Распознавание некоторых современных CAPTCHA

Именно так называлась работа, представленная мной на Балтийском научно-инженерном конкурсе, и принёсшая мне очаровательную бумажку с римской единичкой, а также новенький ноутбук.
Работа заключалась в распознавании CAPTCHA, используемых крупными операторами сотовой связи в формах отправки SMS, и демонстрации недостаточной эффективности применяемого ими подхода. Чтобы не задевать ничью гордость, будем называть этих операторов иносказательно: красный, жёлтый, зелёный и синий.
Проект получил официальное название Captchure и неофициальное Breaking Defective Security Measures. Любые совпадения случайны.
Как ни странно, все (ну, почти все) эти CAPTCHA оказались довольно слабенькими. Наименьший результат — 20% — принадлежит жёлтому оператору, наибольший — 86% — синему. Таким образом, я считаю, что задача «демонстрации неэффективности» была успешно решена.
Причины выбора именно сотовых операторов тривиальны. Уважаемому Научному Жюри я рассказывал байку о том, что «сотовые операторы имеют достаточно денег, чтобы нанять программиста любой квалификации, и, в то же время, им необходимо минимизировать количество спама; таким образом, их CAPTCHA должны быть довольно мощными, что, как показывает моё исследование, совсем не так». На самом же деле всё было гораздо проще. Я хотел набраться опыта, взломав распознав какую-нибудь простую CAPTCHA, и выбрал жертвой CAPTCHA красного оператора. А уже после этого, задним числом родилась вышеупомянутая история.
Итак, ближе к телу. Никакого мегапродвинутого алгоритма для распознавания всех четырёх видов CAPTCHA у меня нет; вместо него я написал 4 различных алгоритма для каждого вида CAPTCHA по отдельности. Однако, несмотря на то, что алгоритмы в деталях различны, в целом они оказались очень похожими.
Как и многие авторы до меня, я разбил задачу распознавания CAPTCHA на 3 подзадачи: предварительную обработку (препроцесс), сегментацию и распознавание. На этапе препроцесса из исходного изображения удаляются различные шумы, искажения и пр. В сегментации из исходного изображения выделяются отдельные символы и производится из постобработка (например, обратный поворот). При распознавании символы по одному обрабатываются предварительно обученной нейросетью.
Существенно различался только препроцесс. Это связано с тем, что в различных CAPTCHA применяются различные методы искажения изображений, соответственно, и алгоритмы для удаления этих искажений сильно различаются. Сегментация эксплуатировала ключевую идею поиска компонентов связности с незначительными наворотами (значительными их пришлось сделать только у жёлто-полосатых). Распознавание было абсолютно одинаковым у трёх операторов из четырёх — опять-таки, отличался только жёлтый оператор.
Код написан на Python с применением библиотек OpenCV и FANN, которые не ставятся без напильника приличных размеров и бубна впридачу. Поэтому мои результаты будет воспроизвести непросто — по крайней мере, до тех пор, пока авторы вышеупомянутых библиотек не сделают нормальные привязки для Python.
RedКак я уже сказал, первым кроликом я выбрал именно эту CAPTCHA. Думаю, несколько примеров прояснят ситуацию:
Вот-вот, и мне тоже сначала показалось, что она очень простая… Однако, это впечатление возникло не на пустом месте. Итак:
- Цвета исчерпываются градациями серого, причём символы — светлые, фон — тёмный
- Отсутствует дополнительный шум
- Постоянные искажения (то есть не изменяющиеся от картинки к картинке)
- Символов всегда ровно пять
- Размеры символов приблизительно одинаковы
- Символы почти всегда связны
Казалось, всё это сводит на нет достоинства этой CAPTCHA:
- Слипающиеся буквы
- Мерзкий дырявый шрифт
- Очень маленький размер (83x23 px)
Естественно, эти «достоинства» являются таковыми только с точки зрения сложности автоматического распознавания. В соответствии с трёхэтапной схемой, упомянутой мной ранее, начнём с предварительной обработки изображения, а именно увеличения в 2 раза.


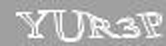
Как я уже упоминал, искажения здесь постоянны, и, даже несмотря на то, что они не являются линейными, избавиться от них нетрудно. Параметры были подобраны эмпирически.




Далее я применяю пороговое преобразование (в народе Threshold) с t=200 и инвертирую изображение:

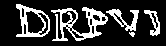

Наконец, белым закрашиваются мелкие (меньше 10px) чёрные связные области:



Далее следует сегментация. Как я уже сказал, здесь применяется поиск компонентов связности:



Иногда (редко, но бывает) буква распадается на несколько частей; для исправления этого досадного недоразумения я применяю довольно простую эвристику, оценивающую принадлежность нескольких компонентов связности к одному символу. Эта оценка зависит только от горизонтального положения и размеров описывающих прямоугольников (bounding boxes) каждого символа.

Нетрудно заметить, что многие символы оказались объединены в один компонент связности, в связи с чем надо их разделять. Здесь на помощь приходит тот факт, что на изображении всегда ровно 5 символов. Это позволяет с большой точностью вычислять, сколько символов находится в каждом найденном компоненте.
Для объяснения принципа работы такого алгоритма придётся немного углубиться в матчасть. Обозначим количество найденных сегментов за n, а массив ширин (правильно сказал, да?) всех сегментов за widths[n]. Будем считать, что если после вышеупомянутых этапов n > 5, изображение распознать не удалось. Рассмотрим все возможные разложения числа 5 на целые положительные слагаемые. Их немного — всего 16. Каждое такое разложение соответствует некоторой возможной расстановке символов по найденным компонентам связности. Логично предположить, что чем шире получившийся сегмент, тем больше символов он содержит. Из всех разложений пятёрки выберем только те, в которых количество слагаемых равно n. Поделим каждый элемент из widths на widths[0] — как бы нормализуем их. То же самое проделаем со всеми оставшимися разложениями — поделим каждое число в них на первое слагаемое. А теперь (внимание, кульминация!) заметим, что получившиеся упорядоченные n-ки можно мыслить как точки в n-мерном пространстве. С учётом этого, найдём ближайшее по Евклиду разложение пятёрки к нормализованному widths. Это и есть искомый результат.
Кстати, в связи с этим алгоритмом мне в голову пришёл ещё один интересный способ искать все разложения числа на слагаемые, который я, правда, так и не реализовал, закопавшись в питоновских структурах данных. Вкратце — он довольно очевидно вылезает, если заметить, что количество разложений определённой длины совпадает с соответствующим уровнем треугольника Паскаля. Впрочем, я уверен, что этот алгоритм давным-давно известен.
Так вот, после определения количества символов в каждом компоненте наступает следующая эвристика — мы считаем, что разделители между символами тоньше, чем сами символы. Для того чтобы воспользоваться этим сокровенным знанием, расставим по сегменту n-1 разделителей, где n — количество символов в сегменте, после чего в небольшой окрестности каждого разделителя посчитаем проекцию изображения вниз. В результате этого проецирования мы получим информацию о том, сколько в каждом столбце пикселей принадлежат символам. Наконец, в каждой проекции найдём минимум и сдвинем разделитель туда, после чего покромсаем изображение по этим разделителям.




Наконец, распознавание. Как я уже говорил, для него я применяю нейросеть. Для её обучения сначала я прогоняю две сотни изображений под общим заголовком trainset через уже написанные и отлаженные первые два этапа, в результате чего получаю папку с большим количеством аккуратно нарезанных сегментов. Затем руками вычищаю мусор (результаты неправильной сегментации, например), после чего результат привожу к одному размеру и отдаю на растерзание FANN. На выходе получаю обученную нейросеть, которая и используется для распознавания. Эта схема дала сбой только один раз — но об этом позже.