Реализация своего АПИ на Rust с помощью Tokio и Wrap

Сейчас вам поведаю о создании своего API сервиса на основе Warp и Tokio.
Это является перевод данной статьи.
Структура
Прежде чем приступить к написанию кода, нужно немного продумать структуру API. Это поможет определить нужные эндпоинты, контроллеры и способы хранения данных.
Роуты
Для своего апи я определил два роута
/customers
- GET -> получить список пользователей
- POST -> создать нового пользователя и добавить инфомацию в хранилище
/customers/{guid}
- GET -> получить информацию о пользователе
- POST -> обновить информацию о пользователе
- DELETE -> удалить пользователя из хранилищаОбработчики
На основе маршрутов мне потребовалось определить несколько обработчиков
list_customers -> вернуть список пользователей create_customer -> создать нового пользователя и добавить его в базу данных get_customer -> вернуть информацию о конкретном пользователе update_customer -> обновить информацию о пользователе delete_customer -> удалить пользователя из базы данных
База данныхчто
Для примера я буду использовать in-memory хранилище.
Чтобы сгенерировать необходимый набор данных я воспользовался mockaroo.

Кроме того, модуль для работы с бд должен уметь инициализировать хранилище после запуска сервера.
Зависимости
- Warp — Фреймворк для создания веб-сервера на Расте.
- Tokio — Асинхронная среда выполнения для Раста.
- Serde — Библиотека для де/сериализации данных в типизированные данные Раста.
Реализация
Модели
Первое, что я хочу сделать, это определить свою модель пользователя, а также добавить некоторую структуру в код.
В main.rs определите новый модуль с именем models следующим образом:
mod models;
fn main() { /* Логика */ }Затем создать новый файл с именем models.rs и добавьте следующее:
pub struct Customer {
pub guid: String,
pub first_name: String,
pub last_name: String,
pub email: String,
pub address: String,
}Так как я разрабатываю API, эта структура данных должна иметь возможность сериализации и десериализации JSON. Я также хочу иметь возможность копировать структуру в хранилище данных и из него, не беспокоясь о проверке заимствования.
Для этого я добавлю оператор drive для структуры пользователя, чтобы использовать пару макросов из библиотеки Serde и пару из Rust. Сейчас models.rs выглядит так:
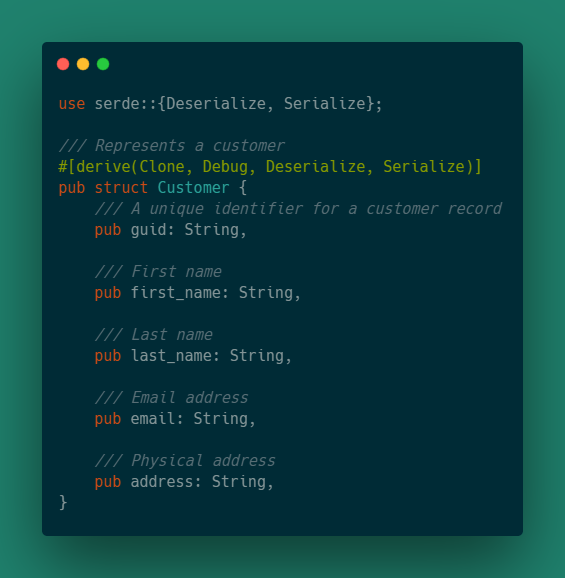
База данных
База данных для этого API будет являться in-memory(то есть находиться в оперативной памяти и после отключения сервера очистится), которая будет являться вектором структуры Customer. Но хранилище должно быть общим для всех маршрутов, поэтому я буду использовать смарт поинтеры[0] Раста вместе с Mutex[1], чтобы обеспечить безопасность потоков.
Во-первых, добавим в main.rs новый модуль db:
mod db;
mod models;
fn main() { /* Логика */ }Теперь создадим новый файл db.rs.
В этом файле нужно сделать несколько вещей, но первое, что нужно сделать, это определить, как будет выглядеть хранилище данных.
Наше простое хранилище это лишь вектор структур Customer, но его необходимо обернуть в thread safe ссылку, чтобы иметь возможность использовать несколько ссылок на хранилище данных в нескольких асинхронных обработчиках.
Добавим примерно такое в db.rs:
use std::sync::Arc; use tokio::sync::Mutex; use crate::models::Customer; pub type Db = Arc<Mutex<Vec<Customer>>>;
Теперь, когда мы определили структуру хранилища данных, нам нужен способ его инициализации. Инициализация хранилища данных имеет два результата: либо пустое хранилище данных, либо хранилище данных, наполненное данными из файла.
Инициализация пустого хранилища довольно проста:
pub fn init_db() -> Db {
Arc::new(Mutex::new(Vec::new()))
}Но чтобы получить данные из файла, нам придется добавить еще одну зависимость:
- serde_json — Для чтения необработанного JSON
serde_json = "1.0"
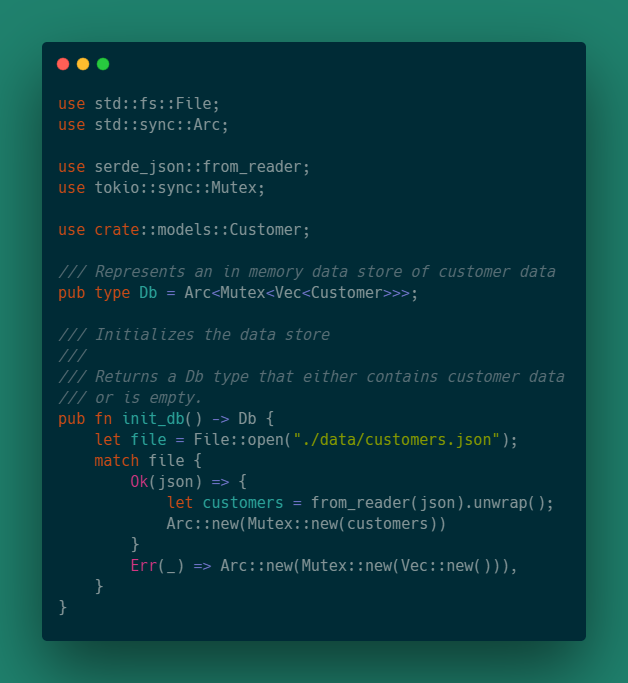
Теперь мы можем изменить db.rs следующим образом:
use std::fs::File;
use serde_json::from_reader;
pub fn init_db() -> Db {
let file = File::open("./data/customers.json");
match file => {
Ok(json) => {
let customers = from_reader(json).unwrap();
Arc::new(Mutex::new(customers))
},
Err(_) => {
Arc::new(Mutex::new(Vec::new()))
}
}
}Эта функция пытается прочитать файл ./data/customers.json. В случае успеха функция возвращает хранилище данных, загруженное данными клиента, в противном случае она возвращает пустой вектор.
db.rs должен выглядеть примерно так:
Обработчики
На текущем этапе мы имеем модели и настройку базы данных. Теперь у нас нужда в общем связывающем инструменте. Тут в дело вступают обработчики.
Создадим файл handlers.rs и определим его, как модуль в файле main.rs:
mod handlers;
Добавим в handlers.rs несколько импортов:
use std::convert::Infallible; use warp; use crate::models::Customer; use crate::db::Db;
Этот кусок позволяет обращаться к примитивам Customer и Db, которые мы определили ранее, из модуля обработчиков. Также тут мы импортируем модуль warp и перечисление Infallible, которое является типом ошибок, что никогда не могут произойти.
Список пользователей
Обработчик list_customersвобработчик принимает на вход ссылку на хранилище и возвращает Result, который оборачивает JSON-ответ.
pub async fn list_customers(db: Db) -> Result<impl warp::Reply, Infallible> {
// ...
} В теле функции нужно реализовать получение данных из хранилища и сериализация их в JSON объект. Для удобства wrap предоставляет функцию, которая преобразовывает вектор в JSON объект.
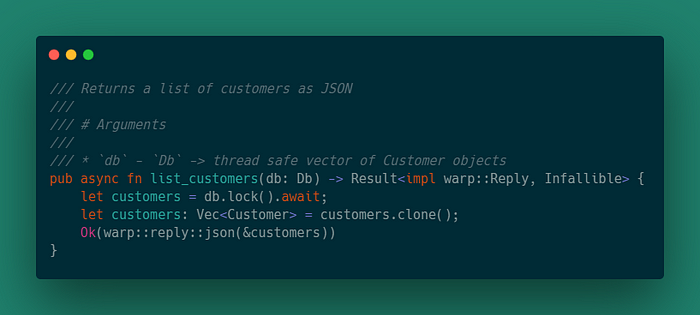
Строчка let customers = db.lock().await; дожидается блокировки выполнения задачи, чтобы можно было безопасно обратиться к хранилищу.
Строка let customers: Vec<Customer> = customers.clone() клонирует вектор из MutexGuard.
Последняя строка Ok(warp::reply::json(&customers)) оборачивает вектор в JSON объект и возвращает его.
Создание пользователя
Обработчик create_customer принимает на вход объект Customer и ссылку на хранилище. В случае успешного создания возвращает статус код CREATED, в ином случае BAD_REQUEST.
Но прежде нужно обновить импорты wrap'a в файле handlers.rs.
Заменяем строчку use wrap; на;
use warp::{self, http::StatusCode};Данное изменение позволит использовать перечисление StatusCode, как респонс.
По аналогии с list_customers определяем обработчик create_customer с подобным содержанием:
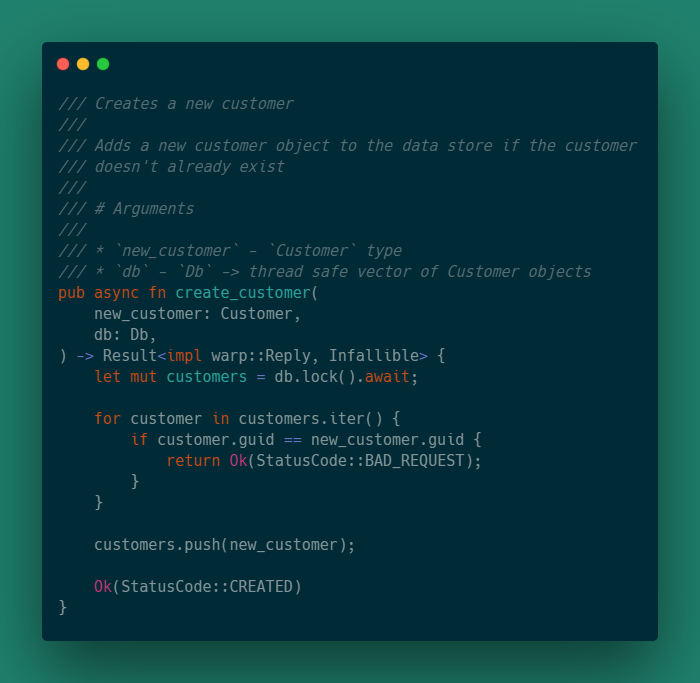
Получение пользователя
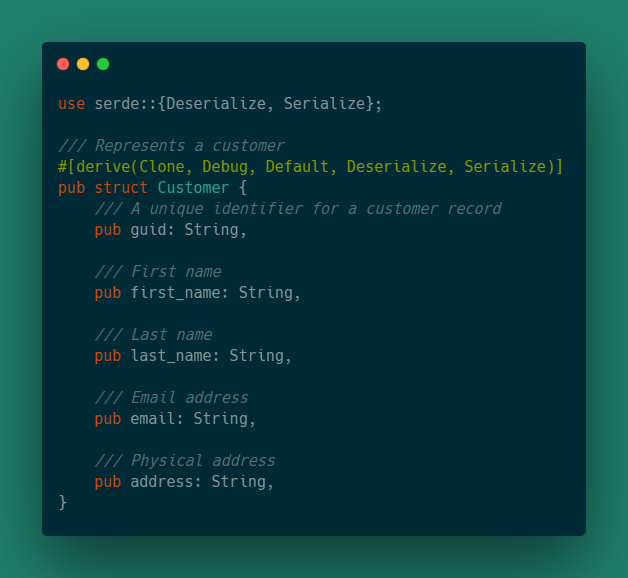
Обработчик get_customer на вход берет guid определенного пользователя и ссылку на базу данных и возвращает JSON-объект, если пользователь найден, иначе вернет заглушку в виде дефолтного объекта пользователя.
Перед этим добавим еще один макрос в структуру пользователя:
По аналогии с другими обработчиками добавляет что-то подобное в код:
pub async fn get_customer(guid: String, db: Db) -> Result<Box<dyn warp::Reply>, Infallible> {
}Возвращаемый примитив немного отличный от других, потому что на выходе мы получаем либо StatusCode, либо JSON-объект. Так как оба этих примитива реализуют warp::Reply, то мы можем использовать динамическое приведение через dyn.
Обновить пользователя
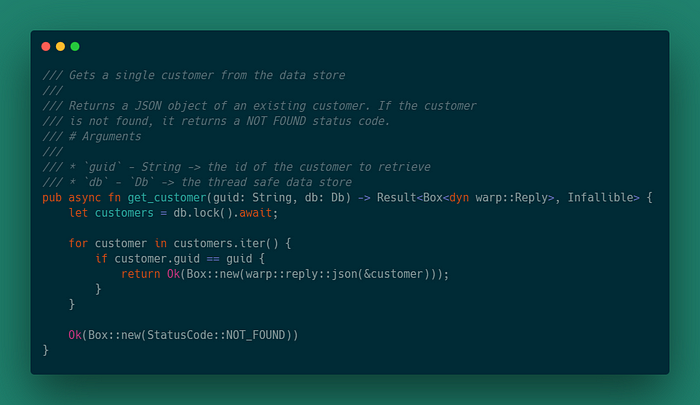
Обработчик update_customer на вход принимает guid пользователя, измененный объект Customer и ссылку на бд. Возвращает OK, если получилось изменить пользователя, NOT_FOUND в случае, если нет пользователя в хранилище.
Удаление пользователя
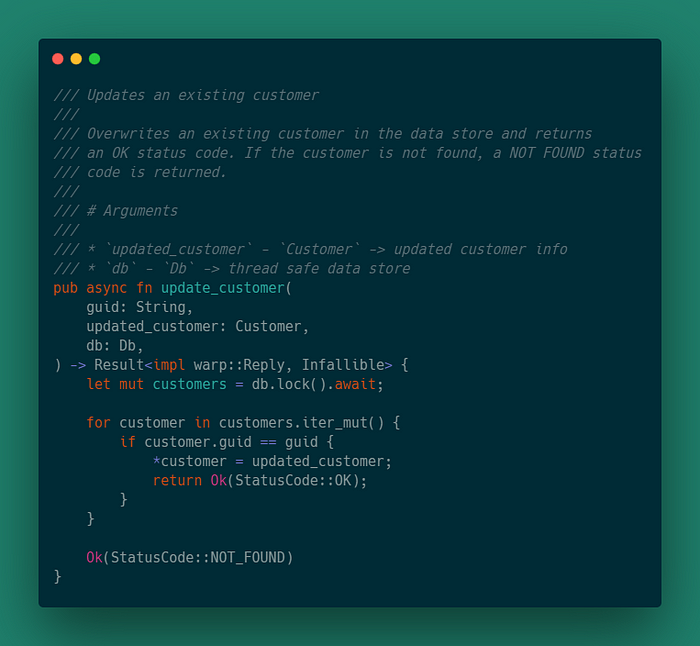
Обработчик delete_customer на вход принимает guid пользователя, которого нужно удалить и ссылку на хранилище.
Если удалось удалить пользователя из базы данных, то функция вернет NO_CONTENT, иначе NOT_FOUND.
Роутинг
Теперь у нас все обработчики собраны, теперь присвоим их соответствующим роутам.
В main.rs определим еще один модуль:
mod routes;
Теперь создадим файл routes.rs:
use std::convert::Infallible;
use warp::{self, Filter};
use crate::db::Db;
use crate::handlers;
use crate::models::Customer;Сначала нам нужна вспомогательная функция для передачи ссылки на хранилище данных в обработчики из маршрутов.
fn with_db(db: Db) -> impl Filter<Extract = (Db,), Error = Infallible> {
warp::any().map(move || db.clone())
}Функция позволяет инжектить хранилище в роут и передавать его обработчику. Filter это трейт, который предоставляет функциональность для подбора маршрутов, что являются результатом одного или нескольких методов Filter.
GET /customers
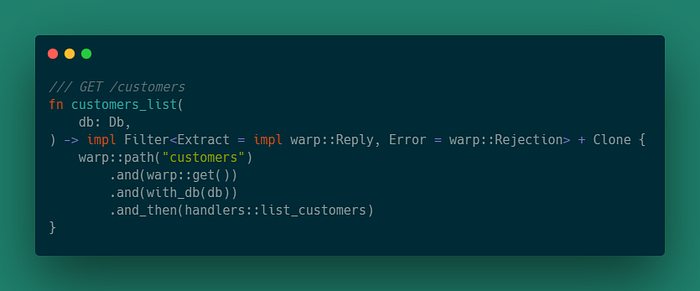
Функция возвращает тип, реализующий трейт Filter. Extract используется, когда происходит совпадение, и возвращается значение Extract.
По сути, функция определяет маршрут, который соответствует запрошенному пути «/customers» и является GET запросом.
Кроме того, чтобы сохранить некоторую работу в будущем, я реализую еще одну функцию, которая будет служить оболочкой для всех маршрутов пользователей. Позже будет легче, когда мы соединим все вместе.
pub fn customer_routes(db: Db) -> impl Filter<Extract = impl warp::Reply, Error = warp::Rejection> + Clone {
customers_list(db.clone())
}POST /customers
Этот маршрут добавит нового клиента в хранилище данных, если он еще не существует.
Одна вещь, которую нужно добавить, прежде чем мы реализуем функцию для маршрута, — это вспомогательная функция для извлечения JSON из тела POST запроса.
fn json_body() -> impl Filter<Extract = (Customer,), Error = warp::Rejection> + Clone {
warp::body::content_length_limit(1024 * 16)
.and(warp::body::json())
}Функция будет очень похожа на customers_list, за исключением обработчика. Добавьте в route.rs следующее:
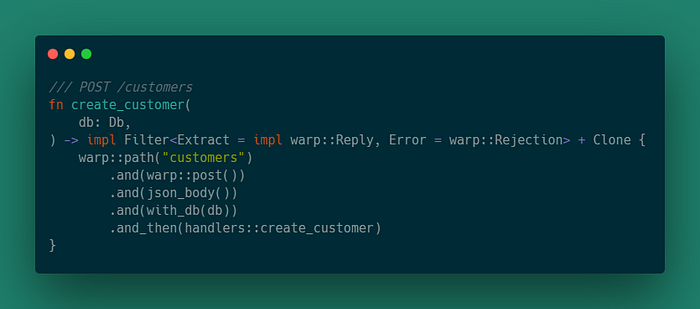
Эта функция определяет маршрут, который соответствует пути «/customers» и является POST запросом. Затем JSON из POST запроса и ссылка на хранилище извлекаются и передаются обработчику.
GET /customers/{guid}
Этот маршрут попытается получить одного клиента из хранилища данных.
В этой функции мы используем макрос path! из wrap, который позволяет передавать путь с переменной.
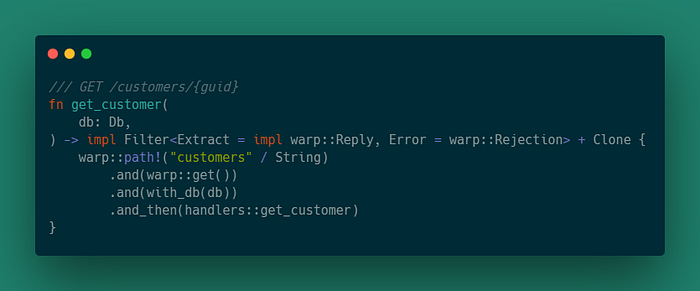
Это определяет маршрут, который будет соответствовать «customers/{какое-то значение}» и GET запросу. Затем он извлекает хранилище и передает его обработчику.
Одна вещь, которую следует учитывать для маршрутов, заключается в том, что наиболее конкретный маршрут должен быть проверен первым, иначе маршрут может не совпасть.
Например, если вспомогательная функция для маршрутов обновлена таким образом:
pub fn customer_routes(
db: Db,
) -> impl Filter<Extract = impl warp::Reply, Error = warp::Rejection> + Clone {
customers_list(db.clone())
.or(create_customer(db.clone()))
.or(get_customer(db.clone()))
}Маршрут get_customer никогда не будет совпадать, потому что они имеют общий корневой путь — «/customers», что означает, что маршрут списка клиентов будет соответствовать «/customers» и «/customers/{guid}».
Чтобы устранить проблему, упорядочите маршрут так, чтобы наиболее точное совпадение было первым. Как это:
pub fn customer_routes(
db: Db,
) -> impl Filter<Extract = impl warp::Reply, Error = warp::Rejection> + Clone {
get_customer(db.clone())
.or(customers_list(db.clone()))
.or(create_customer(db.clone()))
}PUT /customers/{guid}
Этот маршрут попытается обновить клиента, если он существует, и вернуть код состояния OK, в противном случае возвращается код состояния NOT_FOUND.
По аналогии с созданием определяем обработчик:
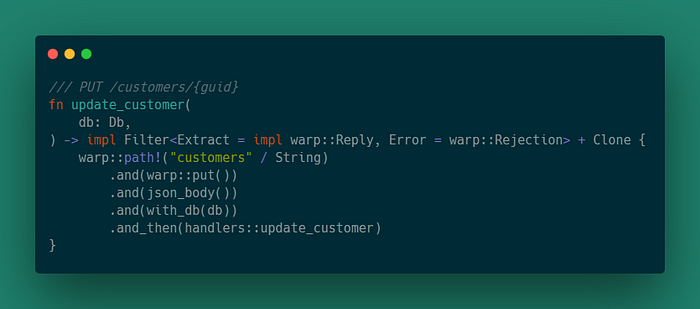
Затем обновим обертку над маршрутом пользователя:
pub fn customer_routes(
db: Db,
) -> impl Filter<Extract = impl warp::Reply, Error = warp::Rejection> + Clone {
get_customer(db.clone())
.or(update_customer(db.clone()))
.or(create_customer(db.clone()))
.or(customers_list(db))
}DELETE /customers/{guid}
Последний маршрут просто удаляет клиента из хранилища данных, если он соответствует заданному guid, а затем возвращает код состояния NO_CONTENT, в противном случае возвращается код состояния NOT_FOUND.
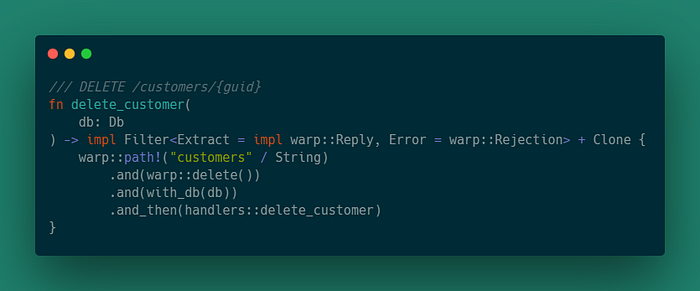
Затем обновим оболочку маршрута клиента. После добавления всех маршрутов обертка должна выглядеть так:
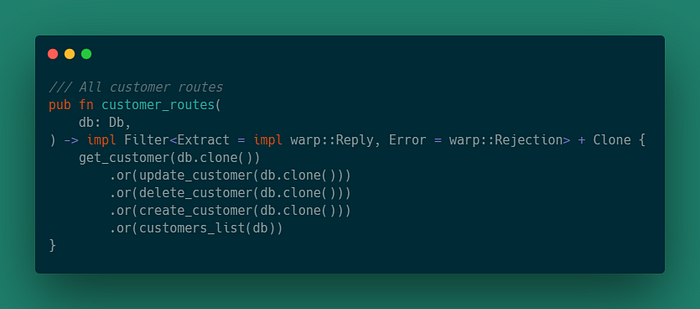
На этом все маршруты заканчиваются. Теперь мы можем перейти к связыванию всего вместе.
Функция main
Файл main.rs собирает все части кода воедино. Он инициализирует хранилище данных, получает все маршруты и запускает сервер. Это также довольно короткий файл, поэтому я просто покажу его целиком:
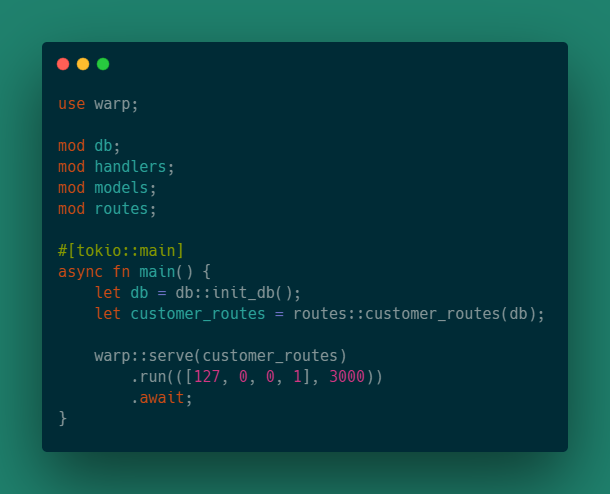
Мы уже видели первые несколько строк, так что давайте пройдемся по основной функции.
Атрибут функции #[tokio::main] устанавливает точку входа для среды выполнения tokio. Это позволяет нам объявить основную функцию как асинхронную.
Первые две строки main — это просто вызовы функций из наших модулей. Первый инициализирует хранилище данных, а второй получает оболочку маршрутов наших клиентов.
В последней строке используется warp::server для создания сервера, а затем run для запуска сервера на указанном хосте и порте. Мы используем ключевое слово await, чтобы выполнить код до тех пор, пока функция запуска не завершится.