Как оценивать предметы в NFT-проектах? — Часть 1

Перевод
Это вольный перевод первой из двух частей: medium.com/nftbank-ai/how-to-value-items-in-nft-projects-part-1-a87be8bcb21d.
Кратко
NFTBank предоставляет высокоточные данные оценки NFT, основываясь на сильной базовой модели.
После исследования различных проектов с невзаимозаменяемыми токенами (NFT) мы обнаружили, что, как и в случае с данной статьей, нельзя применять одну и ту же модель оценки ко всем проектам — каждому проекту нужна своя подходящая модель.
Однако, учитывая рост рынка NFT, время, необходимое для поиска идеально подходящих моделей оценки для всего рынка, увеличивается экспоненциально.
Поэтому наиболее масштабируемым подходом видим использование базовой модели, которая обладает определённым уровнем эффективности для всех NFT-проектов, одновременно улучшая как охват, так и глубину анализа.
Таким образом, предоставляем примерные цены на NFT-предметы в вашем портфеле и на рынке.
Например, на графиках ниже представлены точечные диаграммы с предсказанными и фактическими ценами за еженедельные транзакции в тестовом наборе данных (с 1 сентября 2021 года по 3 октября 2021 года) проекта Cryptopunks.
Наша базовая модель показывает ошибку прогнозирования около 9,974% по сравнению с фактической ценой транзакции в проекте Cryptopunks:
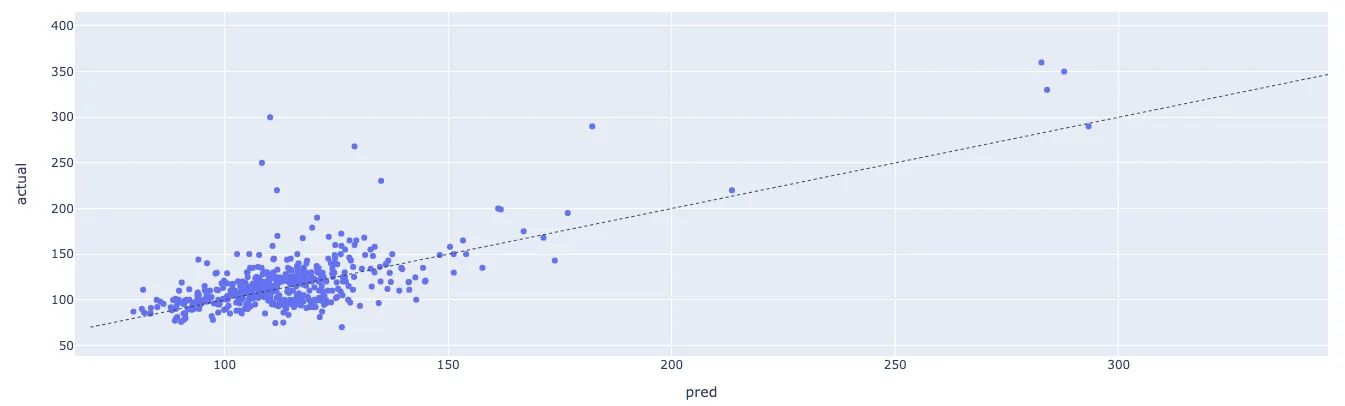
Точечная диаграмма с предсказанными и фактическими ценами (Cryptopunks MAPE: 9,974%)
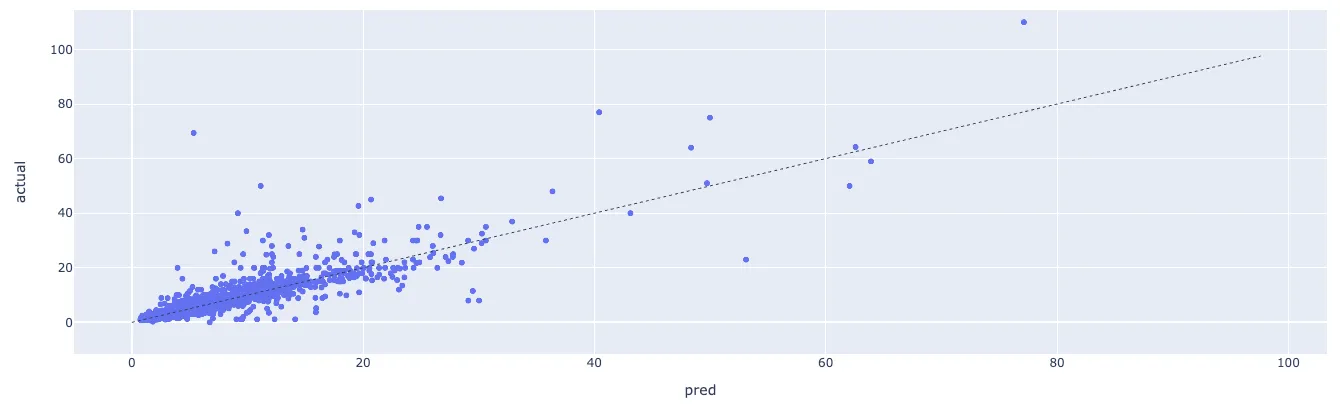
Диаграмма рассеяния с прогнозируемой и фактической ценой (Cool Cats NFTs MAPE : 10,92%)

Диаграмма рассеяния с прогнозируемой и фактической ценой (Lazy Lions MAPE : 13,65%)
В других проектах, включая проект Cryptopunks, базовая модель демонстрирует определённый уровень прогнозной эффективности (об этом будет рассказано подробнее).
Таким образом, как только данные, относящиеся к NFT-проекту, подготовлены, сначала используется базовая модель, и её производительность определяется как исходная…
Затем мы разрабатываем и создаём более сложную модель, чем базовая, чтобы получить соответствующую оценочную цену, выполняя множество итераций.
Хотите узнать больше о том, как мы разработали нашу базовую модель? Читайте дальше.
Почему оценка цен на NFT так сложна?
Как, вероятно, всем известно, резкие колебания цен и объёмов являются нормой для NFT-проектов или даже для всего рынка NFT.

Например, Bored Ape Yacht Club (BAYC) #3749 торговался за 105 ETH 16 июля и 740 ETH 6 сентября 2021 года, то есть менее чем за два месяца его стоимость выросла на 705%. Что действительно интересно, так это то, что это не (единственный) случай.
Cool cats #8875 торговался за 0,8 ETH 3 июля и 75 ETH 28 августа 2021 года, то есть менее чем за два месяца его стоимость выросла на 9375%.
Таким образом, как общий объём проектов NFT, так и цена каждого элемента в проектах меняются быстрее, чем у традиционных финансовых продуктов.

Хотя NFT были одной из самых обсуждаемых тем в 2021 году, многие не знают, как оценивать их стоимость, что делает (участников рынка) осторожными в принятии решений о вложении в выгодные инвестиционные возможности NFT.
Два основных фактора делают задачу оценки стоимости NFT чрезвычайно сложной:
Рассмотрим проект Cryptopunks, который считается самым престижным NFT-проектом (в EVM), в качестве примера.
Из 10 000 существующих панков только 5878 имеют какую-либо историю транзакций.
С момента запуска 23 июня 2017 года по 4 октября 2021 года существует всего 18 777 записей о продажах. Даже среди тех панков, которые переходили из рук в руки два раза и более, среднее время между продажами составляет 117 дней, с максимальным интервалом в 1549 дней.
Помимо низкого объёма транзакций, ценовые изменения также крайне значительны — и это мы ещё не учитываем редкие предметы, которые никогда не были доступны на рынке.
Почему мы не можем использовать традиционные методы?
Между существующими финансовыми продуктами и NFT есть принципиальное различие в плане ликвидности и денежного потока (кэш-флоу). Поэтому использование традиционных методов для оценки стоимости NFT-продуктов является неуместным.
Рассмотрим два интуитивно понятных метода оценки, применяемых к финансовым продуктам.
Пример №01. Последняя цена продажи
Рыночные условия на момент совершения сделки и текущие условия могут значительно отличаться. Например, BAYC #9361 был продан за 1 ETH 1 мая 2021 года, а уже 26 августа он был продан за 500 ETH.
Другими словами, оценивать "текущую" стоимость, используя последнюю цену сделки, рискованно.
Пример №02. Минимальная цена
Диапазон цен существенно различается для редких и не редких предметов. Например, мужской тип Cryptopunks выставлен на продажу за как минимум 102 ETH, в то время как тип "Alien" выставлен на 35 000 ETH.
Иными словами, оценивать стоимость предмета по минимальной цене на рынке также рискованно.
Кроме того, мы обнаружили, что традиционные статистические модели, такие как модели временных рядов, неадекватны для NFT. Конечно, их можно применить, но для достижения приемлемого уровня производительности нужно вложить много усилий в настройку гипер-параметров для каждого проекта (а что ещё хуже, ваши усилия могут не оправдаться).
Также, учитывая разные характеристики NFT, такие как коллекционные предметы и игровые предметы для каждого проекта, создание подходящей модели для каждого из них может занять вечность, учитывая рост рынка NFT.
Именно поэтому NFTBank постоянно стремится разработать подходящую модель оценки для NFT-проектов.
Первые шаги NFTBank к базовой модели
Цель моделирования NFTBank — создать общую модель, которую можно использовать в различных NFT-проектах.
Все данные NFT имеют две основные составляющие. Одна из них — это on-chain данные, содержащие информацию о транзакциях, а другая — off-chain данные, содержащие характеристики каждого предмета.
Если нет истории предыдущих транзакций, будет трудно понять рыночные тенденции, а если нет off-chain данных, будет невозможно определить свойства предмета, такие как редкость.
NFTBank использует передовые технологии для извлечения, составления и предоставления этих двух типов данных.
С точки зрения моделирования рассматриваются две основные проблемы:
- Как работать с транзакциями, включающими наборы предметов?
- Как учитывать категориальные переменные и их редкость?
1. Решение проблемы с наборными транзакциями
Транзакции, включающие наборы предметов, являются одним из факторов, которые могут повлиять на производительность модели.
Например, в проекте League of Kingdoms (LOK) предположим, что несколько связанных земель были проданы в виде наборов (в случае продажи в наборах это очень распространенное явление, превышающее 30%).
Как было показано в нашей ранее опубликованной статье, связанной с LOK (часть 1, часть 2, часть 3), даже если модель создана на основе свойств соседних земель, если регионы с высоким потенциальным значением и регионы с низким потенциальным значением продаются в наборах, могут возникнуть проблемы с прогнозированием стоимости каждой земли (поскольку, попросту говоря, невозможно получить цену каждой земли в наборах).
Для решения этой проблемы мы вводим метод импутации наборов.
Импутация наборов — метод создания модели путём предварительного обучения на данных с ценами земель, включённых в наборы, и повторного обучения набора данных, содержащего импутированные цены, с использованием другой модели.
Схематический процесс импутации показан на следующем рисунке ниже:
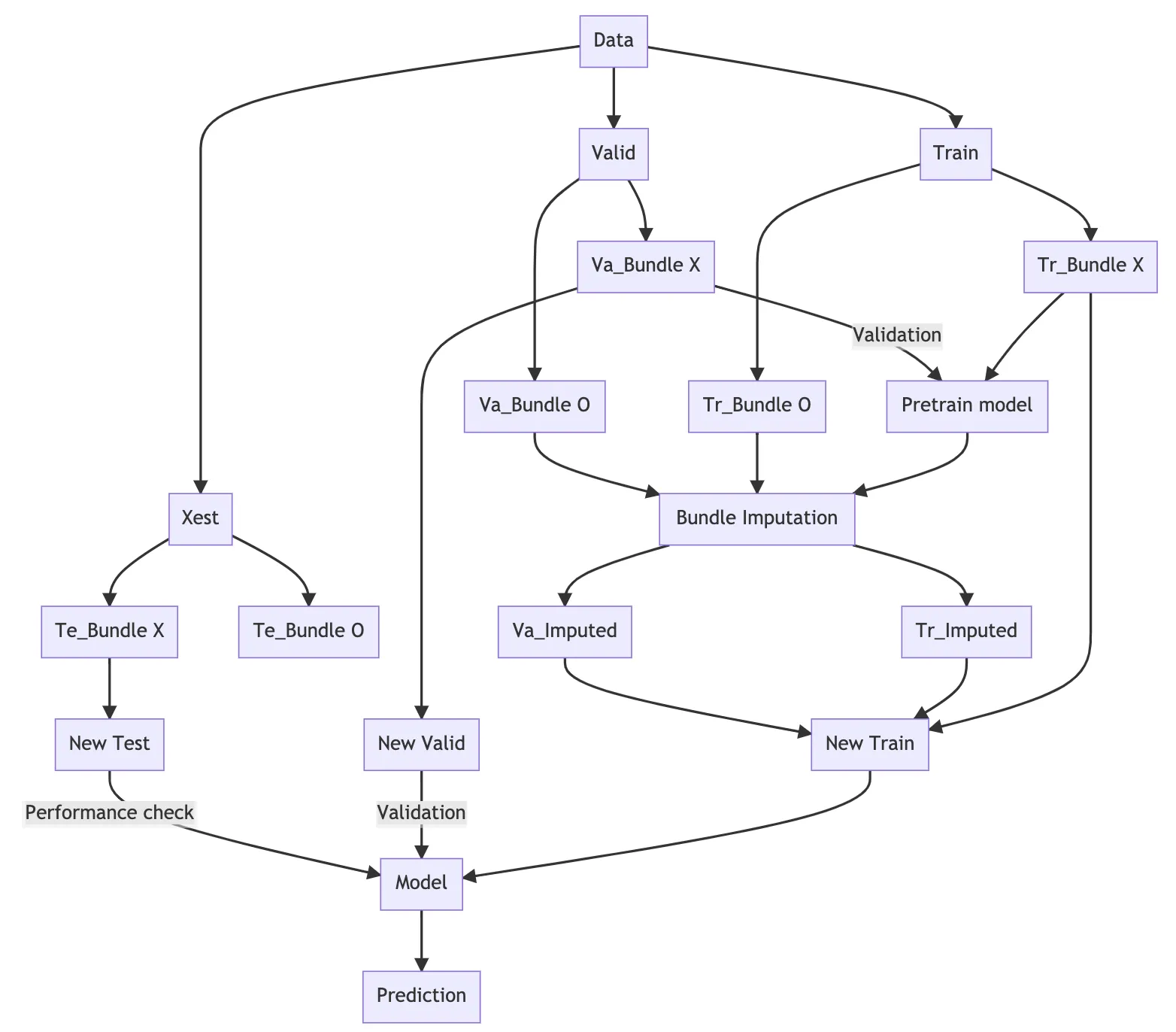
В результате применения методов интерполяции пучков удалось получить более стабильную модель с точки зрения стандартного отклонения MAPE, и было подтверждено, что производительность также улучшилась:

2. Решение проблемы с категориальными признаками
Категориальные переменные или признаки настолько разнообразны в каждом проекте, что часто не существует предметов с одинаковыми комбинациями.
Кроме того, если фильтровать предметы по одному и тому же признаку для каждой категориальной переменной, влияние самой важной переменной на определение цены может снизиться.
Например, Meebits #10761 был продан за 700 ETH. Хотя наиболее важной характеристикой этого предмета является "тип", существует проблема, когда цена может быть завышена за счёт других общих признаков, если модель обучается на признаках без тщательного отбора.
Это говорит о том, что использование техник, основанных на расстоянии (например, k-ближайших соседей) и техник регрессии с точки зрения машинного обучения, затруднено.
Даже если их использовать, масштабирование модели может быть проблематичным, так как нужно учитывать сложные веса или отбор признаков.
Поэтому мы рассматривали возможность применения техники моделирования на основе модели градиентного бустинга (GBM), которая является представителем нелинейных моделей.
Однако сложно утверждать, что выбор этой техники моделирования является точным решением двух вышеупомянутых проблем.
Идея, разработанная NFTBank в качестве меры противодействия первой проблеме, заключается в новой технике создания признаков с использованием эмбеддингов.
Наша техника создания эмбеддингов основана на интуитивном понимании необходимости найти нелинейное преобразование, которое может лучше всего объяснить цену продажи с помощью категориальных признаков.
Другими словами, мы оцениваем параметры W и f, минимизируя следующую целевую функцию, и предполагаем, что f(x) является вектором эмбеддинга, который может хорошо объяснять категориальные переменные.
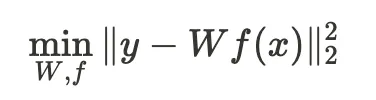
Моделирование состоит из двух этапов: сначала оценивается наилучшее нелинейное преобразование f, которое может объяснить цену через признаки, преобразование признаков через оцененные f и оценка эффективности путём подгонки модели на основе GBM к деталям сделки. Эта техника преобразования схожа с идеями Autoencoder и Word2vec, а функция встраивания f(x) строится как достаточно сложная плотная нейронная сеть.
Если да, то как можно отразить редкость?
Наша модель была разработана для отражения редкости, которая не может быть учтена в методе однократного кодирования, путём учёта веса обратной частоты документа (idf) в признаке перед созданием функции встраивания.
Как показано в таблице ниже, было подтверждено, что производительность предложенной модели была улучшена больше, чем у GBM, на основе медианной абсолютной процентной ошибки (MAPE), где
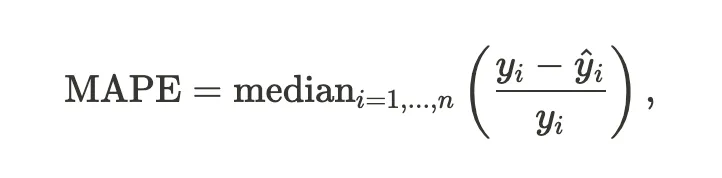
и это было использовано в модели оценки цены.
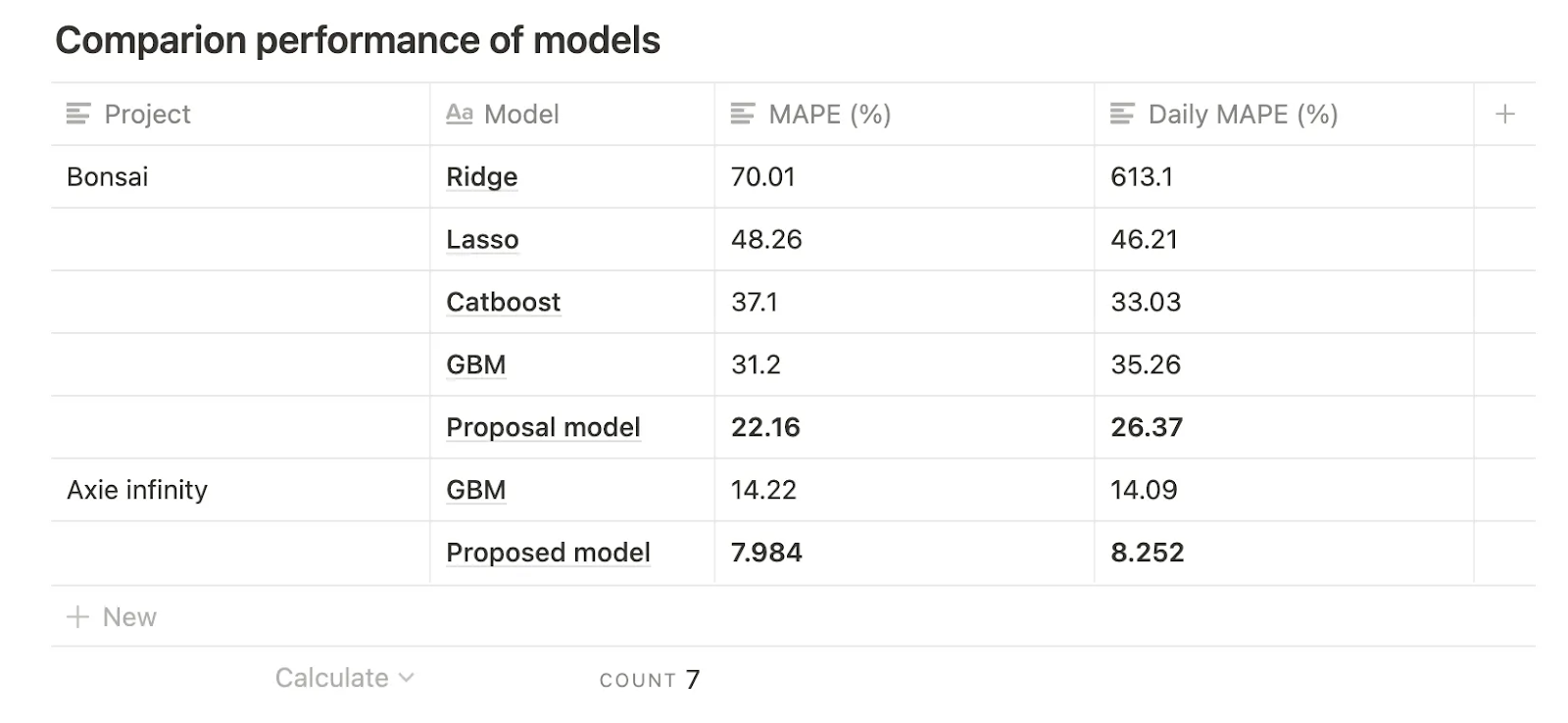
В таблице выше можете легко понять трудности построения модели на примере Bonsai. При использовании линейных моделей, таких как Ridge и Lasso, которые являются репрезентативными статистическими линейными моделями, уровень ошибок составляет 70 и 48 %, поэтому никто не поверит предиктору с такой ошибкой.
Как теперь работает базовая модель NFTBank?
Прошу прощения у тех, кто дочитал до этого места, но представленные выше методики не являются последней базовой моделью (но включены в неё).
Предлагаемая модель постоянно совершенствовалась и будет совершенствоваться при решении проблем, возникающих при увеличении количества покрываемых проектов. Обобщенная оптимизационная задача модели на данный момент выглядит следующим образом:

Хотя форма конкретной функции не может быть раскрыта, f является биективной функцией, а g - моделью предсказания на основе GBM.
После обучения древовидной модели прогнозируемое значение выдается продукту в закрытой форме по приведённой ниже формуле, поскольку f по определению всегда имеет обратную функцию.

Ниже приведены результаты некоторых проектов с использованием базовой модели:

Ниже показана диаграмма рассеивания с прогнозируемой и фактической ценой проектов Veefriends и Meebits. Конечно, погрешность будет, но видно, что разница между прогнозируемым и фактическим значением в большинстве данных невелика.

Диаграмма рассеяния по проекту Veefriends.
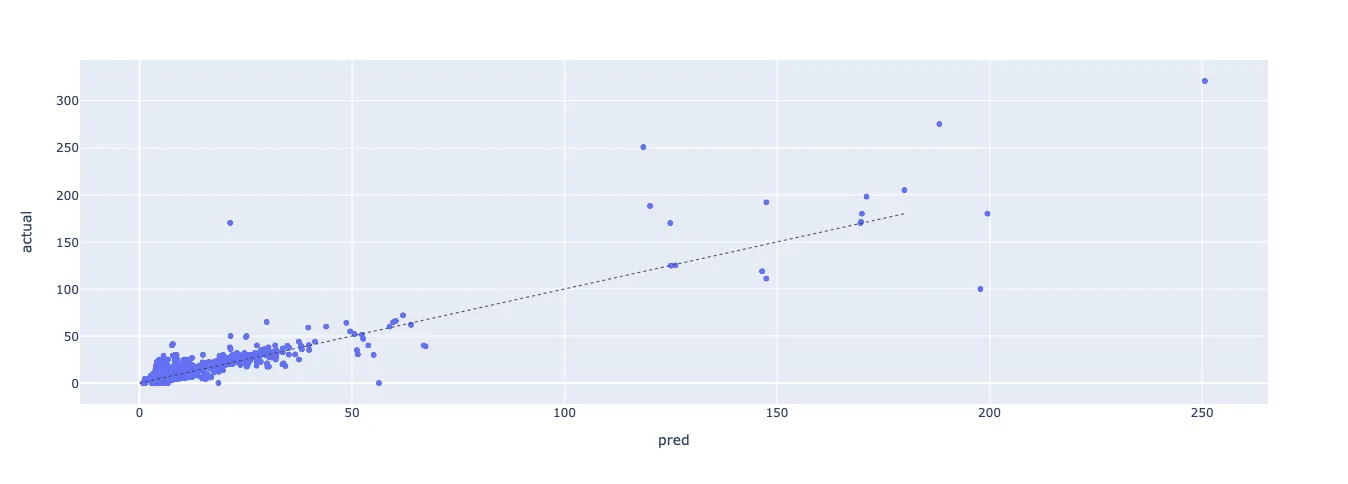
Диаграмма рассеяния по проекту Meebits.
Ограничения
Даже если наша модель улучшена с точки зрения машинного обучения, мы сталкивались с различными случаями, когда наши прогнозы значительно отклонялись, и мы постоянно ищем прорывные решения.
Некоторые ограничения текущей модели и наши цели по её улучшению следующие:
- Модель, как и большинство моделей машинного обучения, оценивает условное ожидание. Проще говоря, "средняя" стоимость предметов, которые сегодня имеют одинаковые признаки на рынке, может быть значительно занижена или завышена по сравнению с той, которую предполагают участники NFT-проекта. Например, в случае игровых NFT будет сложно предсказать изменение рыночной ситуации, если недооцененный предмет внезапно подорожает из-за изменения (данных), опираясь на среднюю рыночную стоимость, сформированную на основе многочисленных предыдущих транзакций.
- Модель с трудом реагирует на появление "game changers".Мы определяем "game changer" как редкий предмет, который внезапно продаётся на рынке. Например, в проекте Cryptopunks, если предмет типа "alien" впервые был продан за 4200 ETH, наша модель не сможет выдать адекватный прогноз для этого, так как нет истории предыдущих продаж.
- Модель не учитывает минимальную цену (floor price).Минимальная цена определяется как наименьшая цена среди текущих "выставленных" цен. Мы понимаем, что минимальная цена является очень важным индикатором на NFT-рынке. Однако, учитывая минимальную цену, существует высокая вероятность того, что оценка будет сильно отклонена (в сторону повышения или понижения), поскольку это не "проданные" цены. Поэтому существует вероятность, что предсказанная моделью стоимость может быть ниже минимальной цены.
- Базовая модель не применима ко всем проектам. Это связано с тем, что, как вы знаете, данные, необходимые для моделирования, не появляются магическим образом. Требуется время и усилия для подготовки данных, поэтому процесс внедрения происходит постепенно, проект за проектом. Мы хотим, чтобы вы знали, что мы вкладываем много усилий и времени в этот процесс.
Наконец, для улучшения модели были добавлены следующие функции для получения обратной связи о предполагаемой цене:
Если у вас возникли вопросы и сомнения по поводу предполагаемой цены, пожалуйста, не стесняйтесь оставлять нам отзывы. Каждый отзыв проверяется, и он обязательно будет учтен для дальнейшего совершенствования модели.
Заключение
Производительность модели NFTBank постоянно улучшается благодаря многочисленным экспериментам и усилиям, и это не прекратится до тех пор, пока она не сможет применяться во всех проектах.
Существует бесчисленное множество теорем в области оптимизации и машинного обучения, но наша любимая - «Теорема о бесплатном обеде».
Эта теорема подразумевает, что наша модель не может быть лучшей для всех проектов. Из неё также следует, что следующим шагом NFTBank будет разработка и создание модели, которая будет лучше подходить для каждого проекта после освоения нашей базовой модели.
В несколько ином смысле, в NFTBank нет бесплатного обеда и даже бесплатного ужина. Все члены команды работают день и ночь, чтобы сделать NFTBank наиболее эффективным инструментом для управления активами NFT.
Наконец, большое спасибо нашим пользователям за то, что поддерживают нас и дают нам отличные отзывы. Это огромный мотиватор для нас и очень много для нас значит.