Возможные будущие развития протокола Ethereum. Часть 2: Прилив aka The Surge

Первая часть
См.: teletype.in/@menaskop/menaskop-ethereum-roadmap-2024-01.
Перевод
Это вольный перевод второй части большого исследования В. Бутерина: vitalik.eth.limo/general/2024/10/17/futures2.html.
Введение ко 2-й части
(Выражаю) особую благодарность Justin Drake, Hsiao-wei Wang, @antonttc, Anders Elowsson and Francesc за отзывы и рецензирование.
Изначально в дорожной карте Ethereum было две стратегии масштабирования. Первая (см., например, эту раннюю статью 2015 года) — это «шардинг»: вместо того чтобы каждый узел проверял и хранил все транзакции в чейне, каждый узел должен был проверять и хранить лишь небольшую часть транзакций.
Это похоже на то, как работают другие одноранговые сети (например, BitTorrent), поэтому, конечно, мы могли бы заставить блокчейны работать аналогично.
Вторая стратегия — протоколы второго уровня (L2): сети, которые располагаются поверх Ethereum, что позволяет им в полной мере пользоваться его безопасностью, при этом большая часть данных и вычислений остается за пределами основной цепочки.
В 2015 году под «протоколами второго уровня» подразумевались state channels, в 2017 году — Plasma, а в 2019 году появились rollups.
Rollups оказались более мощным решением по сравнению со state channels и Plasma, однако требуют значительных объёмов пропускной способности на основном чейне для хранения данных.
К счастью, к 2019 году исследования по шардингу решили проблему проверки «доступности данных» в (нужных) масштабах. В результате оба пути слились, и мы получили дорожную карту, ориентированную на rollups, которая остаётся стратегией масштабирования Ethereum и сегодня.

The Surge, издание дорожной карты на 2023 год
Дорожная карта, ориентированная на rollups, предлагает простое распределение обязанностей: Ethereum L1 сосредоточен на том, чтобы быть надёжным и децентрализованным базовым уровнем, в то время как L2 выполняют задачу масштабирования экосистемы.
Это структура, которую видим повсюду в обществе: судебная система (L1) не предназначена для максимальной скорости и эффективности, она существует для защиты договоров и прав собственности, а предприниматели (L2) строят на этой прочной основе и ведут человечество к (метафорическому и буквальному) Марсу.
В этом году ориентированная на rollups дорожная карта достигла важных успехов: пропускная способность данных Ethereum L1 значительно увеличилась с введением EIP-4844, и несколько EVM-rollups теперь находятся на первом этапе.
Реальностью стала очень разнородная и плюралистическая реализация шардинга, где каждый L2 выступает в роли «шарда» со своими внутренними правилами и логикой.
Но, как мы увидели, этот путь несёт в себе и уникальные вызовы. Наша задача теперь — довести дорожную карту, ориентированную на rollups, до завершения, решая возникающие проблемы, сохраняя при этом надежность и децентрализацию, которые делают Ethereum L1 особенным.
The Surge: ключевые цели
- 100,000+ TPS на L1+L2;
- Сохранение децентрализации и надёжности L1;
- Чтобы хотя бы некоторые L2 полностью унаследовали основные свойства; Ethereum (доверие без посредников, открытость, устойчивость к цензуре);
- Максимальная интероперабельность между L2: Ethereum должен ощущаться как единая экосистема, а не 34 разных блокчейна.
- Трилемма масштабируемости
- Дальнейший прогресс в выборочной проверке доступности данных
- Сжатие данных
- Обобщённая Plasma
- Развитие систем доказательств L2
- Улучшение интероперабельности между L2 и пользовательского опыта
- Масштабирование исполнения на L1
Трилемма масштабируемости
Трилемма масштабируемости — концепция, предложенная в 2017 году, которая утверждает, что существует напряжение между тремя свойствами блокчейна: децентрализацией (в частности: низкой стоимостью запуска узла), масштабируемостью (в частности: большим количеством обрабатываемых транзакций) и безопасностью (в частности: необходимостью для злоумышленника скомпрометировать значительную часть узлов в сети, чтобы даже одна транзакция потерпела неудачу).
(Схематично это выглядит так):

Важно отметить, что трилемма масштабируемости — не теорема, и пост, в котором она была представлена, не сопровождался математическим доказательством. Он предлагал эвристический математический аргумент: если дружественный к децентрализации узел (например, потребительский ноутбук) может проверять N транзакций в секунду, и у нас есть цепочка, обрабатывающая k*N транзакций в секунду, то либо (i) каждая транзакция видна только (для) 1/k узлов, что позволяет злоумышленнику, взломав всего несколько узлов, провести нежелательную транзакцию, либо (ii) узлы будут очень мощными, и цепочка перестанет быть децентрализованной.
Цель поста состояла не в том, чтобы доказать невозможность преодоления трилеммы, а в том, чтобы показать, что преодоление трилеммы сложно — для этого нужно думать вне рамок предполагаемой модели.
На протяжении многих лет некоторые высокопроизводительные блокчейны утверждали, что решают трилемму без принципиальных изменений в архитектуре, обычно за счёт использования программных трюков для оптимизации узлов. Это всегда вводит в заблуждение, так как запуск узла в таких сетях оказывается значительно сложнее, чем в Ethereum.
Этот пост объясняет многие тонкости, почему это так (и, соответственно, почему одного лишь программного обеспечения L1 недостаточно для масштабирования самого Ethereum).
Однако комбинация выборочной проверки доступности данных и SNARK-доказательств действительно решает трилемму: она позволяет клиенту убедиться, что определенный объем данных доступен и что определённые вычисления были выполнены корректно, при этом загружая только небольшую часть данных и выполняя существенно меньший объем вычислений.
SNARK-доказательства не требуют доверия. Выборочная проверка доступности данных имеет более сложную модель доверия «несколько из N», но она сохраняет основное свойство не масштабируемых сетей — даже 51% атака не может привести к принятию сети вредоносных блоков.
Другой способ решения трилеммы — архитектура Plasma, которая использует изощрённые методы, чтобы возложить ответственность за проверку доступности данных на пользователя в совместимой с его интересами форме.
В 2017-2019 годах, когда для масштабирования вычислений у нас были только доказательства мошенничества, Plasma была ограничена в том, что она могла делать безопасно, но благодаря широкому распространению SNARK-доказательств архитектуры Plasma стали гораздо более применимы для различных сценариев, чем раньше.
Дальнейший прогресс в выборочной проверке доступности данных
Какую проблему мы решаем?
С 13 марта 2024 года, после обновления Dencun, в блокчейне Ethereum в каждом 12-секундном слоте доступны три ~125-килобайтных «блоба», что даёт ~375 кБ пропускной способности данных в каждом слоте.
Если предположить, что данные транзакций публикуются непосредственно ончейн, то для перевода ERC-20 требуется примерно 180 байт, а это значит, что максимальный TPS для rollups в Ethereum составляет:
Если добавить текущие данные Ethereum (теоретический максимум: 30 миллионов газа на слот / 16 газа за байт = 1,875,000 байт на слот), то это даст 607 TPS.
С PeerDAS планируется увеличить целевой объём блобов до 8-16, что обеспечит 463-926 TPS в виде данных.
Это значительный прирост по сравнению с L1 Ethereum, но его недостаточно. Наша цель — значительно увеличить масштабируемость. В среднесрочной перспективе мы нацелены на 16 МБ на слот, что в сочетании с улучшениями в сжатии данных для rollups может дать ~58,000 TPS.
Что это такое и как это работает?
PeerDAS — относительно простая реализация «одномерной выборочной проверки».
Каждый блоб в Ethereum представлен полиномом степени 4096 над простым полем размером 253 бита. Мы передаем «доли» полинома, где каждая доля состоит из 16 вычислений на смежных 16 координатах, выбранных из общего набора из 8192 координат. Любые 4096 из 8192 вычислений (в текущих предложенных параметрах: любые 64 из 128 возможных выборок) могут восстановить блоб.
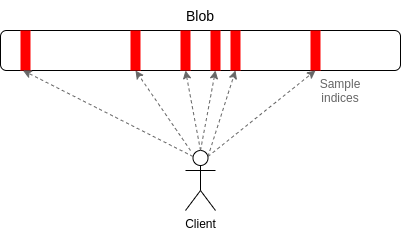
PeerDAS работает так: каждый клиент прослушивает небольшое количество подсетей, где i-я подсеть транслирует i-ю выборку любого блоба, а также запрашивает нужные блобы из других подсетей у своих пиров в глобальной p2p-сети (которые прослушивают другие подсети).
Более консервативная версия, SubnetDAS, использует только механизм подсетей, без дополнительного слоя запросов к пирами. По текущему предложению, узлы, участвующие в proof of stake, будут использовать SubnetDAS, а остальные узлы (то есть «клиенты») — PeerDAS.
Теоретически, можем довольно далеко масштабировать одномерную выборочную проверку: если увеличить максимальное число блобов до 256 (а целевой показатель до 128), то мы достигнем целевых 16 МБ, при этом выборочная проверка доступности данных будет стоить каждому узлу 16 выборок * 128 блобов * 512 байт на выборку на блоб = 1 МБ пропускной способности данных на слот. Это близко к предельной допустимой нагрузке: выполнимо, но это значит, что клиенты с ограниченной пропускной способностью не смогут проводить выборку.
Мы могли бы оптимизировать это, уменьшая количество блобов и увеличивая их размер, но это сделало бы восстановление данных более дорогостоящим.
Поэтому в конечном итоге мы стремимся пойти дальше и перейти к двумерной выборочной проверке, которая предполагает случайную выборку не только внутри блобов, но и между ними.
Линейные свойства KZG-коммитментов позволяют «расширить» набор блобов в блоке, добавляя список новых «виртуальных блобов», которые избыточно кодируют ту же информацию.

Ключевым моментом является то, что вычисление расширения коммитментов не требует наличия самих блобов, что делает схему дружелюбной к распределенному построению блоков. Узел, фактически создающий блок, нуждается только в коммитментах KZG блобов и может сам полагаться на DAS для проверки доступности блобов.
Одномерная выборочная проверка DAS также по своей природе совместима с распределенным построением блоков.
Ссылки на существующие исследования
- Оригинальный пост о доступности данных (2018): ссылка
- Дополнительная статья: arxiv.org
- Пост-объяснение DAS на Paradigm: ссылка
- Двумерная доступность с KZG-коммитментами: ethresear.ch
- PeerDAS на ethresear.ch и статья
- Презентация PeerDAS от Франческо: на YouTube
- EIP-7594: eips.ethereum.org
- SubnetDAS на ethresear.ch
- Нюансы восстановления данных в двумерной выборочной проверке: ethresear.ch
Что нужно сделать и какие существуют компромиссы?
Следующий шаг — завершить реализацию и внедрение PeerDAS. После этого потребуется постепенное увеличение числа блобов в PeerDAS с тщательным контролем сети и улучшением программного обеспечения для обеспечения безопасности.
Одновременно мы хотим провести больше академических исследований по формализации PeerDAS и других версий DAS и их взаимодействию с такими аспектами, как безопасность правила выбора форков.
В будущем потребуется больше исследований для определения идеальной версии двумерной DAS и доказательства её свойств безопасности. Также в перспективе мы хотим перейти от KZG к квантово-устойчивой альтернативе без необходимости доверенной настройки.
На данный момент нет кандидатов, совместимых с распределённым построением блоков. Даже дорогая техника «грубой силы» (брутфорса) с использованием рекурсивных STARK для генерации доказательств достоверности для восстановления строк и столбцов не подходит, так как на практике STARK по размеру почти равен целому блобу.
Реалистичные долгосрочные пути, которые вижу:
- Реализовать идеальную двумерную DAS;
- Оставить одномерную DAS, жертвуя эффективностью пропускной способности выборки и принимая более низкий лимит данных ради простоты и надёжности;
- (Резкий поворот) отказаться от DA и полностью сосредоточиться на Plasma как основной архитектуре второго уровня.
Эти варианты можно рассматривать как спектр компромиссов.

Обратите внимание: такой выбор остаётся актуальным даже в случае, если решим масштабировать выполнение операций непосредственно на L1. Это объясняется тем, что если L1 будет обрабатывать большое количество TPS, блоки L1 станут очень большими, и клиентам понадобится эффективный способ проверки их корректности. Для этого потребуется использовать ту же технологию, которая применяется в rollups (ZK-EVM и DAS) на уровне L1.
Как это взаимодействует с другими частями дорожной карты?
Необходимость в 2D DAS частично снижается или, по крайней мере, откладывается, если будет внедрено сжатие данных (см. ниже), и ещё сильнее снижается, если Plasma получит широкое распространение.
DAS также создаёт вызов для протоколов и механизмов распределенного построения блоков: хотя DAS теоретически подходит для распределенного восстановления, на практике это должно быть интегрировано с предложениями по спискам включения и их правилами выбора форков.
Сжатие данных
Какую проблему мы решаем?
Каждая транзакция в rollup занимает значительное количество места в блокчейне: например, перевод ERC-20 требует около 180 байт. Даже с оптимальной выборочной проверкой доступности данных это ограничивает масштабируемость протоколов второго уровня. При 16 МБ на слот мы получаем:
16000000 / 12 / 180 = 7407 TPS
А что, если, помимо оптимизации числителя, мы сможем также оптимизировать знаменатель, уменьшая количество байт для каждой транзакции в rollup на цепочке?
Что это такое и как это работает?
Лучше всего это объясняет следующая диаграмма двухлетней давности:

Самые простые улучшения — сжатие нулевых байт: замена каждой длинной последовательности нулей на два байта, которые обозначают количество этих нулей. Чтобы пойти дальше, мы используем особые свойства транзакций:
Агрегация подписей — переход от подписей ECDSA к подписям BLS, которые позволяют объединить несколько подписей в одну, подтверждающую корректность всех исходных подписей.
Хотя это не рассматривается для L1 из-за высокой вычислительной нагрузки при проверке даже с учётом агрегации, в условиях дефицита данных на L2 это имеет смысл. Одним из способов реализации такой агрегации является использование функционала ERC-4337.
Замена адресов указателями — если адрес уже использовался, можно заменить 20-байтный адрес на 4-байтный указатель на позицию в истории. Это позволяет добиться значительного сокращения данных, хотя и требует усилий для реализации, так как часть истории блокчейна должна стать частью состояния.
Кастомная сериализация значений транзакций — большинство значений транзакций имеют небольшое количество знаков, например, 0.25 ETH представляется как 250,000,000,000,000,000 wei. Максимальные значения газовой комиссии и приоритетной комиссии также имеют похожий вид. Таким образом, можем представлять большинство валютных значений более компактно, используя собственный десятичный формат с плавающей запятой или словарь наиболее часто встречающихся значений.
Какие существуют ссылки на текущие исследования?
- Исследование от sequence.xyz
- Контракты с оптимизированной calldata для L2 от ScopeLift: L2-optimizoooors
- Альтернативная стратегия - rollups на основе доказательств корректности (т.н. ZK-rollups), которые размещают отличия в состоянии вместо транзакций: Rollup diff compression
- BLS-кошелек - реализация агрегации BLS через ERC-4337
Что ещё нужно сделать и какие существуют компромиссы?
Основное, что предстоит сделать, — это реализовать указанные выше схемы.
Основные компромиссы включают:
- Переход на подписи BLS требует значительных усилий и снижает совместимость с доверенными аппаратными модулями безопасности. Обёртка ZK-SNARK может заменить этот метод.
- Динамическое сжатие (например, замена адресов указателями) усложняет код клиентов.
- Публикация изменений состояния вместо транзакций снижает возможности аудита и нарушает работу многих программ, таких как обозреватели блоков.
Как это взаимодействует с другими частями дорожной карты?
Принятие ERC-4337 и, в конечном итоге, закрепление его элементов в L2 EVM может ускорить внедрение методов агрегации. Закрепление частей ERC-4337 на L1 также может ускорить его внедрение на L2.
Универсальная Plasma
Какую проблему мы решаем?
Даже с 16 МБ блоков и сжатием данных 58,000 TPS может не быть достаточно для охвата массовых платежей, децентрализованных социальных сетей и других областей с высокой пропускной способностью.
Это особенно важно, если учитывать конфиденциальность, которая может снизить масштабируемость в 3-8 раз. Для приложений с большим объёмом и низкой ценностью данных, validium — решение, где данные хранятся вне цепи и при этом оператор не может украсть средства пользователей. Но мы можем сделать лучше.
Что такое Plasma и как она работает?
Plasma — решение для масштабирования, где оператор публикует блоки вне цепи, добавляя Merkle-корни этих блоков в блокчейн (в отличие от rollups, где весь блок публикуется в цепи).
Для каждого блока оператор отправляет каждому пользователю Merkle-ветвь, подтверждающую операции с активами пользователя. Пользователи могут вывести свои активы, предоставив Merkle-ветвь.
Важно, что эта ветвь не обязательно должна быть из последнего состояния — если доступность данных нарушена, пользователь все равно может вывести активы, используя последнее доступное состояние. Если пользователь подаёт недействительную ветвь, механизм оспаривания в блокчейне решает, кому принадлежат активы.
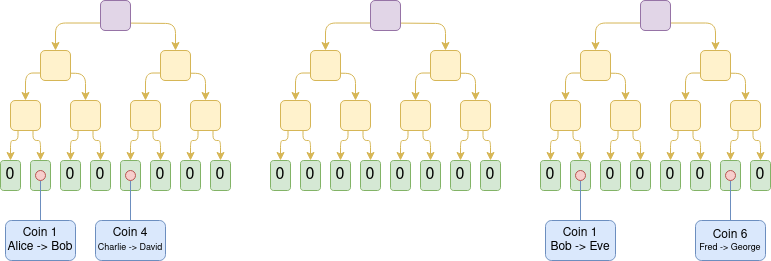
Ранние версии Plasma были способны работать только с примером платежей и не могли эффективно обобщать его. Однако если потребуем, чтобы каждый корень был проверен с помощью SNARK, Plasma станет намного мощнее. Каждая игра-испытание может быть значительно упрощена, поскольку убираем большинство возможных путей обмана для оператора. Кроме того, открываются новые пути, позволяющие распространить методы Plasma на гораздо более общий класс активов. Наконец, в случае, если оператор не жульничает, пользователи могут вывести свои средства мгновенно, не дожидаясь недельного периода вызова.

Одна из ключевых идей заключается в том, что система Plasma не обязательно должна быть идеальной. Даже если она защищает только часть активов (например, монеты, которые не перемещались за последнюю неделю), это уже значительно улучшает статус-кво сверх-масштабируемого EVM, что представляет собой validium.
Другой класс решений включает гибридные конструкции Plasma/rollups, такие как Intmax.
В этих конструкциях минимальный объём данных на пользователя записывается в цепочку (например, 5 байт), что позволяет получить свойства, находящиеся между Plasma и rollups. В случае Intmax обеспечивается высокая масштабируемость и конфиденциальность, хотя при 16 МБ предельная теоретическая пропускная способность составляет около 266,667 TPS (16,000,000 / 12 / 5).
Какие существуют ссылки на текущие исследования?
Что ещё нужно сделать и какие существуют компромиссы?
Основная задача — довести системы Plasma до промышленного использования. Как упоминалось, "plasma против validium" — не бинарный выбор: безопасность validium можно повысить, добавив элементы Plasma в механизм выхода. Исследования сосредоточены на достижении оптимальных свойств (по требованиям доверия, затратам на газ на L1 в худшем случае и уязвимости к атакам типа DoS) для EVM, а также на разработке приложений для конкретных сценариев.
Также необходимо упростить Plasma, поскольку она более концептуально сложна по сравнению с rollups.
Основной компромисс при использовании дизайнов Plasma в том, что они зависят от операторов и сложнее для полной децентрализации, хотя гибридные конструкции Plasma/rollup могут избежать этого недостатка.
Как это взаимодействует с другими частями дорожной карты?
Чем более эффективны решения Plasma, тем меньше давления на необходимость высокой производительности доступности данных на L1. Перемещение активности на L2 также снижает давление MEV на L1.
Созревание систем доказательств для L2
Какую проблему мы решаем?
На сегодняшний день большинство rollups ещё не являются полностью бездоверительными; у совета по безопасности есть возможность изменять поведение системы доказательств…
В некоторых случаях система доказательств вообще неактивна или работает лишь в качестве «консультативной».
Больше всего продвинулись (i) несколько специфических rollups, таких как Fuel, которые уже бездоверительны, и (ii) на момент написания этого текста, Optimism и Arbitrum, два rollups, поддерживающие полный EVM, достигшие промежуточной стадии бездоверительности, называемой «стадия 1».
Основной причиной отсутствия дальнейшего развития является опасение ошибок в коде. Мы нуждаемся в полностью бездоверительных rollups, и поэтому должны активно решать эту проблему.
Что это такое и как работает?
Для начала напомним о системе «стадий», впервые описанной в другом посте.
Существует более подробная структура требований, но в кратком виде она выглядит так:
- Стадия 0: должна существовать возможность для пользователя запустить узел и синхронизировать цепочку. Допускается полное доверие/централизация валидации.
- Стадия 1: должна быть (бездоверительная) система доказательств, которая гарантирует принятие только валидных транзакций. Допускается наличие совета по безопасности, который может вмешиваться в систему доказательств, но только с порогом голосов в 75%. При этом более 26% голосующих членов совета должны быть вне основной компании, разрабатывающей rollup. Также допускается механизм обновления с более слабыми функциями (например, DAO), но с достаточной задержкой, чтобы пользователи могли вывести свои средства до активации вредоносного обновления.
- Стадия 2: должна быть (бездоверительная) система доказательств, гарантирующая принятие только валидных транзакций. Совет безопасности может вмешиваться только в случае доказуемых ошибок в коде, например, если две независимые системы доказательств выдают разные результаты для одного и того же блока или не выдают результатов длительное время (например, неделю). Механизм обновления допускается, но должен иметь очень длительную задержку.
Цель — достичь стадии 2. Основная сложность заключается в том, чтобы убедиться, что система доказательств достаточно надёжна. Существует два основных подхода для этого:
- Формальная проверка: современные математические и вычислительные методы позволяют доказать, что система доказательств (оптимистическая или проверочная) принимает только блоки, соответствующие спецификации EVM. Эти техники существуют уже десятилетия, но последние достижения, такие как Lean 4, сделали их более практичными, а развитие ИИ-ассистированных систем доказательств может ещё больше ускорить этот процесс.
- Множественные доказательства (multi-provers): можно создать несколько систем доказательств и задействовать мультиподпись (например, 2 из 3) между ними и советом по безопасности (и/или другими доверенными механизмами, такими как TEE). Если системы доказательств соглашаются, у совета безопасности нет полномочий; если возникают разногласия, совет может выбрать только один из них, но не может ввести собственный результат.

Какие есть ссылки на существующие исследования?
- EVM K Semantics (работа по формальной верификации от 2017 года): https://github.com/runtimeverification/evm-semantics
- Презентация идеи мультипроверочных систем (2022 год): https://www.youtube.com/watch?v=6hfVzCWT6YI
- Taiko планирует использовать мультипровера: https://docs.taiko.xyz/core-concepts/multi-proofs/
Что остается сделать, и каковы компромиссы?
Для формальной верификации (требуется) многое. Нам нужно создать формально верифицированную версию всего SNARK-провера EVM. Это невероятно сложный проект, хотя мы к нему уже приступили.
Есть один трюк, который значительно упрощает задачу: мы можем сделать формально верифицируемый SNARK-проверщик минимальной ВМ, например RISC-V или Cairo, а затем написать реализацию EVM в этой минимальной ВМ (и формально доказать её эквивалентность какой-либо другой спецификации EVM).
Для многопроцессорных систем остаются два основных момента.
Во-первых, нам нужно получить достаточную уверенность по крайней мере в двух разных системах доказательства, как в том, что они достаточно безопасны по отдельности, так и в том, что если они сломаются, то по разным и несвязанным причинам (и поэтому они не сломаются одновременно).
Во-вторых, нам нужно получить очень высокий уровень гарантии в базовой логике, которая объединяет системы доказательств. Это гораздо меньший кусок кода. Есть способы сделать его чрезвычайно маленьким - просто хранить средства в безопасном мультисигнальном контракте, подписывающими сторонами которого являются контракты, представляющие отдельные системы доказательств, - но это связано с большими затратами на газ на цепи.
Необходимо найти некий баланс между эффективностью и безопасностью.
Как это взаимодействует с другими частями дорожной карты?
Перемещение активности в L2 снижает давление MEV на L1.
Улучшение совместимости между L2 и другими устройствами
Какую проблему мы решаем?
Одна из основных проблем современной экосистемы L2 заключается в том, что пользователям сложно в ней ориентироваться. Более того, самые простые способы сделать это часто вновь вводят предположения о доверии: централизованные мосты, клиенты RPC и так далее.
Если серьёзно относимся к идее о том, что L2 - часть Ethereum, нам нужно сделать так, чтобы использование экосистемы L2 было похоже на использование единой экосистемы Ethereum.

Что это такое и как это работает?
Существует множество категорий улучшений кросс-L2 совместимости. В общем случае, для их определения нужно заметить, что в теории Ethereum, ориентированный на роллапы, - то же самое, что и шардинг выполнения L1, а затем спросить, в чём текущая L2-версия Ethereum не соответствует этому идеалу на практике. Вот несколько из них:
- Адреса, специфичные для цепочек: цепочка (L1, Optimism, Arbitrum...) должна быть частью адреса. Как только это будет реализовано, кросс-L2 потоки отправки можно будет реализовать, просто поместив адрес в поле «отправить», и тогда кошелек сможет понять, как сделать отправку (включая использование протоколов мостов) в фоновом режиме.
- Запросы на оплату по конкретной цепочке: должно быть легко и стандартизировано сделать сообщение вида «пришлите мне X токенов типа Y по цепочке Z». Это имеет два основных сценария использования: (i) платежи, будь то от человека к человеку или от человека к продавцу, и (ii) dapps, запрашивающие средства, например, пример Polymarket выше.
- Межцепочечные свопы и газовые платежи: должен существовать стандартизированный открытый протокол для выражения межцепочечных операций, таких как «Я отправляю 1 ETH на Optimism тому, кто отправит мне 0,9999 ETH на Arbitrum», и «Я отправляю 0,0001 ETH на Optimism тому, кто включит эту транзакцию на Arbitrum». ERC-7683 - одна из попыток первого варианта, а RIP-7755 - второго, хотя оба варианта являются более общими, чем просто эти конкретные случаи использования.
- Лёгкие клиенты: пользователи должны иметь возможность реально проверять цепочки, с которыми они взаимодействуют, а не просто доверять RPC-провайдерам. Helios от A16z crypto делает это для самого Ethereum, но нам нужно распространить эту недоверчивость на L2. ERC-3668 (CCIP-read) - одна из стратегий для этого.
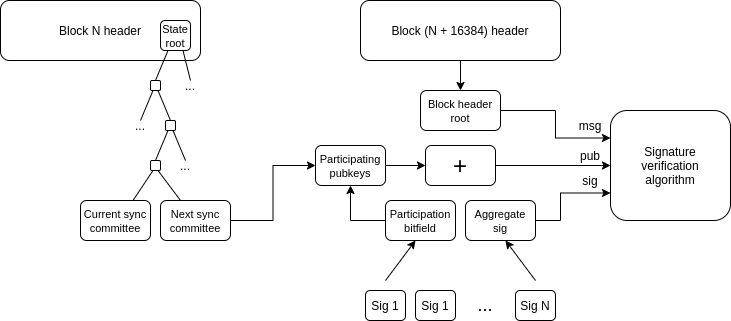
Как только у вас есть цепочка заголовков, вы можете использовать Меркл- доказательства для проверки любого объекта состояния. А когда у вас есть нужные объекты состояния на L1, вы можете использовать доказательства Меркла (и, возможно, подписи, если хотите проверить предварительные подтверждения) для проверки любого объекта состояния на L2. Helios уже делает первое. Расширение на второе - задача стандартизации.
- Кошельки с хранилищем ключей: сегодня, если хотите обновить ключи, управляющие кошельком смарт-контракта, вам придётся делать это на всех N цепочках, на которых этот кошелек существует. Кошельки-хранилища ключей - это техника, которая позволяет ключам существовать в одном месте (либо на L1, либо позже, потенциально, на L2), а затем считываться с любого L2, где есть копия кошелька. Это означает, что обновление должно происходить только один раз. Чтобы быть эффективными, кошельки keystore требуют, чтобы L2 имели стандартизированный способ без затрат считывать L1; два предложения для этого - L1SLOAD и REMOTESTATICCALL.

- Более радикальные идеи «совместного токен-моста»: представьте себе мир, в котором все L2 - ролловеры с доказательством действительности, которые фиксируют Ethereum в каждом слоте. Даже в таком мире перемещение активов из одного L2 в другой L2 «нативно» потребует снятия и внесения средств, что требует оплаты значительного количества газа L1. Один из способов решить эту проблему - создать общий минимальный роллап, единственной функцией которого будет поддержание балансов того, сколько токенов того или иного типа принадлежит тому или иному L2, и позволить этим балансам массово обновляться серией кросс-L2 операций отправки, инициированных любым из L2. Это позволит осуществлять кросс-L2 переводы без необходимости платить L1 газ за перевод и без использования технологий, основанных на поставщиках ликвидности, таких как ERC-7683.
- Синхронная совместимость: позволяет осуществлять синхронные вызовы как между конкретными L2 и L1, так и между несколькими L2. Это может быть полезно для повышения финансовой эффективности протоколов DeFi. Первое может быть сделано без какой-либо координации между L2; второе потребует совместного секвенирования. Основанные роллапы автоматически становятся дружественными ко всем этим методам.
Каковы некоторые ссылки на существующие исследования?
- Адреса конкретных цепочек: ERC-3770: eips.ethereum.org/EIPS/eip-3770
- ERC-7683: eips.ethereum.org/EIPS/eip-7683
- RIP-7755: github.com/wilsoncusack/RIPs/blob/cross-l2-call-standard/RIPS/rip-7755.md
- Дизайн кошелька Scroll Keystore: hackmd.io/@haichen/keystore
- Helios: github.com/a16z/helios
- ERC-3668 (иногда называемый CCIP-read): eips.ethereum.org/EIPS/eip-3668
- Предложение по «основанным (общим) предварительным подтверждениям» от Джастина Дрейка: ethresear.ch/t/based-preconfirmations/17353
- L1SLOAD (RIP-7728): ethereum-magicians.org/t/rip-7728-l1sload-precompile/20388
- REMOTESTATICCALL в Оптимизме: github.com/ethereum-optimism/ecosystem-contributions/issues/76
- AggLayer, включающий идеи моста с общим токеном: github.com/AggLayer
Что остаётся сделать, и каковы компромиссы?
Многие из приведённых выше примеров сталкиваются со стандартной дилеммой: когда стандартизировать и какие слои стандартизировать.
Если стандартизировать слишком рано, рискуете укоренить некачественное решение. Если стандартизировать слишком поздно, рискуете создать ненужную фрагментацию.
В некоторых случаях существует как краткосрочное решение, которое обладает более слабыми свойствами, но его легче внедрить, так и долгосрочное решение, которое «в конечном итоге будет правильным», но на его реализацию уйдёт несколько лет.
Уникальность этого раздела заключается в том, что эти задачи - не просто технические проблемы: они также (возможно, даже в первую очередь!) социальные проблемы. Они требуют сотрудничества L2, кошельков и L1. Наша способность успешно справиться с этой проблемой - это проверка нашей способности держаться вместе как сообщества.
Как это взаимодействует с другими частями дорожной карты
Большинство этих предложений являются конструкциями «более высокого уровня» и поэтому не сильно влияют на соображения L1. Исключением является совместное секвенирование, которое сильно влияет на MEV.
Масштабирование выполнения на L1
Какую проблему мы решаем?
Если L2 станут очень масштабируемыми и успешными, а L1 останется способным обрабатывать очень малый объём транзакций, для Ethereum может возникнуть множество рисков:
- Экономическое положение актива ETH становится более рискованным, что, в свою очередь, влияет на долгосрочную безопасность сети.
- Многим L2 выгодно быть тесно связанными с высокоразвитой финансовой экосистемой L1, и если эта экосистема сильно ослабнет, то стимул стать L2 (вместо того чтобы быть независимым L1) ослабнет.
- Пройдёт немало времени, прежде чем у L2 появятся такие же гарантии безопасности, как и у L1.
- Если L2 выйдет из строя (например, из-за злонамеренного или исчезнувшего оператора), пользователям все равно придется обращаться к L1, чтобы вернуть свои активы. Следовательно, L1 должна быть достаточно мощной, чтобы хотя бы иногда справляться с очень сложным и хаотичным сворачиванием L2.
По этим причинам важно продолжать масштабировать L1 и убедиться, что она сможет и дальше принимать все большее число пользователей.
Что это такое и как это работает?
Самый простой способ масштабирования - просто увеличить лимит газа.
Однако это чревато централизацией L1 и, соответственно, ослаблением другого важного свойства, которое делает Ethereum L1 таким мощным: доверия к нему как к надежному базовому слою.
В настоящее время ведутся споры о том, насколько устойчивым является простое увеличение лимита газа, и это также зависит от того, какие другие технологии будут внедрены, чтобы сделать большие блоки легче проверяемыми (например, истечение истории, безгражданство, доказательства достоверности L1 EVM).
Ещё одна важная вещь, которую необходимо постоянно улучшать, - эффективность клиентского программного обеспечения Ethereum, которое сегодня гораздо более оптимизировано, чем пять лет назад. Эффективная стратегия увеличения лимита газа L1 будет включать в себя ускорение этих технологий верификации.
Другая стратегия масштабирования предполагает определение конкретных функций и типов вычислений, которые можно удешевить без ущерба для децентрализации сети или ее безопасности. Примерами могут служить:
- EOF - новый формат байткода EVM, который более дружелюбен к статическому анализу, что позволяет ускорить реализацию. Байткод EOF может иметь более низкую стоимость газа, чтобы учесть эту эффективность.
- Многомерное ценообразование на газ - установление отдельных базовых ставок и лимитов для вычислений, данных и хранения может увеличить среднюю мощность Ethereum L1 без увеличения максимальной мощности (и, следовательно, создания новых рисков безопасности).
- Снижение стоимости газа для определенных опкодов и прекомпиляций - исторически сложилось так, что несколько раз увеличивали стоимость газа для определённых операций, которые были занижены, чтобы избежать атак типа «отказ в обслуживании». Чего у нас было меньше, а могло бы быть гораздо больше, так это снижения стоимости газа для операций с завышенной ценой. Например, сложение намного дешевле умножения, но стоимость опкодов ADD и MUL в настоящее время одинакова. Мы можем сделать ADD дешевле, а ещё более простые опкоды, такие как PUSH, - ещё дешевле.
- EVM-MAX и SIMD: EVM-MAX («модульные арифметические расширения») - предложение по созданию более эффективной модульной математики для больших чисел в качестве отдельного модуля EVM. Значения, вычисленные с помощью EVM-MAX, будут доступны только другим опкодам EVM-MAX, если только они не экспортируются специально; это позволяет хранить эти значения в оптимизированных форматах. SIMD («single instruction multiple data») - это предложение, позволяющее эффективно выполнять одну и ту же инструкцию над массивом значений. Эти две технологии вместе могут создать мощный сопроцессор наряду с EVM, который можно будет использовать для более эффективной реализации криптографических операций. Это было бы особенно полезно для протоколов конфиденциальности и для L2-доказательств, так что это поможет как L1-, так и L2-масштабированию.
Более подробно эти улучшения будут рассмотрены в одном из будущих постов о Splurge.
Наконец, третья стратегия - нативные роллапы (или «закрепленные роллапы»): по сути, создание множества копий EVM, которые работают параллельно, что приводит к модели, эквивалентной той, которую могут обеспечить роллапы, но гораздо более нативно интегрированной в протокол.
Какие есть ссылки на существующие исследования?
- Дорожная карта масштабирования Ethereum L1 от Polynya: polynya.mirror.xyz/epju72rsymfB-JK52_uYI7HuhJ-W_zM735NdP7alkAQ.
- Многомерное газовое ценообразование:
- vitalik.eth.limo/general/2024/05/09/multidim.html
- EIP-7706: eips.ethereum.org/EIPS/eip-7706
- EOF: evmobjectformat.org
- EVM-MAX: ethereum-magicians.org/t/eip-6601-evm-modular-arithmetic-extensions-evmmax/13168
- SIMD: eips.ethereum.org/EIPS/eip-616
- Нативные свертывания: mirror.xyz/ohotties.eth/P1qSCcwj2FZ9cqo3_6kYI4S2chW5K5tmEgogk6io1GE
- Интервью с Максом Резником о ценности масштабирования L1: x.com/BanklessHQ/status/1831319419739361321
- Джастин Дрейк об использовании SNARK и нативных роллапов для масштабирования: reddit.com/r/ethereum/comments/1f81ntr/comment/llmfi28/
Что остаётся сделать, и каковы компромиссы?
Существует три стратегии масштабирования L1, которые можно реализовывать по отдельности или параллельно:
- Улучшить технологию (например, клиентский код, клиенты без статического состояния, истечение истории), чтобы упростить проверку L1, а затем повысить предел газа.
- Удешевить отдельные операции, увеличив среднюю производительность без увеличения рисков в худшем случае.
- Нативные сворачивания (т. е. «создать N параллельных копий EVM», хотя потенциально это дает разработчикам большую гибкость в параметрах развертываемых копий).
Стоит понимать, что это разные техники, которые имеют разные компромиссы.
Например, нативные сворачивания имеют те же недостатки с точки зрения совместимости, что и обычные роллапы: вы не можете отправить одну транзакцию, синхронно выполняющую операции над многими из них, как это можно сделать с контрактами на одном L1 (или L2).
Повышение лимита газа отвлекает от других преимуществ, которые можно получить, упростив верификацию L1, например, увеличить долю пользователей, запускающих верифицирующие узлы, и увеличить количество соло-стейкеров.
Удешевление отдельных операций в EVM, в зависимости от того, как это делается, может увеличить общую сложность EVM.
Большой вопрос, на который должна ответить любая дорожная карта масштабирования L1: каково конечное видение того, что должно быть на L1 и что должно быть на L2?
Очевидно, что абсурдно всё размещать на L1: потенциальные сценарии использования исчисляются сотнями тысяч транзакций в секунду, и это сделает L1 совершенно нежизнеспособным для верификации (если только мы не пойдем по пути нативного сворачивания).
Но нам нужен какой-то руководящий принцип, чтобы мы могли убедиться, что не создадим ситуацию, когда мы увеличим лимит газа в 10 раз, сильно повредим децентрализацию Ethereum L1 и обнаружим, что пришли к миру, где вместо 99 % активности на L2, 90 % активности на L2, и поэтому результат в остальном выглядит почти так же, за исключением необратимой потери многого из того, что делает Ethereum L1 особенным:

Как это взаимодействует с другими частями дорожной карты?
Привлечение большего числа пользователей на L1 подразумевает улучшение не только масштаба, но и других аспектов L1. Это означает, что больше MEV останется на L1 (а не станет проблемой только для L2), и, следовательно, будет еще более насущная необходимость в явной обработке. Это значительно повышает ценность наличия быстрых слотов на L1.
И это также сильно зависит от того, насколько хорошо пройдёт верификация L1 («The Verge»).