Тестирование бэка: Swagger. Postman
Что такое Swagger?
Postman: посмотреть, как отправлять запросы, настраивать url, метод, заголовки и тело запроса.
Виды авторизации: API токен, Bearer token, basic auth
Вкладка Tests/Scripts в Postman: как добавить в запрос дополнительную проверку на код ответа, на время ожидания ответа.
Переменные в Postman: как добавить переменную окружения и использовать в запросе.
Как в целом можно тестировать бэк: статья от Ольги Назиной.
Чек-лист из этой статьи перенеси себе в шпаргалку и желательно запомнить несколько пунктов оттуда
Тестовый API https://petstore.swagger.io/
Создать коллекцию запросов в Postman, в которой ты сначала создаешь питомца, потом проверяешь его успешное создание GET-запросом, потом изменяешь его, опять проверяешь изменение гетом, потом удаляешь и проверяешь, что он удалился.
То есть итоговая коллекция должна содержать 6 запросов.
Добавь в каждый запрос любой дополнительный тест во вкладке Tests/Scripts или сгенерируй тесты автоматически через функцию "Generate tests" в меню коллекции.
Получившуюся коллекцию экспортируй в JSON-файл и прикрепи в эту таску
UPD: Перед экспортом коллекции нужно жмякнуть кнопку "SAVE" во всех запросах по отдельности, иначе есть риск, что они экспортируются не доделанные
UPD2: Перед экспортом коллекции запусти полностью всю коллекцию по нажатию кнопки "Run collection". Все запросы должны возвращать код 200 кроме последнего GET-запроса (он должен возвращать 404). Если у тебя получились другие коды ответа, то это значит, что где-то ошибка
Слово «API» мелькает в вакансиях даже для начинающих тестировщиков. То REST API, то SOAP API, то просто API. Что же это за зверь такой? Давайте разбираться!
— А зачем это мне? Я вообще-то web тестирую! Вот если пойду в автоматизацию, тогда да… Ну, еще это в enterprise тестируют, я слышал…
А вот и нет! Про API полезно знать любому тестировщику. Потому что по нему системы взаимодействуют между собой. И это взаимодействие вы видите каждый день даже на самых простых и захудалых сайтах.
Любая оплата идет через API платежной системы. Купил билет в кино? Маечку в онлайн-магазине? Книжку? Как только жмешь «оплатить», сайт соединяет тебя с платежной системой.
Но даже если у вас нет интеграции с другими системами, у вас всё равно есть API! Потому что система внутри себя тоже общается по api. И пока фронт-разработчик усиленно пилит GUI (графический интерфейс), вы можете:
Конечно, я за второй вариант! Так что давайте разбираться, что же такое API. Можно посмотреть видео на youtube, или прочитать дальше в виде статьи.
Что такое API

API (Application programming interface) — это контракт, который предоставляет программа. «Ко мне можно обращаться так и так, я обязуюсь делать то и это».
Если переводить на русский, это было бы слово «договор». Договор между двумя сторонами, как договор на покупку машины:
Перевести можно, да. Но никто так не делает ¯\_(ツ)_/¯
Все используют слово «контракт». Так принято. К тому же это слово входит в название стиля разработки:
- Code first — сначала пишем код, потом по нему генерируем контракт
- Contract first — сначала создаем контракт, потом по нему пишем или генерируем код (в этой статье я буду говорить именно об этом стиле)
Мы же не говорим «контракт на продажу машины»? Вот и разработчики не говорят «договор». Негласное соглашение.
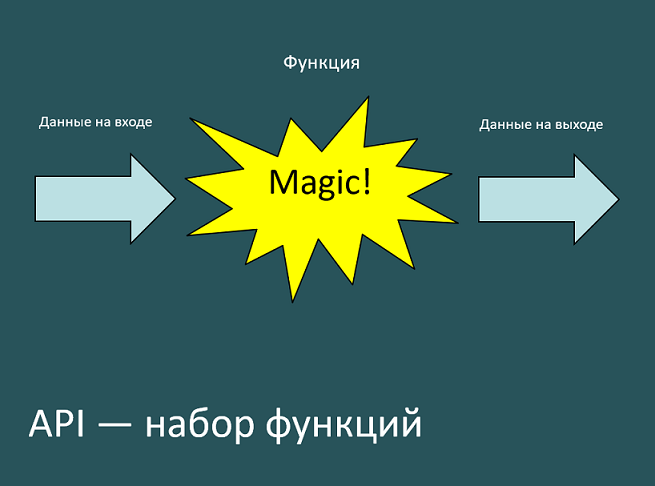
API — набор функций
Когда вы покупаете машину, вы составляете договор, в котором прописываете все важные для вас пункты. Точно также и между программами должны составляться договоры. Они указывают, как к той или иной программе можно обращаться.
Соответственно, API отвечает на вопрос “Как ко мне, к моей системе можно обратиться?”, и включает в себя:
- саму операцию, которую мы можем выполнить,
- данные, которые поступают на вход,
- данные, которые оказываются на выходе (контент данных или сообщение об ошибке).

— Хмм, погоди. Операция, данные на входе, данные на выходе — как-то всё это очень сильно похоже на описание функции!
Если вы когда-то сталкивались с разработкой или просто изучали язык программирования, вы наверняка знаете, что такое функция. Фактически у нас есть данные на входе, есть данные на выходе, и некая магия, которая преобразует одно в другое.
И да! Вы будете правы в том, что определения похожи. Почему? Да потому что API — это набор функций. Это может быть одна функция, а может быть много.
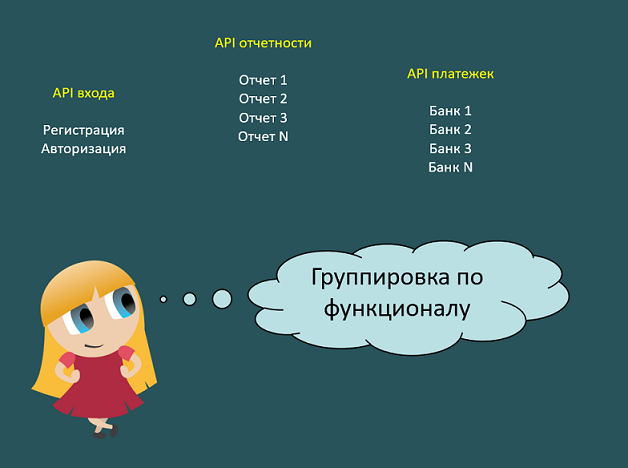
Как составляется набор функций
Да без разницы как. Как разработчик захочет, так и сгруппирует. Например, можно группировать API по функционалу. То есть:
- отдельно API для входа в систему, где будет регистрация и авторизация;
- отдельно API для отчетности — отчет 1, отчет 2, отчет 3… отчет N. Для разных отчетов у нас разные формулы = разные функции. И все мы их собираем в один набор, api для отчетности.
- отдельно API платежек — для работы с каждым банком своя функция.
- ...
Можно не группировать вообще, а делать одно общее API.
Можно сделать одно общее API, а остальные «под заказ». Если у вас коробочный продукт, то в него обычно входит набор стандартных функций. А любые хотелки заказчиков выносятся отдельно.

Получается, что в нашей системе есть несколько разных API, на каждое из которых у нас написан контракт. В каждом контракте четко прописано, какие операции можно выполнять, какие функции там будут

И конечно, функции можно переиспользовать. То есть одну и ту же функцию можно включать в разные наборы, в разные апи. Никто этого не запрещает.

Получается, что разработчик придумывает, какое у него будет API. Либо делает общее, либо распределяет по функционалу или каким-то своим критериям, и в каждое апи добавляет тот набор функций, который ему необходим.
При чем тут слово «интерфейс»
— Минуточку, Оля! Ты же сама выше писала, что API — это Application programming interface. Почему ты тогда говоришь о контракте, хотя там слово интерфейс?
Да потому, что в программировании контракт — это и есть интерфейс. В классическом описании ООП (объектно-ориентированного программирования) есть 3 кита:
Инкапсуляция — это когда мы скрываем реализацию. Для пользователя все легко и понятно. Нажал на кнопочку — получил отчет. А как это работает изнутри — ему все равно. Какая база данных скрыта под капотом? Oracle? MySQL? На каком языке программирования написана программа? Как именно организован код? Не суть. Программа предоставляет интерфейс, им он и пользуется.
Не всегда программа предоставляет именно графический интерфейс. Это может быть SOAP, REST интерфейс, или другое API. Чтобы использовать этот интерфейс, вы должны понимать:
Пользователи работают с GUI — graphical user interface. Программы работают с API — Application programming interface. Им не нужна графика, только контракт.
Как вызывается API
Вызвать апи можно как напрямую, так и косвенно.
- Система вызывает функции внутри себя
- Система вызывает метод другой системы
- Человек вызывает метод
- Автотесты дергают методы
Вызов API напрямую
1. Система вызывает функции внутри себя
Разные части программы как-то общаются между собой. Они делают это на программном уровне, то есть на уровне API!
Это самый «простой» в использовании способ, потому что автор API, которое вызывается — разработчик. И он же его потребитель! А значит, проблемы с неактуальной документацией нет =)
Шучу, проблемы с документацией есть всегда. Просто в этом случае в качестве документации будут комментарии в коде. А они, увы, тоже бывают неактуальны. Или разработчики разные, или один, но уже забыл, как делал исходное api и как оно должно работать…
2. Система вызывает метод другой системы
А вот это типичный кейс, которые тестируют тестировщики в интеграторах. Или тестировщики, которые проверяют интеграцию своей системы с чужой.
Одна система дергает через api какой-то метод другой системы. Она может попытаться получить данные из другой системы. Или наоборот, отправить данные в эту систему.
Допустим, я решила подключить подсказки из Дадаты к своему интернет-магазинчику, чтобы пользователь легко ввел адрес доставки.
Я подключаю подсказки по API. И теперь, когда пользователь начинает вводить адрес на моем сайте, он видит подсказки из Дадаты. Как это получается:
Он вводит букву на моем сайтеМой сайт отправляет запрос в подсказки Дадаты по APIДадата возвращает ответМой сайт его обрабатывает и отображает результат пользователю
Вон сколько шагов получилось! И так на каждый введенный символ. Пользователь не видит этого взаимодействия, но оно есть.
И, конечно, не забываем про кейс, когда мы разрабатываем именно API-метод. Который только через SOAP и можно вызвать, в интерфейсе его нигде нет. Что Заказчик заказал, то мы и сделали ¯\_(ツ)_/¯
Пример можно посмотреть в Users. Метод MagicSearch создан на основе реальных событий. Хотя надо признать, в оригинале логика еще замудренее была, я то под свой сайт подстраивала.
Но тут фишка в том, что в самой системе в пользовательском интерфейсе есть только обычный поиск, просто строка ввода. Ну, может, парочка фильтров. А вот для интеграции нужна была целая куча доп возможностей, что и было сделано через SOAP-метод.
Функционал супер-поиска доступен только по API, пользователь в интерфейсе его никак не пощупает.
В этом случае у вас обычно есть ТЗ, согласно которому работает API-метод. Ваша задача — проверить его. Типичная задача тестировщика, просто добавьте к стандартным тестам на тест-дизайн особенности тестирования API, и дело в шляпе!
(что именно надо тестировать в API — я расскажу отдельной статьей чуть позднее)
3. Человек вызывает метод
- Для ускорения работы
- Для локализации бага (проблема где? На сервере или клиенте?)
- Для проверки логики без докруток фронта
Если система предоставляет API, обычно проще дернуть его, чем делать то же самое через графический интерфейс. Тем более что вызов API можно сохранить в инструменте. Один раз сохранил — на любой базе применяешь, пусть даже она по 10 раз в день чистится.
Для примера снова идем в Users. Если мы хотим создать пользователя, надо заполнить уйму полей!
Конечно, это можно сделать с помощью специальных плагинов типа Form Filler. Но что, если вам нужны адекватные тестовые данные под вашу систему? И на русском языке?
Заполнение полей вручную — грустно и уныло! А уж если это надо повторять каждую неделю или день на чистой тестовой базе — вообще кошмар. Это сразу первый приоритет на автоматизацию рутинных действий.
И в данном случае роль автоматизатора выполняет… Postman. Пользователя можно создать через REST-запрос CreateUser. Один раз прописали нормальные “как настоящие” данные, каждый раз пользуемся. Профит!
Вместо ручного заполнения формы (1 минута бездумного заполнения полей значениями «лпрулпк») получаем 1 секунду нажатия на кнопку «Send». При этом значения будут намного адекватнее.
А еще в постмане можно сделать отдельную папку подготовки тестовой базы, напихать туда десяток запросов. И вот уже на любой базе за пару секунд вы получаете столько данных, сколько вручную вбивали бы часами!
Если вы нашли баг и не понимаете, на кого его вешать — разработчика front-end или back-end, уберите все лишнее. Вызовите метод без графического интерфейса. А еще вы можете тестировать логику программы, пока интерфейс не готов или сломан.
4. Автотесты дергают методы
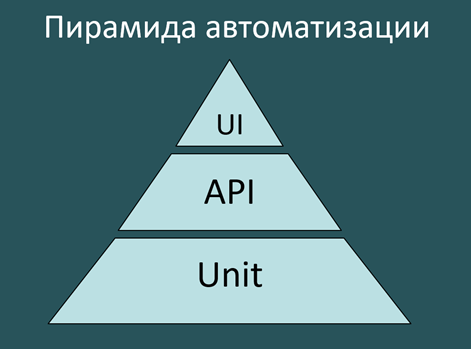
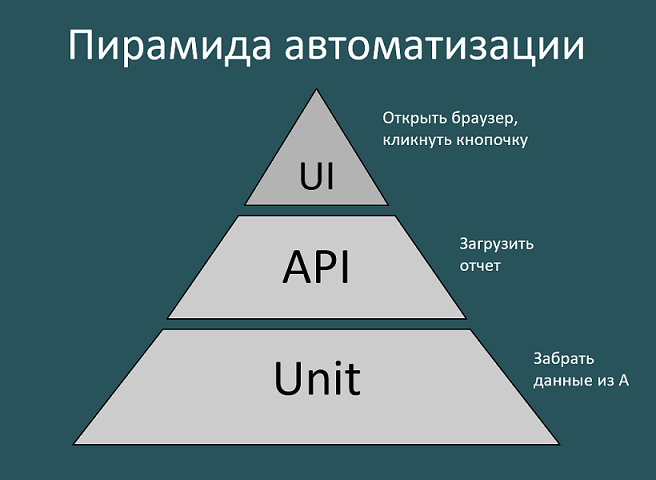
Есть типичная пирамида автоматизации:
- GUI-тесты — честный тест, «как это делал бы пользователь».
- API-тесты — опускаемся на уровень ниже, выкидывая лишнее.
- Unit-тесты — тесты на отдельную функцию
Слово API как бы намекает на то, что будет использовано в тестах ツ
Допустим, у нас есть:
операция: загрузка отчета; на входе: данные из ручных или автоматических корректировок или из каких-то других мест; на выходе: отчет, построенный по неким правилам
Правила построения отчета:
Ячейка 1: Х — YЯчейка 2: Z * 6...
GUI-тесты — честный тест, робот делает все, что делал бы пользователь. Открывает браузер, тыкает на кнопочки… Но если что-то упадет, будете долго разбираться, где именно.
API-тесты — все то же самое, только без браузера. Мы просто подаем данные на вход и проверяем данные на выходе. Например, можно внести итоговый ответ в эксельку, и пусть робот выверяет ее, правильно ли заполняются данные? Локализовать проблему становится проще.
Unit-тесты — это когда мы проверяем каждую функцию отдельно. Отдельно смотрим расчет для ячейки 1, отдельно — для ячейки 2, и так далее. Такие тесты шустрее всего гоняются и баги по ним легко локализовать.
Косвенный вызов API
Когда пользователь работает с GUI, на самом деле он тоже работает с API. Просто не знает об этом, ему это просто не нужно.
То есть когда пользователь открывает систему и пытается загрузить отчет, ему не важно, как работает система, какой там magic внутри. У него есть кнопочка «загрузить отчет», на которую он и нажимает. Пользователь работает через GUI (графический пользовательский интерфейс).
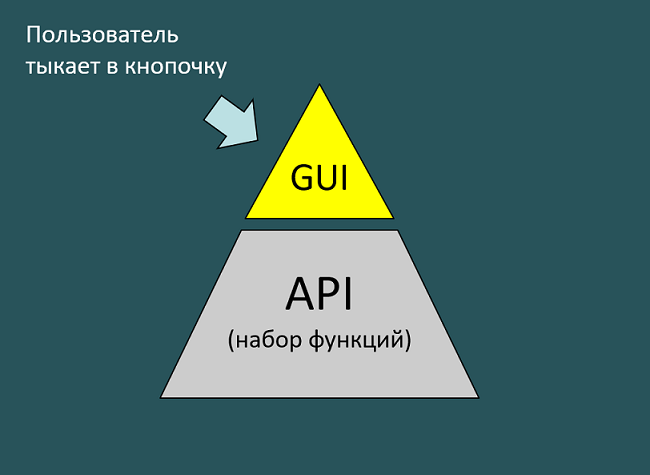
Но на самом деле под этим графическим пользовательским интерфейсом находится API. И когда пользователь нажимает на кнопочку, кнопочка вызывает функцию построения отчета.
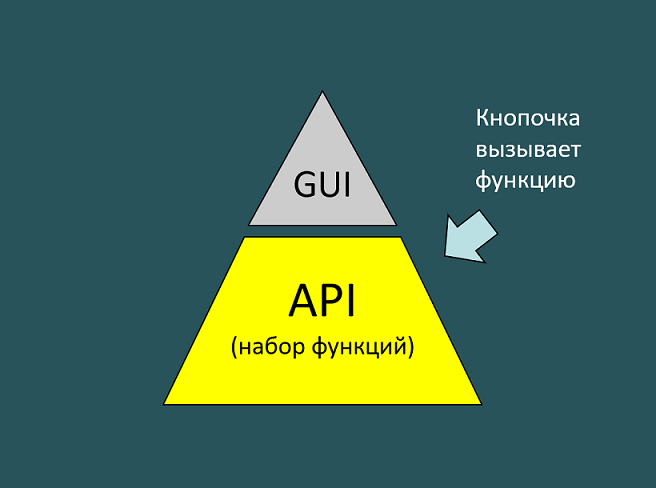
А функция построения отчета уже может вызывать 10 разных других функций, если ей это необходимо.
И вот уже пользователь видит перед собой готовый отчет. Он вызвал сложное API, даже не подозревая об этом!
Что значит «Тестирование API»
В первую очередь, мы подразумеваем тестирование ЧЕРЕЗ API. «Тестирование API» — общеупотребимый термин, так действительно говорят, но технически термин некорректен. Мы не тестируем API, мы не тестируем GUI (графический интерфейс). Мы тестируем какую-то функциональность через графический или программный интерфейс.
Но это устоявшееся выражение. Можно использовать его и говорить “тестирование API”. И когда мы про это говорим, мы имеем в виду:
Интеграция — когда одна система общается с другой по какому-то протоколу передачи данных. Это называется Remote API, то есть общение по сети, по некоему протоколу (HTTP, JMS и т.д.). В противовес ему есть еще Local API (он же «Shared memory API») — это то API, по которому программа общается сама с собой или общается с другой программой внутри одной виртуальной памяти.

Когда мы говорим про тестирование API, чаще всего мы подразумеваем тестирование Remote API. Когда у нас есть две системы, находящихся на разных компьютерах, которые как-то между собой общаются.
И если вы видите в вакансии «тестирование API», скорее всего это подразумевает умение вызвать SOAP или REST сервис и протестировать его. Хотя всегда стоит уточнить!
Резюме
API (Application programming interface) — это контракт, который предоставляет программа. «Ко мне можно обращаться так и так, я обязуюсь делать то и это».
- саму операцию, которую мы можем выполнить,
- данные, которые поступают на вход,
- данные, которые оказываются на выходе (контент данных или сообщение об ошибке).
Вызвать API можно как напрямую, так и косвенно:
- Система вызывает функции внутри себя
- Система вызывает метод другой системы
- Человек вызывает метод
- Автотесты дергают методы
- Пользователь работает с GUI
Когда говорят про API с тестировщиком, обсуждают два варианта:
- автотесты на уровне API (умение автоматизировать)
- интеграцию между двумя разными системами (обычно SOAP или REST, то есть работу в SOAP Ui или Postman).
Тестируем с помощью Swagger
API (Application Programming Interface) — это набор процедур, протоколов и инструментов, позволяющих разным программным приложениям общаться между собой. API дает возможность осуществлять взаимодействие с различными сервисами и приложениями, используя специальные запросы и ответы.
Наиболее популярные и эффективные инструменты для тестирования API:
- Postman — это инструмент для тестирования API, позволяющий создавать, отправлять и тестировать HTTP-запросы и проверять ответы на них.
- Swagger — это инструмент для документирования и тестирования API, позволяющий автоматически создавать документацию API из описания структуры API в формате YAML или JSON файла.
- SoapUI — это инструмент для тестирования веб-сервисов, позволяющий создавать и выполнять тесты на протоколе SOAP.
- Fiddler — это инструмент для анализа и отладки HTTP-трафика между веб-браузером и веб-сервером. С точки зрения тестирования API Fiddler позволяет перехватывать, анализировать и модифицировать HTTP-запросы и ответы, передаваемые между клиентом и сервером. Это позволяет тестировщикам осуществлять валидацию запросов и ответов, проверять правильность передачи параметров, куки и другие элементы запросов, отслеживать проблемы с трафиком, а также выявлять и локализовать проблемы с API.
- JMeter — это инструмент для тестирования производительности и функциональности программного обеспечения, который может использоваться для тестирования API. С точки зрения тестирования API, JMeter является инструментом, позволяющим создавать запросы к API, анализировать ответы и оценивать производительность и функциональность API. JMeter может использоваться для создания нагрузки на API, чтобы измерить производительность, время ответа и другие метрики, которые помогут обнаружить ошибки в API и улучшить его производительность и функциональность.
Вышеперечисленные инструменты позволяют тестировщикам эффективно и быстро проверять API на разных этапах разработки, чтобы обеспечить его соответствие требованиям и качеству.
В данной публикации рассмотрим подробнее Swagger, позволяющий создавать, документировать и тестировать API. С помощью Swagger можно узнать доступные эндпоинты, параметры запросов и формат ответов.
О Swagger
Swagger разработан компанией Reverb Technologies, основанной в 2010 году в Миннеаполисе, США. Основателями компании были Тони Тамбурино (Tony Tambourine), Райан Дювелл (Ryan Duell) и Ник Селлер (Nick Sutterer).
Swagger создан в целях облегчения работы разработчиков API и обеспечения большего взаимодействия между разработчиками и потребителями API. В 2015 году Swagger был перенесен в сообщество OpenAPI Initiative, которое является частью Linux Foundation, где его разработка и поддержка продолжаются по сей день.
Преимущества и особенности Swagger:
- Легкость использования: Swagger имеет простой и легкий интерфейс, позволяющий разработчикам быстро и легко создавать и документировать API.
- Автоматическое поколение документации: Swagger позволяет автоматически создавать документацию для API с использованием стандарта OpenAPI. Это позволяет потребителям API быстро и легко понять, как взаимодействовать с API и использовать его функциональность.
- Поддержка различных языков программирования: Swagger поддерживает многие языки программирования, что позволяет разработчикам использовать его для документирования API на любом языке программирования.
- Поддержка открытых стандартов: Swagger основан на стандартах OpenAPI, которые поддерживаются большим количеством инструментов и платформ, что позволяет разработчикам использовать его с любым другим инструментом или платформой, поддерживающими стандарты OpenAPI.
- Тестирование и валидация API: Swagger позволяет разработчикам тестировать и валидировать API, обеспечивая большую надежность и качество работы API.
- Расширяемость Swagger имеет открытый код и активное сообщество разработчиков, что позволяет им расширять и настраивать его под свои нужды.
Для каждого из методов HTTP Swagger позволяет описать параметры запросов и формат ответов.
Например, для метода GET можно описать параметры запросов, такие как query string parameters, headers, или path parameters, и формат ответа, такой как JSON или XML. Аналогично Swagger позволяет описывать параметры и формат ответов для методов POST, PUT и DELETE. Это обеспечивает понятность и консистентность описания API и позволяет разработчикам эффективно использовать API в своих приложениях.
Примеры описания параметров запросов и формат ответов можно найти здесь.

рПримеры методов
POST метод (создание объекта):

Результат после отправки запроса:

GET метод (получение данных):

PUT метод (редактирование данных):

Результат после отправки запроса:

Метод DELETE (удаление объекта):

Swagger является важным инструментом для тестировщиков, так как позволяет генерировать документацию для API и исследовать его функционал, что помогает увеличивать производительность тестирования API и эффективнее взаимодействовать с командой разработчиков во время процесса разработки и тестирования API.
Полезные материалы:
- Официальная документация Swagger: на сайте Swagger есть подробная документация с описанием различных функций и возможностей.
- Swagger Editor: это бесплатный онлайн-редактор Swagger, позволяющий создавать, редактировать и проверять файл Swagger в режиме реального времени.
- SwaggerHub: это интерактивная среда Swagger, которая позволяет создавать, документировать и публиковать свои API, а также общаться с другими разработчиками API.
- Swagger UI: это интерактивный пользовательский интерфейс, который позволяет тестировать API непосредственно из браузера. Вы можете выполнять запросы API и просматривать ответы в разных форматах.
- Swagger Codegen: это инструмент, позволяющий сгенерировать клиентский код для вашего API на основе файла Swagger. Вы можете выбрать язык программирования и тип клиента для создания кода, который соответствует вашим потребностям.

“Разработка API сложна, Postman делает её лёгкой” © Postdot Technologies, Inc
Когда видишь описание инструментов Postman — захватывает дух, просыпается чувство всевластия над своим будущим детищем. Кажется, что и взрощенные в прошлом "монстры" наконец-то падут перед тобой!
В этой статье мы расскажем о Postman и попробуем написать свой первый скрипт.
Postman
Основное предназначение приложения — создание коллекций с запросами к вашему API. Любой разработчик или тестировщик, открыв коллекцию, сможет с лёгкостью разобраться в работе вашего сервиса. Ко всему прочему, Postman позволяет проектировать дизайн API и создавать на его основе Mock-сервер. Вашим разработчикам больше нет необходимости тратить время на создание "заглушек". Реализацию сервера и клиента можно запустить одновременно. Тестировщики могут писать тесты и производить автоматизированное тестирование прямо из Postman. А инструменты для автоматического документирования по описаниям из ваших коллекций сэкономят время на ещё одну "полезную фичу". Есть кое-что и для администраторов — авторы предусмотрели возможность создания коллекций для мониторинга сервисов.
Введение
1 — коллекция, 2 — папка, 3 — запрос
Главные понятия, которыми оперирует Postman это Collection (коллекция) на верхнем уровне, и Request (запрос) на нижнем. Вся работа начинается с коллекции и сводится к описанию вашего API с помощью запросов. Давайте рассмотрим подробнее всё по порядку.
Collection
Коллекция — отправная точка для нового API. Можно рассматривать коллекцию, как файл проекта. Коллекция объединяет в себе все связанные запросы. Обычно API описывается в одной коллекции, но если вы желаете, то нет никаких ограничений сделать по-другому. Коллекция может иметь свои скрипты и переменные, которые мы рассмотрим позже.
Folder
Папка — используется для объединения запросов в одну группу внутри коллекции. К примеру, вы можете создать папку для первой версии своего API — "v1", а внутри сгруппировать запросы по смыслу выполняемых действий — "Order & Checkout", "User profile" и т. п. Всё ограничивается лишь вашей фантазией и потребностями. Папка, как и коллекция может иметь свои скрипты, но не переменные.
Request
Запрос — основная составляющая коллекции, то ради чего все и затевалось. Запрос создается в конструкторе. Конструктор запросов это главное пространство, с которым вам придётся работать. Postman умеет выполнять запросы с помощью всех стандартных HTTP методов, все параметры запроса под вашим контролем. Вы с лёгкостью можете поменять или добавить необходимые вам заголовки, cookie, и тело запроса. У запроса есть свои скрипты. Обратите внимание на вкладки "Pre-request Script" и "Tests" среди параметров запроса. Они позволяют добавить скрипты перед выполнением запроса и после. Именно эти две возможности делают Postman мощным инструментом помогающим при разработке и тестировании.
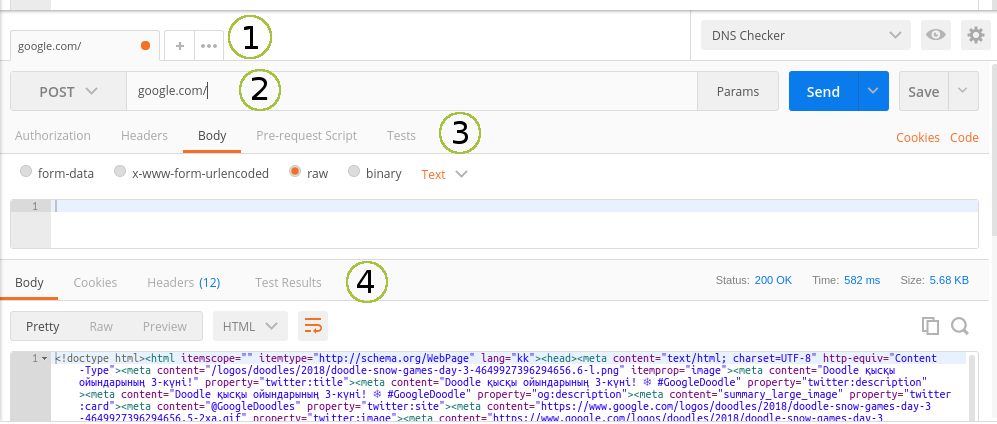
1 — вкладки с запросами, 2 — URL и метод, 3 — параметры запроса, 4 — параметры ответа
Скрипты
"Postman Sandbox" это среда исполнения JavaScript доступная при написании "Pre-request Script" и "Tests" скриптов. "Pre-request Script" используется для проведения необходимых операций перед запросом, например, можно сделать запрос к другой системе и использовать результат его выполнения в основном запросе. "Tests" используется для написания тестов, проверки результатов, и при необходимости их сохранения в переменные.
Последовательность выполнения запроса (из оф. документации)
Помимо скриптов на уровне запроса, мы можем создавать скрипты на уровне папки, и, даже, на уровне коллекции. Они называются также — "Pre-request Script" и "Tests", но их отличие в том, что они будут выполняться перед каждым и после каждого запроса в папке, или, как вы могли догадаться, во всей коллекции.
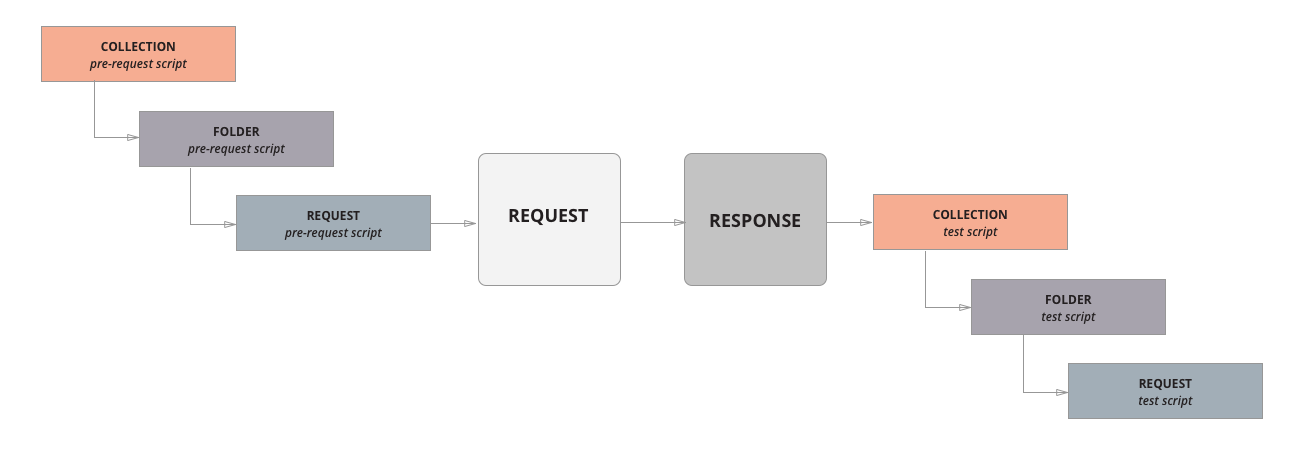
Последовательность выполнения запроса со скриптами папок и коллекций (из оф. документации)
Переменные
Postman имеет несколько пространств и областей видимости для переменных:
- Глобальные переменные
- Переменные коллекции
- Переменные окружения
- Локальные переменные
- Переменные уровня данных
Глобальные переменные и переменные окружения можно создать, если нажать на шестеренку в правом верхнем углу программы. Они существуют отдельно от коллекций. Переменные уровня коллекции создаются непосредственно при редактировании параметров коллекции, а локальные переменные из выполняемых скриптов. Также существуют переменные уровня данных, но они доступны только из Runner, о котором мы поговорим позже.
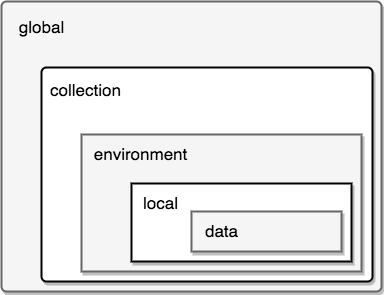
Приоритет пространств переменных (из оф. документации)
Особенностью переменных в Postman является то, что вы можете вставлять их в конструкторе запроса, в URL, в POST параметры, в Cookie, всюду, используя фигурные скобки в качестве плейсхолдера для подстановки.
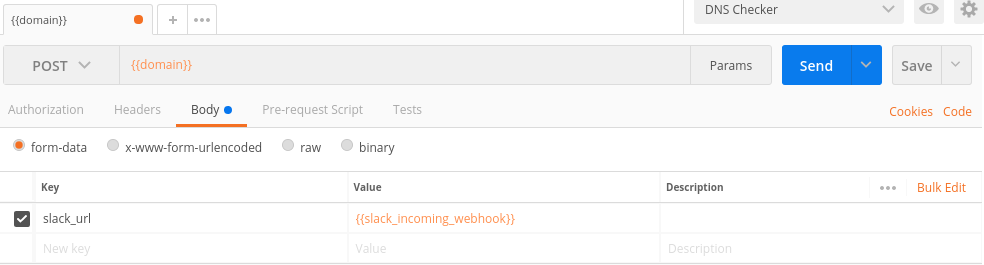
{{domain}} и {{slack_incoming_webhook}} — переменные окружения DNS Checker будут заменены на значения во время выполнения запроса
Из скриптов переменные тоже доступны, но получить их поможет вызов стандартного метода встроенной библиотеки pm:
// получить глобальную переменнуюpm.globals.get("variable_key");// получить переменную из окруженияpm.environment.get("variable_key");// получить переменную из любого пространства согласно приоритетуpm.variables.get("variable_key");Collection Runner
Предназначен для тестирования и выполнения всех запросов из коллекции или папки, на ваш выбор. При запуске можно указать количество итераций, сколько раз будет запущена папка или коллекция, окружение, а также дополнительный файл с переменными. Стоит упомянуть, что запросы выполняются последовательно, согласно расположению в коллекции и папках. Порядок выполнения можно изменить используя встроенную команду:
// Следующим выполнится запрос с названием "Create order",postman.setNextRequest('Create order');После выполнения всех запросов формируется отчет, который покажет количество успешных и провальных проверок из скриптов "Tests".
Console
Пользуйтесь консолью для отладки ваших скриптов, и просмотра дополнительной информации по запросам. Консоль работает, как во время запуска одного запроса, так и во время запуска пакета запросов через Runner. Чтобы её открыть, найдите иконку консоли в нижнем левом углу основного экрана приложения:

Практика
Так как создание коллекций и запросов в конструкторе не должно вызвать затруднений, практическую часть посвятим написанию скриптов, и рассмотрим как создать цепочку запросов с тестами. Перед началом создайте новую коллекцию, назовите её “Habra”, затем создайте новое окружение под названием "Habra.Env"
Шаг 1
Создайте новый запрос, в качестве URL укажите https://postman-echo.com/get?userId=777, а метод оставьте GET. Здесь и далее для простоты и удобства мы будем использовать echo-сервер любезно предоставленный разработчиками Postman. Сохраните запрос в коллекцию "Habra" и назовите “Get user id”, он будет имитировать получение идентификатора пользователя от сервера. Перейдите на вкладку "Tests" и напишите следующий код:
// Тестируем статус ответа и форматpm.test("Status is ok, response is json", function () { pm.response.to.be.ok; // проверка статуса pm.response.to.be.json; // проверка формата});try { // сохраняем userId из json ответа в переменную окружения pm.environment.set("userId", pm.response.json().args.userId);} catch(e) { // выводим исключение в консоль console.log(e);}С помощью этого скрипта мы проверили статус и формат ответа, а также сохранили полученный из ответа идентификатор пользователя в переменную окружения для последующего использования в других запросах. Чтобы проверить работу нашего теста, запустите запрос. В панели информации об ответе, во вкладке "Tests" вы должны увидеть зелёный лейбл “PASS”, а рядом надпись “Status is ok, response is json”.
Шаг 2
Теперь давайте попробуем вставить идентификатор нашего пользователя в json запрос. Создайте новый запрос, в качестве URL укажите https://postman-echo.com/post, выберите метод POST, установите тип для тела запроса raw — application/json, а в само тело вставьте:
{"userId": {{userId}}, "username": "Bob"}Сохраните запрос в нашу коллекцию, и назовите "Update username", он будет запрашивать импровизированную конечную точку для обновления username пользователя. Теперь при вызове запроса вместо {{userId}} система автоматически будет подставлять значение из переменной окружения. Давайте проверим, что это действительно так, и напишем небольшой тест для нашего нового запроса:
// тестируем статус ответа и форматpm.test("Status is ok, response is json", function () { pm.response.to.be.ok; pm.response.to.be.json;});// проверим, что userId из окружения равен userId из ответаpm.test("userId from env is equal to userId from response", function () { pm.expect(parseInt(pm.environment.get("userId"))).to.equal( pm.response.json().data.userId );});В нашем новом тесте мы сравниваем полученный от сервера userId с тем, что хранится у нас в переменной окружения, они должны совпадать. Запустите запрос и убедитесь, что тесты прошли. Хорошо, двигаемся дальше.
Шаг 3
Вы могли заметить, что два тестовых скрипта имеют одинаковую проверку формата и статуса:
pm.test("Status is ok, response is json", function () { pm.response.to.be.ok; pm.response.to.be.json;});Пока мы не зашли слишком далеко, давайте исправим эту ситуацию и перенесем эти тесты на уровень коллекции. Откройте редактирование нашей коллекции, и перенесите проверку формата и статуса во вкладку "Tests", а из запросов их можно удалить. Теперь эти проверки будут автоматически вызываться перед скриптами "Tests" для каждого запроса в коллекции. Таким образом мы избавились от копирования данной проверки в каждый запрос.
Шаг 4
Мы научились записывать и получать переменные окружения, настало время перейти к чему-то потяжелее. Давайте воспользуемся встроенной библиотекой tv4 (TinyValidator) и попробуем проверить правильность схемы json объекта. Создайте новый запрос, в качестве URL используйте https://postman-echo.com/post, установите метод в значение POST, для тела запроса укажите raw — application/json, и вставьте в него:
{ "profile" : { "userId": {{userId}}, "username": "Bob", "scores": [1, 2, 3, 4, 5], "age": 21, "rating": {"min": 20, "max": 100} }}После запуска запроса echo-сервер должен вернуть нам нашу json модель в качестве ответа в поле "data", таким образом мы имитируем работу реального сервера, который мог бы прислать нам информацию о профиле Боба. Модель готова, напишем тест, проверяющий правильность схемы:
// получаем профиль из ответаvar profile = pm.response.json().data.profile;// описываем схему моделиvar scheme = { // указываем тип объекта "type": "object", // указываем обязательные свойства "required": ["userId", "username"], // описываем свойства "properties": { "userId": {"type": "integer"}, "username": {"type": "string"}, "age": {"type": "integer"}, // описываем массив "scores": { "type": "array", // тип элементов "items": {"type": "integer"} }, // описываем вложенный объект "rating": { "type": "object", "properties": { "min": {"type": "integer"}, "max": {"type": "integer"} } } }};pm.test('Schema is valid', function() { // валидируем объект profile с помощью правил из scheme var isValidScheme = tv4.validate(profile, scheme, true, true); // ожидаем, что результат валидации true pm.expect(isValidScheme).to.be.true;});Готово, мы провалидировали схему объекта profile. Запустите запрос и убедитесь, что тесты проходят.
Шаг 5
У нас получился небольшой путь из 3-х запросов и нескольких тестов. Настало время полностью его протестировать. Но перед этим, давайте внесем небольшую модификацию в наш первый запрос: замените значение “777” в URL на плейсхолдер “{{newUserId}}”, и через интерфейс добавьте в окружение "Habra.Env" переменную “newUserId” со значением “777”. Создайте файл users.json на своём компьютере и поместите туда следующий json массив:
[ {"newUserId": 100}, {"newUserId": 200}, {"newUserId": 300}, {"newUserId": 50000}]Теперь запустим Runner. В качестве "Collection Folder" выберем "Habra". В качестве "Environment" поставим "Habra.Env". Количество итераций оставляем 0, а в поле "Data" выбираем наш файл users.json. По этому файлу "Collection Runner" поймет, что ему нужно совершить 4 итерации, и в каждой итерации он заменит значение переменной "newUserId" значением из массива в файле. Если указать количество итераций больше, чем количество элементов в массиве, то все последующие итерации будут происходить с последним значением из массива данных. В нашем случае после 4 итерации значение "newUserId" всегда будет равно 50000. Наш “Data” файл поможет пройти весь наш путь с разными newUserId, и убедиться, что независимо от пользователя все выполняется стабильно.
Запускаем наши тесты нажатием "Run Habra". Поздравляем вы успешно создали коллекцию и протестировали наш импровизированный путь с помощью автотестов!
Тестирование коллекции "Habra"
Теперь вы знаете, как создавать скрипты и вполне можете написать парочку тестов для своего проекта.
Отдельно хочу отметить, что в реальном проекте мы не держим все запросы в корне коллекции, а стараемся раскладывать их по папкам. Например, в папке "Requests" мы складываем все возможные запросы описывающие наш API, а тесты храним в отдельной папке "Tests". И когда нам нужно протестировать проект, в "Runner" запускаем только папочку "Tests".
Полезно знать
В завершении приведем основные команды, которые вам могут понадобиться во время написания скриптов. Для лучшего усвоения, попробуйте поиграться с ними самостоятельно.
Установка и получение переменных
// глобальные переменныеpm.globals.set(“key”, “value”);pm.globals.get(“key”);// переменные окруженияpm.environment.set(“key”, “value”);pm.environment.get(“key”);// локальные переменныеpm.variables.set(“key”, “value”);pm.variables.get(“key”); // если нет локальной, будет искать на уровне выше
Тестирование или asserts
// с использованием анонимной функции и специальных assert конструкцийpm.test(“Название теста”, function () { pm.response.to.be.success; pm.expect(“value”).to.be.true; pm.expect(“other”).to.equal(“other”);});// с использованием простого условия и массива teststests[“Название теста”] = (“a” != “b”);tests[“Название теста 2”] = true;Создание запросов
// пример get запросаpm.sendRequest(“https://postman-echo.com/get”, function (err, res) { console.log(err); console.log(res);});// пример post запросаlet data = { url: “https://postman-echo.com/post”, method: “POST”, body: { mode: “raw”, raw: JSON.stringify({ key: “value” })}};pm.sendRequest(data, function (err, res) { console.log(err); console.log(res);});Получение ответа для основного запроса
pm.response.json(); // в виде jsonpm.response.text(); // в виде строкиresponseBody; // в виде строки
Ответ доступен только во вкладке “Tests”
Работа со встроенными библиотеками
Документация регламентирует наличие некоторого количества встроенных библиотек, среди которых — tv4 для валидации json, xml2js конвертер xml в json, crypto-js для работы с шифрованием, atob, btoa и др.
// подключение xml2jsvar xml2js = require(“xml2js”);// преобразование простого xml в json объектxml2js.parseString("<root>Hello xml2js!</root>", function(err, res) { console.log(res);});Некоторые из библиотек, например, как tv4 не требуют прямого подключения через require и доступны по имени сразу.
Получение информации о текущем скрипте
pm.info.eventName; // вернет test или prerequest в зависимости от контекстаpm.info.iteration; // текущая итерация в Runnerpm.info.iterationCount; // общее количество итерацийpm.info.requestName; // название текущего запросаpm.info.requestId; // внутренний идентификатор запроса
Управление последовательностью запросов из скрипта
Стоит отметить, что данный метод работает только в режиме запуска всех скриптов.
// установить следующий запросpostman.setNextRequest(“Название запроса”); // по названиюpostman.setNextRequest(ID); // по идентификатору// остановить выполнение запросовpostman.setNextRequest(null);
После перехода на следующий запрос Postman возвращается к линейному последовательному выполнению запросов.
Создание глобального хелпера
В некоторых случаях вам захочется создать функции, которые должны быть доступны во всех запросах. Для этого в первом запросе в секции “Pre-request Script” напишите следующий код:
// создаем и сохраняем хелпер для глобального использованияpm.environment.set("pmHelper", function pmHelper() { let helpers = {}; helpers.usefulMethod = function() { console.log(“It is helper, bro!”); }; return helpers;} + '; pmHelper();');А в последующих скриптах пользуемся им так:
// получаем объектvar pmHelper = eval(pm.environment.get("pmHelper"));// вызываем наш методpmHelper.usefulMethod();Это лишь небольшой список полезных команд. Возможности скриптов гораздо шире, чем можно осветить в одной статье. В Postman есть хорошие "Templates", которые можно найти при создании новой коллекции. Не стесняйтесь подглядывать и изучать их реализацию. А официальная документация содержит ответы на большинство вопросов.
Заключение
Основные плюсы, которые подтолкнули нас к использованию Postman в своём проекте:
- Наглядность – все запросы всегда под рукой, мануальное тестирование во время разработки становится легче
- Быстрый старт – вовлечение нового игрока в команду, будь то программист или тестировщик, проходит легко и быстро
- Тесты – возможность писать тесты для запросов, а потом быстро составлять из них, как из пазлов, различные варианты и пути жизни приложения
- Поддержка CI — возможность интегрировать тесты в CI с помощью newman (об этом будет отдельная статья)
- Редактирование коллекции привязано к Postman, т. е. для изменений потребуется сделать импорт, отредактировать, а затем сделать экспорт в репозиторий проекта
- Так как коллекция лежит в одном большом json файле, Review изменений практически невозможно
У каждого проекта свои подходы и взгляды на тестирование и разработку. Мы увидели для себя больше плюсов, чем минусов, и поэтому решили использовать этот мощный инструмент, как для тестирования, так и для описания запросов к API нашего проекта. И по своему опыту можем сказать, даже, если вы не будете использовать средства тестирования, которые предоставляет Postman, то иметь описание запросов в виде коллекции будет весьма полезно. Коллекции Postman это живая, интерактивная документация к вашему API, которая сэкономит множество времени, и в разы ускорит разработку, отладку и тестирование!
P.S.:
Основной функционал Postman бесплатен и удовлетворяет ежедневным нуждам, но есть некоторые инструменты с рядом ограничений в бесплатной версии:
- Postman API – позволяет получать доступ к данным вашего аккаунта, добавлять, удалять и обновлять коллекции, запросы, и другую информацию программно, напрямую через API. Вы можете обратиться к нему 1000 раз в месяц.
- Mock сервер – позволяет развернуть заглушки для вашего API на серверах разработчиков Postman. Доступно 1000 запросов в месяц.
- Api Monitoring – позволяет создавать коллекции для мониторинга и запуска их по расписанию с серверов разработчика Postman. Система мониторинга сделает для вас не больше 1000 запросов в месяц
- Api Documentation – позволяет публиковать автоматически сгенерированную документацию на серверах приложения Postman. Ограничение 1000 просмотров в месяц
Как тестировать методы REST API
Когда ручного тестировщика впервые просишь проверить метод REST API, того охватывает паника: «Как это делать? Я вообще почти ничего не знаю про API. Что делать? Как это тестировать?»
Спокойно. Без паники =) Я уже рассказывала на простом языке, что такое API. А сегодня я расскажу о том, как его тестировать. На самом деле почти также, как GUI: в первую очередь это тест-дизайн и придумывание проверок, а потом уже всякие API-штучки. Но и про них не стоит забывать.
Я дам вам чек-лист, к которому вы сможете обращаться потом — «так, это проверил, и это, и это. А вот это забыл, пойду посмотрю!». А потом мы обсудим каждый пункт — зачем это проверять и как.
После теории будет практика! Для неё возьмем метод doRegister системы Users — он находится в открытом доступе, можете дергать по ходу чтения и проверять =)
Чек-лист проверок
- Правильное тело (пример)
- Бизнес-логика: позитив, негатив
- Различные параметры (обязательность, работа параметров)
- Перестановка мест слагаемых (заголовки, тело)
- Регистрозависимость (заголовки, тело)
- Ошибки: не well formed xml / json
- Правильный параметр (из примера)
- Обязательность (что, если параметр не указать?)
- Бизнес-логика (тест-дизайн)
- Регистрозависимость (если параметр текстовый)
- Перестановка местами
То есть берём REST-часть и обычную, применяем тест-дизайн, словно это параметр в графическом интерфейсе.
- Заголовки из документации работают (в целом)
- А если какой-то не передать? (обязательность)
- А если передать, но неправильно? (текст ошибки)
- Позитивные тесты по доке
- Регистронезависимость заголовков
Кратко прошлись, теперь разберемся в деталях и с примерами.
Содержание
- Позитив или негатив?
- В каком порядке тестируем
- Примеры
- Основной позитивный сценарий
- Альтернативные сценарии/a>
- Негативные сценарии
- Параметры запроса
- Остальные тесты
- Что тестируем в запросе
- Что тестируем в ответе
- Итоговый чек-лист проверки doRegister
- Вывод
Позитив или негатив?
Я учу начинающих тестировщиков так: ВСЕГДА сначала позитивное тестирование, а потом негативное. Иначе вы успеете проверить всякий треш, а с нормальными данными система работать не будет.
Однако в случае тестирования интеграции негатив может оказаться приоритетнее. На одном из рабочих проектов обсуждала это с архитектором, который разрабатывает системы для интеграции — как заказное ПО, так и общедоступное. Он учил меня так:
Сначала надо проверить негатив. Потому что разработчики продукта, которые подключают наше API, всегда будут напарываться на грабли. Не прочитали документацию / прочитали криво — получили ошибку.И нужно, чтобы по сообщению об ошибке они поняли:— Что они сделали не так— Как это исправитьЭто нужно для того, чтобы уменьшить количество обращений в тех. поддержку.Так что проверьте сначала всякие извращения, а потом, пока разработчик чинит найденные баги, сидите со своими позитивными тестами и позитивными сценариями.
В целом, есть логика в его словах. Ну и плюс всё зависит от времени, если вам позитивные тесты погонять займет полчасика, то проще начать с них. А если там куча сценариев + обязательные автотесты часа на 4, то можно сначала погонять руками, выдать пачку замечаний и сидеть спокойно писать свои тесты.
Обсудите со своими разработчиками, как им будет удобнее — чтобы вы сначала потыкали “на слом” и прислали очевидные баги, или вдумчиво проверили всё и прислали результат одним файлом. Как им удобнее, так и делайте.
Но лично я всё же считаю, что как минимум основной сценарий позитивный проверить надо. И желательно пару ответвлений от него.
В каком порядке тестируем
1. Примеры в ТЗ
Самое простое, что можно сделать — дернуть пример из документации, чтобы посмотреть, как метод вообще работает. А потом уже писать обвязку в коде.
Это пойдут делать тестировщики, получив от вас новый функционал. И это же сделает разработчик интеграции / другой пользователь API.
Отсюда вытекают следующие выводы:
а) Примеры в документации должны быть! Причем желательно не один, а на каждый интересный кейс. Чтобы на него точно обратили внимание!
б) Примеры тестируем в первую очередь, потому что именно их дернут первыми. И потом будут делать по аналогии.
В Users есть только один пример:
{ "email": "milli@mail.ru", "name": " Машенька", "password": "1"}- Тип запроса — POST
- URL — http://users.bugred.ru/tasks/rest/doregister
- Тело — из примера
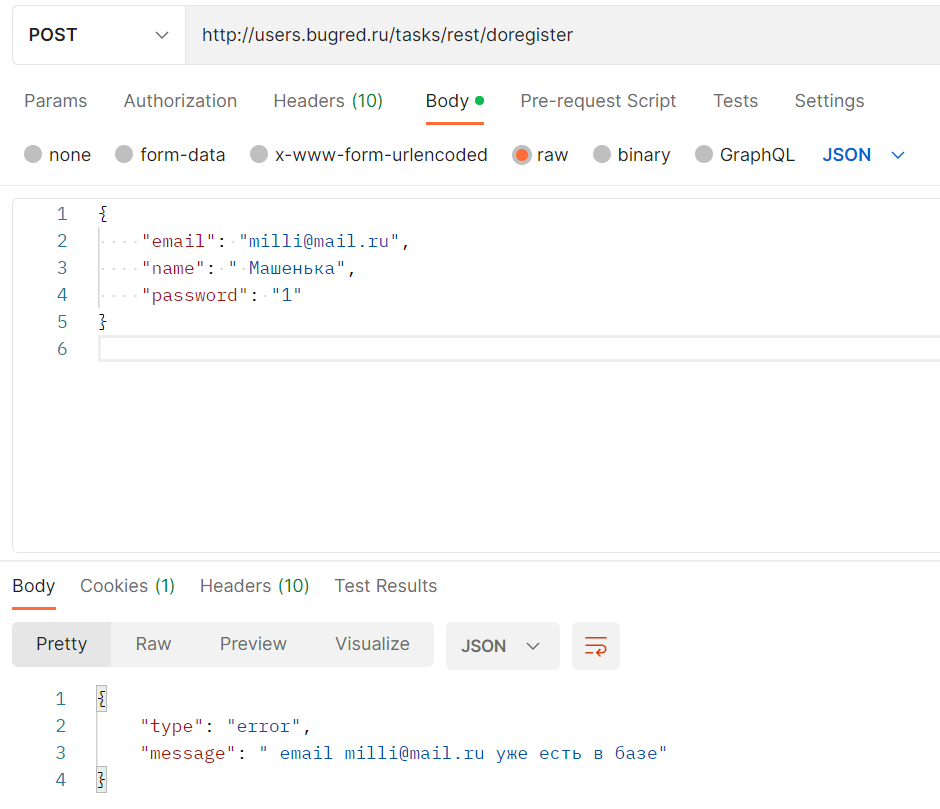
Упс, ошибочка… Читаем её внимательно:
" email milli@mail.ru уже есть в базе"
В целом логично, раз метод создает нового пользователя, может быть ограничение уникальности. Смотрим в ТЗ, и правда:
Имя и емейл должны быть уникальными
Значит, метод не идемпотентный… Нельзя просто взять пример из ТЗ и отправить не глядя.
СправкаМетод HTTP является идемпотентным, если повторный идентичный запрос, сделанный один или несколько раз подряд, имеет один и тот же эффект, не изменяющий состояние сервера. Корректно реализованные методы GET, HEAD, PUT и DELETE идемпотентны, но не метод POST. © developer.mozilla.org
Нужно взять пример и отредактировать его так, чтобы данные стали уникальными. Можно от руки дописать несколько циферок:
{ "email": "milli5678@mail.ru", "name": " Машенька5678", "password": "1"}А можно использовать функционал Postman, который позволяет указать рандомные значения — динамические переменные. Пожалуй, мне хватит $randomInt. Но так как я отправляю запрос в JSON-формате, то надо обернуть переменную в фигурные скобки, иначе постман считает её как простой текст:
{ "email": "milli{{$randomInt}}@mail.ru", "name": " Машенька{{$randomInt}}", "password": "1"}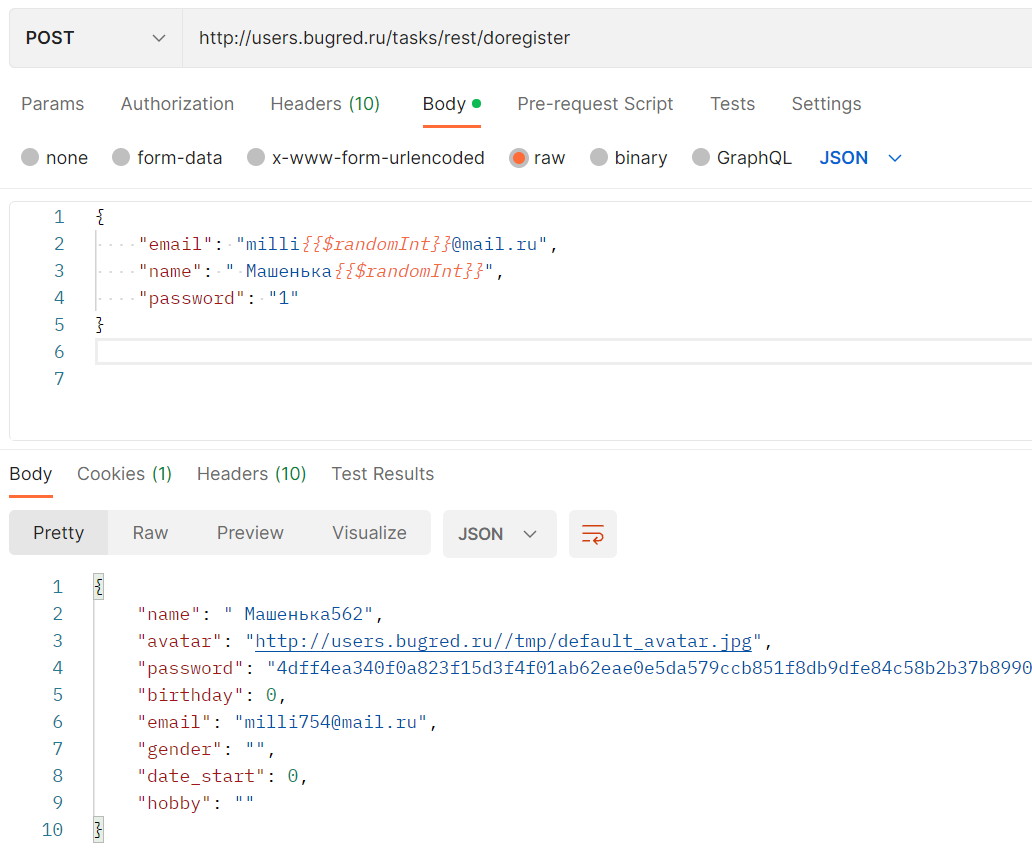
См также: Как понять, что мы отправляли, какую переменную?
Пример проверили, отлично. Он рабочий, но не идемпотентный, так что его нужно скорректировать под себя. Документация НЕ неправильная, запрос рабочий, если его прогонять на пустой базе в первый раз.
Однако пользователи бывают разные. Они вполне могут скопипастить пример, отправить его, получить ошибку и прибежать в поддержку ругаться, не читая сообщение об ошибке — у вас плохой пример, он не работает.
И чем больше у вас пользователей, тем больше таких вопросов будет. Заводить ли тут баг на правку документации? Можно предложить дописать в ТЗ как-то так:
Запрос (для проверки запроса исправьте имя пользователя и email, чтобы они были уникальными): ...
То есть заранее подсказываем, что надо изменить, чтобы запрос сработал AS IS. Можно было бы и пример с рандомными переменными постмана дать, но тут надо понимать, что через постман его будут дергать тестировщики и аналитики со стороны заказчика.
Разработчики же должны написать код, используя ваш пример. А они тоже любят копипастить))) И если дать пример, заточенный под постман, то к вам снова придут с вопросом, почему ваш пример не работает, но уже в коде. И тут опять или писать около примера, что “$randomInt — переменная Postman, она тут для того-то”, или всё же примеры оставить в покое.
Я не вижу особой проблемы в текущем описании, это не повод ставить баг на документацию. Пример нормальный и рабочий. А если принесет головную боль поддержке, тогда и замените.
В нашей доке всего 1 пример. Если бы их было больше, надо было бы вызвать все. Именно на примерах пользователи учатся работать с системой. Дернули, получили такой же ответ, изучили его, осознали, запомнили =)
2. Основной позитивный сценарий
Чтобы настраивать интеграцию, разработчику той стороны нужен работающий сценарий. Самый основной, все ответвления можно отладить позже.
В идеале он берет этот сценарий из примера. Если примеров нет, будет дергать метод наобум, как он считает правильным. Знаете, как с новым девайсом — сначала попробовал сам, если не получилось, пошел читать инструкцию.
Тем не менее у разработчика есть основной позитивный сценарий его системы, его он и будет проверять. И тестировщик должен проверить его в первую очередь.
А у нас есть пример, так что основной позитивный сценарий мы уже почти проверили!
Почему “почти”? Мы проверили, что система вернула в ответе «успешно создалась Машенька562», но точно ли она создалась? Может быть, разработчик сделал заглушку и пока метод в разработке, он всегда возвращает ответ в стиле “успешный успех”, ничего при этом не делая.
Так что идем и проверяем, есть ли наша Машенька в GUI — http://users.bugred.ru/. Ищем поиском — есть!
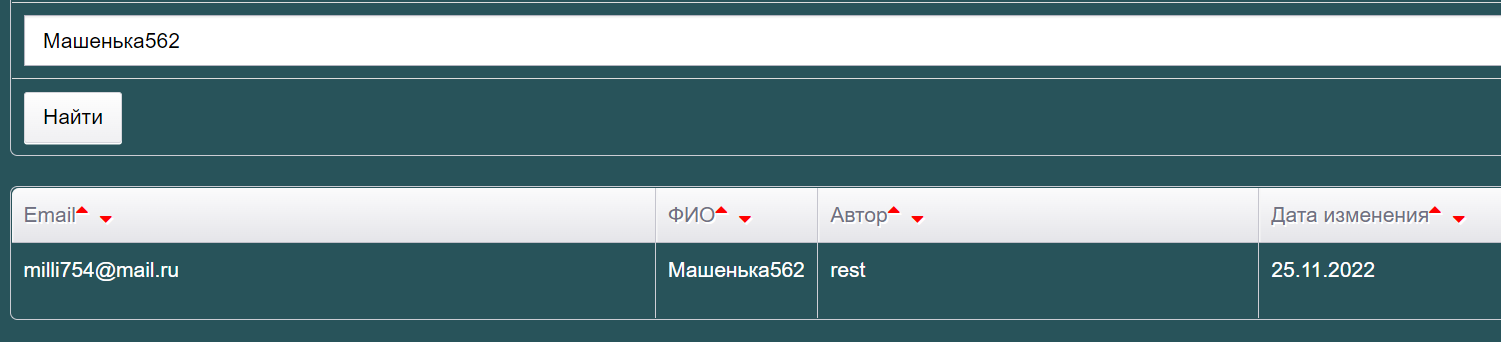
- Емейл правильный, какой мы отправляли.
- Автор «rest», что логично.
- Дата изменения — сегодня, что тоже правильно.
Значит, пользователь правда создан! Хотя постойте… Я же выполняла не метод CreateUser, а doRegister. Его основная цель — не создать карточку, а зарегистрировать пользователя в системе. Просто при регистрации карточка автоматом создается, поэтому её тоже зацепили проверкой.
А как проверить, что регистрация прошла успешно? Правильно, попробовать авторизоваться!
Нажимаем «Войти» и вводим наши данные: milli754@mail.ru / 1
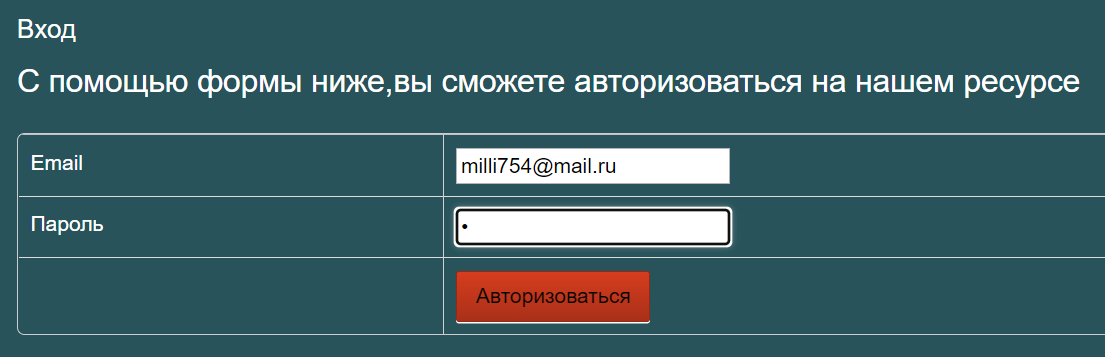
Вошли! Ура, значит, регистрация правда сработала. Вот теперь мы закончили с основным позитивным сценарием.
3. Альтернативные сценарии
На самом деле если в ТЗ нет отдельно выделенного сценария использования, то можно объединить пункты “альтернативные сценарии” и “негативное тестирование”, потому что по факту после базового теста мы:
- Читаем каждое предложение из ТЗ, «Особенности использования» или как этот раздел у вас называется
- Продумываем, как его проверить: как позитивно, так и негативно.
Но давайте для чистоты эксперимента попробуем разнести эти пункты отдельно. Тогда в альтернативы попадают все дополнительные условия, которые накладываются на посылаемые или возвращаемые данные.
Читаем особенности использования:
Пользователь создается и появляется в системе.
Автор у него всегда будет «SOAP / REST», изменять его можно только через соответствующий-метод.
Автора тоже проверили, но только вот в ТЗ он указан капсом, а по факту создается в нижнем регистре. Это уже небольшой баг, скорее всего документации, так как некритично и проще доку обновить. Сделали заметочку / сами исправили доку, если есть доступ.
А дальше видим, что изменять только только через соответствующий метод. Ага, то есть если создали через REST, менять можно тоже только через REST, через SOAP нельзя. И наоборот. Это и проверим.
Для начала под Машенькой в ГУИ посмотрим, есть ли возможность отредактировать собственную карточку — нету. Ок. Открываем в SOAP Ui WSDL проекта — http://users.bugred.ru/tasks/soap/WrapperSoapServer.php?wsdl, и смотрим, каким методом можно вносить изменения.
Нам вполне подойдет UpdateUserOneField, он обновляет одно любое поле пользователя. А как понять, какие поля есть? Покопаться в документации. В Users описаны не все методы, но есть описание CreateUser, где можно взять названия полей. Допустим, хочу обновить кличку кошки — cat. Получается запрос:
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:wrap="http://foo.bar/wrappersoapserver"> <soapenv:Header/> <soapenv:Body> <wrap:UpdateUserOneField> <email>milli754@mail.ru</email> <field>cat</field> <value>Еночка</value> </wrap:UpdateUserOneField> </soapenv:Body></soapenv:Envelope>
Поле cat успешно изменено на Еночка у пользователя с email milli754@mail.ru
Проверяем в интерфейсе, находим карточку пользователя и жмем “Просмотр” (прямую ссылку давать бесполезно, база дропается каждую ночь, тут только самому создать и посмотреть). Значение обновилось:
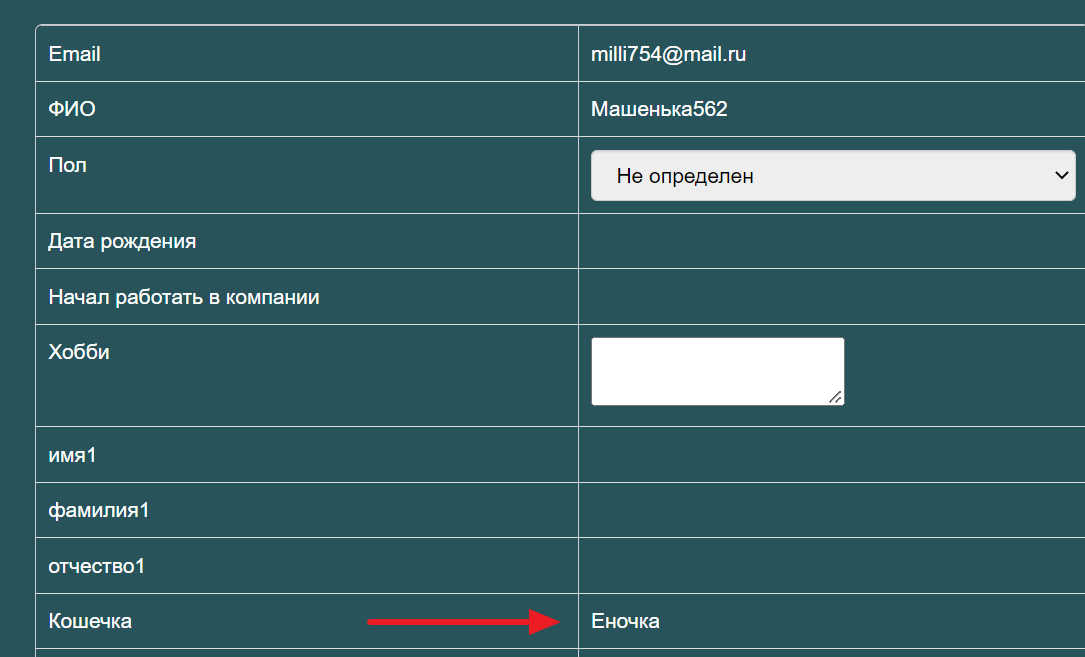
Значит, условие из ТЗ не выполнено, можно ставить баг!
Имя и емейл должны быть уникальными
Раз должны, то будет ошибка в случае неуникальности. А мы решили вынести тестирование негативных сценариев отдельно. Видите, решение тестировать альтернативы отдельно от негативного сразу оказалось не самым удобным — куда лучше просто читать ТЗ и каждый пункт проверять. Так хоть не запутаешься, что проверил, а что ещё нет… Однако в рамках статьи мы всё-таки рассмотрим негативные тесты отдельно.
Пока же смотрим дальше — а всё, кончилось ТЗ, метод то простенький. Тогда переходим к негативу!
4. Негативные сценарии
По факту это проверка сообщений об ошибках. Смотрим на метод и думаем, как его можно сломать? Сначала бизнесово, а потом API-шно…
С бизнесовой точки зрения очень удобно, когда все ошибки прописывают прямо в ТЗ. Получается руководство к действию! Это можно быть разделение на «Особенности использования» и «Исключительные ситуации», как в Folks (логин для входа тут). Тогда тестируем блок «Исключительные ситуации».
Или вот описание Jira Cloud REST API, выберем в левом навигационном меню какой-нибудь метод, например «Delete avatar». Там есть описание метода, а потом в блоке Responces переключалки между кодами ответов.
Ну так вот все желтые коды — это ошибки. Открываем каждую, читаем «Returned if» и выполняем это условие, очень удобно:
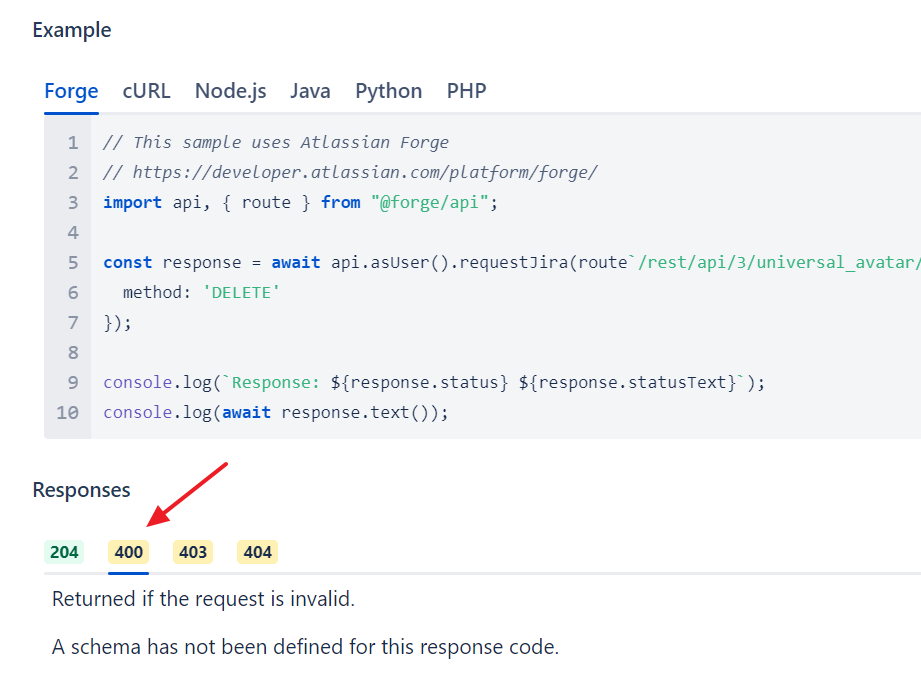
В общем, если есть отдельно про ошибки — класс, проверяем по ТЗ. А потом ещё думаем сами, что там могло быть пропущено.
Плюс проверяем логику ошибок в API, но о ней чуть позже. Сначала бизнес-логика, потом уже серебряная пуля типа well formed json.
Имя и емейл должны быть уникальными
Для проверки нам надо сделать неуникальным:
Можем взять за основу наш исходный запрос, который 1 раз создался:
{ "email": "milli754@mail.ru", "name": " Машенька562", "password": "1"}1. Уникальный емейл, дубликат имени
{ "email": "milli{{$randomInt}}@mail.ru", "name": " Машенька562", "password": "1"}2. Уникальное имя, дубликат емейл
{ "email": "milli754@mail.ru", "name": " Машенька{{$randomInt}}", "password": "1"}3. Дубликаты сразу имени и емейл
{ "email": "milli754@mail.ru", "name": " Машенька562", "password": "1"}И смотрим на ответ. Понятно ли нам из сообщения об ошибке, что именно пошло не так? А статус-код соответствует типу ошибки?
5. Параметры запроса
На входе мы передаем какие-то параметры. И теперь нам нужно взять каждый параметр и проверить отдельно. Как проверяем:
Про первые 2 пункта мы поговорим чуть позже, сейчас сосредоточимся на бизнес-логике.
Вот у вас есть параметры запроса. Как их проверять? Если вы впали в ступор сейчас, то просто представьте себе, что это не API, а GUI. Что у вас в интерфейсе есть форма ввода с этими полями? Как будете тестировать? Вот ровно так и тестируйте, выкинув разве что попытку убрать ограничение на клиенте (снять с поля maxlenght).
Тестируем каждый параметр в отдельности. И тут, как и в GUI, надо понимать:
- Есть ли какие-то проверки у поля? Проверяется ли email по маске email-а? Имя выверяется по справочникам? Или это “просто строка, как прислали, так и сохранил?”
- Куда данные идут дальше, где отображаются? В приветствии, в отчете, в личном кабинете, где?
- Как они потом используются? На емейл придет письмо?
Вроде доп. проверок разработчик не делал, но точно я этого не знаю. Поле базовое, может есть прям во фреймворке какие-то проверки, или в интернете скопипастил… Так что тут стоит убедиться, что email корректный.
Можно взять за основу вот этот чек-лист, но часть проверок скомбинировать
- Корректный существующий email, куда может прийти почта — подставляем свой (начинаем всегда с корректного)
- Верхний регистр, цифры в имени пользователя и доменной части — TEST77@mail9.ru
- Email с дефисами и нижним подчеркиванием — test_user-1@mail_test-1.com
- Email с точками в имени пользователя и парой точек в доменной части — test.user@test.test.test.ru
А дальше идут интересные тесты, которые по идее должны падать, но упадут ли в Users, есть ли там такие проверки?
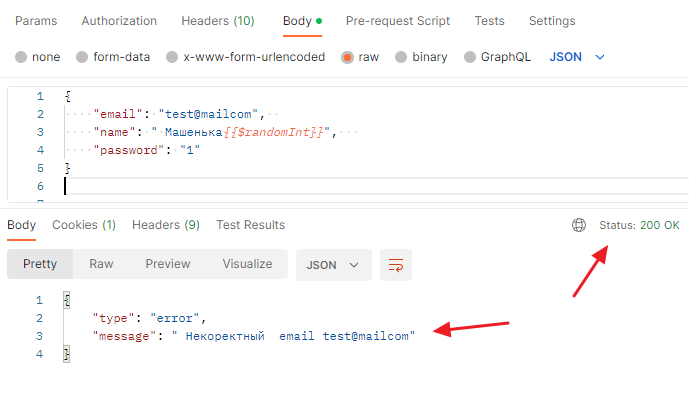
- Email без точек в доменной части — test@mailcom
- Превышение длины email (>320 символов)
- Отсутствие @ в email — testmail.ru
- Email с пробелами в имени пользователя — test user@mail.ru
- Email с пробелами в доменной части — test@ma il.ru
- Email без имени пользователя — @mail.ru
- Email без доменной части — test@
- Некорректный домен первого уровня (допустимо 2-6 букв после точки: .ru) — test@mail.urururururu
Помним, что имя должно быть быть уникальным при этом, потому что негативные тесты мы не смешиваем, только если в этом состоит сам тест “а что, если несколько полей сразу плохие”. Так что пример запроса:
{ "email": "test@mailcom", "name": " Машенька{{$randomInt}}", "password": "1"}И сервер отвечает — некорректный емейл!
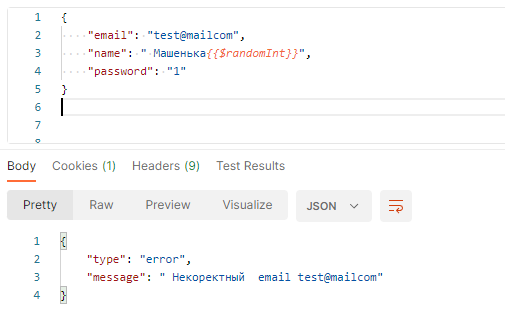
Так что проверки на емейл нужны, особенно — на некорректный.
name
Имя можно тестировать по разному. Если по нему определяется пол, тесты будут одни, если предлагаются подсказки, другие, а если это простая строка — третьи.
Так вот, в Users имя — это простая строка. Пол по ней не определяется, оно просто сохраняется в системе, разве что в правом верхнем углу отображается
Поэтому закапываться в “а теперь проверим мужское имя, и женское, и…” смысла нет.. Так что наша задача — проверить:
Ну и начинаем с позитивного теста. Итого получаем:
- Простое имя типа “Ольга”
- Имя с разным регистром, разными буквами и спецсимволами (все спецсимволы можно перечислить) — если есть ограничение по длине, разобьем на разные тесты
- 1 000 символов — ищем верхнюю границу, если она есть. Заодно смотрим, как это выглядит в интерфейсе и корректируем тест.
- 1 000 000 символов — ищем технологическую границу
Обратите внимание на то, что мы вроде как тестируем API-метод, но после его выполнения лезем в графический интерфейс и проверяем, как там выглядит результат нашего запроса.
А всё почему? Потому что нет абстрактных методов, которые делают “ничего”, просто отправляются. Они все зачем-то нужны. В нашем случае — чтобы создать пользователя в системе. И важно понимать, а что будет потом с нашими данными? Будут ли они нормально отображаться в интерфейсе? Ведь если нет, то надо ставить ограничение на API-метод.
Поэтому помните, что API и GUI идут рука об руку, а не живут в разных мирах.
Password
На пароле тоже никаких ограничений нет — мы это знаем, потому что уже отправляли запрос с паролем “1”. Вот если бы были всякие “нужны заглавные буквы” и прочее, мы бы провели тесты “а если пароль ненадежный” и посмотрели на качество сообщения об ошибке, а так тесты будут как у имени:
- Обычный пароль типа 1
- Смесь из разных регистров, разных букв и спецсимволов — если есть ограничение по длине или составу, разобьем на разные тесты
- 1 000 символов — ищем верхнюю границу, если она есть. Заодно смотрим, как это выглядит в интерфейсе и корректируем тест.
- 1 000 000 символов — ищем технологическую границу
6. Остальные тесты
А дальше мы уже идем по специфике API:
- Перестановка мест слагаемых (заголовки, тело)
- Регистрозависимость (заголовки, тело)
- Well formed xml / json
На конкретных примерах мы остановимся подробнее в следующих разделах. Просто важно не забывать про эти тесты. Этим и отличается API от GUI — тут нельзя снять границу из серии “убрать maxlenght”, зато можно и нужно проверить особенности API запросов.
Что тестируем в запросе
Заголовки (Headers)
Заголовки должны где-то обрабатываться:
Иначе они не нужны, только лишний трафик гонять. Мы ведь передаем сообщение по сети, если интернет плохой, то каждый байт на счету. Зачем отправлять информацию, которую никто не использует?
Так что разработчики используют «Принцип меньшего зла»: заголовок или кем-то обрабатывается, или он вообще не нужен.
— используется дефолтный, прописанный в коде;
Язык должен указываться всегда, иначе непонятно, как вернуть ответ от сервера. Но разработчик может в код зашить русский язык, и тогда даже если вы передадите заголовок «Accept-Language: en-US», то ответ получите на русском.Почему? Потому что разработчик игнорирует этот заголовок, он его не считывает из запроса в принципе. Его право =)
Возможные ситуации, которые надо проверить
Заголовок не передан, как система реагирует:
— выдает ошибку → понятно ли, что мне надо сделать?
— применяет поведение по умолчанию (если язык не передан, используй русский)
Плюс регистрозависимость. Согласно спецификации, все заголовки должны быть регистронезависимы. И неважно, как я их передаю. Могу в CamelCase (первая буква большая, остальные мелкие), могу в верхнем регистре, причем как значение заголовка, так и его название, могу как-то ещё:
- Accept: application/json
- Accept: APPLICATION/JSON
- ACCEPT: application/json
- ACCEPT: APPLICATION/JSON
- ACcePT: APPlicATIon/JSon
Проверить эти варианты — очень важно. Потому что за регистронезависимость отвечает разработчик, сама по себе из воздуха она не появится. Он должен прописать это в коде.
Был случай у моих коллег — заголовок проверили, всё работает. Но проверили по доке, прислали значения «как указано». Вот Accept может быть (как передаются входные данные):
А потом пользователи приходят и жалуются на ошибки «у вас плохой заголовок». При том, что заголовок они отправили правильный. Начали разбираться — запрос идет не напрямую на сервер, он проходит через прокси Nginx. А Nginx меняет заголовки на upper case: ACCEPT: APPLICATION/JSON.
Система к такому не готова, она ищет «Accept», не находит его и выдает ошибку. А переданный заголовок игнорирует. Так что проверять регистр — надо!
Итого — тестирование заголовков в API
- Заголовки из документации работают (в целом)
- А если какой-то не передать? (обязательность)
- А если передать, но неправильно? (текст ошибки)
- Позитивные тесты по доке
- Регистронезависимость заголовков
В документации вообще ничего не сказано про заголовки. Поэтому проверяем, можно ли отправить сообщение без них. Идем на вкладку Headers и снимаем все галки, если они по каким-то причинам там стояли. Запрос сработал успешно:
Но обратите внимание, что в постмане есть ещё скрытые заголовки (hidden):
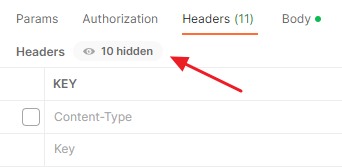
Это те заголовки, что генерирует сам постман. По сути постман — это клиент, помогающий нам отправить запрос на сервер. И у него есть какие-то свои фишечки, ограничения, заголовки опять же.
Можно нажать на это сообщение “(цифра) hidden” и раскрыть этот список (а потом всегда можно нажать на кнопку “hide hidden”:
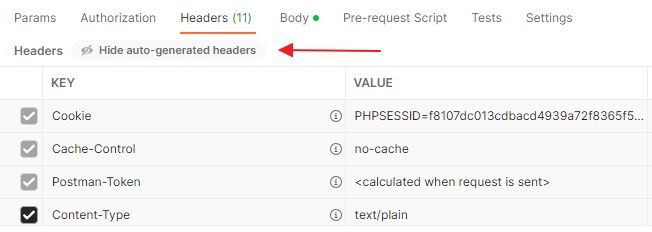
Это некий стандарт, дефолтные значения по умолчанию. Тот же Cache-Control, раз вы его не передаете, по факту он вам не нужен, то есть как если бы вы указали “no-cache”.
Но учтите, что если снять тут все-все-все галки, система может выдать ошибку:
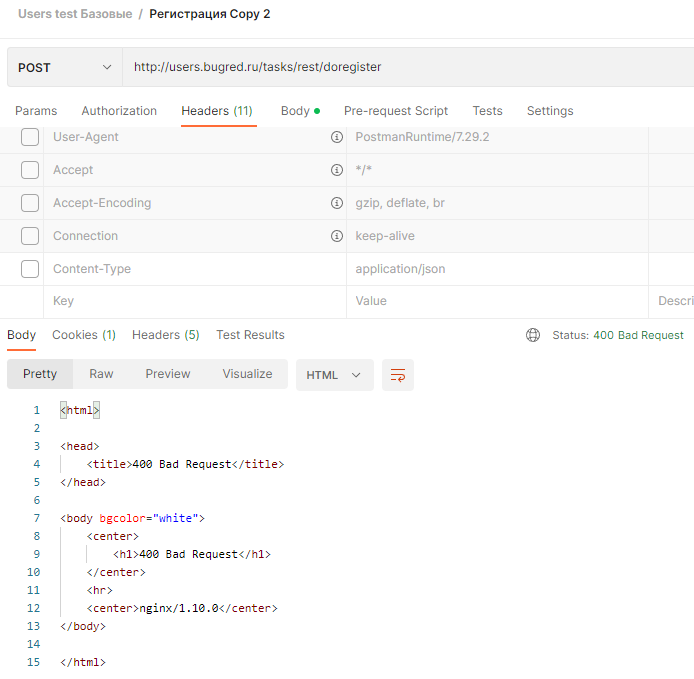
Плохо ли это? Стоит ли заводить баг “в документации сказано, что можно без заголовков, а так не работает” — нет. Для начала попробуйте отправить запрос через curl и посмотрите на результат.
Помните, что Postman — это всё-таки клиент, у которого есть свои навороты. Так что пусть он их накручивает сколько влезет, эти хидден-заголовки тестировать особо не надо. А вот послать хотя бы разок честный curl — надо!
Так что прячем hidden-заголовки и проверяем без них в этом пункте. Да, doregister без заголовков работает, всё ок.
Тело запроса (body)
- Правильное тело (пример)
- Различные параметры (обязательность, работа параметров)
- Бизнес-логика
- Ошибки: бизнес-логика
- Перестановка мест слагаемых
- Регистрозависимость
- Ошибки: не well formed xml / json
Пункты 1-4 мы уже обсудили выше. Идем по ТЗ и каждую строчку изучаем и проверяем.
Это как раз особенность API, поэтому очень важно её проверить. Бизнес-логика и проверки “а что можно ввести в такое-то поле” одинаковы для GUI и API, а вот переставить поля местами в графическом интерфейсе не получится.
При этом в API это сделать проще простого. Мы ведь передаем пары “ключ-значение”. Что будет, если мы попробуем поменять их местами?
В идеале ничего не случится, потому что принимающая система должна из запрос цеплять информацию именно по названию ключа, а не делать “select *” и потом говорить “для первого поля из запрос проверь то, для второго сделай это…”.
Ведь потом изменится входной запрос и у нас вся интеграция сломается! А это нехорошо… Так что смотрим как система реагирует на перестановки.
Вы же помните о том, что регистронезависимость не появляется из воздуха? Её делает разработчик. Поэтому и проверить “как ведет себя система” — тоже надо. И в заголовках, и в теле, и в параметрах URL — вообще везде, где есть символы.
Всегда обязательно изучаем ошибки. Помимо ошибок в бизнес-логике есть ещё неправильно составленный запрос. То есть не well formed. Пробуем такой послать и смотрим на адекватность ошибки
См также:Правила Well Formed XMLПравила Well Formed JSON
По бизнес-логике мы уже прошли, теперь пойдем по API-части:
1. Перестановка мест слагаемых
{
"name": " Машенька{{$randomInt}}",
"email": "test{{$randomInt}}@mail.com",
"password": "1"
}Ура, работает! А как насчет form-data? Тоже всё ок, это хорошо:
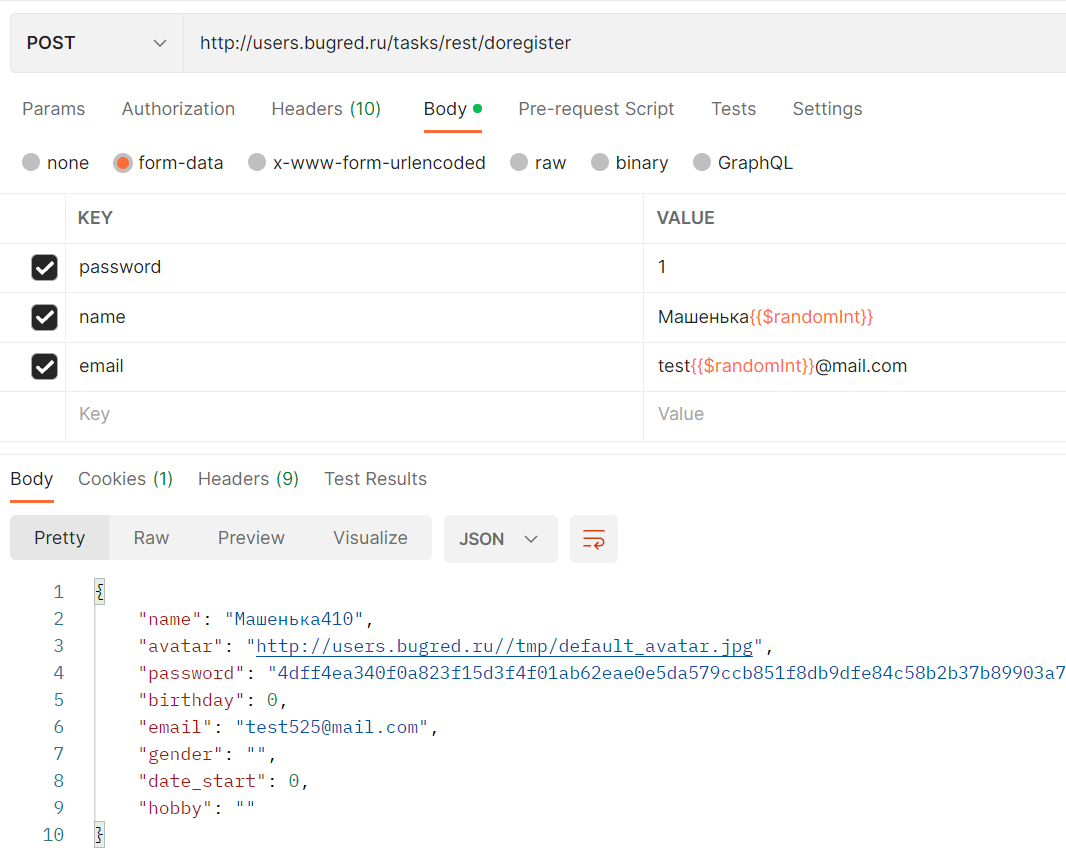
Мы уже поняли, что в Users регистронезависимости может и не быть. Поэтому проверим на одном поле для начала. И не email, а то с ним может быть ложная уверенность в корректной ошибке:
{ "email": "test{{$randomInt}}@mail.com", "NAME": " Машенька{{$randomInt}}", "password": "1"}Запрос не сработал, увы: "Параметр name является обязательным!"
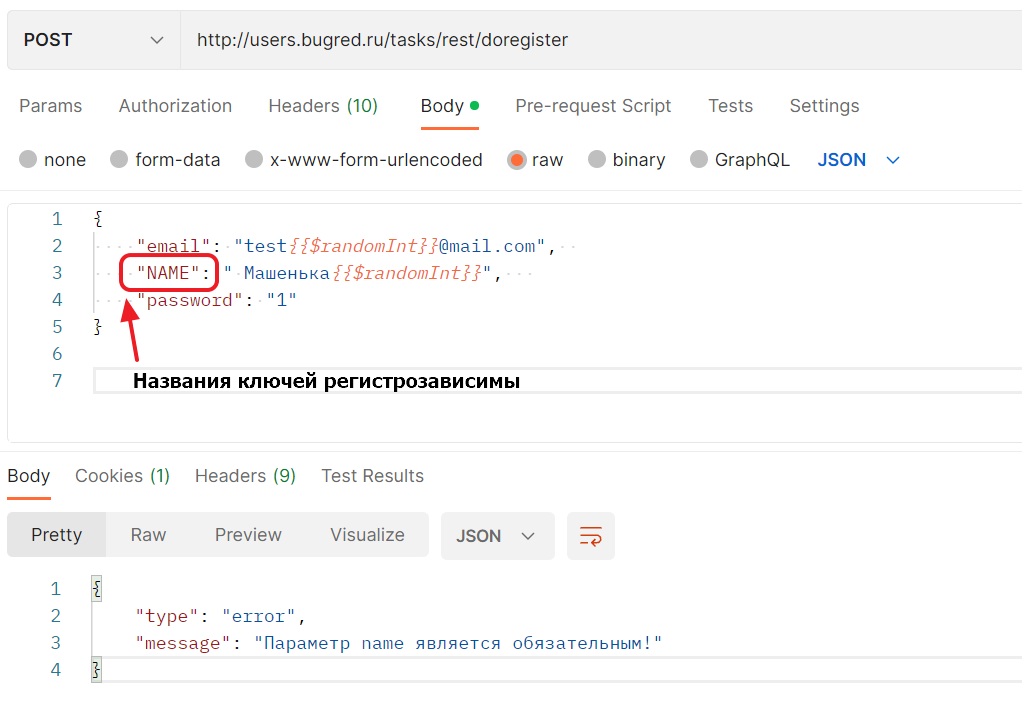
Названия ключей регистрозависимы. Это не очень хорошо, хотя и некритично. Такой баг разработчик может не захотеть исправлять, “пусть присылают по документации”. Ну что же, тогда единственным аргументом будет потом количество обращений в поддержку.
Но мы, по крайней мере, получили информацию по работе системы.
У нас на входе json, смотрим его правила:
- Данные написаны в виде пар «ключ:значение»
- Данные разделены запятыми
- Объект находится внутри фигурных скобок {}
- Массив — внутри квадратных []
И пытаемся сломать. Вообще самая частая ошибка — это запятая после последней пары «ключ:значение». Мы обычно скопипастим строку из середины (вместе с запятой), поставим в конец объекта, а запятую удалить забудем. Получится как-то так:
{
"email": "test{{$randomInt}}@mailcom",
"name": " Машенька{{$randomInt}}",
"password": "1",
}Отправляем такой запрос. М-м-м-м, ответ как-то не очень:
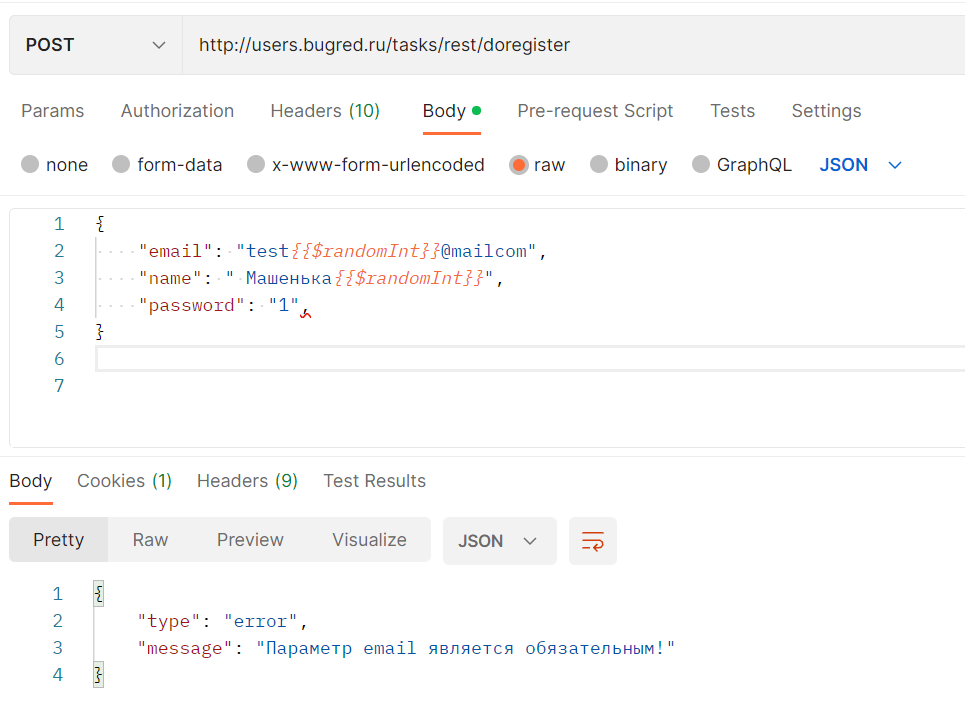
Это постман мне настойчиво подсвечивает красным лишнюю запятую, а если вызов идет из кода и там подсветки нет, то как понять, что пошло не так? Из текста сообщения об ошибке. Только вот из такого текста разработчик очень долго будет угадывать, что не понравилось системе… Нехорошо, стоит завести баг.
Попробуем другие способы сломать формат:
— не в виде пар “ключ:значение”
{ "email": "test{{$randomInt}}@mail.com", "name": " Машенька{{$randomInt}}", "password"}Ответ будет такой же — "Параметр email является обязательным!"
Заметьте, что если мы “сломаем” так email, будет ложное ощущение, что система работает хорошо и правильно дает подсказку. А на самом деле нет…
Так что если уже замечали странности раньше, проверяем на другом поле — на пароле, а не емейле. И видим, что ошибка непонятная.
— данные не разделены запятыми
{ "email": "test{{$randomInt}}@mail.com" "name": " Машенька{{$randomInt}}" "password": "1"}— объект в квадратных скобках, а не фигурных
[ "email": "test{{$randomInt}}@mail.com", "name": " Машенька{{$randomInt}}", "password": "1"]Ответ везде одинаковый — "Параметр email является обязательным!"
Не очень хорошо, в ожидаемый результат чек-листа проверок мы запишем что-то более «правильное» =)) Например, ошибка 400 и сообщение "Не well formed json в запросе".
URL
Там тоже могут быть параметры. Обычно это в методе GET делается, прямо в параметры URL зашивается какая-то информация. Например, идентификатор элемента, который мы хотим получить.
Тестируем точно также, как если бы параметр был в теле:
- Правильный параметр (из примера)
- Обязательность (что, если параметр не указать?)
- Бизнес-логика (тест-дизайн)
- Регистрозависимость (если параметр текстовый)
Почему не на примере Users? А потому что в методе doRegister нет параметров, которые передаются в URL. Да и вообще в Users их нету, там даже get через POST сделан, но сейчас не об этом…
Поищем примеры в Jira Cloud REST API. Например, метод «Get Issue», вот какой у него URL:
GET /rest/api/3/issue/{issueIdOrKey}Мы передаем в URL или id задачи, или её ключ. Условно говоря, это или что-то типа “13005” или “TEST-1”.
И вот тут мы уже можем развернуться!
Базовый позитивный тест, что метод в целом работает. Вызываем обязательно и так, и так:
Попробуем не передать параметр:
/rest/api/3/issue//rest/api/3/issue
Тут стоит подумать в тему состояний объекта. Пробуем получить:
- Свежесозданную задачу
- Несколько раз измененную / отредактированную
- Заполненную по минимуму / по максимуму
- В разных статусах
- Закрытую
- Удаленную
- Не существующую (такого номера ещё нет — это отличается от “он есть в базе, но задача была закрыта”)
При передаче issueId этот пункт не проверить, цифры сами по себе регистронезависимы. Но если мы передаем задачу через Key, то это уже символы. Значит, проверка актуальна:
/rest/api/3/issue/test-1/rest/api/3/issue/TEst-1
Тип метода
Что будет, если мы “подменим” тип запроса?
POST → GET (совсем разные типы запросов)POST → PUT (похожие типы)
Как система отреагирует? Она может или отработать “словно так и надо”, или выдать ошибку. И тут следим за тем, чтобы ошибка была внятной и понятной.
А ещё может показаться, что игнорирование ошибок пользователя — это хорошо. Но далеко не всегда. Например, у меня был случай, когда на проекте обновили библиотеку и она стала намного жестче с ошибкам интеграции. Тут то и выяснилось, что запросы исходные системы присылали “кто во что горазд”.
Если бы система сразу падала, то на первичной интеграции пришлось бы поднапрячься побольше, зато дальнейшие переходы были бы бесшовными. А когда уже всё в продакшене, это будет стопить обновление релиза. Так что может, лучше заранее начать ловить за руку “ты мне какой-то треш” шлешь?
Меняем в запросе тип метода с POST на GET — а ему всё равно, успешно!
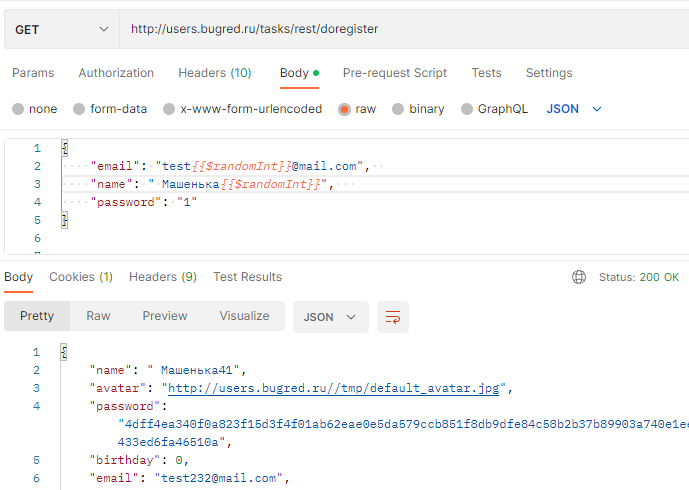
Нельзя сказать, что это прям вау-поведение, но для Users это нормально =)
Что тестируем в ответе
Тело ответа
Если у нас есть ТЗ — то всё понятно. Читаем, как должно быть, проверяем, как есть на самом деле. Смотрим на то, что все поля из требований вернулись, и что в них правильное значение. А то вдруг я сохраняю имя “Оля”, а там всегда сохраняется “Тестовый”... Очень удобно сразу автотесты писать в том же постмане, если отдельного фреймворка нет — идем по ТЗ и каждое поле выверяем.
Если ТЗ нет, то уже сложнее. Ищем «хранителя информации», расспрашиваем, проверяем, как работает на самом деле. Думаем, есть ли проблемы в текущем поведении. Нет? Ок, значит, так и надо.
Если в ответе сообщение об ошибке, то внимательно его изучаем. В API это ещё важнее, чем просто в графическом интерфейсе. Поймет ли пользователь, что именно он сделал не так, где именно ошибся? Помните, плохое сообщение об ошибке приведет к тому, что вас будут дергать по пустякам, вырывая из контекста.
См также:Каким должно быть сообщение об ошибкеСообщения об ошибках — тоже документация, тестируйте их!
Если у вас в системе два интерфейса — SOAP и REST, нужно проверить оба. Обычно они должны быть идентичны. Да и в коде это обеспечивается условно говоря двойной аннотацией “сделай и soap, и rest сгенери”, разработчик не дублирует всю функциональность дважды, а просто “включает” API.
В таком случае действительно всё будет работать идентично, кроме пустых полей в ответе. Что будет, если какое-то поле не заполнено? Может легко быть такая ситуация:
— SOAP возвращает пустые поля;
Более того, это даже может быть нормально! Например, исходно писался только SOAP-интерфейс, и было правило возвращать все поля, даже пустые. Потом решили стать модными, молодежными, подключили REST. И решили там поля пустые не возвращать.
К тому же в SOAP всегда есть схема WSDL, где указаны обязательные поля. Значит, они будут возвращаться в ответе. В ресте же схема WADL необязательна, да и там любят придерживаться принципа минимальных чернил, лишнего не выводить.
В общем, проверьте обязательно, как методы срабатывают на:
Если по разному, то это должно быть описано в доке!
Сначала отправляем базовый запрос и там, и там, как в документации. Но уже по документации мы можем заметить, что набор поле в ответах разный. В SOAP перечислены все поля юзера, включая кличку кошечки, собачки итд… В REST же несколько базовых полей, и всё.
Как так вышло? Очень просто. Для реста набор полей согласовали, разработчик сделал. Потом я сказала, что хочу ещё и SOAP. А там нужна схема WSDL, разработчик с ней особо не парился. Есть сущность “user”? Ну её и вернем в ответе. А в сущности как раз много полей…
Мне не критично, так что менять не стали, да и вообще отличный пример «да, и так бывает» же! =))
Ок, давайте теперь посмотрим на особенности API, ведь всю бизнес-логику перетестировать в SOAP смысла нет, она должна совпадать… Ну разве что вы совсем не верите своим разработчикам… Или кейсы очень важные. А так — бизнес-логику смотрим один раз, а потом переходим в особенностям API.
Поменяем местами name и email — ой ёй ёй!
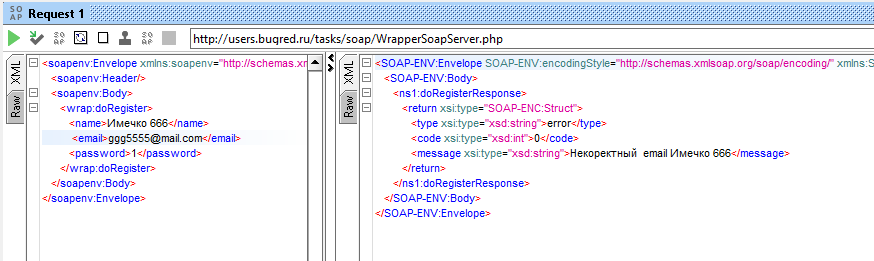
Система пишет «Некоректный email Имечко 666». Это значит, что она ориентируется не названия полей, передаваемые в тегах, а на их порядковых номер. И это ОЧЕНЬ ПЛОХО, на такое стоит идти ставить баг.
Тем более обоснование у нас есть — неединообразно работает. REST вот от перестановки не зависит, и SOAP не должен.
А ещё слово «Некоректный» написано неправильно, там должно быть две буквы “р”. Проверяем в REST, посылая заведомо плохой емейл — да, и там ошибка. Надо бы исправить. Текстовку ошибок вычитываем внимательно!
Каждый тег регистрозависим сам по себе — открывающий и закрывающий должны совпадать по написанию, в том числе по регистру. Если это сломать, будет точно плохой запрос, но мы начнем с условно хорошего — оба тега в капс-локе:
<EMAIL>ggg55555@mail.com</EMAIL>

А вот теперь попробуем разный регистр внутри тегов (в json такую проверку не сделать, это особенно XML, дублирование названия поля):
<EMAIL>ggg55555@mail.com</email>
Не работает — Bad Request. Чтож, вполне логично.
Что, если сломать XML? Скажем, оставить закрывающий тег «/email» без второй угловой скобки:
<wrap:doRegister> <email>ggg5555@mail.com</email <name>Имечко 666</name> <password>1</password> </wrap:doRegister>
<faultcode>SOAP-ENV:Client</faultcode><faultstring>Bad Request</faultstring>
Не супер информативно, но в целом ясно, что мы где-то с запросом накосячили. И если такой текст именно на well formed, то и ладно. Тогда по нему будет сразу понятно, в чем именно проблема. Посмотрим дальше.
Статус-коды
Разработчик может использовать стандартные коды ответов,
Разработчик может даже перекрыть стандартные:
400 — Bad Request
↓
400 — Internal Server Error
Но так лучше не делать =))) Просто знайте, что возможность такая имеется.
Если разработчик ленивый и не настроил коды, то вы будете огребать на любую ошибку стандартный код: 400 Bad Request. Неверный заголовок? Ошибка 400. Неверное тело? Ошибка 400. Проблемы в бизнес-логике? Ошибка 400… Ну и как тут разобраться, что именно надо исправлять?
Или ещё “лучше”, разработчик может сказать “всегда возвращай код 200”. И это очень нехорошо, ведь именно по коду мы ориентируемся в первую очередь: всё хорошо или что-то плохо?
Поэтому статус-код проверяем всегда, обращаем на него внимание. Ну а если в методе собственные статусы (как, например, в методе MagicSearch)
На статус надо было обращать внимание всегда, чтобы не дублировать снова все тесты. Но сейчас просто дернем “хороший” и “плохой” запросы.
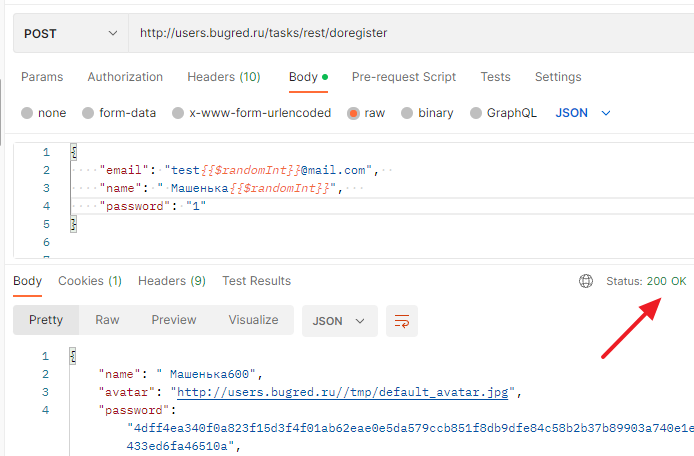
Плохой — ой, статус снова 200, хотя мы видим сообщение об ошибке:
Нехорошо! На это надо ставить баг.
Итоговый чек-лист проверки doRegister
Помним, что в первую очередь проверяем бизнес-логику. А потом уже всякие API-штучки, куда входят:
Базовый тест
Базовый тест тщательно выверяет каждое поле из “корректного” ответа. Проверяет, как вызов API-метода влияет на отображение в GUI… Поэтому его пропишем текстом, а остальные тесты соберем в табличку.
1. Проверка примера из ТЗ (но имя и емейл меняем на уникальные)
{ "email": "milli{{$randomInt}}@mail.ru", "name": " Машенька{{$randomInt}}", "password": "1"}2. В ответе следующий набор полей:
"name": " Машенька562", (то имя, что мы отправили)"avatar": "http://users.bugred.ru//tmp/default_avatar.jpg", (в этом методе всегда такой урл стандартной аватарки)"password": "4dff4ea340f0a823f15d3f4f01ab62eae0e5da579ccb851f8db9dfe84c58b2b37b89903a740e1ee172da793a6e79d560e5f7f9bd058a12a280433ed6fa46510a","birthday": 0,"email": "milli754@mail.com", (тот емейл, мы мы отправили)"gender": "","date_start": 0,"hobby": ""
3. Пользователь добавлен в общий список. Проверяем через GUI — http://users.bugred.ru/. Ищем поиском — есть!
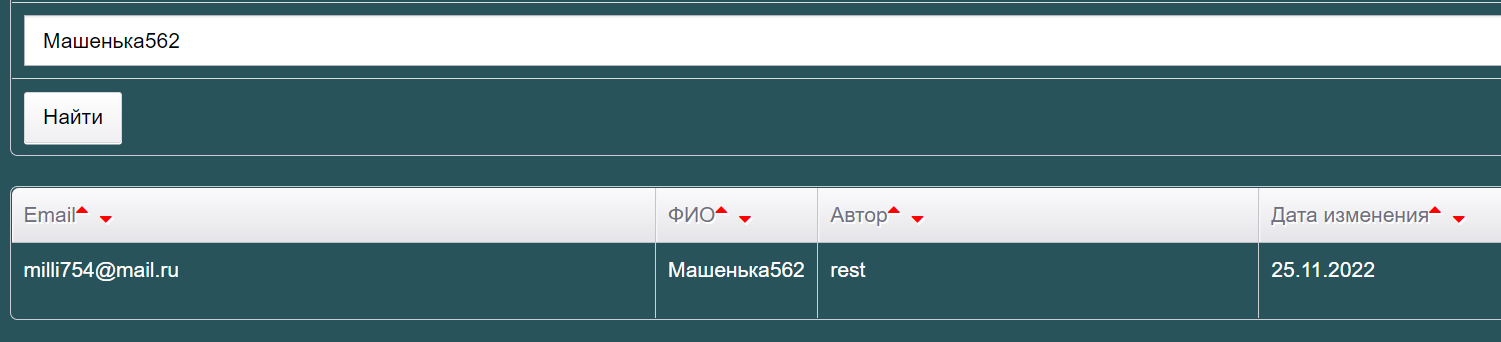
- Емейл правильный, какой мы отправляли.
- Автор «rest», что логично.
- Дата изменения — сегодня, что тоже правильно.
4. Под пользователем можно войти в систему — нажимаем “Войти”, вводим емейл из запроса, пароль из запроса, проверяем авторизацию.
Остальные тесты
Уникальный емейл, дубликат имени
"email": "milli{{$randomInt}}@mail.ru",
В теле ошибка: "name (переданное имя) уже есть в базе"
Уникальное имя, дубликат емейл
"name": " Машенька{{$randomInt}}",
В теле ошибка: "email (переданный email) уже есть в базе"
В теле ошибка: "email (переданный email) уже есть в базе"
Корректный существующий email, куда может прийти почта — подставляем свой (начинаем всегда с корректного)
Верхний регистр, цифры в имени пользователя и доменной части — TEST77@mail9.ru
Email с дефисами и нижним подчеркиванием — test_user-1@mail_test-1.com
Email с точками в имени пользователя и парой точек в доменной части — test.user@test.test.test.ru
Email без точек в доменной части — test@mailcom
Статус 400, ошибка «email некорректный»
Превышение длины email (>320 символов)
Статус 400, ошибка «email некорректный»
Отсутствие @ в email — testmail.ru
Статус 400, ошибка «email некорректный»
Email с пробелами в имени пользователя — test user@mail.ru
Статус 400, ошибка «email некорректный»
Email с пробелами в доменной части — test@ma il.ru
Статус 400, ошибка «email некорректный»
Email без имени пользователя — @mail.ru
Статус 400, ошибка «email некорректный»
Email без доменной части — test@
Статус 400, ошибка «email некорректный»
Некорректный домен первого уровня (допустимо 2-6 букв после точки: .ru) — test@mail.urururururu
Статус 400, ошибка «email некорректный»
Разный регистр, буквы и спецсимволы:
Mixa1234567890`-=[]\;’/.,~!@#$%^&*()_+}{:”?><|Ё_+ХЪ/ЖЭБЮ,ёхъ\-=.
1 000 символов — ищем верхнюю границу, если она есть. Заодно смотрим, как это выглядит в интерфейсе и корректируем тест.
1 000 000 символов — ищем технологическую границу
Ошибка 400 — «Имя слишком длинное. Максимальная длина (такая-то)»
Разный регистр, буквы и спецсимволы:
Mixa1234567890`-=[]\;’/.,~!@#$%^&*()_+}{:”?><|Ё_+ХЪ/ЖЭБЮ,ёхъ\-=.
1 000 символов — ищем верхнюю границу, если она есть. Заодно смотрим, как это выглядит в интерфейсе и корректируем тест.
Успешный запрос, пароль обрезается до X символов
1 000 000 символов — ищем технологическую границу
Успешный запрос, пароль обрезается до X символов
Перестановка мест слагаемых в json
"name": " Машенька{{$randomInt}}",
"email": "test{{$randomInt}}@mail.com",
Перестановка мест слагаемых в form-data
Меняем регистр у любого параметра:
"email": "test{{$randomInt}}@mail.com",
"NAME": " Машенька{{$randomInt}}",
Меняем в запросе тип метода с POST на GET
Статус 400, ошибка «Неправильный тип метода, нужно использовать POST»
Запятая после последней пары «ключ:значение»:
"email": "test{{$randomInt}}@mailcom",
"name": " Машенька{{$randomInt}}",
В теле ошибка: "Не well formed json в запросе"
Запрос не в виде пар “ключ:значение”, у пароля убираем значение:
"email": "test{{$randomInt}}@mail.com",
"name": " Машенька{{$randomInt}}",
В теле ошибка: "Не well formed json в запросе"
"email": "test{{$randomInt}}@mail.com"
"name": " Машенька{{$randomInt}}"
В теле ошибка: "Не well formed json в запросе"
объект в квадратных скобках, а не фигурных
"email": "test{{$randomInt}}@mail.com",
"name": " Машенька{{$randomInt}}",
В теле ошибка: "Не well formed json в запросе"
Вывод
Тестирование API — это не страшно! По факту это всё то же самое, что в GUI + дополнительные тесты. В интерфейсе нельзя подвигать местами поля или изменить название поля. А в API можно.
Но всегда в первую очередь важен тест-дизайн. Прочитайте ТЗ и проверьте его, учитывая классы эквивалентности и граничные значения. А потом добавьте API-часть: