World-Consistent Video-to-Video Synthesis
🔗 Ссылки
https://arxiv.org/abs/2007.08509
https://nvlabs.github.io/wc-vid2vid/
https://github.com/NVlabs/imaginaire/tree/master/projects/wc_vid2vid
💎 Контрибьюшн
Главное достижение этой работы — консистентный vid2vid. Теперь если объекты попадают на видео второй раз, они имеют те же цвета, что и в первый — то есть сеть теперь "помнит" состояние всего ранее сгенерированного мира. Это достигается за счёт того, что по всем сгенерированным кадрам строится общий 3D point-cloud, где каждому пикселю соответствует его цвет. На основе этого point-cloud'а происходит синтез (рендеринг) новых кадров видео, соответствующих семантическим кадрам driving-video.
Плюсом к этому удалось добиться и большего реализма при рендеринге и лучшей временной стабильности.

🛠 Задача
Формулировка задачи точно такая же, как и в vid2vid — сделать так, чтобы распределения сгенерированных видео и реалистичных совпадали при обусловленности на одни и те же семантические карты.
В этой работе авторы вводят понятие world consistency, называя его частным случаем и более сильным условием, чем просто temporal consistency. Видео удовлетворяет world consistency, если оно консистентно относительно всего 3D-мира, который видит зритель при просмотре сгенерированного видео (в отличие от temporal consistency, для которой требуется консистентность на каждом небольшом промежутке вижео).
Математически это не формулируется, но интуитивно идея понятна — увиденные ранее объекты при повторном появлении должны иметь тот же вид.
🔎 Детали
Вводится понятие guidance image — это дополнительная картинка, которая помогает генератору правильно раскрашивать и текстурировать новый кадр в соответствии с ранее сгенерированными. Они должны содержать информацию о 3D-пространстве и о всех предыдущих кадрах. Авторы предлагают использовать для этого point-cloud сцены, который строится кадр за кадром по всему видео. С каждым новым сгенерированным кадром на point-cloud добавляются новые точки с соответствующими цветами.
Причём для обучения и инференса метод построения этого point-cloud'а может отличаться: если для обучающих видео сложно получить point-cloud'ы и имеет смысл использовать Structure-from-Motion (SfM) сети, то при инференсе для создания driving-видео может использоваться игровой движок, который знает GT-point-cloud для сцены.

- Нет прямого варпинга на основе OF (не используется формула маттинга), поскольку преобразование сцены в пространстве задаётся векторами перемещения 3D-точек — motion field. Тем не менее, поскольку нет нормального способа оценки motion field, происходит оценка OF, результат эмбеддится сетью, и выходы слоёв используются для параметров демодуляции в Multi-SPADE модулях генератора (причём так, чтобы соответствовал уровень фичей).
- Multi-SPADE модуль — несколько последовательных демодуляций с разными параметрами. Он нужен для того, чтобы принимать во внимание информацию от разных источников: семантических карт, OF и guidance images.
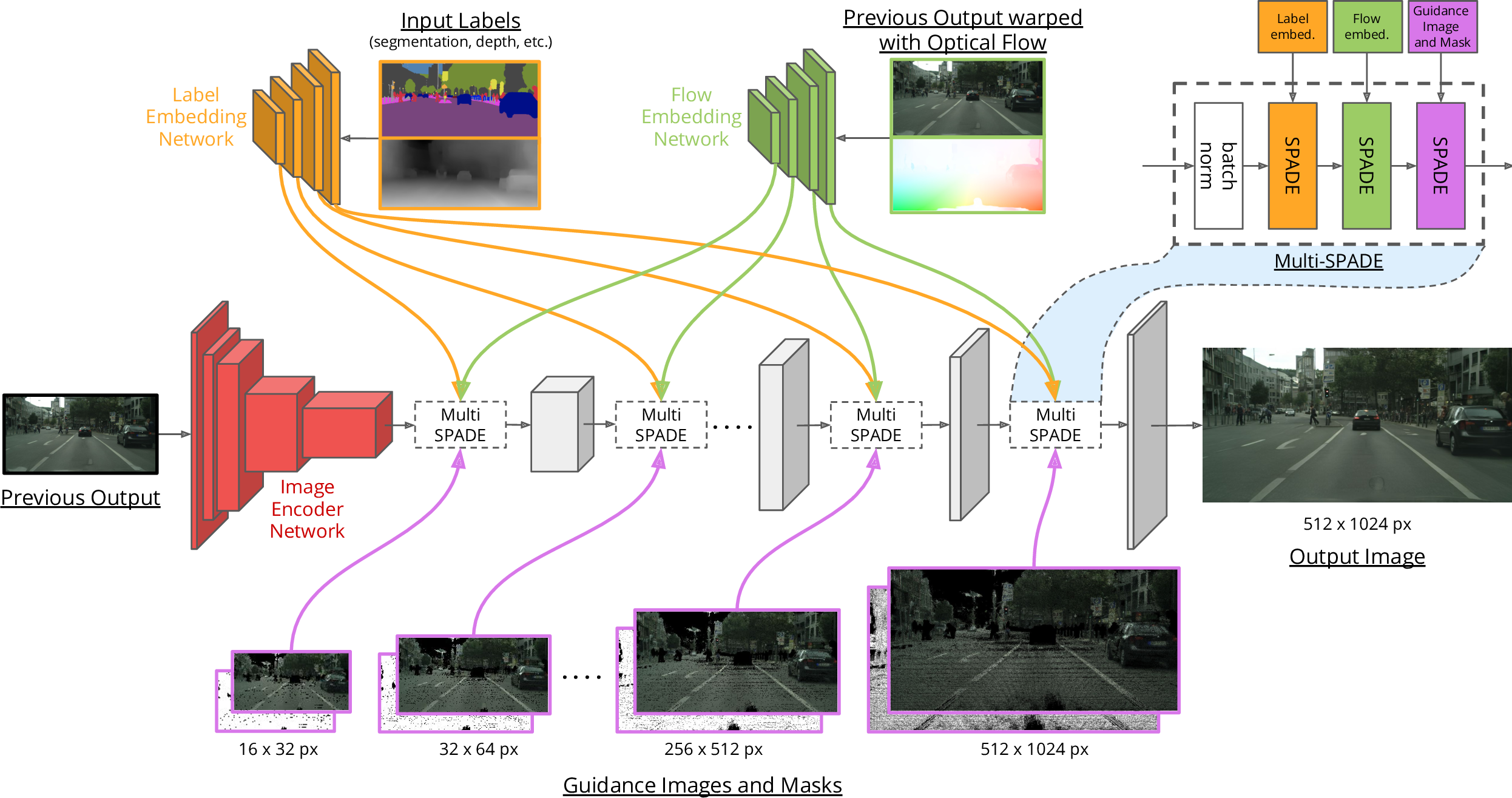
Использование разных эмбеддеров и Multi-SPADE модуля имеет несколько преимуществ по сравнению с конкатенацией всех источников и общим эмбеддером:
- Лучшая репрезентативность. Например, карты сегментации определяют форму и классы объектов, а guidance images — их цвета
- Легко учесть особенности разных видов данных. Например, в guidance images есть пропуски из-за ограничений SfM, поэтому в целесообразно использовать частичные свёртки
- Можно предобучить генератор на single-image generation благодаря тому, что при использовании Multi-SPADE кардинально меняются только нормализационные слои.
При переходе к видео нужно обучить только их, после чего дотюнить всю сеть. Это большой плюс, т. к. сбор картиночных датасетов гораздо проще, чем аннотация видео

Обучение
Обучение проводилось в 2 этапа:
- Single-image generation — обучается только первый SPADE-блок из 3-х. На этом этапе сеть учится генерировать реалистичные картинки по семантическим картам. Обучение длилось 20 эпох для разрешения 1024x512
- Video generation — обучаются все 3 SPADE-блока. Кол-во генерируемых кадров удваивалось каждую эпоху: 8->16->32, дальше не менялось. Тоже 20 эпох
Такой 2-этапный подход ускорил и стабилизировал обучение. Для GAN-лоссов вместо LSGAN выбрана другая модификация — hinge GAN loss. Помимо всех стандартных vid2vid-лоссов был добавлен world-consistency loss, чтобы форсить похожесть текущей генерации на предыдущие кадры.

Для аннотирования использовались:
- DensePose — UV-координаты и сегментации поз
- OpenPose — кейпоинты поз
- MegaDepth — карты глубины
- DeepLabv3-Plus c бэкбоном WideResNet38 — карты сегментации для Cityscapes
- NYUDv2 — карты сегментации для ScanNet
- OpenSfM — point-cloud'ы для guidance images
- HED — edge maps для MannequinChallenge и ScanNet
🔬 Эксперименты

Для сравнения использовались датасеты с практически статичными сценами, в которых SfM работает достаточно хорошо:
- vid2vid
- Inpainting — sota-inpainting метод, который использовался для заполнения дырок в guidance images
- Ours w/o W. C. — предложенная архитектура без использования guidance images
Forward-backward consistency
Помимо стандартных для этой задачи метрик и Human Preference Score зармерялась консистентность сгенерированных кадров зацикленных роликах 1->N->1. А именно замерялась попиксельная разница первого и последнего кадра в таких роликах в пространстве RGB и LAB

Заключение
В результате помимо заявленной проблемы удалось также улучшить short-term temporal stability (авторы говорят об этом на основе своих визуальных наблюдений) и сделать возможной генерацию консистентных стерео-ракурсов:

Основным ограничением модели являются текущие методы SfM, которые плохо справляются с динамичными сценами, что ведёт к проблемам с консистентностью