Извлекаем email адреса из текста при помощи Google Sheets или R
Предположим что у вас есть задача извлечь адреса электронных почт из ячеек, в которых кроме имейлов содержится и другая информация в текстовом формате.
Это можно сделать тремя способами:
Руками - мы понятно его рассматривать не будем. Хотя если есть чужие и очень дешевые руки, а также непреодолимое желание почувствовать себя рабовладельцем - то конечно можно. Кто я такой чтобы запрещать?
Через Google Sheets - наиболее оптимальный и с низким порогом вхождения.
Через язык программирования R - тот же результат, но изящнее и проще реализовывается, если необходимо работать с большим количеством однотипных файлов.
Данные для работы
В моем примере есть небольшой файл, который содержит выгрузку аккаунтов из instagram с описанием из шапки профиля(description или biography кто как называет). Из этого поля мы и будем извлекать имейлы.
Небольшой файл с примером доступен по ссылке
Регулярное выражение
Если быть честным, то по сути данный способ подходит для любых языков программирования, потому что в его основе лежит простое регулярное выражение. А уже где вы его будете использовать это вам решать.
Сама регулярка выглядит так:
[A-z0-9._%+-]+@[A-z0-9.-]+\.[A-z]{2,4}
ее мы и будем использовать в обоих случаях
Извлекаем адреса электронных почт при помощи регулярных выражений в Google Sheets
Насколько я знаю, в Microsoft Excel такой возможности "из коробки" нет и там придется извращаться через макросы VBA. Поэтому мы и используем гугл таблицы. Но киньте в меня справочником если я ошибаюсь.
Для этого нам понадобится всего одна функция, которая и сделает всю работу за нас.
REGEXEXTRACT
Формула работает по принципу REGEXEXTRACT(текст; регулярное выражение)
Вписываем формулу в ячейку и вместо парметра "текст" ставим ссылку на нужную нам ячейку таблицы(в примере это ячейка А2). Вторым параметром пишем нашу регулярку(обязательно в кавычках)

Протягиваем по всему столбцу и получаем результат. Как видно, в тех строках, которые не содержат имейлов, формула выдает ошибку. Можно удариться в перфекционизм и добавить другую формулу IFERROR (ЕСЛИОШИБКА) которая заменит стандартный текст ошибки на какой нибудь другой, например "No email"
Конечная формула и результат выглядят так:
ЕСЛИОШИБКА(REGEXEXTRACT(A2;"[A-z0-9._%+-]+@[A-z0-9.-]+\.[A-z]{2,4}");"No email")
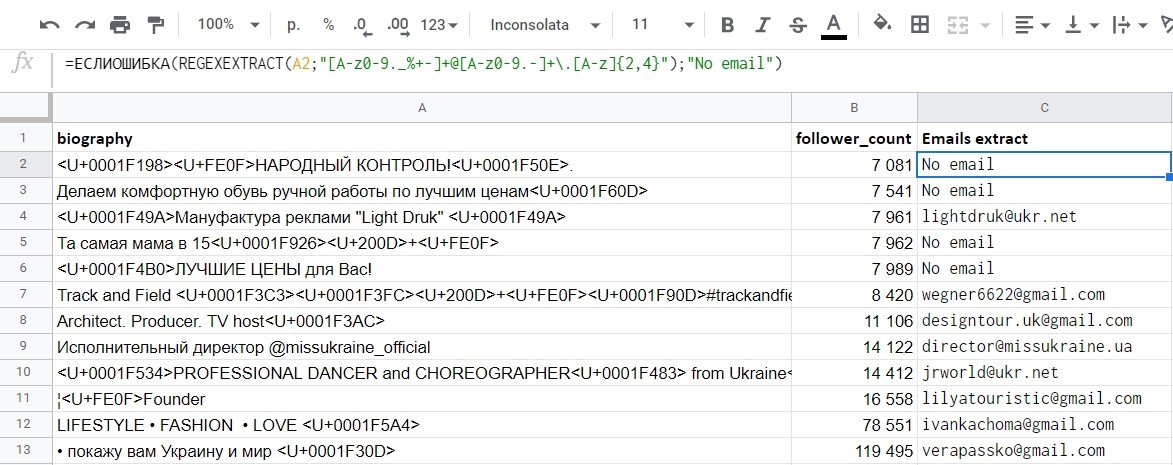
Готово! Наш список электронных почт готов. Остается только использовать его в правильных и непротивозаконных целях.
Извлекаем адреса электронных почт при помощи регулярных выражений в R
Здесь логика примерно такая же. Для извлечения текста из строки я буду использовать библиотеку "stringr", а для работы с CSV файлами "vroom". Устанавливаем библиотеки если еще нет и подключаем их
install.packages('stringr') # Установка
install.packages('vroom')
library('stringr') # Подключение
library('vroom')Загрузим CSV файл и преобразуем его в таблицу
our_table <- vroom("{PATH TO FOLDER}\\Filename.csv")Если же у вас много файлов, у которых одинаковая структура, и их надо собрать в одну большую таблицу, то это также можно автоматизировать через R
files <- dir(path = "{PATH TO FOLDER}", pattern = "\\.csv")
our_table <- vroom(files)Для удобства создадим переменную regex в которую запишем уже знакомое нам регулярное выражение. Обратите внимание что в R спецзнаки экранируются через двойной обратный слеш.
regex <-'[A-z0-9\\._%+-]+@[A-z0-9\\.-]+\\.[A-z]{2,4}'Пишем финальную формулу, в которой добавляем в существующую таблицу новый столбец для извлеченных имейлов
our_table$extract_emails <- str_extract(our_table$biography, regex)
Экспортируем получившийся результат в CSV файл
write.csv(our_table,"{PATH TO FOLDER}\\our_table.csv")Для удобства можно отфильтровать таблицу, оставив в ней только те строки, для которых есть извлеченные имейлы.
our_table_fin <- our_table %>%
filter(!is.na(our_table$extract_emails))Конечны скрипт выглядит как-то так
#Устанавливаем и подключаем библиотеки
install.packages('stringr')
install.packages('vroom')
library('stringr')
library('vroom')
#Грузим таблицу из CSV файла
our_table <- vroom("{PATH TO FOLDER}\\Filename.csv")
#Если файлов несколько то собираем их в одну таблицу
files <- dir(path = "{PATH TO FOLDER}", pattern = "\\.csv")
our_table <- vroom(files)
# Пишем регулярку в переменную
regex <-'[A-z0-9\\._%+-]+@[A-z0-9\\.-]+\\.[A-z]{2,4}'
#Добавляем новый столбец в таблицу и одновременно применяем функцию str_extract
#которая достанет нужный текст по паттерну регулярного выражения
our_table$extract_emails <- str_extract(our_table$biography, regex)
# Если нужно то фильтруем таблицу оставив в ней только строки с имейлами
our_table_fin <- our_table %>%
filter(!is.na(our_table$extract_emails))
#выгружаем результат в красивую CSVшку
write.csv(our_table_fin,"{PATH TO FOLDER}\\our_table.csv")Вот и все. Теперь вы умеете извлекать имейлы из текста при помощи гугл таблиц, R и регулярных выражений.