но одно можно сказать наверняка: это очень простая ситуация. Не используйте простые мозаики, чтобы размыть изображение. Все, что вы делаете, это уменьшаете объём информации на изображении, которое содержит всего

эффективных бит данных аккаунта. Когда вы распространяете такие изображения, вы хотите устранить личную информацию, а не затруднить доступ к ней, уменьшив количество визуальной информации.
Представьте графическое изображение 100×100. Предположим, что я просто усреднил пиксели и заменил каждый из них средним значением (т. е. превратил картинку в однопиксельную «мозаику»). Вы только что создали функцию, которая из 256^(10000) вариантов хешируется до 256 вариантов. Очевидно, что с полученными 8 битами вы никак не сможете восстановить исходное изображение. Но если вы знаете, что всего существует 10 вариантов исходного изображения, то по этим 8 битам легко определите, какое из них было использовано.
Аналогия с атакой по словарю
Большинство системных администраторов UNIX/Linux знают, что пароли в /etc/passwd или /etc/shadow шифруются односторонней функцией, такой как Salt или MD5. Это достаточно безопасно, так как никто не сможет расшифровать пароль, глядя на его зашифрованный текст. Аутентификация происходит путём выполнения одного и того же одностороннего шифрования пароля, введённого пользователем при входе в систему, и сравнения этого результата с сохранённым хешем. Если они совпадают, пользователь успешно прошёл проверку.
Хорошо известно, что односторонняя схема шифрования легко ломается, когда пользователь в качестве пароля выбирает словарное слово. Все, что нужно сделать злоумышленнику, это зашифровать весь словарь английского языка, сравнить зашифрованный текст каждого слова с зашифрованным текстом, хранящимся в /etc/passwd, и выбрать правильное слово в качестве пароля. Таким образом, пользователям обычно рекомендуется выбирать более сложные пароли, которые не являются словами. Атаку по словарю можно проиллюстрировать следующим образом:

Аналогично и размытие изображения является односторонней схемой шифрования. Вы преобразуете изображение, которое у вас есть, в другое изображение, предназначенное для публикации. Но поскольку номера счетов обычно не превышают миллионов, мы можем собрать «словарь» возможных номеров. Например, все номера от 0000001 до 9999999. Затем запустить автоматическую обработку, которая помещает каждое из этих изображений на фотографию пустого фона — и размыть каждое изображение. Затем остаётся просто сравнить размытые пиксели и посмотреть, какие варианты наиболее близко соответствует оригиналу.
Решение
Решение простое: не размывайте изображения! Вместо этого просто закрасьте их:

Помните, что вы хотите полностью убрать информацию, а не уменьшить её количество, как на размытой фотографии.