Утомленные Telecom Data Cup'ом
Недавно закончилось соревнование по Machine Learning "Telecom Data Cup", где Data Science'ы со всей РФ скорами мерялись. Стоит сказать, что закончилось оно чуточку раньше, просто во время сессии не было времени собраться с мыслями, от слова совсем. Но сейчас...

В общем, надёжно(но это не точно) окопавшись около ТОП ~10%, 55 (+/- 5) из 535, постараюсь кратко обобщить свой 3-ёх недельный опыт и рассказать, как вот это делать надо и, что более важнее, как это делать ну вот совсем не надо, если после публикации на привате очень не хочется искать себя за ТОП 300.

Ссылочка тут, кому надо, тот меня сдеанонит.
https://mlbootcamp.ru/round/15/rating/
Ладно, поехали. ТОП 5 советов, как ЭТО надо делать:
- Здравый смысл
Некоторые считают, что для предсказательной модели сгодится всё. Именно поэтому в алгоритм попадает овер 100500 показателей, куча бессмысленно сгенерированных фич, статистики,

и много чего ещё. После всего этого, на полном серьёзе ожидается получить хорошее предсказание. Но как мы помним, "Garbage in, garbage out". Именно поэтому важно отобрать фичи с точки зрения повышения качества предсказания и наличия здравого смысла.
2. Повторение — мать учения
А кросс валидация — мать хорошего предсказания. Именно поэтому нужно валидировать предсказание, чтобы избежать "подгона" под данные и долгого падения на привате.

Он не послушал маму, а ты?
3. Куй железо, пока горячо
Лучше сразу вступить в контест, не стоит откладывать это дело. Ибо потом в отсутствии времени и попыток не будет шанса проверить годные идеи. Если нужен относительно хороший топ, начать нужно сразу.

4. Feature engineering наше всё
Алгоритмы, конечно, вещь хорошая, но хорошо отобранные и с умом сгенерированные фичи — лучше. Стоит акцентировать своё внимание именно на них.

5. Till the end
Ну и последним, как символично, будет совет, пытаться до последнего. До последнего дня и до последней попытки. Свой лучший скор я получил именно в последний день

Как-то так. Вообще стоит сказать, что советы, как ЭТО не надо делать, вытекают из вышесказанного.
- Больше не лучше
Самое лучшее решение на паблике(общедоступной тестовой выборки), может ну ооочень сильно отличаться от привата(оценочной тестовой выборки). И скорее всего, самое лучшее решение, это решение, подстроенное под паблик. Лучше взять наибольшее решение из тех, что экспериментально вы смогли повторить. Вы что... хотите как в Ук.. то есть как в таблице ниже?
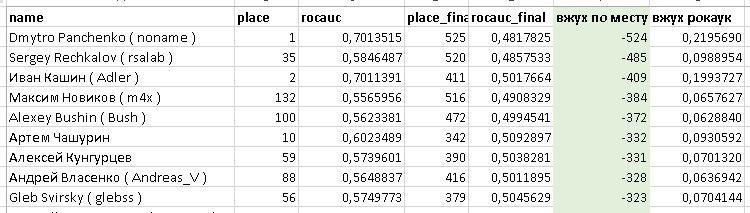
2. Таргет вон
Важно при генерации фич не допускать утечки целевой переменной в входные данные и не генерировать фичи на основе её. К примеру, не стоит пилить фичу "средняя удовлетворенность связью по регионам". Это гарантировать вызовет у модели переобучение, а у вас депрессию. И кому это надо?

3. Never lose hope
Соревнование по Machine Learning это не пробежка по стадиону. Это долго и выматывает, особенно морально. Ну т.е. обобщая, это долго вымывает... Важно не поддаваться моральному упадку, а продолжать работу.

4. Код НАААААДАААА?
Не стоит нагромождать решение огромными кусками кода. Со временем в ходе чемпионата, его сложно переписывать. Лучше сразу оформлять всё функциями и членораздельно. Да, на это не смотрят, но это важно.
5. Синдром Coursera
Это не совсем относится к ML чемпионатам, но важно помнить, что ни курсы на курсере, ни пары по ML не дадут вам таких знаний, как практическая задача любого контеста. Может быть стоит перераспределить затраченное время?

В общем, как-то так.
P.S. Это не претендует на объективность, правильность и т.д. Будем считать это попыткой осмысления первого серьёзного ML контеста. Всем мир... By Memphis