Методы отладки и тестирования программы
Теоретические сведения
Ошибки, сделанные в программе, можно разделить на два типа: синтаксические и семантические. Синтаксические ошибки возникают при нарушении правил записи программы на выбранном языке программирования. Современные компиляторы хорошо выявляют такие ошибки и выводят на экран толковые сообщения о типе ошибки и месте ее обнаружения. Эти сообщения позволяют быстро найти место ошибки и исправить ее. Дело несколько осложняется тремя обстоятельствами.
Во-первых, компилятор указывает не ту строку исходного текста программы, в которой произошла ошибка, а ту, в которой она проявилась. Эта строка может оказаться гораздо ниже, чем та, на которой сделана ошибка. Например, если вы забудете закончить описание класса на языке С++ точкой с запятой, как в следующем примере, то компилятор будет считать, что описание продолжается, и сообщит об ошибке только тогда, когда в этом "продолжении" возникнет какое-нибудь противоречие. Оно может проявиться спустя несколько десятков строк исходного текста, и вы будете ломать голову, недоумевая, какая же в этом месте может быть ошибка. Нужен некоторый опыт, чтобы сообразить, что ошибка находится гораздо выше.
class А{ int п;
public:
A(int n){ this.n = n;
}
}
class B{ } ;Во-вторых, ошибка может произойти по разным причинам, компилятор же укажет только одну. Иногда компилятор честно сообщает, что не может определить причину ошибки, написав просто: "Syntax error". В большинстве случаев он указывает наиболее часто встречающуюся, по мнению разработчиков компилятора, ошибку, в вашей программе может оказаться совсем другая, поэтому принимайте сообщения компилятора не как истину, а только как один из возможных вариантов.
В-третьих, некоторые ошибки компилятор не в состоянии обнаружить. К ним относится деление на ноль или переполнение в арифметических выражениях, отрицательное или слишком большое значение индекса массива, и другие ошибки, возникающие в процессе вычислений. Такие ошибки проявляются уже на этапе выполнения (run time) программы и сообщает о них не компилятор, а исполняющая система. Их следует учитывать уже при проектировании, включая в программу обработку исключительных ситуаций.
Синтаксические ошибки обнаруживаются и устраняются довольно легко после нескольких запусков программы. Без исправления этих ошибок программа просто не будет работать. Гораздо труднее исправить семантические ошибки — ошибки в алгоритме работы программы.
Часто встречающаяся семантическая ошибка — неправильная расстановка скобок в выражении. Компилятор может проверить парность скобок, но если число открывающих скобок совпадает с числом закрывающих скобок, то компилятор не может сказать, в нужных ли местах они стоят. Здесь надо быть особенно внимательным и отдавать себе отчет в том, что вы хотите вычислить. Например, переменная х может получить значение, вычисленное следующим оператором:
double х = 2 * (а - Ь) / (а + Ь) + к * 5 * (а + Ь) / (а * Ь) ;
Но значение х вполне можно вычислить и таким оператором:
double х = 2 * (а - b) / (а + Ь) + к * (5 * а + Ь) / (а * Ь) ;
Компилятору обе записи "кажутся" правильными. Выбор того или иного оператора зависит от задачи, в которой вычисляется переменная х.
Еще одна распространенная ошибка, не обнаружимая компилятором, возникает из-за неправильной расстановки или отсутствия фигурных скобок.
В следующем примере, очевидно, переменная s, в которой накапливается сумма, должна изменяться при каждой итерации цикла, но компилятор не может "понять", что, фактически, она меняется только один раз: после выполнения цикла.
int m, S = 0; for (int k = 0; k < a.sizeO - 1; k++) m = a[k + 1] - a[k]; s += 2 * m * m - 3 * m + 2;
Чтобы избежать таких ошибок, специалисты рекомендуют записывать тело любого составного оператора в фигурных скобках.
Семантические ошибки выявить гораздо труднее, чем синтаксические. Поскольку компилятор не может их заметить, он не выдает никаких сообщений. Программа может долго работать, не попадая в условия, в которых проявляются семантические ошибки. Бывает, что ошибочные результаты появляются только после нескольких месяцев эксплуатации программы. Поэтому для выявления таких ошибок зачастую приходится прикладывать специальные усилия, а в проекте необходимо предусматривать специальную фазу отладки и тестирования.
Процесс отладки проходит несколько этапов. Ошибку сначала надо обнаружить. Потом найти место ее появления, как говорят, локализовать ошибку. После этого ошибку надо устранить. Рассмотрим подробнее каждую стадию отладки.
Обнаружение ошибки
Большинство синтаксических ошибок обнаруживается компилятором или выявляется сразу же после первых запусков программы. Их нетрудно обнаружить и исправить. Как правило, трудности вызывает обнаружение семантических ошибок. О них обычно и идет речь, когда говорят об отладке.
После того как очевидные ошибки устранены, и программа при запуске не сообщает об ошибках, могут возникнуть следующие ситуации:
1. Программа не дает никаких результатов. Это происходит чаще всего в результате зацикливания или ожидания какого-то события, которое по разным причинам не может наступить.
2. Программа дает неверные результаты. Самый распространенный вари-ант, возникающий из-за ошибок в алгоритме или из-за ошибок в коди-ровании алгоритма.
3. Программа дает правдоподобные результаты. Это самый опасный слу-чай, поскольку получаемые значения можно принять за верные резуль-таты и передать в эксплуатацию ошибочную программу.
4. Программа работает правильно. Почти фантастика. Рассмотрим подробнее каждую ситуацию.
Программа не дает результатов
В этой ситуации надо, прежде всего, добиться все-таки от программы хоть какой-то выдачи. Это достигается добавлением в программу функций вывода printf(), fprintf о, puts() или других функций, выводящих промежуточные значения всех или наиболее важных переменных. Они образуют так называемую отладочную печать. Это название появилось в эпоху телетайпов, когда результаты выводились на бумажную ленту. Сейчас отладочные сведения выводятся на экран дисплея или записываются в файл, но слово "печать" осталось в лексиконе программистов, означая выдачу результатов на какое-нибудь устройство вывода.
Что входит в отладочную печать? Прежде всего, надо распечатать исходные данные, чтобы убедиться, что ввод происходит правильно. Затем надо проверить начало и окончание каждого цикла, распечатав начальные значения цикла и значения, полученные по окончании цикла. Печать внутри цикла обычно не делается, она будет выполняться при каждом повторении цикла и приведет к огромной выдаче, в которой будет трудно что-либо понять.
Отладочная печать ставится перед разветвлениями, а также в начало каждой ветви, чтобы убедиться в правильном прохождении условных операторов.
Очень много ошибок возникает при передаче аргументов в функции. Компилятор работает с каждой функцией отдельно, у него нет сведений о других функциях, и он не может проверить правильность фактических параметров. Поэтому отладочная печать ставится в начале каждой функции, чтобы проверить правильность полученных ею аргументов. Кроме того, нужно распечатывать значение, возвращенное функцией, чтобы убедиться в точности ее работы.
Программа дает неверные результаты
Эта ситуация встречается чаще всего. Она может возникнуть по самым разным причинам. К ней могут привести и простая ошибка в наборе текста программы, и неверный алгоритм решения задачи. Например, вы можете случайно исказить оператор присваивания:
double х = 3.45 * а[к - 1] + 2.5 * а[к + 1];
и написать, поставив вместо десятичной точки звездочку:
double х = 3.45 * а[к - 1] + 2*5 * а[к + 1];
Из-за этой мало заметной ошибки значение переменной х изменится в четыре раза.
Такие ошибки легко обнаружить, но очень трудно локализовать. Зачастую приходится делать полную трассировку программы, поставив отладочную печать после почти каждого оператора, тем самым тщательно отслеживая изменения переменных. Трассировкой не следует злоупотреблять: в результате выдается масса информации, которую трудно проанализировать. Поэтому на практике к этому методу прибегают только в самых крайних случаях.
Гораздо чаще для обнаружения ошибки в программу устанавливаются контрольные точки (breakpoints), в те места, где ошибки наиболее вероятны. Программа останавливается на каждой контрольной точке. После останова можно просмотреть значения переменных и продолжить выполнение программы до следующей контрольной точки. Многие инструментальные средства программирования позволяют даже изменить переменные в контрольной точке и продолжить выполнение программы с другими значениями.
Еще одно средство поиска ошибок — пошаговое выполнение программы, при котором она приостанавливается после выполнения каждого оператора. После останова можно просмотреть промежуточные значения переменных и выполнить следующий оператор. Разумеется, полное пошаговое выполнение всей программы займет слишком много времени. Поэтому его обычно начинают с какой-либо контрольной точки и прекращают, как только ошибка найдена.
Еще труднее найти ошибки в алгоритме решения задачи. Они могут накапливаться понемногу от оператора к оператору. По отладочной печати трудно отследить момент появления таких ошибок. Пошаговое выполнение программы тоже не поможет найти ее. В таком случае надо проверять сам алгоритм и убеждаться в его правильности.
Программа дает правдоподобные результаты
Это самая коварная ситуация. Получив результаты, близкие к предполагаемым, вы можете подумать, что программа работает правильно, и передать ее в эксплуатацию.
Как убедиться в том, что результаты правильны, а не правдоподобны? Здесь помогает тестирование программы. Тщательно подобранные тесты позволят отличить правдоподобные значения от правильных результатов. Как правило, одного набора тестов недостаточно для убедительного доказательства неверности работы программы. Специалисты-тестировщики всегда подбирают несколько наборов тестов так, чтобы точнее выявить дефекты программы.
Выявить правдоподобные результаты часто помогает прием, заимствованный из математики. Обычно мы проверяем правильность вычисления корня уравнения, подставляя его в уравнение и убеждаясь в том, что левая часть уравнения равна правой его части. Тем не менее, математикам давно известно, что из того, что левая часть уравнения, при подстановке в него приближенно вычисленного корня, почти совпадает с правой частью, вовсе не вытекает, что этот корень близок к настоящему корню уравнения.
Особенность таких некорректных задач заключается в том, что небольшое изменение исходных данных приводит к сильному изменению результата, хотя такой сильный скачок не вытекает из условий задачи. Это дает способ проверки правильности правдоподобных результатов. При тестировании программы надо провести серию испытаний с близкими значениями исходных данных и следить за тем, как меняются результаты ее работы. Неоправданно сильное изменение результатов при незначительном изменении данных должно вызвать сомнение в правильности вычислений, если только это не вытекает из условий задачи.
Локализация ошибки
После обнаружения ошибки надо найти место ее возникновения, как говорят, локализовать ошибку. Это не такая простая задача, как кажется поначалу. Ошибка может быть сделана где-то в начале исходного текста программы, а обнаружена позже, спустя несколько десятков строк исходного текста или даже в другой функции. Для локализации приходится делать обратный просмотр исходного текста программы, начиная от места обнаружения ошибки. В этом помогает трассировка программы, расстановка контрольных точек и пошаговое выполнение. Контрольная точка устанавливается в некотором отдалении от места обнаружения ошибки, в том месте, где по вашим соображениям может начаться неправильное выполнение программы. После этого тщательно проверяется участок программы от контрольной точки до места обнаружения ошибки.
Иногда такое обратное отслеживание хода выполнения программы не помогает. Тогда приходится прослеживать ее работу по исходному тексту, просматривая выполнение операторов со значениями, полученными из контрольной печати, и доходя до места обнаружения ошибки. Такое прослеживание часто называют прокруткой программы. Прокрутка программы — трудоемкое занятие, ее лучше проводить на небольшом участке программы, сузив предварительно участок прокрутки с помощью отладочной печати.
Когда и прокрутка не помогает, приходится проверять логику выполнения программы. Проверка начинается с места обнаружения ошибки. Просматривается полученная в этой точке отладочная печать, и проводятся рассуждения вроде следующих: "Такие результаты мог дать оператор А или оператор В. Но оператор В в этом случае не может выполняться. Значит, посмотрим на оператор А. Оператор А дал значение С, а оно могло получиться только в ситуации D. Чтобы возникла ситуация D, надо, чтобы...". На каждом логическом шаге приходится делать отладочную печать и небольшую прокрутку. Привлечение логических рассуждений помогает быстрее проделать эту трудную работу, поскольку концентрирует внимание только на тех переменных, которые могут получить ошибочные значения, а таких переменных немного.
Наконец, каждый программист знает, что при попытке объяснить ошибку, которая никак не поддается локализации, своему коллеге по работе или постороннему консультанту, неожиданно, в процессе рассказа, самому автору программного кода вдруг становится ясно, в чем заключается ошибка. Иногда даже письменное изложение проблемы помогает найти ее решение. Это объясняется тем, что при последовательном изложении проблемы мысли приходят в порядок, выстраивается логическая цепочка, приводящая к решению задачи. Поэтому очень важно периодически обсуждать возникающие проблемы всей командой разработчиков. Такие обсуждения не только позволяют устранять трудности, возникающие в процессе разработки, но и держат программистов в курсе всех задач, решаемых на каждом этапе реализации проекта.
Устранение ошибки
После того как ошибка обнаружена и найдено место ее возникновения, наступает время исправления программы. Некоторые ошибки, такие как неправильно записанные выражения, неверно определенные начальные значения переменных, неправильные входы и выходы из циклов, ошибки в логических условиях, исправить легко. Для этого достаточно изменить один или несколько операторов в исходном коде программы. После этого надо снова запустить те же наборы тестов, чтобы убедиться в том, что ошибки исчезли.
Другие ошибки, например, те, которые возникают из-за неправильно запрограммированного алгоритма, исправить сложнее. Их устранение требует изменения больших кусков программного кода. Такие изменения зачастую вносят в программу новые ошибки. Эти ошибки снова надо обнаруживать, локализовать и устранять. Процесс отладки становится циклическим. Его приходится повторять несколько раз. Как гласит шутливая аксиома отладки: "Каждая последняя ошибка является предпоследней".
Чтобы не попасть в неприятный цикл отладки или быстрее выйти из него, следуйте простому правилу: "Исправлять за один раз только одну ошибку". Тогда вы будете знать, из-за чего возникла новая ошибка, и сможете быстро устранить ее.
Труднее всего исправить ошибки алгоритма, заложенного в программу. Изменение алгоритма часто влечет переработку структуры программы, введение новых классов или значительное изменение существующих классов. Происходит возврат к этапу проектирования.
Наконец, не так уж редко встречается ошибка в определении требований к программе. Программа выдает не те результаты, которые ожидает заказчик программного продукта, да и вообще не то, что он хотел. Можно считать это не ошибкой, а недоговоренностью или недоразумением, но такое положение надо исправлять. Для исправления приходится возвращаться к самому первому этапу разработки и начинать все сначала, уточняя требования к программе.
Средства отладки
Трудоемкость процесса отладки всегда вызывала стремление автоматизировать его. С появлением первых компиляторов стали появляться и программы- отладчики (debuggers), называемые на жаргоне программистов "дебаггерами". Они предоставляют программные средства для выполнения основных работ по отладке. С их помощью легко установить контрольные точки, сделать трассировку и пошаговое выполнение программы, просмотреть текущие значения всех или выбранных переменных.
Отладчики тесно связаны с компиляторами. Для улучшения отладки компилятор может вставлять в машинный код дополнительную, отладочную, информацию, которую отладчик использует при прогоне программы. Поэтому отладчики чаще всего поставляются вместе с компиляторами, в одной интегрированной среде разработки IDE (Integrated Development Environment). В меню Options, или каком-нибудь другом меню, предназначенном для настройки параметров компилятора в такой интегрированной среде, можно выбрать один из нескольких режимов работы компилятора, в том числе отладочный режим, Debug, или окончательный режим, Release.
Во время разработки программы надо выбрать отладочный режим компилятора. Тогда можно будет использовать все средства отладчика, которые обычно перечислены в меню Debug интегрированной среды. После окончания отладки, когда уже решено передавать программу в эксплуатацию, компилятор надо перестроить на создание окончательной версии (release, build). В режиме Release компилятор удаляет из машинного кода отладочную информацию и генерирует оптимизированный рабочий код.
Тестирование
Нельзя сказать, что программа, успешно прошедшая тестирование, свободна от ошибок. Тем не менее, после серьезного тестирования можно запускать программу в промышленную эксплуатацию с большой долей уверенности. Практика показывает, что полностью протестированный программный продукт успешно справляется со своей задачей.
Тестирование не следует отождествлять с отладкой, хотя они тесно связаны. Задача тестирования — выявить наличие дефектов в программе, а задача отладки — отыскать их местоположение и устранить ошибки. Сначала с помощью тестирования надо найти ошибки, а потом, во время отладки, устранить их. Иногда тестирование и отладка выполняются одним специалистом в одном процессе, чаще их осуществляют разные люди.
Unit-тестирование
По сути дела, тестированием своего участка программы занимается каждый разработчик программного обеспечения. Написав какой-либо класс, процедуру или несколько процедур, программист обязательно проверяет их работу на характерных для этого кода наборах данных. Появившаяся недавно методика unit-тестирования возводит эту привычку в абсолютное правило. Эта методика предписывает проводить тестирование после написания каждой процедуры или класса. Более того, unit-тестирование обязывает писать тесты еще до создания исходного кода программы!
Допустим, мы решили написать класс комплексных чисел complex. По методике unit-тестирования мы начинаем с того, что пишем пустой класс complex и вместе с ним сразу же пишем класс Testcomplex, который будет впоследствии содержать тесты.
class Complex{};
class TestComplex{
Complex z;
public:
TestComplex(Complex z)
{
this.z = z;
}
void runTest(){ }
};Весь этот код сразу компилируется, чтобы убедиться в правильности написанной конструкции. Затем начинаем разработку класса complex. В процессе разработки каждый создаваемый метод класса complex записывается еще и в тестовый класс Testcomplex, например, следующим образом:
#include <iostream>
class Complex
{
double re, im;
public:
Complex(double a = 0.0, double b = 0.0)
{
re = a; im = b;
}
double mod()
{
return sqrt(re * re + im * im) ;
}
};
class TestComplex
{
Complex z;
public:
TestComplex(Complex z)
{
this.z = z;
}
void runTest(double result)
{
cout « testMod(result) « endl;
}
bool testMod(double result)
{
return z.modO == result;
}
};
void main()
{
Complex zl(), z2(0.0, 1.0), z3(3.0, -4.0);
TestComplex tl(zl), t2(z2), t3(z3);
tl.runTest(0.0);
t2.runTest(1.0);
t2.runTest(5.0);
}После компиляции и отладки этого кода сразу же начинается тестирование. Только после того, как все тесты выполнены успешно, продолжается создание класса.
Такая методика программирования получила название программирования, управляемого тестами (TDP, test-driven programming). Она вошла обязательной составной частью в быстро получившую популярность среди разработчиков свободного программного обеспечения методику экстремального программирования ХР (extreme programming). Unit-тестирование первоначально возникло в технологии Java. Не удивительно, что и наибольшее развитие получил свободно распространяемый программный продукт JUnit, автоматизирующий unit-тестирование Java-ioiaccoB. Для разработчиков, пишущих программы на языке С++, по аналогии с этим программным продуктом, создана библиотека классов, названная CppUnit.
Сейчас в распоряжении программистов есть множество программных продуктов, облегчающих unit-тестирование. Более того, есть продукты, генерирующие наборы тестов. Например, фирмой Parasoft Corporation создан и распространяется программный продукт JTest, подготавливающий тесты для JUnit.
Методики тестирования
За полувековую историю развития компьютеров предложено множество методик тестирования. Самая простая рассматривает программу как "черный ящик", внутренняя структура которого неизвестна. Испытатель проверяет работу "черного ящика", подавая на его вход определенные сигналы и наблюдая, как программа реагирует на них. Первым эту методику предложил, пожалуй, Козьма Прутков, сказавший: "Щелкни кобылу в нос, она махнет хвостом".
По методике "черного ящика" каждый тест задает исходные данные программе. Программа выполняется, после чего полученные результаты сравниваются с заранее известными тестовыми значениями. Такая методика покажет отсутствие ошибок только в том случае, когда набор тестов охватит все возможные исходные данные. Поскольку их необъятно много, всеобъемлющий охват исходных данных невозможен. Следовательно, теоретически нет уверенности, что такая методика выявит все ошибки. Кроме того, две ошибки могут взаимно уничтожаться на тестах и не будут выявлены по этой методике.
Другая методика обращается с программой как с "белым ящиком" или, другими словами, "прозрачным ящиком". Она учитывает исходный текст про��граммы. По этой методике набор тестов должен привести к выполнению каждого оператора программы и прохождению каждого из возможных путей выполнения программы хотя бы по одному разу. Эта методика хорошо проверяет логику выполнения программы, но тоже не может выявить все ошибки. Например, некоторые ветви программы могут быть просто упущены в процессе разработки, а такое тестирование не выявит их отсутствие.
Реальные методики тестирования используют оба подхода. Одни методики приближаются к "черному ящику", другие — к "прозрачному ящику". Так или иначе, в настоящее время практически во все наборы тестов включаются тесты, учитывающие исходный текст программы. Это значительно облегчает тестирование.
Пусть, например, надо протестировать программу, находящую площадь треугольника по длинам его сторон а , b, с. Если мы знаем, что эта программа вычисляет отдельно площадь прямоугольного треугольника как полупроизведение его катетов, и отдельно площадь остальных треугольников по формуле Герона, то нам не надо создавать огромное количество тестов. Мы можем разбить все множество исходных данных а , b, с на два класса — образующих прямоугольный треугольник и не образующих его — и прогнать всего по одному тесту для каждого класса.
По своему назначению тесты делятся на несколько групп:
□ функциональное тестирование;
□ тестирование обращений к базам данных;
□ тестирование логики программы;
□ нагрузочное тестирование;
□ стрессовое тестирование;
□ тестирование интерфейса пользователя;
□ тестирование безопасности и прав доступа;
□ тестирование инсталляции программного продукта. Рассмотрим подробнее каждую из этих групп тестов.
Функциональное тестирование
Это основной вид тестирования, проверяющий соответствие программы функциональным требованиям, предъявленным к ней на самом первом этапе проектирования программного продукта. Функциональное тестирование призвано убедиться в правильности ввода исходных данных, обработки и вывода результатов, а также в правильности работы всех элементов управления программой. Для этого проигрываются все сценарии использования программы (use case). При этом в тестах задаются и правильные и неправильные входные данные. Это позволяет проверить реакцию программы на ошибки ввода.
В большинстве функциональных тестов программа рассматривается как "черный ящик", поскольку проверяется работа программы, а не ее реализация. Тем не менее, как уже говорилось выше, знание алгоритма и исходного текста программы может помочь в проверке правильного ее функционирования.
уравнение ax + Ьх + с = 0 с действительными коэффициентами. Для этого надо подготовить тестовый набор коэффициентов а, b, с, учитывающих все возможные ситуации. Не зная о том, что решение уравнения зависит от знака дискриминанта, мы можем упустить один из тестов, приводящих к положительному или отрицательному дискриминанту. Зато, зная алгоритм нахождения корней, мы можем разбить все тестовые значения коэффициентов на те, которые дают неотрицательный дискриминант, и те, для которых дискриминант отрицателен. В каждой группе можно взять только один набор значений коэффициентов а , b, с. Дополнив этот набор вырожденными и граничными значениями, мы получим полный набор тестов.
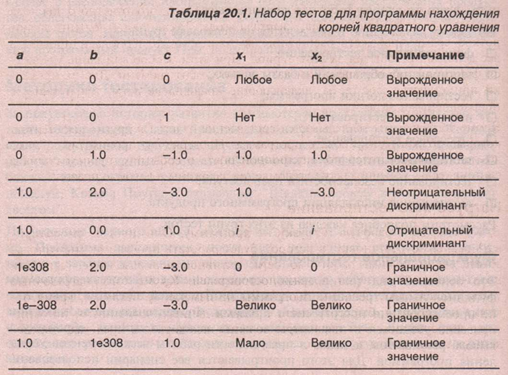
Успешно выполнив этот набор, мы можем быть уверены, что обычный школьный алгоритм решения квадратного уравнения работает правильно. Конечно, такую уверенность дает только простота задачи, которую решает тестируемая программа. В реальных условиях убедиться в полноте набора тестов гораздо труднее.
Тестирование обращений к базам данных
Этот набор тестов проверяет правильность связи программы с базами данных, в которых она хранит информацию. Тесты должны проверить все используемые программой обращения к базам данных. Их надо проделать как с верными данными, так и с ошибочными, чтобы убедиться в том, что база данных сохраняет целостность во всех случаях.
Это тестирование предполагает знание методов обращения к базе данных, примененных в программе, а также знание особенностей используемого программой сервера базы данных. Поэтому подход к программе, как к "черному ящику" здесь не годится. Подготовка наборов тестов должна вестись со знанием использованных в программе связей с базой данных.
Тестирование бизнес-логики программы
Тестирование деловых правил, заложенных в программу, призвано проверить правильность ее работы в течение определенного отчетного периода времени: дня, недели, месяца, квартала, года. Такие тесты должны за короткое время пробежать расписание всего отчетного периода и проделать все действия и события за этот период. При этом особое внимание уделяется функциям, обрабатывающим даты и интервалы времени. Для их проверки применяются как тесты, включающие правильные даты, так и тесты с неправильными датами.
Кроме того, в тесты закладывается составление отчетов и других документов, которые должна генерировать программа. Проверяется, происходит ли уведомление пользователей по электронной почте о событиях, происходящих в системе, если, конечно, такие уведомления заложены в деловые правила.
Нагрузочное тестирование
Эти тесты дают рабочую нагрузку на программу. Они должны смоделировать реальную обстановку, в которой будет работать программа: многопользовательский режим, работу по сети, активное использование устройств ввода-вывода, принтеров и графопостроителей. Кроме того, нагрузочные тесты отслеживают реакцию программы на изменение нагрузки, время отклика на события, быстроту связи с базами данных, удаленными источниками информации. Эти параметры должны находиться в пределах, определенных техническим заданием.
Нагрузочное тестирование должно проверить, как программа использует все необходимые ресурсы компьютера, и убедиться в том, что она правильно работает в заданных условиях.
Стрессовое тестирование
Стрессовое тестирование заключается в том, чтобы дать предельные нагрузки на программу с целью проверить ее работу в условиях дефицита ресурсов. Эти тесты должны проверить работу программы при недостатке оперативной памяти, превышении пропускной способности сетевых средств, переполнении каналов ввода-вывода, одновременного доступа большого количества пользователей и т. п. Успешное выполнение стрессовых тестов даст уверенность в том, что программа сохранит работоспособность при перегрузках.
Для программ, рассчитанных на быстрое восстановление после сбоев, стрессовое тестирование должно сымитировать такие сбои, чтобы проверить способность восстановления.
Стрессовые тесты полезны не только для выявления дефектов программы, но и для получения информации о реакции программы на пиковые нагрузки. Эту информацию затем можно включить в инструкцию по эксплуатации программы.
Тестирование интерфейса пользователя
Тестирование интерфейса содержит наибольший объем ручной работы. Тес- тировщик должен проверить работу всех элементов управления, открыть все окна, имеющиеся в программе, пройти и опробовать все пункты меню. Ему надо попытаться проделать и всевозможные неправильные действия пользователя, чтобы проверить реакцию программы на ошибки использования интерфейса.
Во время тестирования интерфейса следует вводить всевозможные значения во все поля ввода, чтобы проверить, отвечает ли их диапазон требованиям, предъявленным к программе. Необходимо вводить и невозможные значения, например, в числовые поля вводить символьные данные, чтобы просмотреть сообщения системы, сделанные в ответ на ввод неправильных данных.
Тестирование безопасности и прав доступа
Подсистема безопасности требует отдельного тестирования. При этом проверяются регистрация новых пользователей, локальный и удаленный доступ к системе, разграничение прав доступа к ней. Очень часто система строится так, что одни пользователи могут только просматривать доступную им информацию, другие пользователи могут добавлять, редактировать и удалять ее, а третьи могут менять права пользователей первых двух категорий. Все это обязательно надо протестировать и проверить, правильно ли определяются права пользователей на те или иные действия в системе.
Для тестирования безопасности в системе создаются несколько временных пользователей с разными правами доступа. Тесты выполняются несколько раз от имени каждого из них. В наборе тестов следует предусмотреть все действия пользователя, имеющиеся в программе, и посмотреть, какие из них разрешены пользователю, а какие — нет.
Тестирование инсталляции программного продукта
Первая функция программного продукта, с которой сталкивается пользователь, — это его установка на компьютер. Если установить продукт не удастся, то потребитель откажется от него. Если при установке возникнут трудности, то пользователь потеряет доверие к продукту и к фирме — разработчику этого продукта. Поэтому необходимо тщательно протестировать процесс инсталляции на разном оборудовании, обратив внимание на безошибочное выполнение повторной установки, обновления предыдущей версии, адаптации к разному оборудованию.
Наборы тестов
Набор тестов (test suite) следует подготовить еще до проектирования программного продукта, на этапе определения требований к нему. Именно требования к программе и составляют круг тех задач, которые должны быть выражены в тестовых заданиях. Кроме того, спроектировав систему, уже трудно беспристрастно оценивать ее. Направление мысли разработчика во- лей-неволей будет идти в русле готового проекта, а это помешает всесторонней оценке проделанной работы. Поэтому подготовку тестов и последующее тестирование следует поручить не разработчикам проекта, а профессионально подготовленной команде специалистов-тестировщиков.
Как составить набор тестов? Это целиком зависит от тестируемой программы и требований к ней. Здесь можно дать только самые общие рекомендации. Во-первых, для каждой из перечисленных выше групп тестов надо составить свой набор тестов. Во-вторых, надо подобрать набор тестов, работающих с программой как с "черным ящиком", рассмотрев все возможные области значений исходных данных. В-третьих, надо изучить исходный текст программы и подобрать тесты для прохождения всех путей алгоритма, заложенного в программу, и тесты для выполнения каждого оператора программы.
Каждый отдельный тест, называемый специалистами тестовым случаем (test case), состоит из исходных данных, вводимых в тестируемый программный модуль, и предполагаемого результата, который должен получить модуль.
Результатом не обязательно должны быть значения, возвращаемые модулем. Это могут быть обновления базы данных, изменения в конфигурационных файлах, отправка сообщений по сети. Важно, чтобы это были четко отслеживаемые значения, влияющие на ход выполнения программы.
Процесс тестирования
Не следует думать, что тестирование завершает разработку и тестировать надо уже готовую программу. Напротив, этот процесс надо начинать на самых ранних стадиях разработки. Тестирование может выявить упущения в проектировании программного модуля, а такие упущения лучше устранить пораньше. Кроме того, известно, что исправление одних ошибок часто вносит другие. Хотя общее число ошибок уменьшается, после каждого исправления приходится снова тестировать программу. Таким образом, тестирование вклинивается в процесс разработки. По этим причинам сейчас получила большую популярность методика непрерывного тестирования программы во время ее разработки. Она называется zero-defect mindset.
Согласно методике zero-defect mindset, все ошибки подразделяются на несколько уровней по своей грубости. Программист не имеет права добавлять новую функциональность в программу, пока он не исправит все крупные ошибки до определенного уровня. Допустимый уровень ошибки устанавливается для каждого этапа разработки, он повышается по мере завершения работы.
Итак, по всем современным методикам тестирование выполняется прямо в процессе разработки. При тестировании программы, состоящей из нескольких программных модулей, надо выбрать один из двух противоположных стилей тестирования: тестирование снизу вверх или тестирование сверху вниз.
Тестирование снизу вверх начинает с отдельных подпрограмм: функций и процедур, не вызывающих другие подпрограммы. На их вход подаются тестовые данные, результаты их работы сравниваются с тестовыми результатами. После того как тесты уже не выявляют ошибок в таких подпрограммах, тестировщик переходит к тестированию подпрограмм, вызывающих уже протестированные подпрограммы. При этом выявляются ошибки, возникающие при взаимодействии подпрограмм. Затем тестируются подпрограммы, вызывающие только что протестированные подпрограммы и т. д. Наконец, в последнюю очередь проверяется работа головного модуля всей программы.
Тестирование сверху вниз, напротив, начинает сразу с готового прототипа головного модуля программы. Вместо подпрограмм, вызываемых из головного модуля, подставляются заглушки (stubs), выдающие головному модулю заранее определенные значения. Убедившись в правильности работы такого скелета всей программы, тестировщик начинает по очереди заменять за- глушки настоящими подпрограммами или их прототипами, пока не дойдет до самых мелких программных единиц, уже не вызывающих никакие другие подпрограммы.
На практике тестировщики редко следуют в чистом виде тому или иному стилю тестирования. Чаще всего одновременно тестируются и отдельные программные единицы, и прототип головного модуля, а окончательная сборка всей программы происходит где-то посередине. В некоторых случаях задача ставится таким образом, что надо протестировать сразу и головной модуль, и какие-то отдельные подпрограммы. В других случаях те или иные модули и программные единицы просто не готовы к тестированию.
Какова бы ни была методика тестирования, сразу же после исправления ошибки прогоняется тот же набор тестов, с помощью которого была найдена ошибка. Это так называемое регрессионное тестирование, позволяет убедиться в том, что ошибка исправлена. Если регрессионное тестирование не выявило дефектов в программе, то этот набор тестов можно отложить и перейти к следующему этапу тестирования.
Особенности тестирования объектно-ориентированных программ
Объектно-ориентированный подход к программированию накладывает свой отпечаток и на методику тестирования. Вместо тестирования функций, процедур и прочих программных модулей, производится тестирование классов, связей между ними и иерархий классов.
Количество классов, их строение и взаимодействие между ними определяются на стадии объектно-ориентированного проектирования. На этой стадии создаются диаграммы классов и диаграммы связей. Зачастую по этим диаграммам генерируется исходный программный код в виде абстрактных классов и/или интерфейсов. После этого уже можно провести полноценное тестирование полученной модели. Исправление ошибок на такой ранней стадии позволит значительно сэкономить время отладки и всей разработки в целом. Более того, тестирование поможет выяснить, соответствует ли модель требованиям, предъявленным к программному продукту, и своевременно исправить проект.
Тестирование объектно-ориентированных программ чаще всего выполняется снизу вверх. Вначале проверяется программный код методов класса и тестируются отдельные методы. Затем начинается тестирование класса.
Для тестирования класса пишется тестовая программа, в которой создаются объекты класса с разными значениями его полей. Тестовая программа проверяет выполнение контрактов методами классов. Для этого она обращается ко всем методам класса и отслеживает результаты их выполнения. При проверке работы методов, обращающихся к другим объектам, создаются объек- ты-заглушки, содержащие только поля и методы, нужные для тестирования основного объекта. Поля объекта-заглушки получают определенные, хорошо узнаваемые значения. Методы объекта-заглушки очень просты, они только сигнализируют каким-нибудь образом обо всех обращениях к ним.
Тестирование шаблонов классов требует особого внимания. Здесь легко допустить ошибку и трудно обнаружить ее. Разработчик должен в точности знать, какой класс создаст компилятор по шаблону, написанному им, а для этого нужен большой опыт работы с этим компилятором. Тестировщик тоже должен знать особенности компилятора, чтобы создать тесты для каждого класса, создаваемого по шаблону.
После того как тестирование отдельных классов уже не выявляет ошибок в них, создаются объекты разных классов, и проверяется их взаимодействие. Выстраивается иерархия классов и тестируется правильность наследования в этой иерархии. Здесь удобнее стиль тестирования сверху вниз, от базовых классов к порожденным классам, от вершины иерархии классов к самым конкретным классам. Для тестирования абстрактных классов специально создаются его реализации-заглушки.
Особую трудность вызывает тестирование классов, использующих полиморфизм. Каждый объект такого класса обладает своим поведением, отличным от поведения других объектов того же типа. Тип объекта маскируется, класс полиморфного объекта трудно определить, поэтому нелегко проверить контракт объекта, тем более что в процессе разработки такие объекты могут легко заменяться другими объектами того же типа. При составлении тестов приходится учитывать будущее поведение полиморфного объекта, а для этого надо хорошо знать разрабатываемый проект.
Средства тестирования
Процесс автоматизации коснулся и тестирования. Множество фирм занимается выпуском программных продуктов, предназначенных для тестирования. Наиболее известны компании: Parasoft Corporation, TestQuest, Optimyz Software, Segue Software, Compuware Coiporation, AutomatedQA Corporation. Ими и другими фирмами создано множество программных продуктов, облегчающих и автоматизирующих этот процесс. Мы уже упоминали JUnit, JTest, CppUnit. К ним можно добавить программные продукты Rational Functional Center, Insure++, ITG Center, SilkPerformer, CARS. Это только малая часть средств автоматизации тестирования и генерации тестов.
Такое многообразие программных инструментов тестирования объясняется не только важностью и актуальностью самой задачи тестирования, но и тем, что эта задача сильно специализирована. Почти каждый новый программный продукт ставит новые задачи тестировщикам. Для их решения приходится разрабатывать новое средство автоматизации или значительно моди- фицировать имеющиеся средства. Некоторые из этих новых средств получают дальнейшее развитие и распространение, другие завершают свой жизненный цикл с завершением тестирования.