Соревнование Santa's Stolen Sleigh

Компания FICO запустила конкурс Santa's Stolen Sleigh. Суть вкратце такова: нужно оптимизировать маршрут Санты и развести подарки по координатам.
Каждый подарок имеет свой вес и координаты доставки. Сани вмещают 1000 кг подарков, поэтому за пополнением нужно каждый раз возвращаться на северный полюс. Подробнее можно прочитать по ссылке на конкурс выше.
Карта адресов подарков
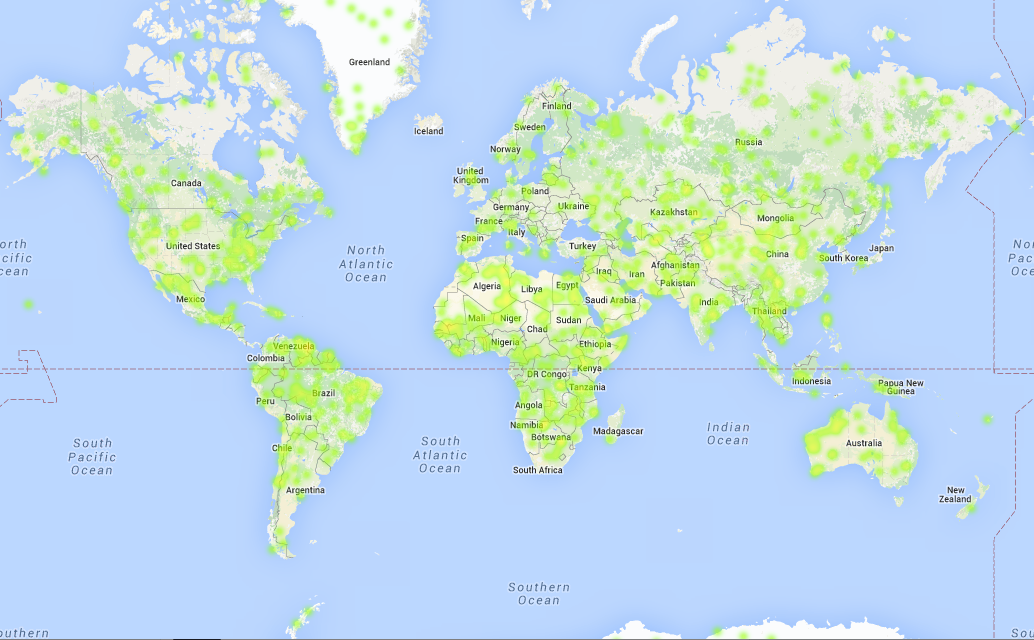
Начала файла со списком подарков
GiftId Latitude Longitude Weight 0 1 16.345769 6.303545 1.000000 1 2 12.494749 28.626396 15.524480 2 3 27.794615 60.032495 8.058499 3 4 44.426992 110.114216 1.000000 4 5 -69.854088 87.946878 25.088892 5 6 53.567970 -71.359308 38.000151 6 7 12.902584 79.966949 44.206616 7 8 -6.291099 -64.891751 1.000000 8 9 -2.685316 111.089758 1.000000
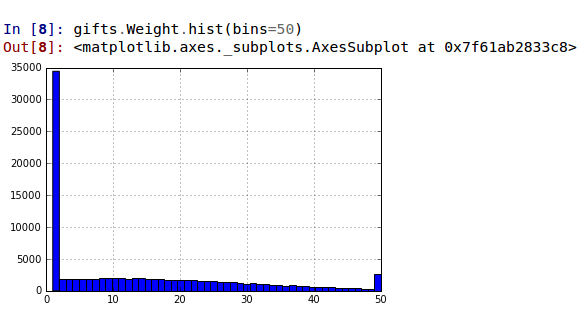
Гистограмма массы подарков. Основная большинство подарков массой около килограмма.
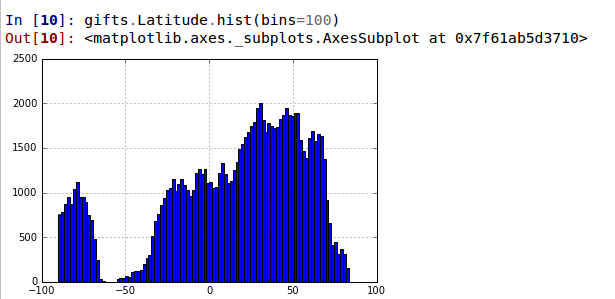
Распределение подарков по широтам
В качестве быстрого решения можно идти по каждой широте по вокруг справа налево, но из-за разорванности данных, это решение совсем не оптимально. Поэтому нужно для начала кластерирозовать на большие куски (например материки) и каждый материк отдельно перебегать.
Выделим 10 кластеров
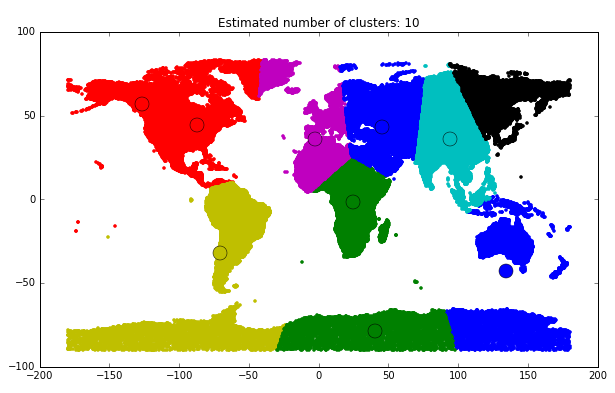
Теперь можно привести весь скрипт целиком с комментариями.
# https://www.kaggle.com/c/santas-stolen-sleigh/leaderboard
# Score: 15 316 005 444.46930
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
from sklearn.cluster import MiniBatchKMeans
gifts = pd.read_csv("../input/gifts.csv")
output_file = 'gurov_sub.csv'
# Разделяем все подарки на несколько частей
print('Mini cluster')
ms = MiniBatchKMeans(n_clusters=10, init='k-means++')
ms.fit(gifts.loc[:, ['Longitude', 'Latitude']].as_matrix())
gifts['cl1'] = ms.labels_
# Каждую часть делим на полоски по широте
# Подарки в каждой полоске сортируем по долготе
print('Sort')
gifts.loc[:, 'LatKey'] = np.around(gifts.loc[:, 'Latitude'])
gifts = gifts.sort_values(by=['cl1', 'LatKey', 'Longitude'], ascending=[True, True, True])
# Добавляем столбец с накопленой суммой и делим на куски по 1000 кг
# 951 - специальное число, чтобы масса в поездке не превышала 1000 кг
print('Cumsum')
gifts.loc[:, 'Wsum'] = gifts.loc[:, 'Weight'].cumsum()
gifts.loc[:, 'TripId'] = (np.trunc(gifts.loc[:, 'Wsum'] / 951) + 1).astype(int)
# ts = DataFrame(gifts.groupby('TripId')['Weight'].sum())
# print(ts[ts.Weight>1000])
print('file: ' + output_file)
gifts[[ 'GiftId', 'TripId' ]].to_csv(output_file, index = False)
Достоинства данного скрипта в том, что он работает очень быстро (4 секунды на Kaggle), выдавая приличный результат (15316005444.46930 у лидера 12389228461.09110) и не используя рассчеты расстояний между строчками, при этом краток и прост.