Модель BG-NBD для анализа клиентской базы на Python
Введение
В этом материале мы воспроизведём на Python модель BG-NBD (Beta Geometric Negative Binomial Distribution). Она может быть использована для прогнозирования повторных заказов клиентов, чтобы определить пожизненную ценность клиентов (LTV — lifetime value). Она также может быть использована для прогнозирования оттока.
Будем всё делать на примере данных в excel-файлике, скачать его можно здесь.
Модель уже реализована на Python в пакете lifetimes, но наша цель изучить её изнутри и понять каждый шаг, необходимый для её реализации.
Допущения
У данной модели, как и у любой другой, есть ряд допущений, которые надо соблюдать для её корректного применения. Рассмотрим их.
1. Пока пользователи активны, их транзакции на временном отрезке t подчиняются распределению Пуассона со средним значением λt.
Давайте посмотрим на распределение вероятностей для одного клиента со значением λ = 5.
import matplotlib.pyplot as plt
from scipy.stats import poisson
probability_arr = []
distribution = poisson(5)
for transactions in range(0,20):
probability_arr.append(distribution.pmf(transactions))
plt.figure(figsize=(8,5))
plt.ylabel('Probability')
plt.xlabel('Number of Transactions')
plt.xticks(range(0, 20))
plt.title('Probability Distribution Curve')
plt.plot(probability_arr,
color='black',
linewidth=0.7,
zorder=1)
plt.scatter(range(0, 20),
probability_arr,
color='purple',
edgecolor='black',
linewidth=0.7,
zorder=2)
plt.show()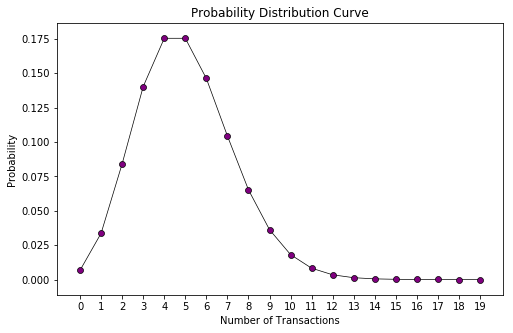
2. Различия в частоте транзакций между клиентами соответствуют гамма-распределению с размерностью r и масштабом α.
Давайте посмотрим, как будут выглядеть распределения вероятностей для 100 клиентов с r = 9.0 и α = 0.5:
import numpy as np
plt.figure(figsize=(8,5))
for customer in range(0, 100):
distribution = poisson(np.random.gamma(shape=9, scale=0.5))
probability_arr = []
for transactions in range(0,20):
probability_arr.append(distribution.pmf(transactions))
plt.plot(probability_arr, color='black', linewidth=0.7, zorder=1)
plt.ylabel('Probability')
plt.xlabel('Number of Transactions')
plt.xticks(range(0, 20))
plt.title('Probability Distribution Curve 100 Customers')
plt.show()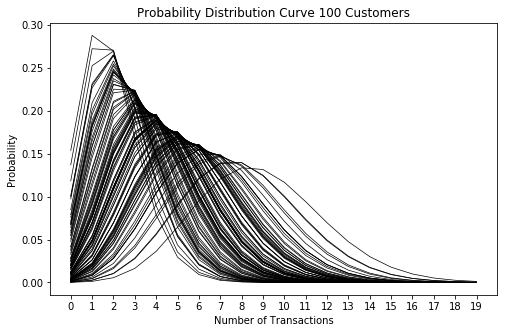
3. Каждый клиент становится неактивным после каждой транзакции с вероятностью p.
4. Различия в p соответствуют бета-распределению с параметрами a и b.
Давайте сгенерируем случайный отток клиентов с вероятностью p, который подчиняется бета-распределению с параметрами a = 1.0 и b = 2.5 для каждого из наших 100 клиентов после каждой транзакции и посмотрим, что произойдёт с кривыми распределения вероятностей:
import numpy as np
plt.figure(figsize=(8,5))
for customer in range(0, 100):
distribution = poisson(np.random.gamma(shape=9, scale=0.5))
probability_arr = []
beta = np.random.beta(a=1.0, b=2.5)
cumulative_beta = 0
for transactions in range(0,20):
proba = distribution.pmf(transactions)
cumulative_beta = beta + cumulative_beta - (beta * cumulative_beta)
inactive_probability = 1 - cumulative_beta
proba *= inactive_probability
probability_arr.append(proba)
probability_arr = np.array(probability_arr)
probability_arr /= probability_arr.sum()
plt.plot(probability_arr, color='black', linewidth=0.7, zorder=1)
plt.ylabel('Probability')
plt.xlabel('Number of Transactions')
plt.xticks(range(0, 20))
plt.title('Probability Distribution Curve 100 Customers with drop-off probability after each transaction')
plt.show()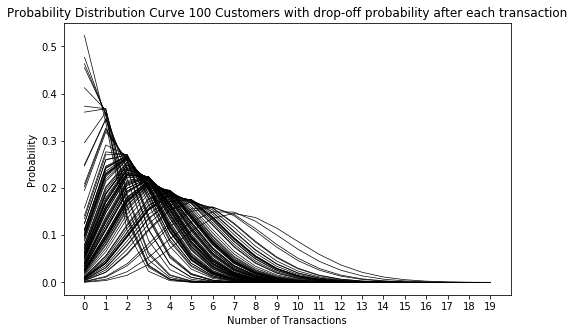
Видим, что распределение сместилось влево. Это логично, т.к. возрастает вероятность меньшего количества транзакций, потому что после каждой транзакции клиент может не вернуться, и она накапливается с каждой дополнительной транзакцией.
5. Скорость транзакций и вероятность оттока у разных клиентов варьируются независимо друг от друга.
Загрузка данных
Давайте начнём с загрузки данных из файла Excel в датафрейм Pandas.
import pandas as pd
df = pd.read_excel('bgnbd.xls', sheet_name='Raw Data').set_index('ID')
df.head()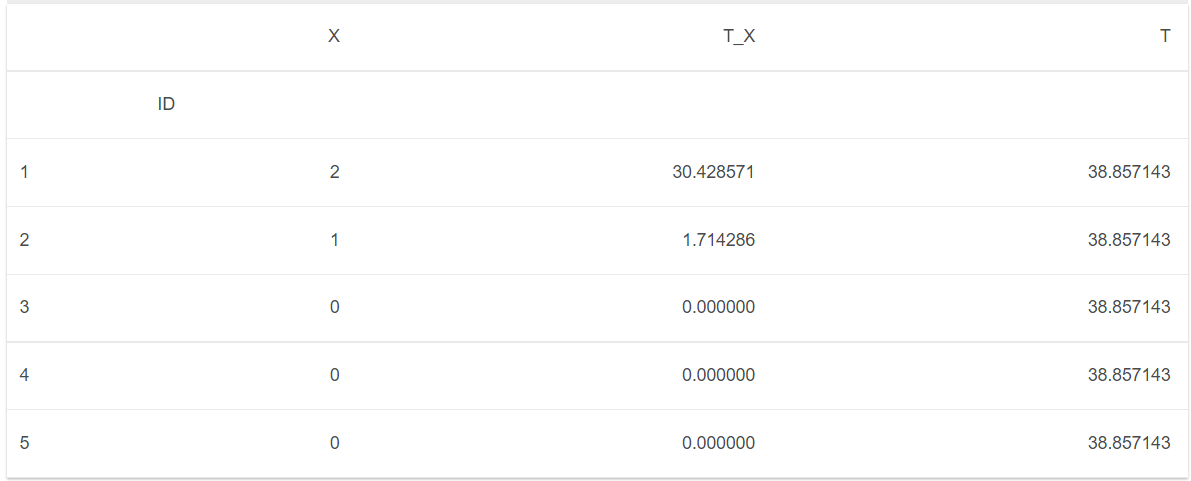
- x — количество повторных покупок у клиента с момента первой покупки.
- tx — дата самой последней покупки в неделях с момента первой покупки клиента.
- T — это время в неделях с момента первой покупки клиента.
Оптимизация параметра функции правдоподобия
Учитывая вышеуказанные допущения, вероятность того, что клиент совершит x покупок за период времени T, равна:

Однако, вероятность зависит от знания переменных λ и p, которые мы по факту определить не можем.
Вместо этого мы можем написать функцию правдоподобия случайного клиента с историей покупок X = x, tx, T как:
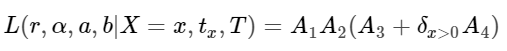
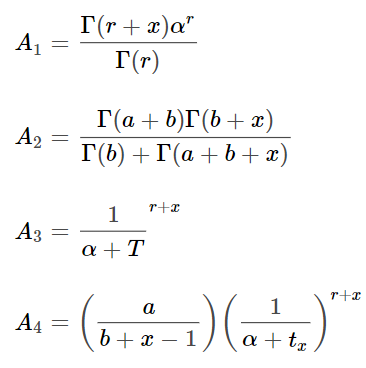
Теперь мы можем оптимизировать параметры функции правдоподобия путём оптимизации функции логарифмического правдоподобия таким образом, чтобы функция логарифмического правдоподобия была:
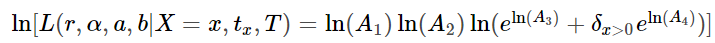
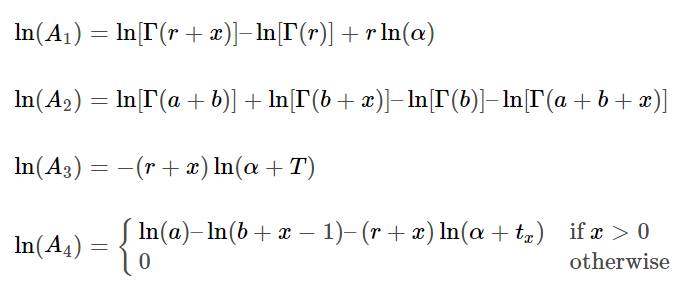
Определим это как отрицательное логарифмическое правдоподобие в Python:
from scipy.special import gammaln
def negative_log_likelihood(params, x, t_x, T):
if np.any(np.asarray(params) <= 0):
return np.inf
r, alpha, a, b = params
ln_A_1 = gammaln(r + x) - gammaln(r) + r * np.log(alpha)
ln_A_2 = (gammaln(a + b) + gammaln(b + x) - gammaln(b) -
gammaln(a + b + x))
ln_A_3 = -(r + x) * np.log(alpha + T)
ln_A_4 = x.copy()
ln_A_4[ln_A_4 > 0] = (
np.log(a) -
np.log(b + ln_A_4[ln_A_4 > 0] - 1) -
(r + ln_A_4[ln_A_4 > 0]) * np.log(alpha + t_x)
)
delta = np.where(x>0, 1, 0)
log_likelihood = ln_A_1 + ln_A_2 + np.log(np.exp(ln_A_3) + delta * np.exp(ln_A_4))
return -log_likelihood.sum()Теперь мы можем оптимизировать наши параметры. Мы будем использовать метод оптимизации Нелдера-Мида, который является эвристическим неградиентным методом поиска, чтобы минимизировать нашу функцию потерь отрицательного логарифмического правдоподобия.
from scipy.optimize import minimize
scale = 1 / df['T'].max()
scaled_recency = df['t_x'] * scale
scaled_T = df['T'] * scale
def _func_caller(params, func_args, function):
return function(params, *func_args)
current_init_params = np.array([1.0, 1.0, 1.0, 1.0])
output = minimize(
_func_caller,
method="Nelder-Mead",
tol=0.0001,
x0=current_init_params,
args=([df['x'], scaled_recency, scaled_T], negative_log_likelihood),
options={'maxiter': 2000}
)
r = output.x[0]
alpha = output.x[1]
a = output.x[2]
b = output.x[3]
alpha /= scale
print(f"r = {r}")
print("alpha = {}".format(alpha))
print("a = {}".format(a))
print("b = {}".format(b))r = 0.242594123569 alpha = 4.41358813135 a = 0.792935471652 b = 2.42595536972
Прогнозирование ожидаемых продаж
Итак, теперь, когда у нас подобраны параметры r, α, a и b, мы можем использовать их для прогноза повторных продаж для когорты клиентов за период времени t, используя следующую формулу для любого конкретного человека:
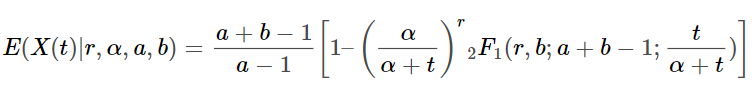
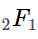
— это гипергеометрическая функцией Гаусса, которая принимает вид:
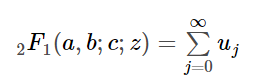
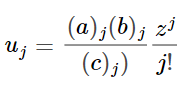
И эту запись можно свести к ряду:
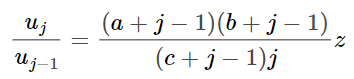
Теперь заменим приведённые выше значения на значения функции 2F1 a, b, c и z.
from scipy.special import hyp2f1
def expected_sales_to_time_t(t):
hyp2f1_a = r
hyp2f1_b = b
hyp2f1_c = a + b - 1
hyp2f1_z = t / (alpha + t)
hyp_term = hyp2f1(hyp2f1_a, hyp2f1_b, hyp2f1_c, hyp2f1_z)
return ((a + b - 1) / (a - 1)) * (1-(((alpha / (alpha+t)) ** r) * hyp_term))Итак, теперь мы можем оценить прогнозные продажи для клиента. Допустим, мы хотим посмотреть, сколько покупок мы можем ожидать от клиента в течение одного года (52 недели):
expected_sales_to_time_t(52)
1.444010643699092
Модель прогнозирует 1,44 продаж.
Теперь рассчитаем совокупные повторные продажи за 78 недель для всей когорты. Мы для этого не можем просто масштабировать наш прогноз по клиенту на общее число клиентов, ведь нам нужно учитывать тот факт, что у каждого клиента разное время первой покупки.
ns — это количество людей, недавно совершивших новую покупку.
S — это общее возможное количество дат совершения покупки.
Общее количество повторных транзакций:
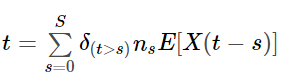
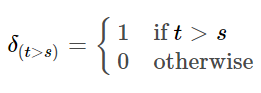
# Срок рассмотрения составляет 39 недель # Т показывает время, прошедшее с момента первой покупки n_s = (39 - df['T']).value_counts().sort_index() n_s.head()
0.142857 18 0.285714 22 0.428571 17 0.571429 20 0.714286 23 Name: T, dtype: int64
18 человек совершили свою первую транзакцию на 1-й день (1/7 недели), 22 — на 2-й день (2/7 недель), 17 — на 3-й день (1/7 недели) и так далее.
forecast_range = np.arange(0, 78, 1/7.0)
def cumulative_repeat_transactions_to_t(t):
expected_transactions_per_customer = (t - n_s.index).map(lambda x: expected_sales_to_time_t(x) if x > 0 else 0)
expected_transactions_all_customers = (expected_transactions_per_customer * n_s).values
return expected_transactions_all_customers.sum()
cum_rpt_sales = pd.Series(map(cumulative_repeat_transactions_to_t, forecast_range), index=forecast_range)
cum_rpt_sales.tail(10)76.571429 4109.744742 76.714286 4114.856053 76.857143 4119.961614 77.000000 4125.061441 77.142857 4130.155549 77.285714 4135.243956 77.428571 4140.326675 77.571429 4145.403724 77.714286 4150.475118 77.857143 4155.540873 dtype: float64
Таким образом, в течение следующих 78 недель мы прогнозируем около 4156 повторных транзакций от клиентов.
Условное мат. ожидание
Если мы хотим рассчитать ожидаемые продажи одному клиенту (сколько транзакций совершит любой отдельный клиент в будущем за период времени t), мы можем рассчитать условное мат. ожидание при помощи следующей формулы:
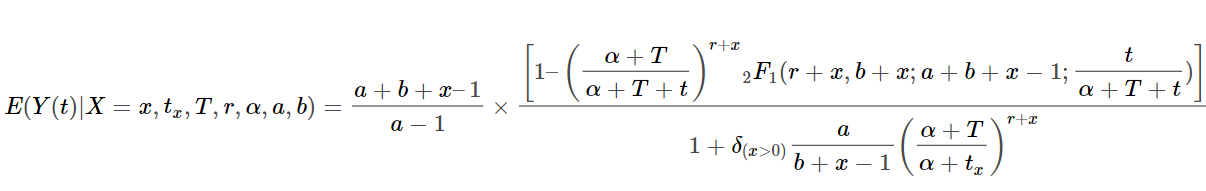
def calculate_conditional_expectation(t, x, t_x, T):
first_term = (a + b + x - 1) / (a-1)
hyp2f1_a = r + x
hyp2f1_b = b + x
hyp2f1_c = a + b + x - 1
hyp2f1_z = t / (alpha + T + t)
hyp_term = hyp2f1(hyp2f1_a, hyp2f1_b, hyp2f1_c, hyp2f1_z)
second_term = (1 - ((alpha + T) / (alpha + T + t)) ** (r + x) * hyp_term)
delta = 1 if x > 0 else 0
denominator = 1 + delta * (a / (b + x - 1)) * ((alpha + T) / (alpha + t_x)) ** (r+x)
return first_term * second_term / denominator
calculate_conditional_expectation(39, 2, 30.43, 38.86)1.225904664486748
Таким образом, мы ожидаем, что клиент, с такими характеристиками:
совершит 1.22 покупки в течение следующих 39 недель, учитывая, что они взяты из той же когорты, что и другие, использованные для расчёта наших параметров.
Надеюсь, вы не сошли с ума ( ͡❛ ‿‿ ͡❛).
Источник: Ben Alex Keen