Средства автоматизации анализа вредоносных программ

На днях попал мне в руки мартовский образец программы-вымогателя REvil, интересно было уточнить одну деталь. Образец оказался обфусцированным, в нем зашифрованы строки и конфигурация, а также еще и обфусцированы вызовы функций API. Сделано это было авторами, разумеется, для того, чтобы программа не обнаруживалась статическими анализаторами антивирусов (сигнатурным и эвристическим) и прочими средствами поиска по паттернам, а также, чтобы затруднить эксперту статический анализ в дизассемблере.
Можно же запустить в виртуалке, скажете вы. Почему нет!? Но тут два варианта. Очевидный и ожидаемый – пошифрует файлы в гостевой операционной системе. По крайне мере, результат! Убедимся, что действительно шифровальщик, а не, например, шпионская программа, как иногда гласит вердикт какого-нибудь антивируса. А неочевидный вариант, но наиболее вероятный, программа вообще не запустится. И тут даже дело не в виртуалке, как таковой, а в ее региональных и языковых настройках, а они, скорее всего, будут такими же, как и в хостовой операционной системе, например, российскими. Дело в том, что REvil (они же Ransomware Evil или Sodinokibi) – одна из криминальных группировок с постсоветского пространства, промышляющая (или всё же промышлявшая?) вымогательством. И у наших земляков-киберробингудов есть (или был?) своего рода кодекс чести – бедняков и своих, то есть нас с вами, не обижать, поэтому в программах проверяются региональные настройки системы, используемые раскладки клавиатуры и т.п., и они не осуществляют шифрование, если хоть что-то соответствует стране из состава бывшей одной шестой части суши. На самом же деле это шутка, а причина куда прозаичная – боязнь ответственности перед местными правоохранительными органами. В связи с этим вспоминается рассказ деда, после войны он в Воронежской области был бригадиром охотников. Когда в деревне массово начинали пропадать куры, а обычно это было связано с появлением в деревне хорька, собирались с каждого двора и выясняли, у кого же куры не пропадают. В итоге оказывался один двор – такой островок безопасности, где куры совсем не исчезали в отличие от соседних домов. Сразу понимали, что вот в этом-то дворе хорек и поселился. Умное животное, что сказать, у себя не ворует, чтоб не вызвать подозрений.
Вообще же с REvil накануне произошла необъяснимая и темная история, они в одночасье исчезли из паблика, а у последней и самой крупной жертвы – IT-компании Kaseya таинственно появился универсальный декриптор. Совпадение? Не думаю! Такое впечатление, что к хулиганам на детской площадке вышел местный авторитетный и крепкий дядя… "Дядь, мы все поняли, сейчас только бычки за собой подберем…". И хулиганы вроде как разбежались.
Возвращаясь к образцу… Посвящать статью его анализу совершенно нет смысла, есть уже много удачных публикаций с результатами анализа REvil. Кстати, риторический вопрос, стоит ли вообще исследовать программы-вымогатели (ransomware)? По-моему мнению, с практической точки зрения – нет! А что собственно является целью такого анализа? Выявить уязвимости в криптосхеме, которые бы позволили без выплаты выкупа расшифровать файлы или облегчить подбор ключа для расшифровки? Увы, сейчас это большая редкость, и эти времена в далеком прошлом. Да, были случаи, когда разработчики ошибались с реализацией алгоритмов шифрования. Так было, например, с ошибками в реализации алгоритма salsa20 в Petya. Или использование уязвимого алгоритма генерации случайных чисел для ключей шифрования, например, наподобие srand(time(NULL)) и далее rand(), который позволяет сравнительно просто подобрать ключ. Современные шифровальщики редко балуют такими штуками и практически не имеют уязвимых мест. Хотя всё же обманываю, у некоторых активных по сегодняшний день шифровальщиков, есть небольшая возможность сдампить ключи шифрования в процессе шифрования. С другой стороны, целью анализа может быть благородное желание "посадить вора в тюрьму" и выявить в коде хоть какие-то артефакты, позволяющие найти преступника. Увы, но и это тоже малоперспективно.
Поэтому программы-вымогатели в основном анализируются с исследовательской точки зрения, и, надо отметить, есть очень интересные результаты исследований. Вот и этот образец REvil послужит в учебных целях для демонстрации средств автоматизации анализа, в основном для деобфускации для последующего анализа. В статье мы рассмотрим несложные вещи, но наличие некоторого базового уровня все же приветствуется.
Не забываем про меры безопасности. А то беда иногда приходит оттуда, откуда ее совсем не ждешь. Как-то давно один товарищ решил запустить программу-локер в песочнице. Товарищ выбрал реальную среду в качестве тестовой (тогда это была XP), ну и для верности запустил на нескольких песочницах и пошел спокойно домой, дело было вечером. Разработчик песочницы подошел к вопросу построения "рационально", использовал на жестких дисках несколько разделов: один под управляющую систему, а остальные для развертывания "реальных" песочниц. Как оказалось, этот локер перезаписывал загрузчик MBR, а после перезагрузки выводил DOS-окно для ввода пароля для восстановления MBR. Следующее утро, как вы понимаете, было бодрым, сервера песочницы перезагрузились и вывели окна локера. Пароль в DOS-коде локера был просто заксорен, поэтому легко был извлечен. MBR был восстановлен, но загрузчик UNIX управляющей системы не пережил. Поэтому надо быть очень осмотрительным, и не наступать на грабли, а тем более на детские, потому как это намного больнее.
Речь дальше пойдет, прежде всего, о статическом анализе в дизассемблере IDA Pro. Хотя статический анализ не предполагает выполнение кода, на одном этапе все же прибегнем к отладчику, куда без него. Вообще же статический анализ удобно совмещать с динамическим, для этого неплохо бы иметь два монитора: на одном – открытый дизассемблер, на другом – виртуальная среда с отладчиком. Но лучше, конечно, иметь три монитора, на третьем мониторе можно изучать документацию, гуглить или писать, например, одновременно с анализом отчет. Много мониторов для реверса не бывает!
Предварительно, перед дизассемблером можно взглянуть на образец в hex-редакторе, умеющем работать с различными форматами исполняемых файлов (PE32, Elf, Mach-O и т.д.). Давно и с удовольствием в качестве такого пользуюсь Hiew. Знаю, что некоторым не нравится Hiew, а его синее окно вызывает некоторую аллергию. Конечно, можно использовать и другие редакторы, такие как, 010Editor, PEstudio, PE Explorer, CFF Explorer и т.п. Кому, что нравится, это дело вкуса и привычки.
Посмотрим в редакторе на PE-заголовок, секции и импорт.
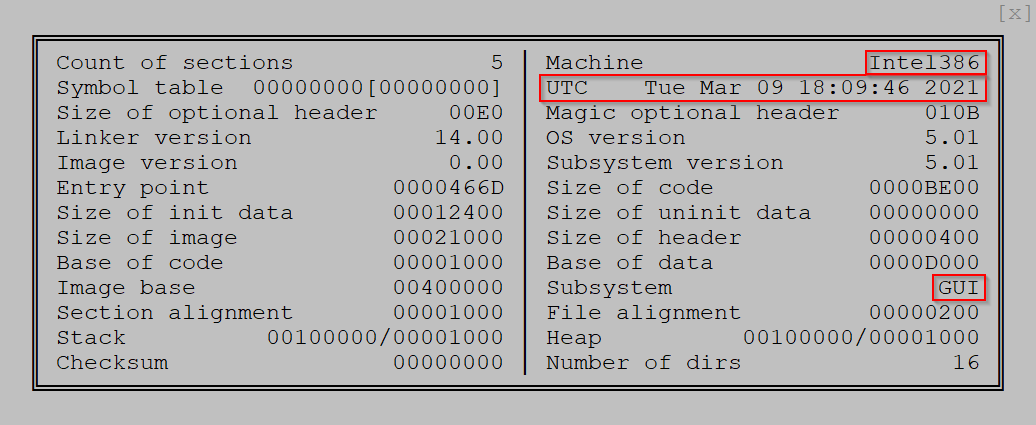
Из основных полей PE-заголовка видим, что перед нами 32-разрядное GUI-приложение, время компиляции – 2021-03-09 18:09:46 (UTC). Разумеется, что достоверность этого поля не велика, оно легко может быть изменено.
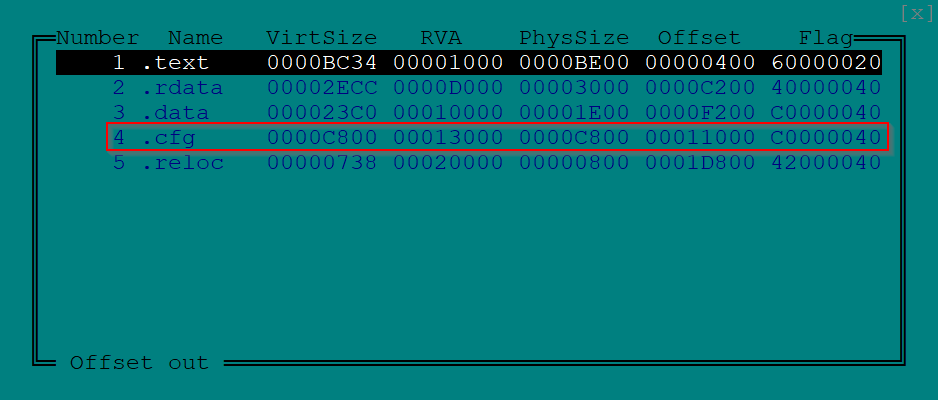
Просматривая список секций, в глаза сразу бросается нестандартная секция ".cfg", к тому же имеющая достаточно солидный размер – 51 200 (0С800h) байт.
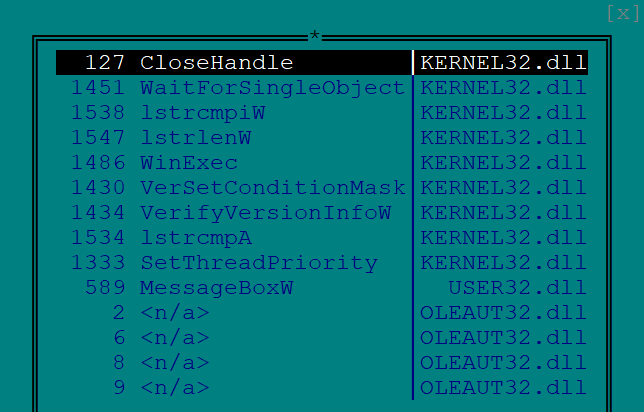
А вот малое число импортируемых функций может говорить о том, что программа обфусцирована. При этом визуальный просмотр кода в том же редакторе показывает, что сама программа вряд ли запакована, а обфускация, скорее, применялась авторами на этапе разработки программы, а не уже к готовому скомпилированному модулю. Открываем в IDA Pro, видим, что и карта навигатора в IDA выглядит достаточно стандартно, не в пользу версии "навесной" обфускации.

По моему мнению, анализ вредоносных программ – процесс весьма творческий, поэтому у каждого реверс-инженера свои подходы и стили. Важна и глубина анализа, которая зависит от поставленных целей. Открывая образец в IDA, дальше многие действуют по своему алгоритму. Бывает и так, что образец попадается совсем "тяжелый" и непонятный, и не знаешь, с какой стороны к нему подойти. По поводу непонимания, один институтский преподаватель, не помню, правда, математики или физики, сказал давно одну замечательную фразу, когда мы, студенты, пожаловались ему, что нам ничего не понятно. На это он задорно ответил: "Чтобы понять, надо привыкнуть!". Вроде бы все банально, но есть в этом что-то. Вот читаешь учебник или техническую литературу, и совсем ничего не понятно. Читаешь еще раз, уже встречаются знакомые термины, обозначения, так начинаешь привыкать к стилю изложения, а потом и к содержимому, и, в конце концов, рано или поздно приходит-таки прояснение и понимание. Так и с "тяжелыми" образцами, привыкаешь к коду, потом начинаешь понимать стиль и подходы автора, еще дальше предугадывать логику работы, строить гипотезы, большинство из которых оказывается верными. Как вариант, в таких образцах можно начать с импорта и просто медитировать, "причесывая" данные, чтобы зона данных в навигаторе IDA "посерела". Вот так просматриваешь данные и видишь… О! Это знакомо – массив данных от такой-то математической или другой стандартной функции RTL (Runtime library), и IDA не всегда, но очень часто помогает в этом. С какого-то момента начинают идти пользовательские данные, встречаешь интересные строки, знакомые массивы для какого-нибудь алгоритма шифрования, зашифрованные данные… Можно, на основе этого раскручивать цепочки кода, и так начать складывать паззл.
Расшифровка данных
Ранее, при просмотре в Hiew зацепила секция ".cfg", вот и "потянем эту ниточку" дальше в IDA Pro.

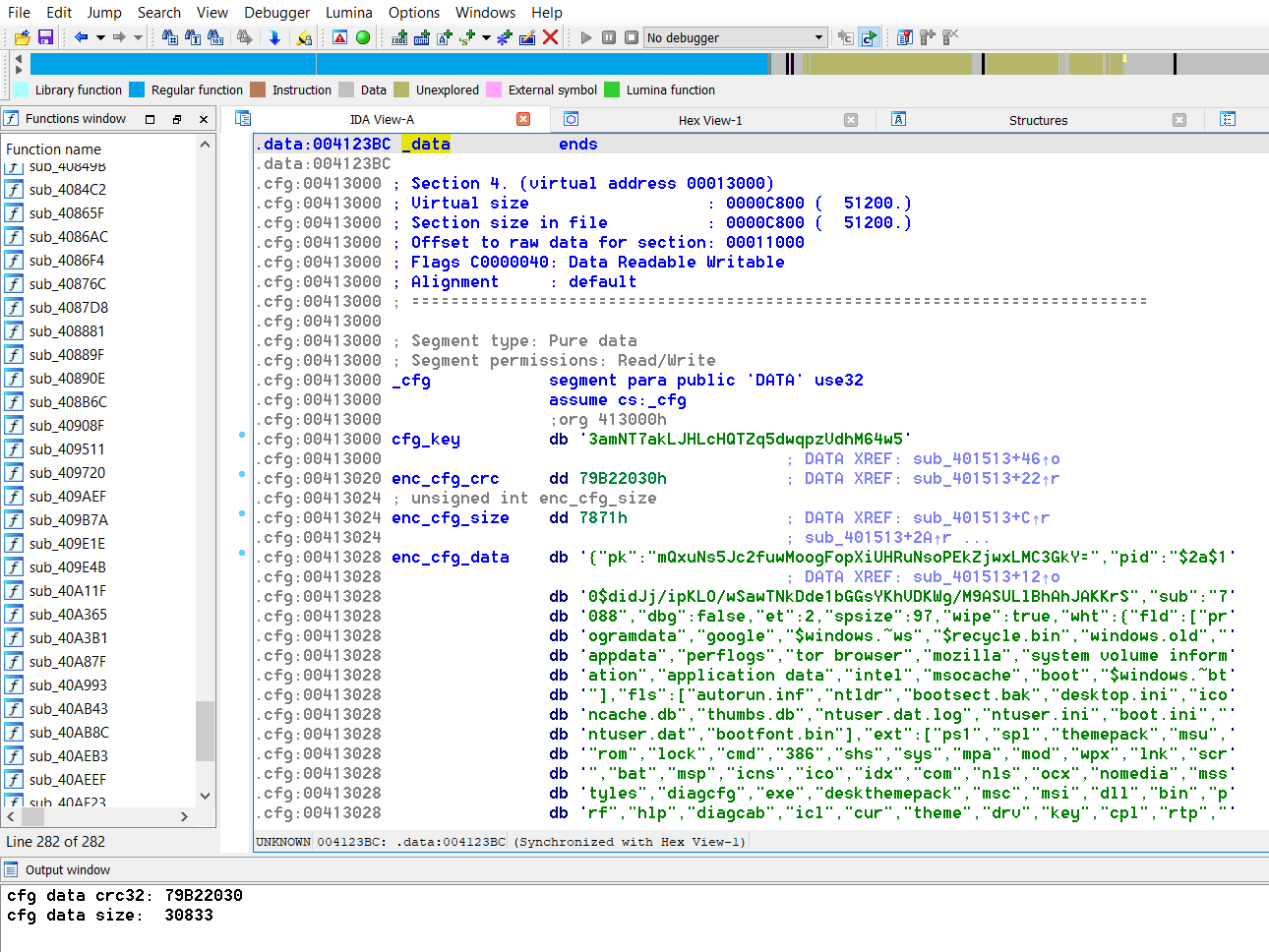
Итак, что показывает IDA Pro? Метки и типы данных дизассемблер расставил в зависимости от кого, как на них производятся ссылки в коде. unk_413000 – видно, что это строка, состоящая из 32 символов, dword_413020 – некое 32-битное значение (79B22030h), dword_413024 – 32-битное значение (7871h), а unk_413028 – на изображении этого не видно, но это достаточно большой массив данных. Можно сразу предположить, что 7871h (30 833) – размер данных unk_413028. И в этом можно убедиться, если изучить структуру данных unk_413028. Окажется, что после 30 833 байт "случайных" данных следуют нулевые байты (20 327 байт), которые, просто резервируют место и в данном конкретном случае не используются. Исходя из такой структуры данных, опять же можно предположить, что все данные секции ".cfg" записываются авторами в уже готовый скомпилированный образец. Обычно так делается с конфигурационными данными, чтобы каждый раз не перекомпилировать образец.
Смотрим, где используются данные unk_413028 (xrefs). Используются только в одном месте, вот этот фрагмент кода:
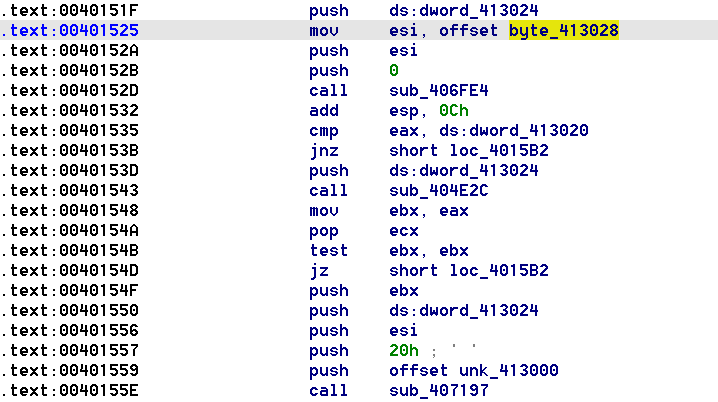
Данные unk_413028 используются в функциях sub_406FE4 и sub_407197. Взглянем на код функции sub_406FE4, аргумент arg_0 определяет начальное значение, arg_4 содержит адрес данных (указатель) и arg_8 – их длину. Изменения данных в функции не происходит, а с помощью вычислительных манипуляций с ними вычисляется некоторое значение.

И тут стоит сказать про очень важный навык реверсера. Это умение узнавать распространенные криптографические алгоритмы и алгоритмы сжатия. Есть удобные вспомогательные средства для этого, например, плагины к IDA findcrypt, findcrypt-yara и им подобные. Они идентифицируют алгоритмы по используемым в них таблицам данных и "магическим" числам, и можно эти плагины в дальнейшем дорабатывать под свои нужды. Но иметь наметанный глаз куда важнее.
Очевидно, что функция sub_406FE4 – это функция получения значения контрольной суммы по алгоритму CRC32. Можно привести ее в порядок: переименовать аргументы и определить тип функции, нажав "y" на имени функции:
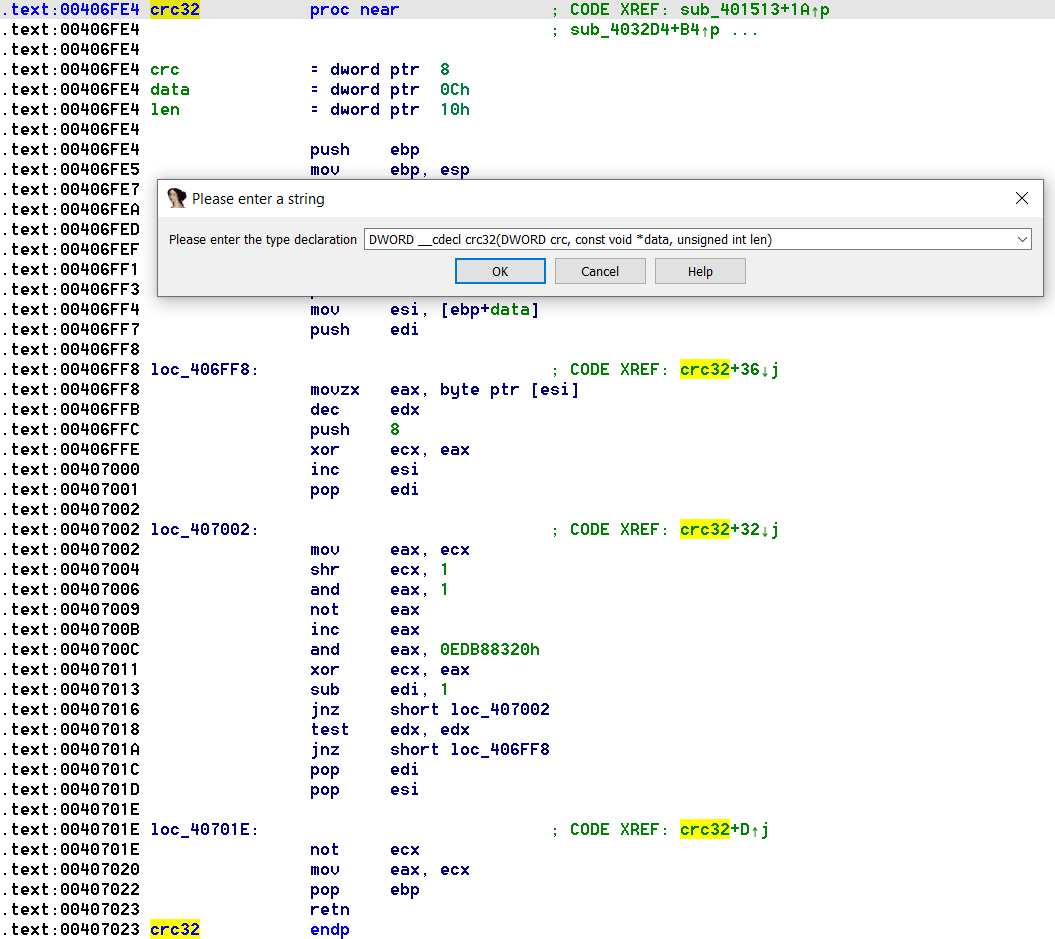
Если вернуться к первому фрагменту кода, станет понятным, что вычисляется контрольная сумма CRC32 для данных unk_413028, длина которых определяется значением в dword_413024(7871h). Вычисленное значение CRC32 проверяется с контрольным значением в dword_413020 (79B22030h). Так осуществляется проверка целостности данных unk_413028. Далее после проверки целостности длина данных (dword_413024) в качестве единственного аргумента передается в функцию sub_404E2C.

В этой функции, как раз и встретилась обфускация вызовов функций API, о которой говорилось в самом начале, то есть dword_41150C и dword_411320 – адреса функций API, которые пока неизвестны. Чтобы не мешать все в кучу, закончим с расшифровкой данных, а к деобфускации вызовов функций API вернемся позже. Но зададимся вопросом, что может делать эта функция, получающая на вход размер данных и возвращающая значение, которое при ненулевом значении используется при вызове следующей функции – sub_407197? Конечно, выделять память! И пока обойдемся этим, а потом удостоверимся в этом.
А теперь более интересное – код функции sub_407197, внутри нее вызываются функции sub_406E89 и sub_406EE1.

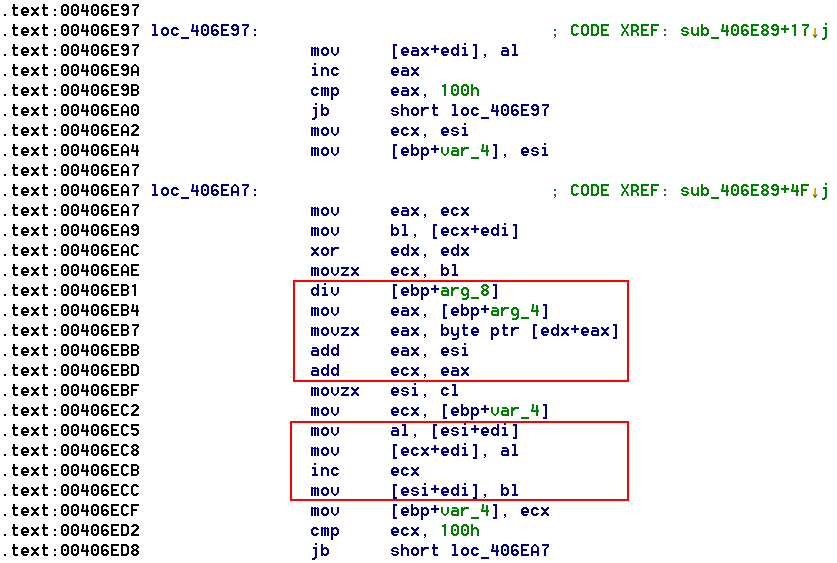

Я уже выше говорил про важное умение распознавать криптографические алгоритмы, и плагины вряд ли помогут в этом случае, ведь нет никаких таблиц и "магических" чисел, просто алгоритм. В принципе, можно, конечно, написать YARA-правило на паттерны кода этого алгоритма, но вариантов реализации алгоритма будет много, и каждый раз придется учитывать конкретную реализацию. Надеюсь, вы узнали нестареющий и горячо любимый многими разработчиками вредоносного ПО потоковый алгоритм шифрования RC4. В функции sub_406E89 идет формирование S-блока, а в sub_406EE1 с помощью генератора псевдослучайной последовательности осуществляется шифрование/расшифровка данных.
И теперь все встало на свои места, стала понятна суть кода, и можно расшифровать данные.
Приведенный в порядок код в IDA:

В зависимости от сложности кейса приходится иногда много программировать. Поэтому какой-нибудь универсальный интерпретируемый язык должен быть обязательно в арсенале реверсера. Достаточно давно в качестве такого языка наиболее популярен, конечно, Python. Он реализован во многих инструментах, используемых для анализа, есть много полезных готовых программ на гитхабе. Мой чудаковатый друг очень давно мне посоветовал учить Python, о нем тогда мало кто слышал. И друг все твердил, что скоро Python станет самым популярным интерпретируемым языком. Но я не слушал, мучился, плевался, но учил модный тогда Perl, при этом накупил всяких толстых книжек по нему. А сейчас всю хочу отдать их на макулатуру, да жалко.
Итак, проанализированный код выше реализуем на языке программирования Python
Программа расшифровки данных на Python
Вот такие конфигурационные данные в формате JSON в итоге расшифровуются после запуска скрипта. Начальная часть их на изображении:

Ух, сколько доменов! Насчитал всего 1 230! Злоумышленники накидали в кучу еще легальных, чтобы замаскировать свои, на которые шифровальщиком будет направляться идентификационная информация. Нечто похожее было ранее реализовано в семействе DorkBot в 2017 году. Только там авторы подошли к вопросу более креативно: в теле бота содержался большой список доменов (около полторы тысячи), среди которых были действующие командные центры бот-сети, так дополнительно еще постоянно генерились случайные домены, и осуществлялись попытки их разрешения. Это дало неожиданный побочный эффект, авторы DorkBot и предположить не могли, что под Новый 2018-ый год благодаря их усилиям "лягут" часть DNS-серверов.
А теперь тот же самый код расшифровки, только на IDAPython. И сразу хочу дать совет по справке IDAPython… Лучше не читать ее! Но это сугубо мое личное мнение. Изучать лучше исходники IDAPython, которыенаходятся в каталоге "python" IDA, или просто "грепать" их. А самое главное, надо обрастать скриптами IDAPython, на основе которых будут разрабатываться новые.
Программа расшифровки данных на IDAPython
Этот код делает то же самое, но демонстрирует часть широких возможностей IDAPython: устанавливает имена и типы переменных, получает данные образца из базы данных IDA, заменяет зашифрованные данные расшифрованными. Последнее в данном примере – все-таки лишнее, но часто такая возможность бывает полезной. Повторный запуск из-за этого соответственно приведет к ошибке, так как из-за пропатченных расшифрованных данных не совпадут контрольные суммы.
Ну и, собственно, результат работы скрипта IDAPython:
Источник: https://habr.com/ru/post/570200/