Многопоточность С++
Процессом (process) называется экземпляр программы, загруженной в память. Этот экземпляр может создавать нити (thread), которые представляют собой последовательность инструкций на выполнение. Важно понимать, что выполняются не процессы, а именно нити.
Причем любой процесс имеет хотя бы одну нить. Эта нить называется главной (основной) нитью приложения.
Потоки предоставляют возможность проведения параллельных или псевдопараллельных, в случае одного процессора, вычислений. Потоки могут порождаться во время работы программы, процесса или другого потока. Основное отличие потоков от процессов заключается в том, что различные потоки имеют различные пути выполнения, но при этом пользуются общей памятью. Путь выполнения потока задается при его создании, указанием его стартовой функции, созданный поток начинает выполнять команды этой функции, и завершается когда происходит возврат из функции.
Так как практически всегда нитей гораздо больше, чем физических процессоров для их выполнения, то нити на самом деле выполняются не одновременно, а по очереди (распределение процессорного времени происходит именно между нитями). Но переключение между ними происходит так часто, что кажется, будто они выполняются параллельно.
Инициализация потока
В новом стандарте C++11 многопоточность осуществлен в классе thread, который определен в файле thread.h. Для того чтобы создать новый поток нужно создать объект класса thread и инициализировать передав в конструктор имя функции которая должна выполнятся в потоке.
#include<iostream>
#include<thread> //Файл в котором определен класс thread
using namespace std;
void anyFunc() {
cout<<"thread function";
}
int main() {
thread func_thread(anyFunc);
return 0;
}В этой программе создается новый объект класса thread и в объявлении конструктору передается имя функции anyFunc, который печатает на экране текст "thread function". Но если скомпилировать данное приложение и запустить, то как бы странно не было оно закончится аварийна с сообщением об ошибке. Все дело в том что главная функция программы main создает объект func_thread, с параметром конструктора anyFunc и продолжает свое выполнение не дожидаясь чтобы процесс закончился, что и вызывает ошибку времени выполнения. Чтобы ошибки не было надо чтобы до того как закончится функция main все потоки были закончены. Это осуществляется путем синхронизации потоков вызывая метод join. Метод join возвращает выполнение программе когда поток заканчивается, после чего объект класса thread можно безопасно уничтожить.
using namespace std;
void anyFunc() {
cout << "thread function";
}
int main() {
thread func_thread(anyFunc);
func_thread.join();
// Выполнение возвращается функции main когда поток заканчивается
return 0;
}Метод join нужно указывать там, где мы хотим дождаться выполнения нашего потока.
Позвольте добавить что перед вызовом функции join надо проверить является ли объект joinable то есть представляет он реальный поток или нет, к примеру объект может быть объявлен но не инициализирован или уже закончен вызовом функции join. Проверка делается функцией joinable, который возвращает true в случае если объект представляет исполняемый поток и false в противном случаи. Надо отметить что может быть ситуация когда нам ненужно ждать чтобы поток закончился, для этого у класса thread есть другой метод по имени detach. Обе метода ничего не принимают и не возвращают и после их вызова объект становится not joinable и можно безопасно уничтожить.
#include<iostream>
#include<thread> //Файл в котором определен класс thread
using namespace std;
void anyFunc()
{
cout << "thread function";
}
int main()
{
thread func_thread(anyFunc);
if (func_thread.joinable())
func_thread.join();
// Выполнение возвращается функции main когда поток заканчивается
// func_thread.detach(); В этом случае поток заканчивается принудительно
return 0;
}В инициализацию объекта можно и передать параметры в функции перечисляя их после имени функции как продемонстрировано в следующем примере:
#include<iostream>
#include<thread> //Файл в котором определен класс thread
using namespace std;
void printStr(char * str)
{
cout << str << '\n';
}
void printArray(int a[],const int len)
{
for (int i = 0; i < len; i++) {
cout << a[i] << ' ';
}
}
int main()
{
char* str = "thread function with parametrs";
const int len = 8;
int arr[len] = {12, 45, -34, 57, 678, 89, 0, 1};
// Передаем параметр функции во время инициализации
thread func_thread(printStr, str);
// Параметров может быть много
thread func_thread2(printArray, arr, len);
if (func_thread.joinable()) func_thread.join();
if (func_thread2.joinable()) func_thread2.join();
return 0;
}Параметры можно передавать не только по значению но и по ссылке. Для чего воспользуемся функцией ref из пространства имен std. В ниже приведенной программе вызываемому потоку передается массив и его длина, а в потоке в него добавляются 5 новых значений.
#include<iostream>
#include<cstdlib>
#include<thread>
using namespace std;
void addElements(int a[], int &len)
{
for (int i = len; i < len + 5; i++) {
a[i] = rand();
}
len += 5;
}
int main()
{
const int LENGTH = 20;
int arr[LENGTH] = {1, 2, 3, 4, 5}, current_length = 5;
cout << "Output the array before thread\n";
for (int i = 0; i < current_length; i++) {
cout << arr[i] << ' ';
}
thread arr_thread(addElements, arr, ref(current_length));
if (arr_thread.joinable()) arr_thread.join();
cout << "\nOutput th array after thread\n";
for (int i = 0; i < current_length; i++) {
cout << arr[i] << ' ';
}
return 0;
}Потоки могут быть инициализированны не только функцией но и объект функцией, то есть в классе объекта определен метод operator(), и обычным открытым методом класса. В первом случае нужно передать объект этого класса в конструктор thread, а во втором случае ссылку на функцию и адрес объекта, конечно не надо забыть про список параметров если они есть.
#include<iostream>
#include<thread>
using namespace std;
class arrayModifier
{
public:
void operator()(int a[], int len) {
for (int i = 0; i < len; i++) {
a[i] *= 2;
}
}
void invers(int a[], int len) {
for (int i = 0; i < len; i++) {
a[i] *= -1;
}
}
};
int main()
{
const int length = 5;
int arr[length] = {1, 2, 3, 4, 5};
arrayModifier obj;
cout << "Output the array before threads\n";
for (int i = 0; i < length; i++)
{
cout << arr[i] << ' ';
}
// Инициализируется объект функцией
thread arr_thread(obj, arr, length);
// Инициализируется обычным открытым методом
thread arr_thread2(&arrayModifier::invers, &obj, arr, length);
if (arr_thread.joinable()) arr_thread.join();
if (arr_thread2.joinable()) arr_thread2.join();
cout << "\nOutput th array after threads\n";
for (int i = 0; i < length; i++)
{
cout << arr[i] << ' ';
}
return 0;
}В вышеприведенном примере у класса arrayModifier есть два метода первый это operator() который элементы массива умножает на 2, а второй умножает на -1. Во втором объекте мы передаем адрес объекта связи с тем что метод класса в качестве скриптового параметра принимает адрес объекта для которого был вызван этот метод.
ID потока
У каждого потока есть свой уникальный номер который отличается от других потоков этой программы. Для этого в классе thread есть закрытый член id и открытый метод get_id вызов которого возвращает значение этого члена.
#include<iostream>
#include<cstdlib>
#include<thread>
using namespace std;
class printNumber
{
public:
void operator()(int number,int arr[],int idx)
{
int sum = 0;
for(int i = 0; i < number; i++)
{
if(1%15 == 0) continue;
if(i%3 == 0) sum += 3*i;
if(i%5 == 0) sum += 5*i;
}
arr[idx] = sum;
}
};
int main()
{
const int length = 10;
thread::id id;
thread thread_array[length];
int res_arr[length] = {0};
for (int i = 0; i < length; i++)
{
thread_array[i] = thread(printNumber(), rand(),res_arr,i);
}
for (int i = 0; i < length; i++)
{
if (thread_array[i].joinable())
{
id = thread_array[i].get_id();
thread_array[i].join();
cout << "Thread with id " << id << " finished. With result "<<res_arr[i]<<"\n";
}
}
return 0;
}Пространство имен this_thread
В заголовочном файле thread.h определено пространство имен this_thread который содержит в себе функции для работы с конкретным потоком. Три из этих функций для того чтобы на некоторое время остановить выполнение потока: sleep_until - передается переменная класса chrono:time_point и блокируется выполнение потока пока системные часы не дойдут до этого времени; sleep_for - передается переменная класса chrono::duration и выполнение потока блокируется пока не прошло столько времени сколько было преданно; yield - останавливает выполнение потока на некоторое время предоставляя возможность выполнится другим потокам. А четвертая функция это get_id и как метод класса thread возвращает id потока.
#include<iostream>
#include<sstream>
#include<chrono>
#include<thread>
using namespace std;
class printNumber
{
public:
void operator()()
{
ostringstream out;
thread::id id = this_thread::get_id();
out << "Thread with id " << id << " started\n";
cout << out.str();
// Останавливает выполнение на одну секунду
this_thread::sleep_for(chrono::seconds(1));
out.str("");
out << "Thread with id " << id << " finished\n";
cout << out.str();
}
};
int main()
{
const int length = 10;
thread thread_array[length];
for (int i = 0; i < length; i++)
{
thread_array[i] = thread(printNumber());
}
for (int i = 0; i < length; i++)
{
if (thread_array[i].joinable())
{
thread_array[i].join();
}
}
return 0;
}Одновременный доступ к ресурсам
В вышеприведенном примере для печати на экран использовался sstream, предварительно превращая в строку то что хочу печатать а потом передаю в поток вывода. А что если сразу передать в поток вывода, сперва первую строку, потом переменную типа thread::id и наконец вторую строку. Но в этом случае потоки не по очереди будут передавать в поток вывода и в итоге получается совсем не то что мы хотели. Такая ситуация бывает когда несколько потоков работают с одним и тем же объектом. Для того чтобы предотвратить это воспользуемся классом mutex который определен в файле mutex. Переменная типа mutex можно блокировать и разблокировать. Когда вызывается метод lock класса mutex, метод проверяет объект и если он разблокирован то блокирует его и возвращает выполнение, в противном случае оно ждет пока объект разблокируется и после чего делает то же самое. А метод unlock разблокирует объект класса mutex этим позволяя другим процессам его блокировать.
#include<iostream>
#include<cstdlib>
#include<vector>
#include<mutex>
#include<thread>
using namespace std;
const int elementsCount = 10;
void push(vector<int> &arr, mutex& m_arr, mutex& m_out)
{
int num;
for (int i = 0; i < elementsCount; i++)
{
m_arr.lock();
num = rand();
arr.push_back(num);
m_arr.unlock();
m_out.lock();
cout << "Push " << num << "\n";
m_out.unlock();
}
}
void pop(vector<int> &arr, mutex& m_arr, mutex& m_out)
{
int i = 0, num;
while (i < elementsCount)
{
m_arr.lock();
if (arr.size() > 0)
{
num = arr.back();
arr.pop_back();
m_out.lock();
cout << "Pop " << num << "\n";
m_out.unlock();
i++;
}
m_arr.unlock();
}
}
int main()
{
mutex m_arr, m_out;
vector<int> vec;
thread push_thread(push, ref(vec), ref(m_arr), ref(m_out));
thread pop_thread(pop, ref(vec), ref(m_arr), ref(m_out));
if (push_thread.joinable()) push_thread.join();
if (pop_thread.joinable()) pop_thread.join();
return 0;
}В вышеприведенной программе мы создаем два объекта класса thread первый инициализируем функцией push, который добавляет в вектор 10 элементов блокируя и раз блокируя объекты m_arr и m_out, а второй функцией pop, который удаляет 10 элементов из вектора, конечно опять блокируя и раз блокируя объекты m_arr и m_out.
Механизмы синхронизации
Вводные понятия синхронизации потоков
Критический участок – часть кода потока, в которой производится обращение к общим данным и их изменение.
Взаимоисключение потоков – ситуация, при которой поток, находящийся в критическом участке, не должен допускать входа в критический участок всех других потоков, использующих эти же данные.
Синхронизация потоков – согласование потоками взаимного порядка доступа к общим ресурсам и очередности обработки событий.
При создании многопоточного приложения необходимо уделить внимание обеспечению синхронизации потоков. В противном случае могут появиться ошибки, которые трудно поддаются локализации. В чем заключается синхронизация потоков? Если сказать кратко, то синхронизация потоков (в том числе принадлежащих разным приложениям) заключается в том, что некоторые потоки должны приостанавливать свое выполнение до тех пор, пока не произойдут те или иные события, связанные с другими потоками.
Здесь возможно очень много вариантов. Например, главный поток порождает дочерний поток, который выполняет какую-либо длительную работу, например, подсчет страниц в текстовом документе. Если теперь потребуется отобразить количество страниц на экране, главный поток должен дождаться завершения работы, выполняемой дочерним потоком.
Другая проблема возникает, если, например, вы собираетесь организовать параллельную работу различных потоков с одними и теми же данными. Особенно сложно выполнить необходимую синхронизацию в том случае, когда некоторые из этих потоков выполняют чтение общих данных, а некоторые - изменение. Типичный пример - текстовый редактор, в котором один поток может заниматься редактированием документа, другой - подсчетом страниц, третий - печатью документа на принтере и так далее.
Синхронизация необходима и в том случае, когда вы, например, создаете ядро системы управления базой данных, допускающее одновременную работу нескольких пользователей. При этом вам, вероятно, потребуется выполнить синхронизацию потоков, принимающих запросы от пользователей, и выполняющих эти запросы.
В программном интерфейсе операционной системы Microsoft Windows предусмотрены различные средства синхронизации потоков, как выполняющихся в рамках одного процесса, так и принадлежащих разным процессам. В последнем случае принято говорить о синхронизации процессов. Сложность синхронизации процессов заключается в том, что они не имеют общего адресного пространства и нуждаются в создании специальных системных объектов.
Работа с потоками с помощью функций WinAPI Несинхронизированные потоки
Первый пример иллюстрирует работу с несинхронизированными потоками. Основной цикл, который является основным потоком процесса, выводит на экран содержимое глобального массива целых чисел. Поток, названный "Thread", непрерывно заполняет глобальный массив целых чисел.
#include <process.h>
#include <stdio.h>
int a[ 5 ];
void Thread( void* pParams )
{
int i, num = 0;
while ( 1 )
{
for ( i = 0; i < 5; i++ ) a[ i ] = num;
num++;
}
}
int main( void )
{
_beginthread( Thread, 0, NULL );
while( 1 )
printf("%d %d %d %d %d\n",
a[ 0 ], a[ 1 ], a[ 2 ],
a[ 3 ], a[ 4 ] );
return 0;
}Как видно из результата работы процесса, основной поток (сама программа) и поток Thread действительно работают параллельно (подчёркиванием обозначено состояние, когда основной поток выводит массив во время его заполнения потоком Thread):
81751652 81751652 81751651 81751651 81751651 81751652 81751652 81751651 81751651 81751651 83348630 83348630 83348630 83348629 83348629 83348630 83348630 83348630 83348629 83348629 83348630 83348630 83348630 83348629 83348629
Запустите программу, затем нажмите "Pause" для остановки вывода на дисплей (т.е. приостанавливаются операции ввода/вывода основного потока, но поток Thread продолжает свое выполнение в фоновом режиме) и любую другую клавишу для возобновления выполнения.
Критические секции
А что делать, если основной поток должен читать данные из массива после его обработки в параллельном процессе? Одно из решений этой проблемы - использование критических секций.
Критические секции обеспечивают синхронизацию подобно мьютексам за исключением того, что объекты, представляющие критические секции, доступны в пределах одного процесса. События, мьютексы и семафоры также можно использовать в "однопроцессном" приложении, однако критические секции обеспечивают более быстрый и более эффективный механизм взаимно-исключающей синхронизации. Подобно мьютексам объект, представляющий критическую секцию, может использоваться только одним потоком в данный момент времени, что делает их крайне полезными при разграничении доступа к общим ресурсам. Трудно предположить что-нибудь о порядке, в котором потоки будут получать доступ к ресурсу, можно сказать лишь, что система будет "справедлива" ко всем потокам.
#include <windows.h>
#include <process.h>
#include <stdio.h>
CRITICAL_SECTION cs;
int a[5];
void Thread(void* pParams)
{
int i, num = 0;
while (TRUE)
{
EnterCriticalSection(&cs);
for (i = 0; i < 5; i++) a[i] = num;
LeaveCriticalSection(&cs);
num++;
}
}
int main(void)
{
InitializeCriticalSection(&cs);
_beginthread(Thread, 0, NULL);
while (TRUE)
{
EnterCriticalSection(&cs);
printf("%d %d %d %d %d\n",
a[0], a[1], a[2],
a[3], a[4]);
LeaveCriticalSection(&cs);
}
return 0;
}Мьютексы (взаимоисключения)
Мьютекс (взаимоисключение, mutex) - это объект синхронизации, который устанавливается в особое сигнальное состояние, когда не занят каким-либо потоком. Только один поток владеет этим объектом в любой момент времени, отсюда и название таких объектов - одновременный доступ к общему ресурсу исключается. Например, чтобы исключить запись двух потоков в общий участок памяти в одно и то же время, каждый поток ожидает, когда освободится мьютекс, становится его владельцем и только потом пишет что-либо в этот участок памяти. После всех необходимых действий мьютекс освобождается, предоставляя другим потокам доступ к общему ресурсу.
Два (или более) процесса могут создать мьютекс с одним и тем же именем, вызвав метод CreateMutex . Первый процесс действительно создает мьютекс, а следующие процессы получают хэндл уже существующего объекта. Это дает возможность нескольким процессам получить хэндл одного и того же мьютекса, освобождая программиста от необходимости заботиться о том, кто в действительности создает мьютекс. Если используется такой подход, желательно установить флаг bInitialOwner в FALSE, иначе возникнут определенные трудности при определении действительного создателя мьютекса.
Несколько процессов могут получить хэндл одного и того же мьютекса, что делает возможным взаимодействие между процессами. Вы можете использовать следующие механизмы такого подхода:
- Дочерний процесс, созданный при помощи функции
CreateProcessможет наследовать хэндл мьютекса в случае, если при его (мьютекса) создании функиейCreateMutexбыл указан параметр lpMutexAttributes . - Процесс может получить дубликат существующего мьютекса с помощью функции
DuplicateHandle. - Процесс может указать имя существующего мьютекса при вызове функций
OpenMutexилиCreateMutex.
Вообще говоря, если вы синхронизируете потоки одного процесса, более эффективным подходом является использование критических секций.
#include <windows.h>
#include <process.h>
#include <stdio.h>
HANDLE hMutex;
int a[ 5 ];
void Thread( void* pParams )
{
int i, num = 0;
while ( TRUE ) {
WaitForSingleObject( hMutex, INFINITE );
for ( i = 0; i < 5; i++ ) a[ i ] = num;
ReleaseMutex( hMutex );
num++;
}
}
int main( void )
{
hMutex = CreateMutex( NULL, FALSE, NULL );
_beginthread( Thread, 0, NULL );
while( TRUE )
{
WaitForSingleObject( hMutex, INFINITE );
printf( "%d %d %d %d %d\n",
a[ 0 ], a[ 1 ], a[ 2 ],
a[ 3 ], a[ 4 ] );
ReleaseMutex( hMutex );
}
return 0;
}События
Событие - это объект синхронизации, состояние которого может быть установлено в сигнальное, путем вызова функций SetEvent или PulseEvent . Существует два типа событий:
Событие с ручным сбросом
Это объект, сигнальное состояние которого сохраняется до ручного сброса функцией ResetEvent . Как только состояние объекта установлено в сигнальное, все находящиеся в цикле ожидания этого объекта потоки продолжают свое выполнение (освобождаются).
Событие с автоматическим сбросом
Объект, сигнальное состояние которого сохраняется до тех пор, пока не будет освобожден единственный поток, после чего система автоматически устанавливает несигнальное состояние события. Если нет потоков, ожидающих этого события, объект остается в сигнальном состоянии.
События полезны в тех случаях, когда необходимо послать сообщение потоку, сообщающее, что произошло определенное событие. Например, при асинхронных операциях ввода и вывода из одного устройства, система устанавливает событие в сигнальное состояние когда заканчивается какая-либо из этих операций. Один поток может использовать несколько различных событий в нескольких перекрывающихся операциях, а затем ожидать прихода сигнала от любого из них.
Поток может использовать функцию CreateEvent для создания объекта события. Создающий событие поток устанавливает его начальное состояние. В создающем потоке можно указать имя события. Потоки других процессов могут получить доступ к этому событию по имени, указав его в функции OpenEvent .
Поток может использовать функцию PulseEvent для установки состояния события в сигнальное и затем сбросить состояние в несигнальное после освобождения соответствующего количества ожидающих потоков. В случае объектов с ручным сбросом освобождаются все ожидающие потоки. В случае объектов с автоматическим сбросом освобождается только единственный поток, даже если этого события ожидают несколько потоков. Если ожидающих потоков нет, PulseEvent просто устанавливает состояние события в несигнальное.
#include <windows.h>
#include <process.h>
#include <stdio.h>
HANDLE hEvent1, hEvent2;
int a[ 5 ];
void Thread( void* pParams )
{
int i, num = 0;
while ( TRUE )
{
WaitForSingleObject( hEvent2, INFINITE );
for ( i = 0; i < 5; i++ ) a[ i ] = num;
SetEvent( hEvent1 );
num++;
}
}
int main( void )
{
hEvent1 = CreateEvent( NULL, FALSE, TRUE, NULL );
hEvent2 = CreateEvent( NULL, FALSE, FALSE, NULL );
_beginthread( Thread, 0, NULL );
while( TRUE )
{
WaitForSingleObject( hEvent1, INFINITE );
printf( "%d %d %d %d %d\n",
a[ 0 ], a[ 1 ], a[ 2 ],
a[ 3 ], a[ 4 ] );
SetEvent( hEvent2 );
}
return 0;
}Потокобезапасность
STL не потокобезопасная библиотека, но исправить это очень просто. Предположим, вам необходимо сохранять данные в вашу коллекцию в одном потоке, когда другой поток также сохраняет их туда. Тогда просто используйте критическую секцию или Mutex.
Типовые задачи синхронизации
Процесс - вычисление, применение конечного множества операций к конечному набору данных. Два процесса считаются параллельными, если первая операция одного процесса начинает выполняться до завершения другого. Ресурсы, используемые несколькими процессами, называются разделяемыми. Критический ресурс - это разделяемый ресурс, который одновременно может использоваться не более чем одним процессом. Критический интервал или критическая секция - участок кода, где процесс работает с критическим ресурсом. Взаимосвязанные процессы - это процессы, использующие общий ресурс или обменивающиеся информацией. Синхронизация процессов - ограничения, накладываемые на порядок выполнения процессов. Эти ограничения задаются с помощью правил синхронизации, которые описываются с помощью механизмов синхронизации (примитивов).
К типовым задачам синхронизации можно отнести:
• взаимное исключение;
• обедающие философы;
• поставщики - потребители;
• читатели - писатели.
Задача о взаимном исключении формулируется так: есть несколько процессов, программы которых содержат участки, где процессы обращаются к разделяемому ресурсу. Требуется исключить одновременные обращения процессов к критическому интервалу. При этом необходимо, чтобы задержка любого процесса вне его критического интервала не влияла на развитие других процессов. Решение должно быть симметричным для всех процессов, т.е. все процессы равноправны. Решение не должно допускать общих и локальных тупиков. Общий тупик - это взаимная блокировка всех процессов; локальный тупик - взаимная блокировка одного или нескольких процессов.
Задача "обедающие философы": на круглом столе находятся k тарелок с едой, между которыми лежит столько же вилок, k>=2. В комнате имеется k философов, чередующих философские размышления с принятием пищи. За каждым философом закреплена своя тарелка; для еды философу нужны две вилки, причем он может использовать только вилки, примыкающие к его тарелке. Требуется так синхронизировать философов, чтобы каждый из них мог получить за ограниченное время доступ к своей тарелке. Предполагается, что длительность еды и размышлений философа конечна, но заранее недетерминирована.
Задача "поставщики-потребители": имеется ограниченный буфер на m мест (m порций информации). Он является критическим ресурсом для процессов двух типов: процессы-поставщики, получая доступ к ресурсу, помещают на свободное место порцию информации; процессы-потребители, получая доступ к ресурсу, считывают из него порцию информации. Требуется исключить одновременный доступ процессов к ресурсу. При полном опустошении буфера задерживаются процессы-потребители, при полном заполнении буфера задерживаются процессы-поставщики.
Задача "читатели-писатели": имеется разделяемый ресурс - область памяти, к которой требуется обеспечить доступ процессам двух типов: процессы-читатели могут получать доступ к ресурсу одновременно, они считывают информацию (неразрушающее считывание); процессы-писатели взаимно исключают друг друга и читателей. Известны два варианта этой задачи:
1. читатели, изъявившие желание получить доступ к ресурсу, должны получить его как можно быстрее;
2. читатели, изъявившие желание получить доступ к ресурсу, должны получить его как можно быстрее, если отсутствуют запросы от писателей. Писатель, требующий доступ к ресурсу, должен получить его как можно быстрее, но после обслуживания читателей, подошедших к ресурсу до первого писателя.
Во многих приложениях требуется барьерная синхронизация N параллельных процессов - они все должны прийти к некоторой точке и только после этого все процессы, запросившие барьерную синхронизацию, могут продолжиться.
Механизм семафоров
Пусть S - семафор - переменная специального типа с целочисленными значениями, над которой определены две операции: Р (закрытие) и V (открытие).
P(S): если S≥1, то процесс продолжает выполняться, а S уменьшается на единицу; если S = 0, то процесс задерживается, а имя его передается в очередь процессов, ожидающих доступа к данному ресурсу (обычно семафоры связывают с некоторыми ресурсами).
V(S): если в очереди к семафору S есть процессы, то один из них выбирается и активизируется (переводится в состояние готовности: помещается в очередь процессов, претендующих на процессорное время); если в очереди нет процессов, то выполняется операция S = S+1 (при условии непревышения результатом максимально допустимого значения семафора; для двоичного семафора S ∈{0,1}).
Операции Р и V неделимы, т.е. над одним семафором одновременно может работать только один процесс. Так, процесс, начавший работу с семафором, должен ее закончить до переключения процессора на другой процесс в случае квазипараллельных процессов.
Все упомянутые задачи синхронизации можно решить с помощью семафоров. Рассмотрим задачу взаимного исключения:
S=1; Процесс_i: P(S); Критическая секция V(S);
При неаккуратном использовании семафорных переменных могут возникать тупиковые состояния. Например, тупик возможен в случае представленных ниже двух процессов при их одновременном выходе на второй вызов P:
S1=1 S2=1 P(S1) P(S2) P(S2) P(S1) V(S2) V(S1) V(S1) V(S2)
Следует, однако, отметить, что приведенные в примере процессы могут работать и неограниченно долгое время, не попадая в тупик.
Семафорное решение задачи о философах
Обозначим через Р1, Р2, Р3, Р4 - процессы-философы; b1, b2, b3, b4 - вилки. Для еды философу необходимо использовать две соседние вилки
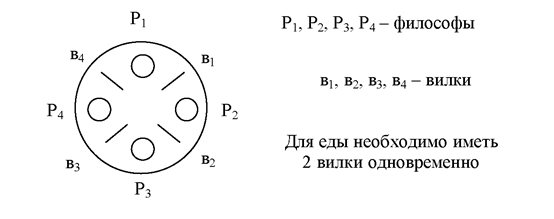
Алгоритм работы каждого философа предполагает использование пяти семафоров (Si, i =1,4 ; S). Семафор S предназначен для взаимного исключения процессов при получении доступа к массиву b, отвечающему за вилки. Каждый семафор Si предназначен для подвешивания i-го философа в том случае, если в результате проверки вилок он обнаружит, что нужных ему вилок в наличии нет. Приведем алгоритм работы первого философа, остальные работают аналогично.
P1: P(S[1]); P(S); if (b1>0)&(b2>0) then begin b1:=0; b2:=0; V(S);
{питание} P(S);
b1:=1; b2:=1; V(S);
for i:=1 to 4 do V(S[i]); {философствование} end else
V(S); goto P1;